
基于AGConv 局部特征描述符的点云配准
2023-11-18 03:32张文丽任密蜂续欣莹阎高伟
计算机工程 2023年11期
张文丽,程 兰,任密蜂,续欣莹,阎高伟,张 喆
(太原理工大学 电气与动力工程学院,太原 030024)
0 概述
点云配准问题是估计最佳刚性变换矩阵的问题,旨在将两个具有重叠部分的3D 点云对齐到同一坐标系。点云配准任务是三维重建[1]、自动驾驶[2]以及同时定位与建图(Simultaneous Localization and Mapping,SLAM)[3]中的重要环节,然而在真实场景中使用点云配准也存在一定的挑战,主要因为不同场次扫描的点云之间存在密度变化、有噪声、有遮挡的问题,并且点云数据是无序、不规则和稀疏的,所以在真实数据中提高算法配准精度和鲁棒性是非常必要的。
根据数据转换方式的不同,在点云上进行学习可以分为基于体素、多视图和原始点云的点云配准方法。由于基于体素[4]和多视图[5-7]的点云配准方法在转换过程中会造成信息丢失,并消耗大量内存和计算资源,因此目前基于原始点云的点云配准方法成为了在点云上进行学习的主流方法。文献[8]提出PointNet,直接在原始点云上提取特征,解决了输入点云的无序性、置换不变性以及旋转不变性问题。之后,研究者将直接对点云进行处理的点云配准方法推广到基于学习的点云配准方法中,分为端到端方法和基于特征描述的方法[9]。
端到端的点云配准方法是将一对点云输入神经网络,直接输出两个点云之间的变换矩阵。文献[10]提出PointNetLK,一对点云分别利用去除T-Net 的PointNet 获得每个点的特征,然后通过可微的LK[11]算法优化特征之间的差异并估计变换矩阵。文献[12]提出一种深度最近点(Deep Closest Point,DCP)模型,首先使用动态图卷积神经网络(Dynamic Graph CNN,DGCNN)[13]对点云进行特征提取,接着加入Transformer 模块考虑两个点云之间的上下文信息,最后使用奇异值分解(Singular Value Decomposition,SVD)计算旋转和平移矩阵。文献[14]在DCP 的基础上提出了PRNet,不同的是PRNet 没有考虑所有输入点的对应关系,而是预测了关键点到关键点的对应关系,解决了部分到部分的点云配准问题。尽管PRNet 的精度优于PointNetLK 和DCP,但仍仅适用于合成数据集,在真实数据上效果不佳。
基于特征描述的方法融合了深度学习提取特征和传统点云配准方法的思想,首先通过深度网络建立关键点之间的对应关系,然后使用随机采样一致性(RANdom SAmpling Consistency,RANSAC)算法[15]进行离群值过滤估计刚性变换矩阵,主要侧重于关键点描述。文献[16]以PointNet 为基本框架,建立对采样点的局部邻域计算点对特征的网络结构(PPFNet),PPFNet 采集了局部和全局特征,但依然对噪声和旋转操作敏感。文献[17]使用完全卷积网络[18]提取全局描述符,虽然处理速度很快,但全局描述符对遮挡和背景干扰不具备鲁棒性。文献[19]提出一种局部深度描述符模型(DIP),采用基于局部块的特征提取方式,首先对每个局部块建立局部参考坐标系(Local Reference Frame,LRF)[20]用于规范化每个点,使其具有旋转不变性,然后将规范化后的局部块作为基于PointNet 网络的输入,生成局部描述符。DIP[19]在真实数据集上匹配精度优于文献[20-21]模型,但采用PointNet 作为特征提取网络,没有考虑点云中局部邻域的空间信息。自适应图卷积(Adaptive Graph Convolution,AGConv)[22]网络不仅使用图卷积[13]充分考虑了全局形状信息和局部邻域信息,而且使用自适应核提高了卷积灵活性,并能获得不同语义部分点间的不同关系。
