
基于数据驱动的低压配电网故障检测方法
2023-11-29 01:16何金波陈晨辉管委玲
内蒙古电力技术 2023年5期
杨 军,何金波,陈晨辉,倪 烨,李 赟,管委玲
(1.国网浙江省电力有限公司台州市路桥区供电公司,浙江 台州 318050;2.浙江省台州市宏泰供电服务有限公司路桥分公司,浙江 台州 318050)
0 引言
目前,随着用户需求的逐渐提升,配电网规模不断壮大,配电网发生故障的概率大幅增加,对故障诊断技术提出了更高要求[1-3]。低压配电网中,低压侧的线路分支及负荷类型较多,传统的故障检修方法存在检修周期长、成本高的弊端[4-6]。如何利用现有的配电网设备降低故障检修成本、提高故障检修效率,成为保障配电网安全可靠运行亟需解决的问题[7-8]。
数据驱动在配电网故障诊断和定位方面应用广泛[9-10]。文献[11]通过监控和数据采集系统分析实际中压配电网的历史数据,对故障进行预测和诊断,但是对于不同类型的故障,诊断精度还不够高。文献[12]提出了一种基于改进Relief-Softmax算法的配电网故障风险预警方法,但对于不同的配电网,数据获取、处理方式都不同,对数据进行特征提取时还需特别考虑地域特性,应用上不够便捷。文献[13]对比分析了多种基于机器学习主流模型的故障诊断方法,但这些方法对数据质量的要求极高。文献[14]提出了基于卷积神经网络的主成分分析法,但该方法侧重于区域故障突发后的快速响应、电力客服中心的压力缓解和服务质量的提升。文献[15]对传统的粒子群算法进行改进,提高了配电网故障定位精度及抗干扰能力,但该方法的适用范围并不明确。文献[16]提出的多策略改进鲸鱼优化算法能够解决大量分布式电源接入配电网时传统算法故障定位准确度不高的问题,但该方法能否用于无分布式电源接入时配电网的故障检测尚不明确。文献[17]提出了边缘计算与集中计算协同的配电网故障检测方法,构建了考虑量测数据时滞相关性的边缘计算模型,提升了对数据异常、通信丢包等情况的耐受能力,能够降低配电网因分布式能源接入而出现的不确定性。文献[18]针对风电机组故障检测中梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法超参数难以选择的问题,利用贝叶斯超参数优化算法对GBDT中的关键参数进行了优化,提出了基于GBDT 算法的风电机组齿轮箱故障检测方法。文献[19]针对电力电子电路模式多样化、原始数据特征维度高的特点,分别利用主成分分析法和GBDT算法对输入特征进行有效故障信息提取和故障模式识别,提出了电力电子电路故障诊断方法。
随着智能电能表等智能量测装置在配电网中的大量部署,配电网数据的实时采集情况得到了很大改善[20]。智能量测装置虽然可以提高数据采集效率,但对于规模巨大、种类繁多、冗余度高的数据而言,将其直接由智能量测装置上传至配电网区域主站并不能明显提高故障检测效率。为此,可以引入边缘计算,就近处理配电网数据并进行故障诊断和信息筛选,缓解区域主站数据处理压力,提高配电网数据处理效率[21]。为此,本文基于GBDT 算法和多头自注意力机制模型提出了一种检测方法,旨在提高故障检测效率和准确率,在33 节点、0.4 kV配电网系统上的测试结果表明,该方法能够有效应用于低压配电网的故障检测。
1 算法简介
1.1 GBDT
梯度提升算法(Gradient Boosting)是提升算法(Boosting)中的一种,以决策树(Decision Tree)作为基学习器时,即为GBDT 算法。该算法在每轮迭代中沿损失函数下降最快的方向构建新学习器,并通过加法模型得到强学习器,多用于回归、分类和排序任务。加法模型如式(1)所示:
式中:x 为输入特征,即配电网输入的特征变量,如电压、电流等;M 为决策树的数量;ω为模型参数,ωm即为第m棵决策树的模型参数;hm为第m棵决策树;αm为第m棵决策树的权重;fm为第m棵加权后的决策树。
GBDT算法流程如下。
给定一个训练数据集:
式中:x∈X ⊆R ,X为实例空间;y∈Y ⊆R ,Y为标签集合;N为样本数。在配电网故障检测中,X为配电网输入的特征变量集,标签0表示未发生故障,标签1表示发生故障。
首先要进行初始化,如式(3)所示:
式中:L(yi,c)为损失函数;c为使损失函数极小化的常数值。
随后,对决策树中的每个样本进行残差计算,得到的残差作为新的数据参与下一棵决策树的训练,经过迭代后得到新的决策树[22]。第m 棵决策树的表达式如下:
式中:j=1,2,…,J为第m棵决策树叶节点的个数;Rmj为第m棵决策树的叶节点区域;cmj为Rmj范围内的最佳拟合值;I为指示函数。
将所有回归树进行叠加,得到最终模型:
GBDT可以直接构造输入特征与输出标签间隐含的映射关系。对于训练好的GBDT 模型,输入配电网实时运行数据,数据特征将决定其在每棵树上的叶节点区域,将每个叶节点区域对应的数值进行加和,即为输出的预测值。预测值接近0 则记为标签0,预测值接近1 则记为标签1,由此实现配电网故障判断。
1.2 多头自注意力机制
对于自注意力机制模型,将具有不同拓扑结构的配电网的运行数据作为输入特征时,数据与各自不同的参数矩阵W进行交互计算,最终的输出结果能够体现数据间的关联特性[23]。然而,自注意力机制模型可能会过度将注意力集中于自身,引入多头自注意力机制模型则能够结合多个单头自注意力机制模型进行并行计算,在保持计算效率的同时提高模型的表达能力和泛化性能,在一定程度上弥补了GBDT算法缺乏并行计算能力的缺陷[24]。
1.2.1 自注意力机制模型
自注意力机制将输入特征线性映射到3个不同的向量空间,并进一步得到查询矩阵Q、键矩阵K和值矩阵V。如式(6)所示:
式中:X 为输入特征矩阵;Wq、Wk、Wv分别为模型针对Q、K、V使用的权重矩阵。
将Q、K、V 输入到注意力函数中即可得到最终输出,如式(7)所示:
式中:Attention(Q,K,V )为单头自注意力机制模型的最终输出;KT为K的转置矩阵;dk为输入矩阵的维度。
1.2.2 多头自注意力机制模型
将每个单头自注意力机制模型的输出结果进行拼接,再与线性变换矩阵WO相乘,即可得到多头自注意力机制模型:
式中:headi为第i 个单头自注意力机制模型;h 为拼接数量;Mutihead(Q,K,V )为多头自注意力机制模型的最终输出。第i 个头中,代表模型针对Q、K、V使用的不同权重矩阵。
配电网的输入特征通过多头自注意力机制模型的转换与优化后,再输入GBDT 模型判断故障是否发生时,判断结果具有更高的准确性。同时,在多头自注意力机制模型优化数据的过程中,采取适当的张量操作,可以实现并行计算,在保证输入特征得到优化的同时提高计算效率。
2 基于数据驱动的低压配电网故障检测模型
2.1 低压配电网故障检测模型
以多头自注意力机制模型和GBDT 算法为核心,构建基于数据驱动的低压配电网故障检测模型。该模型包括边缘终端的边缘计算模块和区域主站的集中计算模块两部分,智能电能表采集的数据在该模型中的传输方式如图1所示。

