
基于改进YOLOv7 的果园行间导航线检测
2023-11-26 10:12:38彭书博陈兵旗李景彬范鹏宣刘翔业邓红涛张雄楚
农业工程学报 2023年16期
彭书博 ,陈兵旗 ※,李景彬 ,范鹏宣 ,刘翔业 ,房 鑫 ,邓红涛 ,张雄楚
(1. 中国农业大学工学院,北京 100083;2. 石河子大学机械电气工程学院,石河子 832003)
0 引言
在农田作业中,自动导航技术的发展给工作人员带来了便利,作业效率相对提升,农作物产量也随之增加[1]。20 世纪90 年代以来,国内外学术刊物上有较多的科研成果,主要集中在机器视觉导航方面;20 世纪90 年代中后期,国内外对农田导航的研究多集中在GPS(global positioning system)导航系统;经过20 多年的发展,全球高精度GNSS(global navigation satellite system)农田导航技术已日趋成熟,但其主要应用于无作物耕地的导航[2],而对于果树等被叶片严重遮盖的农田,由于卫星信号的丢失而造成定位精度下降。随着数字照相技术和计算机技术的快速发展,当前的视觉导航不仅具有更低的硬件成本,而且能够应用于耕作、播种、插秧、植保等农事活动,是农田作业机械实现自动导航的一个重要研究方向[3-5]。
本课题组前期对不同农田作业条件下的导航路径识别方法的研究,为本课题的实施提供了理论基础、技术储备与应用经验。CHEN 等[6]开发了一种水稻自动插秧机引导系统,对田端田埂和幼苗行列进行提取,并且可以检测出行列和田间的末端。赵颖等[7]提出了一种改进的哈夫变换(Hough transformation)方法,求得所有方向上的候补点连接已知点斜率的最大值,经过转化得到导航线斜率。张红霞等[8]根据农田图像特点,采用K均值聚类算法(K-means)实现农作物与背景的分离,并通过定位点的位置信息对定位线进行提取。李景彬等[9]先对图像进行滤波处理,再对第一帧图像寻找候补点群、非第一帧图像与前帧关联寻找候补点群,最后通过已知点Hough 变换完成棉花种植生产过程中的导航路线自动提取。彭顺正等[10]针对矮化密植枣园环境,提出“行阈值分割”和“行间区域”方法,将目标和背景分离,并对行间噪声进行消除,准确定位了主干与地面的交点。张雄楚等[11]提出在灰枣枣园中将像素值为0 的像素坐标平均值作为Hough 变换的已知点坐标进行导航,在骏枣枣园中将每行像素上R(red,R)分量值最小的像素点平均值作为Hough 变换的已知点坐标进行导航。以上研究都是基于色彩变换的传统图像处理技术,在特定的农田环境有适用性,但对果园的适应性较弱。
神经网络是一种非常有效的学习方法。该算法能够充分考虑不同场景下的真实农业场景,具有较强的抗干扰能力,能够很好地应对光照、阴影等干扰,如今被广泛地应用到各个领域。吴伟斌等[12]在金字塔场景解析网络(pyramid scene parsing network,PSPNet)的基础上构建了MS-PSPNet 语义分割模型,对山地果茶园道路进行分割识别。韩振浩等[13]使用U-Net 语义分割算法获取到路径拟合点,接着对拟合点进行多段拟合,最终形成导航路径。YU 等[14]研究了5 种基于深度学习的机器视觉方法在不同野外场景下用于导航线的提取,并成功部署在系统上。LIU 等[15]将基于卷积神经网络(convolutional neural networks,CNN)的Faster R-CNN(faster region convolutional neural networks,Faster R-CNN)和SSD(single shot multiBox detector,SSD)目标检测模型应用于稻田幼苗的识别和定位,以定位点进行拟合提取导航线,结果表明,Faster R-CNN 精度更高但SSD 速度更快。张勤等[16]介绍了一种利用 YOLOv3 对水稻幼苗进行目标提取的方法,通过对幼苗图像进行灰度化、滤波,提取到幼苗的特征点,对特征点进行最小二乘法进行苗列中间线的拟合。以上所研究的深度学习算法能够有效地解决一些应用场景中传统图像处理算法难以处理的问题。