本文设计一种基于AGConv 特征描述符的点云配准模型。通过预处理模块对点云提取局部块并进行LRF 规范化,将其输入基于AGConv 的特征提取模块,利用匹配损失函数优化对应关系,并使用RANSAC 算法过滤离群点并估计变换矩阵。
1 基于AGConv 局部特征描述符的点云配准
本文提出的基于AGConv 局部特征描述符的点云配准模型主要由基于局部块的数据预处理模块、基于AGConv 的特征提取模块、基于RANSAC 刚性变换估计的点云配准模块等3 个模块构成,如图1 所示。首先给定两个具有重叠区域的点云,通过数据预处理模块从两个输入点云的重叠区域中分别提取局部块作为训练数据;然后设计一个基于AGConv的特征提取模块,将输入数据映射到一个新的特征空间,通过计算损失函数来训练网络以获得对应局部块的特征描述;最后在得到对应点的特征描述符后选择常用的RANSAC 算法去除误匹配并估计刚性变换矩阵,最终实现成对点云配准。
1.1 数据预处理模块
一般通过扫描设备得到的点云包含大量的点,并且比较密集。如果把点云中的所有点都作为输入,那么会消耗非常大的计算资源,因此通常会通过预处理对原始点云数据进行关键点采样处理。另外,在点云配准过程中,对应点仅存在于两个点云的重叠区域,在重叠区域进行特征匹配能够有效提高配准精度。
如图2 所示(彩色效果见《计算机工程》官网HTML 版),数据预处理模块沿用了DIP[19]中基于局部块的思想,从一对重叠区域大于30%的点云对(P,P')中提取局部块。在网络训练过程中,通过真实的变换矩阵T∊SE(3)找到点云对之间的对应点集(O,O'),如果对所有对应点求描述符则会增加不必要的计算量,因此采用最远点采样法(Farthest Point Sampling,FPS)[23]提取N=256 个关键点以确保采样的点均匀分布在重叠区域。给定点云P中关键点的集合为X⊂O及其在点云P'中的最近点X'⊂O'。以点云P为例,首先对于每个关键点xi∊X,提取半径为的局部 块,并使用局部块内的点计算相应的LRF[20],记为L。与DIP 类似,为了减少计算量对局部块内的点进行随机采样n=256 个点以构成关键点的局部邻域。然后重新计算n个点中每个点相对于其局部块中心xi的坐标并进行归一化,归一化后局部块中点的集合为最后为了加强描述符的旋转不变性,应用计算的L对F(Y)进行旋转变换操作,最终点云P的局部块可以表示为F=L⊗F(Y)。以同样的操作得到点云P'的局部块F',将数据预处理模块得到的局部块F和F'分别作为特征提取模块的输入,对关键点的局部邻域特征进行编码,从而对遮挡和环境干扰具有较强的鲁棒性。因此,基于局部特征的点云配准模型在真实数据集上更有效稳健。

图2 数据预处理模块结构Fig.2 Structure of data preprocessing module
1.2 特征提取模块
1.2.1 特征提取网络
基于PointNet 的特征提取网络在一些分类和分割任务中具有较优的性能,但是PointNet 只是对所有点云数据提取了全局特征,缺少局部信息,因此适用于处理复杂点云。为了解决该问题,使用AGConv 对局部块提取逐点特征。与标准的图卷积不同,AGConv 在卷积操作中根据每一层学习的特征为点生成自适应核,而不是使用固定的卷积核,能够有效地提取不同语义部分的点之间的不同关系。特征提取模块结构如图3 所示。

图3 特征提取模块结构Fig.3 Structure of feature extraction module
