
基于DeepSort的动态车辆多目标跟踪方法研究*
2023-11-29 02:31何维堃彭育辉黄炜姚宇捷陈泽辉
汽车技术 2023年11期
何维堃 彭育辉 黄炜 姚宇捷 陈泽辉
(福州大学,福州 350116)
主题词:多目标跟踪 DeepSort 自动驾驶 Haar-like SENet
1 前言
面对复杂多变的交通环境,自动驾驶汽车需不断提高对车外环境的感知能力。其中,检测与跟踪道路行驶车辆并预测其运动轨迹是环境感知研究领域的重要课题。
近年来,多目标跟踪识别网络在智能驾驶方面的应用引起了国内外学者的普遍关注[1-2],解决行驶过程中车辆的身份切换问题是本文研究的重点。在基于Deep-Sort 的研究方面,Perera 等将DeepSort 中的卡尔曼滤波替换为无迹卡尔曼滤波[3];Mu等将卡尔曼滤波替换为拓展卡尔曼滤波[4],使网络能更好地处理应用场景的非线性问题,对目标未来帧进行有效预测,但依然无法保证预测本身的准确性;裴云成将交并比(Intersection Over Union,IOU)匹配更换成广义交并比(Generalized Intersection Over Union,GIOU)[5],使网络能更有效地判断检测框和预测框之间的权重分配,但无法很好地解决特征匹配时出现失配的问题。在DeepSort网络中,重识别网络提取的深度特征用于前、后帧物体的特征匹配,在防止身份切换时能起到很好的作用。金立生等将检测器更换为Gaussian YOLO V3,并用重识别网络的中心损失函数代替交叉熵函数,提高对车辆特征的提取性能与跟踪网络的判断能力[6],但当光照发生变化时,网络无法适应环境的改变,从而导致身份切换;Wu等将重识别网络替换为ShuffleNet V2 以适用于计算能力较低的设备[7],但在复杂场景下,无法很好地提取物体的特征;Liu 等将原有的重识别网络替换为ResNet50[8],加深了网络深度,并结合特征金字塔网络(Feature Pyramid Networks,FPN)提取物体的多层特征,但复杂的网络结构增加了计算负担。
综上,复杂场景下跟踪检测目标时,跟踪器的准确性及稳定性较差,现有的重识别网络无法有效地对不同场景下的车辆进行特征提取,前、后帧中目标的匹配效果较差。为此,本文采用YOLOX 作为检测器,对基于DeepSort研究中重识别网络的特征匹配方法进行改进,添加Haar-like 特征反映车辆的光暗变化,对原有的特征匹配机制进行补充,在协调匹配速度的同时加深重识别网络层数并添加SENet 注意力机制强化提取车辆外观特征的能力,最后通过实际道路采集的视频数据集对算法的有效性进行验证。
2 多特征融合匹配
2.1 距离度量
DeepSort 是基于匈牙利算法和卡尔曼滤波算法的单假设跟踪方法,引入卡尔曼滤波对轨迹运动状态进行预测,将检测结果经重识别网络提取的特征与轨迹储存的特征共同传入匈牙利算法,进行关联匹配。在匹配过程中,对检测结果框、轨迹预测框的马氏距离及深度特征的余弦距离信息进行整合判断。
余弦距离主要用于衡量检测结果与轨迹的特征向量间的差距。对于物体被遮挡后再出现的情况,网络将轨迹中储存的特征集与物体在重新出现时的特征向量进行计算,得出其最小余弦距离:
式中,d(1)(i,j)为第j个检测框内的特征向量与第i个轨迹的特征向量之间的最小余弦距离;rj为第j个检测框内的特征向量;为跟踪器存储的第i个轨迹的特征向量集,其包含第i个轨迹过去成功匹配的k个特征向量;Ri为第i个轨迹的特征向量库。
马氏距离用于衡量上一帧中目标经过卡尔曼滤波预测的位置信息与检测结果的位置信息的差距:
式中,d(2)(i,j)为第j个检测框和第i个由跟踪器预测的物体框之间的马氏距离;dj为第j个检测框的位置信息;yi为第i个由跟踪器预测的物体框位置信息;Si为第i条轨迹在检测空间的协方差矩阵。
将基于外观特征的余弦距离和基于运动信息的马氏距离进行线性加权获得最终的度量:
式中,ci,j为最终度量标准;λ为权重系数。
交通场景中的车辆运动轨迹是非线性的,而卡尔曼滤波采用线性状态方程,因此预测能力较弱[9]。通过物体的运动状态预测出的运动信息估计量会存在一定偏差,导致马氏距离关联方法易失效,从而造成身份跳转的现象。在最终度量中设置λ=0,使马氏距离在级联匹配过程中仅为判定值。当2 个物体的对象特征一致且两者的马氏距离小于一定阈值,则判定匹配成功。
2.2 Haar-like特征匹配
自动驾驶所涉及的场景多变且复杂,在车辆的多目标跟踪中,车辆之间的相互遮蔽、场景变换、光下的阴影变换都将导致追踪目标失败。本文融合传统特征与深度特征信息,结合各自的优点解决跟踪过程中身份跳转的问题。
传统特征相较于深度特征,在精度方面的表现较差,且泛化能力不足。深度特征的提取受训练集影响较大,训练过程需要大量的场景图像数据,而传统特征的提取作为人工认知驱动的方法,具有解释性,不需要训练,且对算力的要求较低。因此,本文算法以原有的深度特征作为主要匹配依据,融合传统特征Haar-like 作为补充匹配。
Haar-like[10]是计算机视觉和图像处理中用于目标检测的特征描述算子。特征模板内有白色和黑色2 种矩形,矩形的位置关系不同,影响着所提取的特征信息,如边缘特征、线条特征、中心特征、对角线特征。通过特征模块大小的变换和在图片子窗口的移动得到所需的特征,如图1所示。其中,图片特征提取框为YOLOX输出图片,而非整张图,可明显缩短特征提取的时间。

