
发电机定子单相接地故障诊断模型研究与设计
2023-11-30 09:48:40汤联生许孝果张美锋乔苏朋卢应强
电气技术与经济 2023年8期
汤联生 许孝果 张美锋 乔苏朋 卢应强
(1.福建华电可门发电有限公司 2.国电南京自动化股份有限公司)
0 引言
发电机定子单相接地故障是发电机运行过程中经过长期绝缘磨损、劣化之后极容易发生的故障类型。在发电机继电保护系统中通过设置基波零序电压保护可以覆盖机端85% ~95%的定子绕组, 通过设置三次谐波保护定值则可以对中性点侧5% ~15%的定子绕组区域进行保护, 通过两者相结合则可以有效保护发电机定子绕组接地情况。但是, 值得注意的是在发电厂变压器低压侧和主变高压侧发生接地故障时, 经过变压器绕组耦合可能会引起发电机零序电压的保护误动作, 从这方面看保护具有一定的局限性。建立发电机定子单相接地故障诊断模型需要综合利用多个特征量综合判断定子接地情况,对比单一数据来源判断具有更高的可靠性。
1 设计概要
发生定子绕组接地故障对发电机的主要危害: 1.接地电流所产生的电弧会烧伤铁芯等发电机组件, 进而可能使定子绕组铁芯叠片烧结。2.大的接地电流会进一步烧毁绕组绝缘, 扩大事故面积。
正常运行中对于发电机机端三次谐波电压和发电机中性点三次谐波电压的比值为u2≤1.0。当发电机定子发生单相接地时u2会有增大情况。
当发电机正常运行情况, 发电机机端三次谐波电压和中性点三次谐波电压之间的相位差为u3∈[0°,1.5°],u3变化范围较小。定子单相接地时,u3增大。
系统分为输入模块、时间序列模块、识别故障模块、输出模块, 他们的关系如图1 所示, 以下将对各个部分分别进行详细设计。
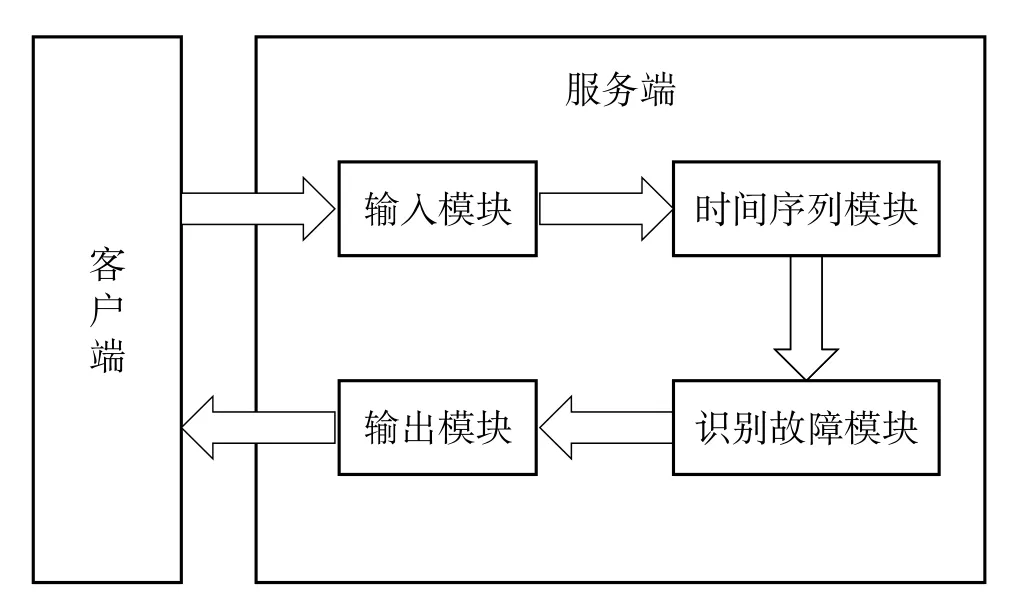
图1 模块关系
在数据交互方面, 由于JSON 所使用的字符量比XML 少很多, 输入模块使用的技术框架为Flask 框架, 有很好的扩展性, 较其他同类型框架更为灵活、轻便、安全且容易上手。A 相电流波峰与电压波峰的采样点差值绝对值u5、B 相电流波峰与电压波峰的采样点差值绝对值u6、C 相电流波峰与电压波峰的采样点差值绝对值u7后, 将JSON 数据结构的key 值抽取出来, 即u1、u2、u3、u4、u5、u6、u7, 分别对应行号0, 1, 2, 3, 4, 5, 6, 将长度为length 的key 对应的value 值抽取出来, 将新生成的数组以函数调用的方式传入时间序列模块。
时间序列模块被封装为python 函数, 时间序列模块的输入为n*length 的数组, 此模块将循环处理每一行数据, 将空缺值补齐, 同时将数组转化为字典的形式, 字典的key 也为u1、u2、u3、u4、u5、u6、u7, 但是每个key 对应的value 为列表形式, 同时, 列表长度也被设置为识别故障模块需要的时间序列长度TimeSeriesLength,此列表数据为输入的最新数据, 即从数组的每一行从后向前截取TimeSeriesLength 长度的数据并转化为列表的形式以存储在字典中对应的key 值中, 循环结束后, 将返回一个时间序列字典给识别故障模块。