对于每个输入点云可以表示为(N,n,3)的形式,其中,N为局部块的个数,n为局部块内采样点的个数,3 表示每个点为三维坐标形式。为了弥补LRF 错误估计的问题,输入(N,n,3)的点云局部块,经过可学习的转换网络Spatial T-Net 实现点云的自动对齐,Spatial T-Net 使用了KNN 图结构[13]以及PointNet 中的T-Net 估计变换矩阵。首先,将对齐后的局部块输入到4 层AGConv 层(64,64,128,256)进行多级特征提取,并将每一级的输出特征进行连接以聚合多尺度的特征。然后,将聚合后的特征信息通过多层感知器(Multi-Layer Perceptron,MLP)以及最大池化操作输出每个局部块的1 024 维表示。最后,由3 层MLP 层(512,256,32)处理,其中最后一层的32 维输出由一个局部响应归一化层(Local Response Normalization,LRN)进行归一化。
1.2.2 损失函数
孪生网络结构由两个相同且权值共享的网络组成,用于衡量两个输入的相似性。配准问题的输入是两个具有相似数据结构的点云集合,因此在图1中使用孪生网络训练用于提取局部块描述符的特征提取网络,训练的目的是使重叠点云对中的两个对应局部块之间产生尽可能相似的描述符,即使匹配局部块的描述符间的距离尽可能小,不匹配局部块描述符的距离尽可能大。在网络训练过程中,针对两个不同的目标通过最小化两个损失的线性组合来学习网络参数。因为在学习的仿射变换下需要几何对齐两个局部块,而Chamfer Loss[24]具有使两个点云在几何空间上相似的特性可以有效解决仿射变换下几何对齐的问题。又因为两个对应局部块在特征空间也应尽可能相似,而Hardest-contrastive Loss[17]能同时 对相似性和不相似性进行计算使输入数据在特征空间找到两个对应点。
1)Chamfer Loss
倒角距离(Chamfer Distance,CD)是用来计算离最近特征点的平均距离。对于点云中的每个点,CD都会找到另一个点集中的最近点。因此,在点云配准网络中为了使匹配点间的距离最小,一般会将该距离用作训练该网络的损失函数。首先在变换矩阵A上使用Chamfer Loss[24]以几何对齐两个局部块,训练网络的目的是最小化局部块F中每个点与局部块F'中其最近邻点之间的距离,距离越小说明对齐效果越好。Chamfer Loss的计算公式可表示如下:
其中:|.|是集合中点的个数;A和A'分别为局部块F和F'通过Spatial T-Net 学习到的变换矩阵。
2)Hardest-contrastive Loss
Hardest-contrastive Loss 可以有效衡量孪生神经网络中两个输入数据的相似性,而点云配准问题中训练特征提取网络就是为了找到两个特征相似的对应点。因此,使用一种结合负样本挖掘技术的度量学习损失函数Hardest-contrastive Loss[17]来度量两个局部块之间的相似性。给定一对锚点的描述符(f,f'),挖掘最难负例(f-,f-'),损失函数可以定义如下:
其中:C+是锚点对的集合,即正样本集;C-是局部块中描述符的集合,用于负例挖掘;fk是距离锚点最近的点;[ ∙]+表示取正数部分;mp和mn分别是正样本对和负样本对的边界,正样本对的距离应该小于mp,负样本对的距离应该大于mn,按照一般规定[17],设置mp=0.1、mn=1.4。
该特征提取网络总的损失函数为LC和LH的线性组合L,训练的目标是最小化L。
2 实验结果与分析