图1 特征模块移动方式
传统特征中,Haar-like 能够表示图像像素值明暗变化信息,能更好地体现车辆行驶状态的特征[11]。在原有的DeepSort中加入Haar-like,将深度神经网络提取的车辆抽象特征与Haar-like信息相融合[12],可有效增强网络对不同场景的适应性。图2 所示为融入Haar-like 特征的DeepSort网络结构。首先,对检测器输入结果进行深度特征提取和Haar-like 特征提取。在匹配过程中,将确认态轨迹中所保留的深度特征与重识别网络提取的深度特征进行匹配,再将未匹配的轨迹和检测物体进行Haar-like特征匹配,最后进行IOU匹配。

图2 融合Haar-like的DeepSort目标跟踪算法流程
3 重识别网络的优化
车辆目标由于遮挡或未被检测,会出现与之前的目标断开联系且在短时间内重新出现在检测器中的现象。DeepSort利用重识别网络提取车辆外观信息,再将外观信息放入级联匹配。通过计算不同帧物体的外观信息的余弦距离,进行物体的相似度配对,将同一辆车重新建立联系。
车辆作为刚体,在不同视角下所呈现的姿态、大小多变[13]。在自动驾驶过程中,当检测车辆与摄像头的距离发生改变,或检测车辆处于半遮挡及转弯的状态,检测车辆的外观都会发生变化。在原网络中,重识别网络结构简单,无法准确提取行驶过程中实时变化的车辆外观信息,在重识别车辆时具有明显的局限性。
3.1 物体框尺寸的计算
无人驾驶车辆行驶过程中,对象车辆由于距离变化及遮挡的原因,其宽和高在视频中的形变量较大。经过YOLOX[14]检测器识别后,检测器会将车辆的物体框传入追踪网络。重识别网络对车辆特征进行提取的过程中,需要重新调整图像大小。原网络中定义了图片的高为128,宽为64,适用于对行人的特征提取,但无法满足对车辆的特征提取[15]。为避免过大幅度地调整图片的高和宽,导致识别误差,应寻找合适的车辆物体框的高和宽。
本文在自制的道路数据集上进行标注,截取视频中不同场景下(无遮挡、被其他车辆、树木和路障等遮挡)不同车型(挂车、皮卡和轿车等)大小及形态不同的物体框,对识别的物体框的宽和高进行均值处理,求得最优的物体框尺寸为高96、宽128。
3.2 重识别网络加深
在重识别网络中,提取的语义信息随着卷积层数的加深而越来越明显。加深网络层数,会带来更加强大的非线性表达能力和复杂的变换,使提取的信息愈加复杂、抽象[16]。在特征提取网络中,底层网络会提取物体的边缘信息,较深层的网络会提取物体的纹理特征,更深层的网络则会提取目标的形状,能更好地表达车辆的整体信息。原始的重识别网络由6个残差网络组成,最后的特征维度为128。广泛应用于行人的重识别网络由8个残差网络组成,特征维度为512,增加了特征维度使得分类更加细致,但其仍无法进行复杂情况下的车辆特征提取。为了提取车辆更深层次的信息,以满足实际行车中的追踪要求,本文在保证其时效性的同时加深了网络的深度[17],称为ResNet13,网络结构如表1所示。