苹果一般采用宽行距、窄株距的种植模式[17],果园环境复杂多变,导致果园内的光照和阴影呈现出非均匀分布的特点,传统图像处理技术普适性较差。视觉导航参照点的选择是获得正确导航线的关键[18],果树树干根部中点位置是一个重要的特征点。在苹果树生长期间,果树根部易被杂草等遮挡,造成果树根点提取不准确。
本文提出一种基于 YOLOv7 改进的果树树干检测算法,利用该模型获得矩形边框的底部中心坐标,并将其作为定位参照点,通过最小二乘法对两侧果树行线和导航线进行拟合,以实现导航路径的精准规划。
1 YOLOv7 模型
YOLOv7 网络结构主要由3 个部分组成,即输入端(Input)、主干网络(Backbone)、检测头网络(Head),在检测速率5~160 帧/s 范围内,该模型在速度和精度上有较大的优势[19]。输入部分通常为640×640×3 尺寸的图像,经过预处理输入到主干网络中。主干网络在YOLOv5 的基础上引入 ELAN(efficient layer aggregation networks)结构和MP1(max pooling,MP1)结构,结合CBS 模块对输入的图像进行特征提取。其中,CBS 模块由卷积(convolution)、标准化(batch normalization)、激活函数(SiLU)组成,ELAN 结构由多个CBS 模块进行堆叠,MP1 结构则通过最大池化层和卷积块双路径分别对特征图进行压缩。检测头网络由SPPCSPC(spatial pyramid pooling,cross stage partial channel)结构、引入ELAN-H 和MP2 结构的特征提取网络以及RepConv 结构组成。由主干网络输出的3 个特征层在检测头网络得到进一步训练,经过整合输出3 个不同尺寸的预测结果,实现对目标的多尺度检测。
2 YOLOv7 网络改进
YOLOv7 模型对尺度较小或低分辨率的目标信息识别能力不足,容易出现漏检和误检的情况。而在果园图像中,靠近相机的物体会占据更多的图像空间,离相机较远的物体图像空间占据少,看起来更小,这种“透视效果”对于果树行远处的目标树干检测提出了更高要求。另外,本文以矩形框的底边中点坐标作为果树定位参照点,矩形框的准确性对导航线的提取至关重要,因此提升矩形框的置信度以及准确度,可以有效提高导航线的精度。
改进YOLOv7 结构如图1 所示。本文首先在YOLOv7检测头网络中引入CBAM 注意力机制,以提取苹果树干的关键特征信息,同时抑制树干背景噪声对检测目标的干扰,增强模型对目标的识别能力,然后在ELAN-H 模块和Repconv 模块间增加一个针对低分辨率图像和小目标的 CNN 模块SPD-Conv,以替代甚至消除卷积步长和池化层带来的负面影响,提高模型对低分辨率和小目标的检测能力。
2.1 CBAM 注意力机制
为有效降低果园复杂环境的干扰,提升树干识别检测模型的鲁棒性,本文在YOLOv7 的检测头网络中引入CBAM 注意力机制,和SENet(squeeze-and-excitation networks)[20]只关注通道的注意力机制不同,它包括通道注意力模块(channel attention module)和空间注意力模块(spatial attention module)两个部分。
