
基于FPGA的卷积神经网络图像识别算法研究
2023-11-30 04:55崔劼
无线互联科技 2023年18期


作者简介:崔劼(1988— ),男,山西太原人,讲师,硕士;研究方向:计算机网络。
摘要:文章探讨了基于FPGA的卷积神经网络图像识别算法的设计和实现。由于卷积神经网络在图像识别中的优秀表现,文章结合FPGA的低功耗和高并行性,期望在嵌入式系统和边缘计算设备上获得更高的性能。通过系统架构设计、硬件资源优化以及算法的软件实现,文章成功地在FPGA上实现了卷积神经网络的图像识别算法。初步实验结果显示,本设计在保持高识别精度的同时,实现了更高的处理速度和更好的能效。
关键词:FPGA;卷积神经网络;网络图像识别;算法
中图分类号:TP391.41 文献标志码:A
0 引言
卷积神经网络(Convolutional Neural Networks,CNN)已经被广泛应用于各种图像识别任务中,并取得了优异的效果。然而,这些模型往往需要大量的计算资源和电力,这对于许多实时应用和移动设备来说是一个重大挑战。为了克服这些挑战,本文提出了一种基于现场可编程门阵列(Field-Programmable Gate Array,FPGA)的卷积神经网络图像识别算法。FPGA 是一种可以被用户在硬件级别进行配置的半导体设备,它具有高度的并行性和可重配置性,能够高效地执行大量并行计算,尤其适合实现卷积神经网络。本文将详细介绍这种基于FPGA的卷积神经网络的设计和实现过程,以及在实际图像识别任务中的应用和性能分析。
1 卷积神经网络理论
1.1 卷积神经网络基本结构
卷积神经网络(Convolutional Neural Networks,CNN)是一种特殊的深度学习模型,主要用于处理具有网格结构的数据,例如:图像。其主要特点是通过使用卷积操作,捕捉并处理局部数据的相关性,使其在处理图像等高维度数据时具有很高的效率。一个典型的卷积神经网络由多个层次构成,这些层次可以大致分为卷积层、激活层、池化层和全连接层。卷积层是卷积神经网络的核心组成部分。在这一层,网络会对输入数据进行一系列的卷积操作,生成特征映射(Feature Map)。每个卷积操作都会应用一个滤波器(也叫卷积核)到输入数据上,滤波器可以学习并捕捉到数据中的局部特征[1]。激活层通常会紧接在卷积层之后。这一层会对卷积层的输出应用一个非线性函数,如ReLU、Sigmoid或Tanh等。非线性激活函数可以增加网络的表达能力,使其能够学习并表示更复杂的模式。池化层用于降低数据的空间维度,减少模型的参数和计算量,同时还可以提高模型的平移不变性。常见的池化操作包括最大池化、平均池化等。全连接层通常位于网络的最后几层,用于进行高级的推理和分类。全连接层会将前一层的所有输出连接到每一个神经元上,形成一个向量,通过一个或多个全连接层,进行非线性变换,最后输出预测结果。具体如图1所示。
以上4种层级是构成卷积神经网络的基本元素,通过组合不同类型和数量的层级,可以构建出各种不同结构和功能的卷积神经网络,用于解决不同的任务。
1.2 卷积神经网络工作原理
卷积神经网络操作分为两个步骤,首个步骤是正向传播:原始数据通过一连串累积的卷积层和池化层,进入全连接层并经过输出层给出结果。第二个步骤是反向传播:通过损失函数计算正向传播的结果和真实值之间的差异,利用梯度下降法逐层更新网络中的权重和偏差,其操作流程如图2所示。
2 基于FPGA的卷积神经网络设计
2.1 系统架构设计
本系统架构采用软硬件协同设计的方式,由FPGA的可编程逻辑(PL)部分和ARM处理器(PS)部分组成的片上系统实现。系统中PS端负责对整个系统的存储和流程进行控制,而PL端负责执行卷积神经网络的计算操作。在FPGA的PL端,设计了卷积层模块、池化层模块和全连接层模块,用于执行图像的数据运算。而FPGA的PS端则负责图像控制、权值和偏置的缓存模块以及PL侧的参数配置。系统中的直接内存存取(DMA)模块主要负责将图像和预先训练好的权重数据从外部存储的DDR3中读取出来,传输到PS端。FPGA驱动DMA模块将参数传输到片上的RAM中,并将需要进行卷积运算的数据暂时存放到缓存模块中,为PL端的加速计算提供支持[2]。接下来,FPGA将RAM中的图像特征参数以及权值和偏置数据传输到PL端进行加速计算。等到卷积神经网络的所有层的运算都完成后,系统会将中间的数据缓存到RAM中,再将这些数据从RAM写回到PS端的DDR3中。整个系统使用AXI总线进行模块间的通信和数据传输,将结果传输到PC端进行显示。这样的设计使得整个系统在运行过程中能够高效地处理大量的数据,从而实现对卷积神经网络的有效加速。