识别故障模块包括两种算法, 解析法识别算法和人工智能识别算法。这两种算法都被封装为python 函数的形式, 通过调用函数的形式使用这两种算法。识别故障模块接收到时间序列字典后, 首先通过滑动窗口获取数据, 此过程第一步需要确定滑动窗口大小slide, 然后以第1 ~slide 个数据为第一个滑动窗口数据, 并以步长1 向后滑动, 得到N-slide +1 个滑动窗口数据, 在训练人工智能算法时可将所有滑动窗口数据输入以训练模型, 训练完成的模型的参数与权重将被保存到对应的pth 文件中, 在应用人工智能算法识别故障时, 只需要重新加载预训练好的模型并将最新的时间滑动窗口数据输入人工智能算法模型, 便可以实现故障识别。下面首先对人工智能识别算法使用的GRU 模型的设计与使用进行详细说明。
使用GRU 模型的原因如下, 算法识别率容易提升。当训练样本数量增加时, 算法识别率的增速仍然较大;GRU 网络非常灵活, 其结构容易调节。少量训练样本可以使用少量层数的深度学习网络; 大量训练样本可以使用大量层数的深度学习网络; 深度学习网络可以通过调节激活函数等方法来加快大样本的训练速度。
为使用GRU 网络, 需要进行数据处理, 要求数据输入是序列数据, 格式要求是(batch, time_ step,input_ size), 使用Pytorch 的nn.Module, 在初始化函数中, 可以具体定义, 在训练过程中, 根据模型的训练效果灵活调整模型参数。
模型搭建完成后, 便可以定义损失函数, 其通过计算每个预测值与对应真实值之间的差值的平方, 再求这些差值的平均值以得到模型的识别精度。
完成优化器的定义之后, 便可以进行模型的训练。在模型训练过程中, 可依据模型的训练效果动态调整迭代次数, 在训练过程中, 模型采用反向传播算法来学习网络, 反向传播算法的学习过程由正向传播过程和反向传播过程组成。依据的原理是导数的链式求导法则, 所以需要求损失函数对各参数的偏导, 在算出了对各参数的偏导之后, 就可以更新参数, 依次迭代直到损失收敛, 即小于某一个阈值。对损失函数值的计算由上文定义的损失函数进行, 在损失函数计算完成之后, 需要通过Pytorch 的zero_ grad () 函数进行梯度清零, 再通过backward () 函数完成反向传播过程, 最终通过step () 函数完成参数的更新。在每一次迭代中, 都需要重复进行损失函数的计算, 反向传播与参数更新, 同时在训练过程中, 可以观察损失函数的变化, 或采用early stopping 策略, 防止模型过拟合的发生, 使GRU 模型获得更好的泛化能力。
GRU 模式识别和GRU 模式预测都使用GRU 网络, 二者的区别在于训练样本不同。GRU 识别故障的训练样本是故障发生时的样本; 而GRU 预测故障的训练样本是故障发生前的样本。在模型训练完成后, 便可将模型参数与权重保存在相应的pth 文件中, 在应用此模型时, 便不再需要重新训练模型。