通道注意力模块用于计算每个通道的重要性。通过最大池化和平均池化对特征图空间向量进行池化操作,将池化结果输入到多层感知机(shared multi-layer perception,Shared MLP)模型中,通过Sigmoid 函数生成通道注意力权重向量,从而更好地区分不同通道之间的特征。
空间注意力模块用于计算每个像素在空间上的重要性,更好地捕捉图像的空间结构。空间注意力机制将通道注意力模块得到的特征图作为输入,对其在空间维度上进行最大池化和平均池化操作,然后进行卷积操作,并通过Sigmoid 函数将其归一化到[0,1]的范围内,最后与通道注意力模块得到的特征图进行内积运算,得到最终的特征图。
通道注意力和空间注意力的组合,使得网络能够更加准确地捕捉到目标的重要特征,提高网络的表示能力和泛化能力[21],从而实现对树干关键特征的高效提取和特征增强,削弱环境背景干扰。
2.2 SPD-Conv 模块
在苹果树干图像中存在着一些小目标,这些小目标分辨率较低,特征学习受限;同时大目标通常主导特征学习过程,致使小目标无法检测到。传统CNN 架构使用跨步卷积和池化层跳过具有大量冗余像素的信息,但在图像分辨率低和小目标识别任务中存在细粒度特征损失从而导致学习特征困难[22]。如图1 所示,在YOLOv7 目标检测模型检测头网络的ELAN-H 模块后引入SPDConv 模块可有效提升对低分辨率小目标的检测能力,减少漏检、误检现象。
SPD-Conv 主要由一个SPD 层和一个非跨步卷积构成。当比例因子为2 时,在SPD 层部分,给定原始特征图X尺寸为s×s×c1(s代表特征图的长和宽,c1为特征图的通道数),通过切片得到4 个子映射,它们的尺寸均为(s/2,s/2,c1),沿着通道维度将这些子特征映射连接起来,从而得到一个特征映射X′,它的空间维度减少了一个比例因子,通道维度增加了一个比例因子,尺寸为(s/2,s/2,4c1)。在SPD 特征转换层之后,为了尽可能地保留所有的判别特征信息,添加一个具有c2通道数的无卷积步长层,其中c2<4c1,特征图尺寸变为(s/2,s/2,c2)。
3 试验与结果分析
3.1 数据采集及预处理
数据集采集于北京市昌平区的北京兴寿农业专业合作社,果园内果树树形为纺锤形,种植行距约3.5 m,株距约2.5 m。数据集由PCBA-P1080P 工业摄像头进行采集,拍摄时水平手持摄像头,置于两行果树中央,距离地面1.5 m 左右,缓慢向前移动,并采集摄像头正前方的图像,包括不同光照亮度下的苹果树行间信息。共采集视频28 条,平均时长在30 s 以上,对视频进行抽帧处理,得到数据集共1 588 张。将数据集进行划分,得到训练集1 264 张、验证集158 张、测试集158 张,使用LabelImg 进行标注,标签设置为tree。将完整的树干标定在矩形边框内,1 588 张图像所标记的苹果树干为11 043 个。图像标定完成后,所生成的标签以xml 文件保存,文件中包含了标签类别和矩形边框的左上角和右下角坐标。
3.2 试验环境与评价指标
试验采用台式计算机,处理器为Intel(R)Core(TM)i5-12 400 2.50 GHz,内存为16 GB,GPU 为NVIDIA GeForce RTX 3 070,运行环境为Windows10(64 位)操作系统,配置深度学习环境为Python=3.7.12+torch=1.7.1+torchvision=0.8.2,CUDA 版本为11.0。在训练过程中,对网络模型使用随机梯度下降法(stochastic gradient denset,SGD)进行学习和更新网络参数[23],并采用余弦退火的学习率衰减方式,设定的部分超参数如表1 所示。