表1 ResNet13网络结构
4 重识别网络融合SENet
SENet[18]在通道维度上增加1个注意力机制,并利用损失函数的自我学习,调整不同通道维度的特征权重,增大有效特征通道的权重。根据SENet所提供的各特征通道的重要程度,网络能自主地关注重要的特征通道。其包括挤压、激励和特征重标定3个部分,如图3所示。

图3 SENet结构
挤压是将不同特征通道数(c)的特征图集的全局信息嵌入,聚合成c×1×1的特征描述符。在不同特征通道数的特征图集中加入SENet,将网络中的特征图集聚合成32×1×1、64×1×1、128×1×1、256×1×1、512×1×1的特征描述符。在不同层次上获得每个特征图集的全局描述符:
式中,zc为特征图挤压聚合得到的特征描述;uc为特征图;w为特征图的宽;h为特征图的高。
获取不同深度的特征描述符后,激励通过2个全连接层获取通道间的关系,再经由Sigmoid函数转化为不同网络深度(32、64、128、256、512)下每个通道的权重值:
式中,s为所有特征图的权重集;σ为Sigmoid函数;δ为线性整流(Rectified Linear Unit,ReLU)函数;W1为第1 个全连接层操作;W2为第2个全连接层操作;z为所有特征图挤压聚合所得的特征描述符集。
最后,特征重标定将激励获得的通道权重逐通道加权到不同深度的原始特征图通道上,减小不重要的特征图的权重,提高包含重要分类信息的特征图权重:
式中,为特征图与对应权重相乘得到的特征图;sc为特征图的权重。
ResNet13采用残差块结构[19],将输入的X与由多个卷积级联输出的F(X)相加。残差结构作为小型网络,X为输入的观测值,H(X)为输出的残差网络的预测值,F(X)为观测值与预测值之间的差,即残差。该网络结构有利于保护信息的完整性,且在加深网络层数的同时,能有效解决梯度消失和梯度爆炸的问题。在ResNet13中,随着网络层数的增加,特征图的深度不断扩张。将SENet加入残差网络中,可以对网络中不同深度的特征图进行重构,如图4所示。

图4 残差网络结合SENet结构
5 试验
试验采用开源的PyTorch 1.6.0 深度学习框架,CPU配置为Intel®Aeon®Silver 4108,主频1.80 GHz,显卡为GeForce GTX 1080Ti,内 存容量为64 GB,系统为Ubuntu16.04 LTS,包含Python 3.7、CUDA 10.1、CuDNN 7.6.5、OpenCV 4.4.0 环境。数据集的采集设备为长虹CXC-X6行车记录仪。
5.1 重识别网络训练
将ResNet13 和SENet 应用于复杂场景下对车辆特征的提取,以VeRi-776[20-21]数据集训练所得的准确率(Accuracy)和损失(Loss)为基准判断算法的质量。对重识别网络进行数据集的训练时,为保证数据的准确性,3组网络训练采用相同的参数:学习率为0.001,经过20代(epoch),学习率乘以0.1。
准确率是用于对重识别网络训练效果进行度量的主要指标,计算重识别模型正确分类的样本数与总样本数之比,本文利用误差(Error)对准确率进行表达。图5展示了原网络6 层残差网络、8 层残差网络,以及ResNet13并加入SENet网络预测期间的误差曲线。

图5 误差对比
误差公式为:
式中,α为误差率;TP为真正例数量;TN为真负例数量;FP为假正例数量;FN为假负例数量。
损失函数用于表达实际输出和期望输出之间的差值,使网络更新模型参数,减小误差。图6 展示了原网络6 层残差网络、8 层残差网络,以及ResNet13 并加入SENet网络预测期间的损失。

图6 损失对比
损失公式为:
式中,q(xi)为实际输出的各类别的概率分布;p(xi)为期望输出各类别的分布;n为类别总数;H(p,q)为交叉熵损失。
图5 和图6 中,原始网络的6 层残差网络与本文的重识别网络都进行850代的训练对比。在2个网络训练到第80代时,误差和损失都迅速减少,随后下降速度逐渐减缓,直至第200 代时趋于平稳。但原始网络在第200 代后,训练的模型精度较差,波动较为明显。在经历850代训练后,误差和损失依然不理想,误差为0.55,损失为2.35。本文网络在训练过程中比原始网络更加平稳,误差和损失也更加精确,误差为0.03,损失为0.16。因此,本文网络在车辆外观提取方面,比原始网络具有更好的性能。
5.2 跟踪算法试验
分别采用DeepSort 的原始版本和本文改进的版本对车辆进行追踪,利用车辆在不同场景(城市、乡村)下的视频集进行试验,验证算法的可行性。本文的试验场景为自制的双车道的来往车辆视频,包括城市和乡镇,具有一定的普遍性。
图7所示为原始网络在数据集中前、后帧的变化情况。由图7可知,身份标签为10的车辆在视频中发生了身份跳转。