解析法识别算法主要用于识别故障位置, 此模块首先提取采样周期u4和故障波形数据u5、u6、u7, 然后计算u5、u6、u7中的最大值v, 该最大值对应相的下相就是故障相, 其次计算偏移角θ=360 ×v/u4以及计算m=n·θ/360。n为每分支匝数。m就是故障点相对中性点的匝数位置。识别故障模块最后将识别到的故障原因, 状态以及故障位置包装为字典形式, 并以此为参数调用输出模块。
输出模块的主要作用是将故障状态封装成JSON结构输出给客户端, 客户端与服务端的通信协议使用http 协议。服务端设置监听IP 地址和端口。客户端通过IP 地址和端口访问服务端。一级界面如图2 所示。

图2 一级界面
二级界面如图3 所示。

图3 二级界面
2 总体描述
协议内容主要包括输入和输出两类。
客户端输入: A 相电流波峰与电压波峰的采样点差值绝对值u5、B 相电流波峰与电压波峰的采样点差值绝对值u6、C 相电流波峰与电压波峰的采样点差值绝对值u7。
u1、u2、u3是浮点数。u4的单位是采样点数, 是整型数。u5、u6、u7是浮点数。
服务端输出: JSON 结构封装的1 个故障原因s1、1 个状态s2、1 个故障位置s3。
故障原因s1是整型数, 其数值与含义如表1 所示。
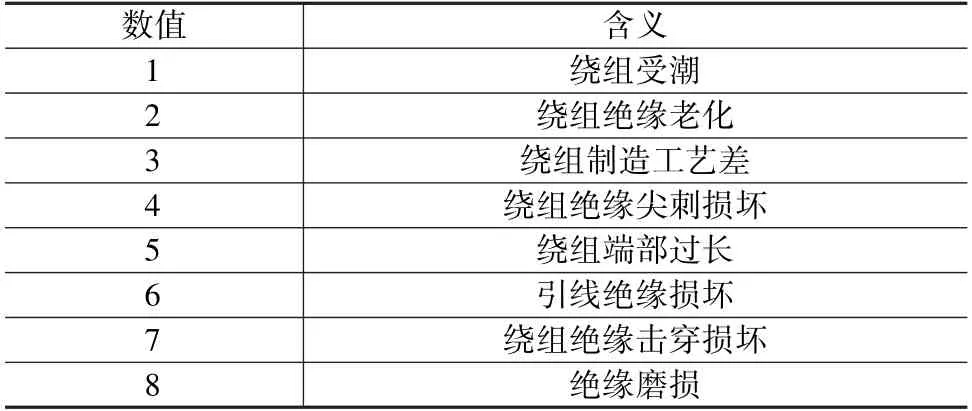
表1 故障原因的数值与含义
状态s2是整型数, 其数值及含义如表2 所示。

表2 故障原因的数值与含义
故障位置s3是故障点相对中性点的匝数位置, 其值为整型数。
3 软件功能
“输入模块”接收客户端输入, 输出解析JSON结构后的数组给“时间序列模块”。“时间序列模块”将输入数组转换成时间序列, 再输出给“识别故障模块”。“识别故障模块”输出故障原因、状态、故障位置给“输出模块”。“输出模块”将故障状态封装成JSON 结构输出给客户端。
4 运行过程
“识别故障模块”的识别流程图如图4 所示:

图4 识别故障流程图
“识别故障模块”的识别方法分为2 类: 解析法识别、人工智能识别。解析法识别使用决策树来识别故障原因和状态。解析法识别特点如下, 优点: 算法简单高效, 所需样本少, 缺点: 算法识别率不高。
5 结束语
随着科技和生产的发展, 人们对智能运行、机器自动化诊断要求越来越高。电力系统的发展使得机器自动判断应用成为迫切需求。
猜你喜欢
防爆电机(2021年1期)2021-03-29 03:02:46
水利规划与设计(2020年1期)2020-05-25 08:01:28
测控技术(2018年2期)2018-12-09 09:00:52
大电机技术(2017年3期)2017-06-05 09:36:02
军事文摘(2016年16期)2016-09-13 06:15:49
中国医药指南(2016年1期)2016-07-11 11:57:51
智能建筑电气技术(2015年5期)2015-12-10 05:52:30
Transactions of Nanjing University of Aeronautics and Astronautics(2015年2期)2015-11-24 02:39:22
电机与控制应用(2015年10期)2015-03-01 03:50:16
电力工程技术(2014年1期)2014-03-20 14:19:06