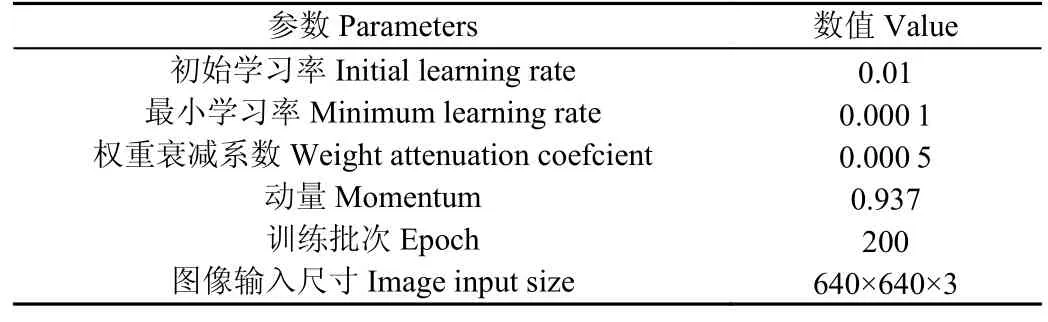
表1 网络训练超参数Table 1 Network training hyperparameters
本文采用准确率(precision,P)、召回率(recall,R)、精度均值(average precision,AP)参数量(parameters,Params)和画面每秒传输帧数(frames per second,FPS)来共同对改进模型进行评价[24]。其中准确率指模型正确预测为正的占全部预测为正的比例,召回率指正确预测为正的占全部实际为正的比例,参数量代表模型的空间复杂程度,每秒传输帧数评价模型的识别速度。相关计算式如下:
式中TP 为准确识别出树干的数量,FP 为非树干被检测为树干的数量,FN 为未检测出树干的数量。
3.3 试验结果分析
为验证本文改进YOLOv7 模型的优势,将其与Faster R-CNN、YOLOv7、YOLOv5、YOLOv4 进行对比。在相同的硬件条件、数据集和试验参数下,试验结果如表2 所示。可以看出,改进后的模型检测精度比Faster R-CNN、YOLOv7、YOLOv5、YOLOv4 分别高11.5、2.31、4.02、13.87 个百分点;检测速度相对于YOLOv5、YOLOv4 较低,但高于Faster R-CNN 和原始YOLOv7 模型,满足实时检测的需要;在参数量方面,改进YOLOv7 模型相比较原始YOLOv7 模型有一定增加,但远低于Faster R-CNN、YOLOv5、YOLOv4 模型。综合比较,改进后模型在苹果树干识别方面有较大的优势。

表2 不同模型试验结果对比Table 2 Comparison of different models test results
为进一步验证本文改进YOLOv7 模型中各改进方法的有效性,对同一数据集以原始YOLOv7 模型为基础进行消融试验,试验设置参数与表1 相同,试验结果如表3 所示。在检测头网络引入CBAM 注意力机制模块,优化了网络结构的特征融合能力,减小了图像中背景的干扰,增强目标果树的关键特征;同时引入SPD-Conv模块,提高对低分辨率图像和小物体的识别效果,降低模型错检、漏检率。如表3 所示,原始YOLOv7 模型精度为92.9%,引入CBAM 注意力机制模块后模型精度为93.97%,比原始YOLOv7 模型提升了1.07 个百分点,本文算法精度达到了 95.21%,比引入 CBAM 注意力机制模型提升了1.24 个百分点,检测速度提升了4.85 帧/s。

表3 消融试验结果Table 3 Ablation experiment results
3.4 检测结果对比
为验证本文改进算法对树干识别的有效性和通用性,对原YOLOv7 模型和改进YOLOv7 模型的检测效果进行比较,如图2 所示。可以看出,对于场景1,原YOLOv7模型漏检了右前方的一棵苹果树,且图像左下角这棵树的目标框标记不太准确,改进YOLOv7 模型则没有出现这些问题;对于场景2,原YOLOv7 模型漏检了远处特征不明显的一颗小树,改进YOLOv7 模型则检测成功且更为准确;场景3 中枣树较密,原YOLOv7 模型识别数量少,改进YOLOv7 模型识别出大多数树干。试验结果表明,改进后的算法在苹果园以及枣园环境中能够更有效更准确地检测出目标。此外,改进YOLOv7 模型输出的置信度值通常更高,这说明改进后的网络检测能力更强,更能关注目标的特征信息。

图2 果树树干检测效果对比Fig.2 Comparison of fruit tree trunk detection results
4 导航线检测
4.1 定位参照点的获取