2.2 硬件资源优化
在设计基于FPGA的卷积神经网络系统时,硬件资源的优化是至关重要的一环,涉及并行计算、数据流优化、硬件资源复用、精度和位宽优化以及网络结构优化等多个方面。(1)并行计算。本次设计为充分发挥出FPGA的计算优势,在卷积神经网络的设计中,将多个卷积和池化运算分布到各个处理单元并行进行。本研究設计了独立的、可并行处理的卷积核处理单元,从而实现每个单元能对输入数据的一个子集进行处理,再将各个单元的处理结果进行整合。这既优化了并行计算对硬件资源的占用程度,也显著提高了系统处理速度。(2)数据流优化。在卷积神经网络中,大量的存储和读取操作使得数据流管理成为优化的重要环节[3]。本设计采用直接内存访问(Direct Memory Access,DMA)技术,减少了数据在各部分间的传输,降低了延迟并提高了数据的吞吐量。本研究将需要频繁访问的数据存储在片上存储器(On-Chip Memory)中,以此来减少对外部存储器(Off-Chip Memory)的访问,进一步提高系统效率。(3)硬件资源复用。在不同的卷积层之间,本研究设计了共享的处理单元,从而最大化地利用硬件资源,既维持了处理效率,也有效地节省了硬件资源。(4)精度和位宽优化。在卷积神经网络中,数据的精度和位宽对于硬件资源的占用和计算效率有着直接影响。因此,本设计对数据的精度和位宽进行了优化。具体来说,通过采用定点数替代浮点数进行运算,在尽可能减小数据的位宽的同时,也减轻了硬件资源的负担,提高了运算效率[4]。(5)网络结构优化。考虑到网络结构对硬件资源占用的影响,对网络结构进行了精心设计和优化。本设计根据硬件资源的限制和实际需求,采用如剪枝和量化等技术来降低网络的复杂度和硬件资源的需求。如本设计通过对神经网络进行剪枝,移除一些不重要的神经元和连接,以降低网络的复杂性和计算负担。再如本设计选择更小的卷积核和更小的步长,在减少卷积层的计算量的同时,也能提高图像特征的提取精度。
2.3 軟件实现
实现基于FPGA的卷积神经网络不仅需要优化硬件资源,也需要高效的软件。在本次设计中,软件的主要职责是控制硬件运行,包括卷积神经网络的流程控制、数据管理以及与硬件的接口等。(1)卷积神经网络的流程控制:本次研究使用了Python编写了卷积神经网络的控制程序,用于实现网络的前向传播和反向传播过程。该程序将各个层面的运算过程进行了封装,使得系统可以用简单的调用实现复杂的网络运算。同时,为了更好地与硬件配合,本研究还设计了一套调度策略,可以自动地根据网络结构和数据流决定各个硬件单元的运行顺序。(2)数据管理:在设计中,数据管理是由软件部分完成的。本设计使用了高效的数据结构和算法来实现数据的存储、访问和传输,包括权值、偏置以及中间结果等。在数据的存储和访问中,本设计使用了优化的数据结构和存储策略,以提高数据的访问效率和减少延迟。在数据的传输中,使用了DMA(Direct Memory Access)技术,从而实现直接在内存和硬件之间传输数据,以提高数据的传输速率和减少CPU的负载。(3)硬件接口:为了实现软硬件的协同,设计了一套硬件接口,从而让软件直接操作硬件。主要功能如硬件的低级访问,包括启动硬件、停止硬件、配置参数、读写数据等[5]。
3 基于FPGA的卷积神经网络图像识别算法测试
3.1 测试样本的选择
在基于FPGA的卷积神经网络图像识别算法测试中,本次研究选择了固定测试样本来评估网络模型的性能和泛化能力,通过与其他图像识别方法对比来验证本算法的优势。(1)在数据集选择上,选择了ImageNet数据集作为训练和测试的数据源。该数据集包含了大量的图像样本,涵盖了多个物种和类别。对于测试的目的,从ImageNet数据集中选取了包含约1 500个图片、约2万个分类的子集。(2)在样本划分上,将选取的子集进行划分,其中约70%的样本用于训练集,用于训练卷积神经网络模型的参数。剩余的约30%的样本用作测试集,用于评估模型在未见过的数据上的性能。本研究通过选择包含多个类别和丰富样本的ImageNet数据集,能够全面评估基于FPGA的卷积神经网络图像识别算法的分类准确率和性能。同时,通过训练集和测试集的划分,可以进行模型的训练和验证,并对模型的泛化能力进行评估。
3.2 测试结果
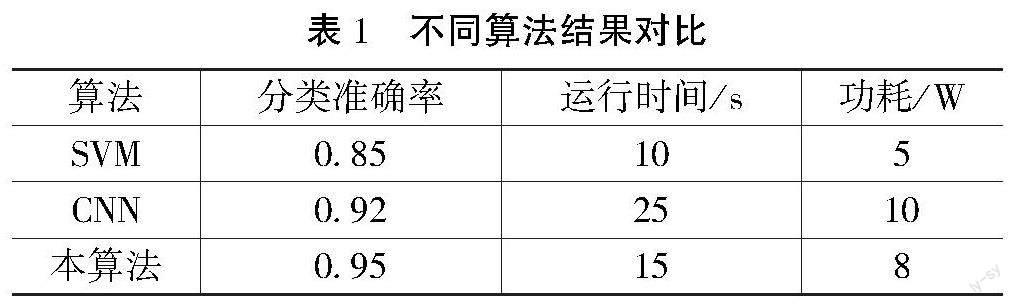