图1 低压配电网故障检测系统数据传输模型Fig.1 Data transmission model of fault detection system for low voltage distribution network
该模型的输入特征为配电网中馈线和各分支上的电压标幺值和电流标幺值,以及各分支的三相电压标幺值和电流标幺值。故障检测流程见图2。

图2 故障检测流程图Fig.2 Fault detection flow chart
2.2 故障检测
边缘终端是配电网与区域主站之间的桥梁,结合边缘终端与配电网中部署的智能量测装置,能够对配电网中的实时数据进行快速采集和分析处理。边缘终端的边缘计算采用GBDT 算法,对智能量测装置采集的电网数据进行处理。截取一定长度的时间序列,将该时间序列的数据输入梯度提升决策树模型,即可判断配电网是否发生故障。若未发生故障,则定时将历史数据上传至区域主站;若发生故障,则立即将能够反映故障的数据上传至区域主站。
采用边缘计算对数据进行初步分析,减轻了区域主站直接处理海量数据的负担,提高了系统的数据处理效率和故障检测效率。
边缘终端用于判断故障发生与否的梯度提升决策树如图3 所示。经过模型训练后,即可得到输出结果,使用0 和1 两个标签来区分两种情况,0 代表未发生故障,1代表发生故障。

图3 用于故障检测的梯度提升决策树Fig.3 GBDT for fault detection
2.3 故障定位及故障分类
当边缘终端判断配电网发生故障时,区域主站会接收到边缘终端上传的能反映故障的数据。之后采用多头自注意力机制模型对这些数据进行预处理,为后续的故障定位和故障分类奠定基础。最后,使用故障数据训练两个新的梯度提升决策树,对配电网故障进行定位和分类。
故障定位能够精确到配电网的具体分支,通过对分支上数据的判断,确定该分支是否发生故障。用于判断故障分支的梯度提升决策树如图4(a)所示,模型输出结果中的标签0 表示该分支未发生故障,标签1表示发生故障。

图4 用于故障定位和分类的梯度提升决策树Fig.4 GBDT for fault location and classification
用于判断故障类型的梯度提升决策树如图4(b)所示,输出结果中的1、2、3 分别代表L1、L2、L3相的单相接地短路故障,4代表三相短路故障。
用于故障分类的梯度提升决策树根据故障分支上各相电压和电流间的关系来判断故障类型。配电网故障类型较多,包括接地短路、相间短路、过载、漏电等[25-30]。其中,短路故障更具有代表性,因此本文设置了单相接地短路故障和三相短路故障。
3 算例分析
本文将所提出的低压配电网故障检测方法应用于由Matlab/Simulink 环境设计的33 节点、0.4 kV低压配电网系统,该系统共有9 条分支,如图5 所示。