定位参照点的正确提取对于获得果园内导航线至关重要[25]。苹果树干与树冠在横向面积上相差较大,且树枝向外部延伸长短不一,导致树干中心点横坐标与树冠不同,另外果树在种植时一般以树干根点作为定位成行的基点,若以整棵树的中心作为定位参照点,导航线误差较大,因此选择以苹果树干根部中心作为定位参照点。
通过YOLOv7 训练可得到目标树干的矩形边框坐标,进而得到苹果树干的中心坐标。设矩形边框的左上角坐标为(x1,y1),右下角的坐标为(x2,y2),苹果树干根部中心坐标(x,y)可以表示为
对图2 中3 个场景进行定位参照点提取,结果如图3 所示,提取到的定位参照点用黄色标记点表示,红色标记点为人工标记树干中点。

图3 人工标记树干中点与定位参照点提取结果Fig.3 Extraction results of manual marking of trunk midpoints and locating reference points
4.2 定位参照点误差分析
在测试集中随机抽取100 张图像共计769 棵苹果树干进行定位参照点的误差分析,以验证本文选择定位参照点的效果。如图4 所示,可以看出横向误差和纵向误差大都集中在10 像素以内,横向误差在10 像素以内的有750 棵,占比97.5%,纵向误差在10 像素以内的有758 棵,占比98.5%,平均直线误差为4.43 像素。
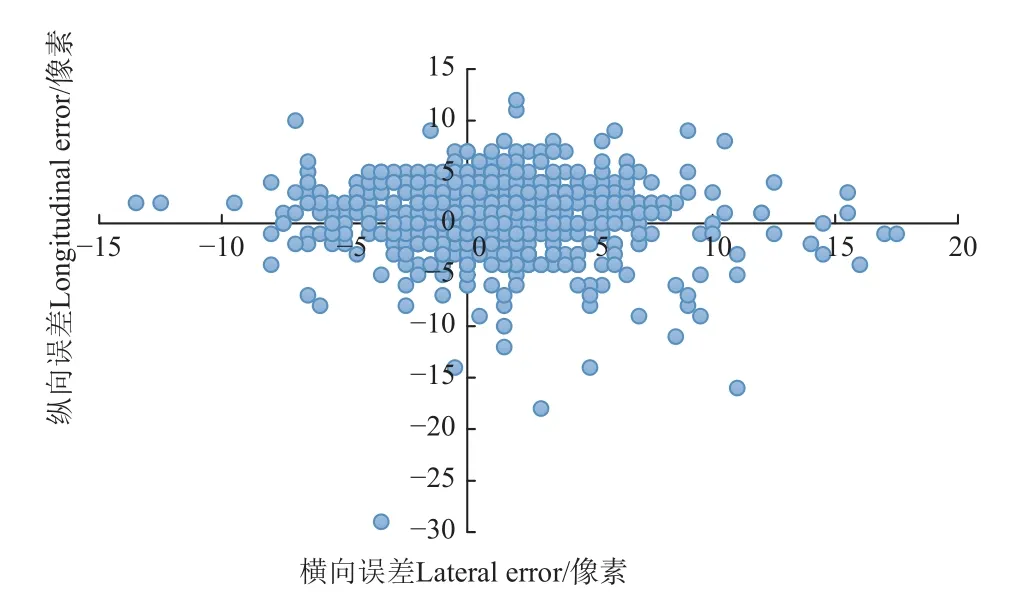
图4 人工标记树干中点与定位参照点像素误差Fig.4 Pixel error between manual marking of trunk midpoints and locating reference points
对相机进行标定,使用Matlab 软件得到相机的内参矩阵,通过计算将像素坐标转换成相机坐标[26]继而求出定位参照点与人工标记树干中点的实际平均误差为8.85 cm,证明本文以矩形边框底部中点代替树干根部中点作为导航线定位参照点的有效性。
4.3 导航线拟合
导航线拟合算法常用的有三次样条插值[27]、Hough变换[28]和最小二乘法[29]等。三次样条插值曲线每两个坐标点之间都需要拟合一组参数,复杂度较高;Hough变换和最小二乘法都可以用于本研究导航线的拟合,但是由于目标点较少,最小二乘法相对简单快速,因此本研究选择以最小二乘法进行导航线的拟合。
最小二乘法的拟合原理是:给定一系列(xi,yi),(i=1,2,3…N),假定x和y具有线性关系,即可以用y=Kx+B的方式进行拟合。定义一个优化函数,为了避免正负相消,使用实际观察值与拟合值之间的差的平方和来定义:
当f最小时,拟合效果最好,此时的K和B值为最优参数。
在获得左右两列苹果树干的定位参照点坐标后,进行果树行线的拟合。设单侧树干生成的20 个定位参照点坐标为 (Xi,Yi),i=1,2,3,···m(Xi,Yi),i=1,2,3···20,通过最小二乘法对其进行拟合,得到两侧果树行线如图5所示。在得到的两侧果树行线上分别在垂直方向上等间隔取20 个点,坐标记为(Xl,Yl),l=1,2,3…20;(Xr,Yr),r=1,2,3…20;将这左右各20 个点的x、y坐标分别对应求取平均值,可以得到位于两侧果树行线中间的导航拟合线的20 个定位点,其坐标为(Xp,Yp),p=1,2,3…20,表达式为
对定位点进行最小二乘法计算,得到拟合导航线如图6 中的黄色线段所示。图中红色线段为人工观测导航线,是对两侧果树人工标记树干中点进行对应求取平均值,再通过最小二乘法得到的。

图6 拟合导航线和人工观测导航线Fig.6 Fitting navigation line and manual observation navigation line