图7 原始网络的前、后帧变化
图8所示为添加Haar-like特征匹配网络后,试验的前、后帧变化情况。当车辆处于视频的远端角落时,会发生形变及特征不清晰的情况。原始重识别网络提取的深度特征不足以应对复杂的车辆行驶情况,从而发生身份跳转。添加Haar-like特征匹配网络以提取目标车辆的光暗变化,从而实现对原始网络在深度特征匹配之后的补齐。将深度特征无法匹配的车辆进行Haar-like特征再匹配,抑制了身份跳转的发生。

图8 添加Haar-like特征匹配网络的前、后帧变化
图9所示为原始网络在数据集中前、后帧的变化情况。车辆失去识别后再次出现时,身份标签为3的车辆发生了身份跳转。

图9 原始网络的前、后帧变化
图10所示为改进后的ResNet13以及添加了注意力机制网络后,视频前、后帧的变化情况。在相同视频帧下,车辆的身份并没有发生切换;在车辆处于半遮挡状态时,ResNet13可提高网络对车辆的特征提取效果。结果表明:SENet 可自动学习到不同通道特征的重要程度,注意力机制提高了目标特征的权重,使网络专注于信息量大的通道特征,减弱不重要信息的通道特征,将ResNet13与SENet相结合可达到更好的匹配结果。

图10 加深网络和加入SENet的前、后帧变化
5.3 追踪结果测试与分析
采用多目标跟踪精度(Multiple Object Tracking Accuracy,MOTA)、平均数比率IDF1(Identification F1)和帧速率3 个评价指标对跟踪算法进行评估。MOTA衡量了跟踪器在检测物体和保持轨迹时的性能,相比IDF1更专注于检测器的性能。IDF1用于判断跟踪器在视频中长时间地对同一事物进行准确跟踪的能力,着重于计算物体的初始身份号码占其在视频中出现的所有身份号码的比例。帧速率反映了处理速度。对比算法的评价结果,如表2所示。
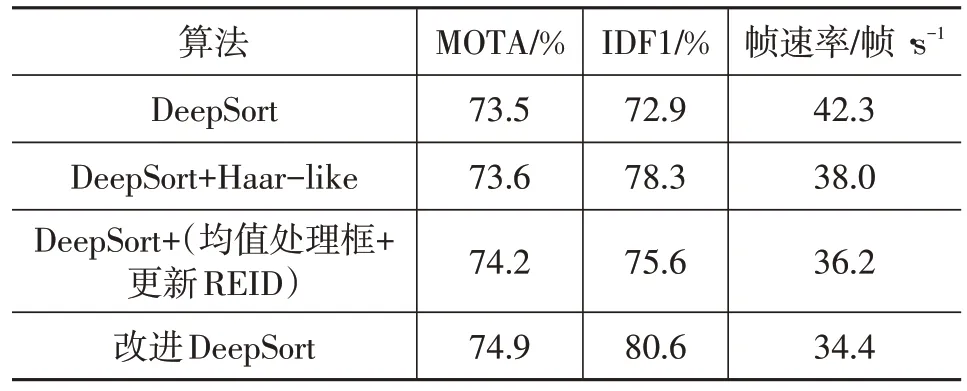
表2 评价结果
由表2可知,在跟踪网络中加入Haar-like特征且对重识别网络进行改进,可有效提升跟踪网络的效果。
6 结束语
本文针对自动驾驶汽车,面向外界动态车辆多目标跟踪的场景,提出以YOLOX 为前端检测器的DeepSort改进算法,利用Haar-like 算法提取车辆的光暗变化特征,实现对网络原有匹配机制的补充。此外,通过ResNet13 网络对重识别网络进行更换、添加注意力机制,从而提高重识别网络对车辆深度特征的提取能力。采用实际道路驾驶采集的视频数据,对本文算法和传统算法进行对比验证,结果表明:相较于传统DeepSort 算法,改进后算法的MOTA 提高了1.4 百分点,IDF1 提升了7.7百分点。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
中学生数理化·高一版(2020年1期)2020-02-20
自动化学报(2019年6期)2019-07-23
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
科普童话·百科探秘(2015年4期)2015-05-14