图5 33节点、0.4 kV低压配电网Fig.5 0.4 kV low voltage distribution network with 33-node
通过仿真一共生成了4068 个样本,其中包含1525 个故障样本和2543 个非故障样本。根据电力系统单相接地短路故障和三相短路故障的故障特征,选择网络上各个节点的三相电压标幺值和三相电流标幺值作为配电网输入的关键特征变量,设置Vthre=0.8,Ithre=1.5,并按照8:2的比例将样本集随机分为训练集、测试集。仿真结果均通过不同的故障电阻来进行测试,故障电阻取值为0.1 Ω, 0.5 Ω, 1 Ω,3 Ω, 5 Ω, 7.5 Ω, 10 Ω, 30 Ω, 50 Ω, 75 Ω, 100 Ω,300 Ω, 500 Ω, 750 Ω和1000 Ω。该模型的故障检测、故障定位和故障分类准确性均由准确率(Accuracy,Acc)来评估,准确率(式中用Acc表示)计算公式如下:
式中:T1和T2分别表示正确判断为有故障和无故障的样本数;F1和F2分别表示错误判断为有故障和无故障的样本数。
运行GBDT 算法需要设置参数,为使故障检测试验正常进行,试验中对较为重要的参数进行了优化,优化后的参数如表1所示。
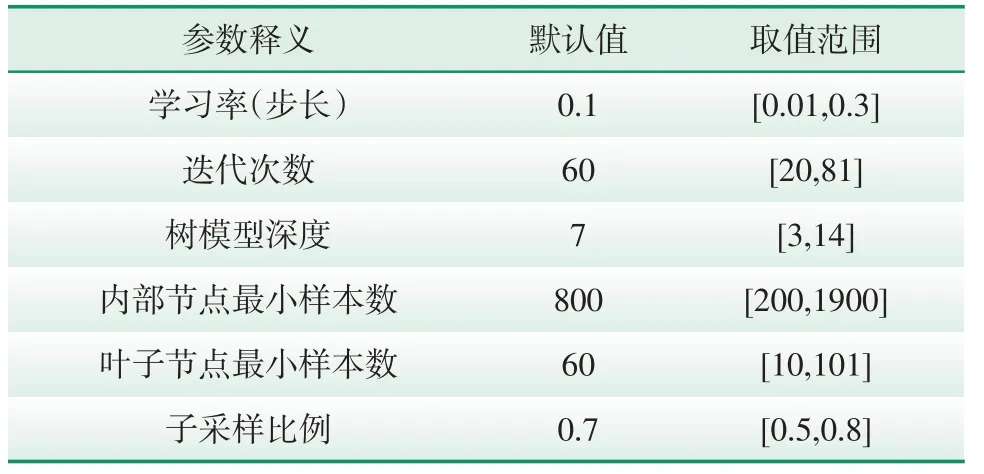
表1 GBDT的模型参数Tab.1 Model parameters of GBDT
3.1 故障检测结果分析
使用不同的故障电阻进行测试时,故障检测准确率均能达到98%以上。说明对于低压配电网故障检测,该方法在大多数情况下是有效且可靠的。
3.2 故障定位和分类结果分析
图6(a)和图6(b)分别表示使用不同的故障电阻进行测试时的故障定位和故障分类准确率。

图6 使用不同故障电阻进行测试时的故障定位、分类准确率Fig.6 Accuracy of fault location and fault classification when using different fault resistances for testing
由图6(a)可以看出,随着故障电阻的增大,故障定位准确率呈下降趋势,当故障电阻值为0.1 Ω时准确率最高,为99.8%;当故障电阻值为750 Ω时,准确率最低,为97.3%。
由图6(b)可以看出,对于低故障电阻(故障电阻值小于30 Ω,故障分类准确率基本保持在99%以上。随着故障电阻的增大,故障分类准确率虽有下降,但始终保持在较高水平,当故障电阻值为1000 Ω时,准确率为97.1%。
针对故障定位准确率,本文将所提出的方法与文献[31]中的方法进行了比较,如图7所示。从图中可以明显看出,相较于文献[31]提出的方法,本文方法的故障定位准确率高。

图7 故障定位准确率比较Fig.7 Comparison of fault location accuracy
4 结语
本文提出了一种基于数据驱动的低压配电网故障检测方法。通过边缘终端建立的梯度提升决策树初步判断低压配电网故障与否,未检测到故障时定时向区域主站上传数据,检测到故障时将能够反映故障的数据上传至区域主站。区域主站通过多头自注意力机制模型弥补GBDT算法难以并行处理数据的缺陷,增强数据间的关联性,并通过GBDT算法完成故障定位和分类。在33节点、0.4 kV配电网系统中的应用结果显示,本文提出的方法与传统方法相比具有明显的优势,能够提高故障检测效率、提升故障定位和故障分类准确率、减少在配电网计量设备方面的冗余投资,满足低压配电网故障检测的时效性和经济性要求。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
电子制作(2019年22期)2020-01-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
现代工业经济和信息化(2016年3期)2016-05-17
郑州大学学报(医学版)(2015年1期)2015-02-27
电力需求侧管理(2014年6期)2014-03-20