4.4 导航线提取精度分析
为分析拟合导航线与人工观测导航线的误差,引入偏差Xo,指人工观测导航线的中点与拟合导航线中点的横向像素距离。
对测试集中随机抽取的100 张图像进行分析,得到Xo的统计结果,如图7 所示。结果显示,偏差均小于7.88 像素,平均偏差为2.45 像素,实际平均偏差为4.90 cm,满足苹果园内导航的精确度要求。
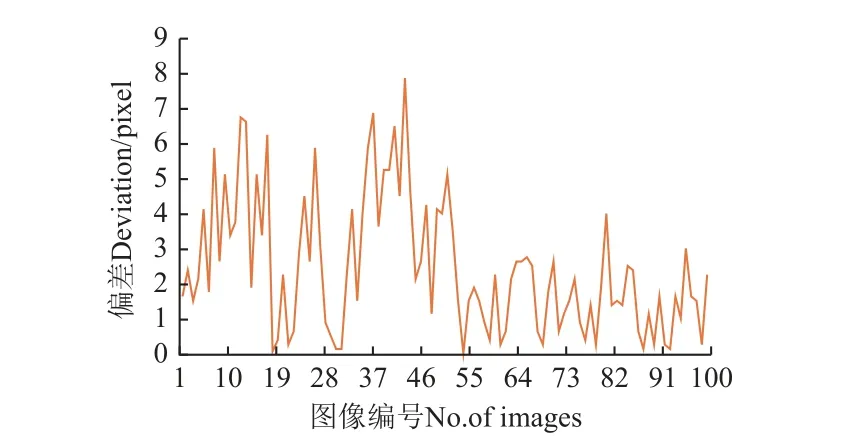
图7 导航线偏差分析Fig.7 Navigation line deviation analysis
4.5 导航线检测速度分析
对导航线检测速度进行分析,读入在不同光照条件下拍摄的3 条视频,并记录视频帧数。在处理程序中设置计时器,对程序开始和程序结束时间进行记录。完成对读入视频的导航线检测之后,用程序结束的时刻减去程序开始的时刻,即为视频处理时长。将视频处理时长除以视频帧数,得到处理1 帧图像的平均耗时。如表4 所示,3 段视频平均耗时分别为0.047、0.040 和0.044 s/帧,总平均耗时为0.044 s/帧,满足苹果园内导航的实时性需要。

表4 导航线提取速度分析Table 4 Navigation line extraction speed analysis
5 结论
本文提出一种改进YOLOv7 模型,在模型的检测头网络加入CBAM 注意力机制模块,使卷积神经网络能够去注意图像中的特殊的和重要的信息;同时引入了SPD-Conv 模块,使模型更适合处理低分辨率图像。使用改进YOLOv7 模型,可以更精确地获得果树树干的坐标信息,进而通过最小二乘法拟合导航线。结果表明本文所研究方法检测出的拟合导航线和人工观测导航线误差较小,可以满足导航的需要。本文获得了以下主要结论:
1)改进模型在兼顾检测速度的同时有效提升了检测精度,且在苹果园和树干密集的枣园中都适用。原始YOLOv7 算法精度为92.9%,改进后的YOLOv7 算法精度为95.21%,减少了在检测过程中出现的误检、漏检等情况。
2)采用矩形边框的中点代替树干根点作为定位参照点,对测试集中抽取的100 张图像中的769 棵树干进行误差分析,结果显示横向误差在10 像素以内的占比为97.5%;纵向误差在10 像素以内的占比为98.5%,证明了矩形边框的中点代替树干根点的可行性。
3)通过对定位参照点进行最小二乘法计算得到拟合后的导航线。对测试集中抽取的100 张图像进行导航线误差和速度分析,以拟合导航线的中点和人工观测导航线中点的横向像素距离作为依据,结果显示偏差在7.88个像素以内,平均偏差为2.45 像素,实际平均偏差为4.90 cm,处理1 帧图像平均耗时为0.044 s,证明本文所采用提取导航线的方法具有较高的精确度。
猜你喜欢
小猕猴智力画刊(2023年4期)2023-10-10 10:00:33
今日农业(2022年1期)2022-11-16 21:20:05
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
军事文摘(2021年16期)2021-11-05 08:49:16
今日农业(2020年23期)2020-12-15 03:48:26
传媒评论(2017年3期)2017-06-13 09:18:10
小猕猴学习画刊(2017年1期)2017-02-17 16:04:14
小猕猴学习画刊(2017年1期)2017-02-17 15:57:35
广东第二课堂·小学(2016年11期)2016-12-06 14:29:33
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