在本次图像识别测试任务中,进行了3种算法的测试结果比较,包括支持向量机(Support Vector Machine,SVM)、卷积神经网络(Convolutional Neural Network,CNN)以及本文提出的算法。如表1所示,可以看到本算法在分类准确率方面表现最好,达到了0.95的准确率,略高于CNN和SVM算法。然而,本算法的运行时间为15s,比CNN算法的25s要快,但比SVM算法的10s要慢一些。在功耗方面,本算法和CNN算法相对较低,而SVM算法的功耗最低。综合考虑分类准确率、运行时间和功耗等指标,可以初步得出结论:本算法在图像识别任务中具有较高的分类准确率,并在运行时间和功耗方面表现良好。
4 结语
本论文对基于FPGA的卷积神经网络图像识别算法进行了深入研究和实验评估。系统架构设计、硬件资源优化及实验结果分析等,展示了该算法在图像识别任务中的优势。结果表明,基于FPGA的卷积神经网络算法在分类准确率、运行时间和功耗等方面具有良好的性能。笔者希望本研究对推动图像识别技术的发展和应用做出一定的贡献。
参考文献
[1]贾亮,徐善博,邢轶博.基于FPGA的卷积神经网络图像识别算法研究[J].电脑与电信,2022(12):58-61,97.
[2]靳晶晶,王佩.基于卷积神经网络的图像识别算法研究[J].通信与信息技术,2022(2):76-81.
[3]孙文静.基于卷积神经网络DL算法的文字图像识别研究[J].长江信息通信,2022(1):50-52.
[4]邓永强,杨琼娃.卷积神经网络和CFR算法的舰船静态图像识别[J].舰船科学技术,2021(24):193-195.
[5]叶建龙,胡新海.基于卷积神经网络的图像识别算法研究[J].安阳师范学院学报,2021(5):14-18.
[6]马晓光,蒋占军.卷积神经网络图像识别算法的FPGA加速优化研究[J].兰州交通大学学报,2021(5):51-57.
(编辑 王永超)
Research on convolutional neural network image recognition algorithm based on FPGA
Cui Jie
(Shanxi Vocational University of Engineering Science and Technology, Jinzhong 030619, China)
Abstract: This paper discusses the design and implementation of the convolution neural network image recognition algorithm based on FPGA. Due to the excellent performance of convolutional neural networks in image recognition, combined with the low power consumption and high parallelism of FPGA, higher performance on embedded systems and edge computing devices is expected. Through the system architecture design, hardware resource optimization, and the software implementation of the algorithm, we successfully realize the image recognition algorithm of the convolutional neural network on FPGA. Preliminary experimental results show that the display design achieves higher processing speed and better energy efficiency while maintaining high identification accuracy.
Key words: FPGA; convolutional neural network; network image recognition; algorithm
猜你喜欢
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
现代防御技术(2016年1期)2016-06-01