所有实验选用的设备配置信息为:GPU GTX 3090,CUDA 11.4,Ubuntu 18.04,PyTorch 1.10.1,Python 3.7。训练模型使用SGD 优化器训练10 个epoch,每个epoch 迭代16 602 次,每次迭代都是一对点云。初始学习率设为0.01,学习率每学习3次降低10%。
2.1 实验数据集及参数设置
在大规模公开数据集3DMatch[4]上进行实验。3DMatch 数据集包含62 个使用RGB-D 传感器采集的真实室内场景,按照官方划分的比例将54 个场景用于训练,8 个场景用于测试。实验选取3DMatch 数据集中重叠率大于30%的点云对训练深度网络,使用0.01 m 的体素大小对点云进行下采样。为了测试模型是否具有旋转不变性,对3DMatch 数据集中的每个点云通过[0,2π]任意角度旋转,组成3DMatch Rotated 数据集。
2.2 评价指标
使用特征匹配召回率(Feature Matching Recall,FMR)衡量特征的描述能力,测量了数据集中正确匹配的点云数量。FMR 计算公式可表示如下:
其中:|M|表示重叠率大于30%的匹配点云对的数量是通过 最近邻 搜索找 到的一 对预测对应点;Ωs是第s个匹配点云对中找到的对应点的集合;Ts是当前匹配点云对的真实变换矩阵;Ind(∙)是指示函数;按照一般规定设置内点距离阈值τ1=0.1 m,内点比率阈值τ2=0.05。
配准召回率(Registration Recall,RR)是衡量点云配准实际任务性能的主要指标,评估了使用RANSAC 估计后的变换矩阵的质量,即一组具有真实变换矩阵的点云对,测量配准模型可以正确匹配的点云对的占比。RR 计算公式可表示如下:
2.3 对比实验
表1 为所提模型在3DMatch 和3DMatch Rotated数据集中采样5 000 个点,与基于传统手工特征描述符的FPFH[25]模型以及近几年代表性的基于学习描述符 的3DMatch[4]、PPFNet[16]、PPF-FoldNet[26]、PerfectMatch[20]、FCGF[17]、DIP[19]、D3Feat[21]模型进 行FMR 对比分析。由表1 可以看出,所提模型不仅在3DMatch数据集上相较于其他模型具有较高的特征匹配召回率,并且在3DMatch Rotated 数据集上依然表现出很好的旋转不变性。
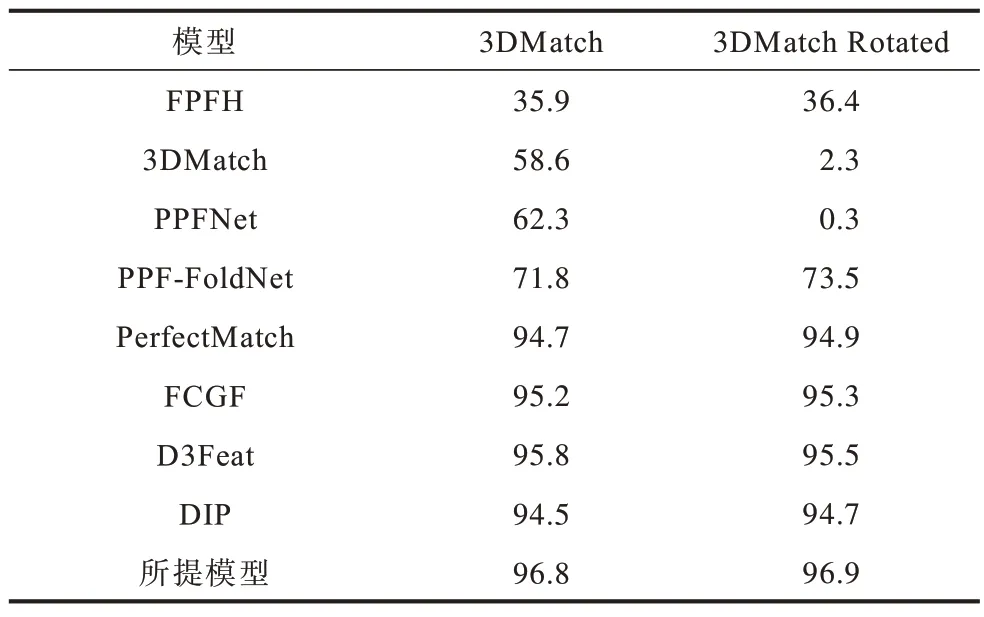
表1 不同模型的特征匹配召回率对比Table 1 Comparison of feature matching recall of different models %
通过改变式(4)中的τ1和τ2验证所提模型的鲁棒性,所提模型与对比模型的鲁棒性对比结果如图4 所示(彩色效果见《计算机工程》官网HTML 版)。由图4 可以看出:当增大τ1到相同数值时,所提模型相较于其他模型的FMR 上升趋势更快;当增大τ2时,所提模型的FMR 下降速度最慢。特别是在τ2=0.200 时,所提模型和DIP 差距最明显,这表明采用AGConv 提取的稳健特征进一步提高了模型鲁棒性。

图4 不同模型的鲁棒性对比Fig.4 Robustness comparison of different models
表2 展示了不同模型在3DMatch 数据集的8 个测试场景中的配准召回率对比结果。由表2 可以看出,所提模型在8 个场景中均具有较优的结果,其中在Home1 场景中的配准召回率略低于FCGF,可能的原因为该场景中的点云重叠率较低。值得注意的是Lab 场景是由多个平面组成的场景,缺乏结构化信息,所提模型在该场景中依然能得到88%的配准召回率,这表明所提模型能够提取出更独特的特征。
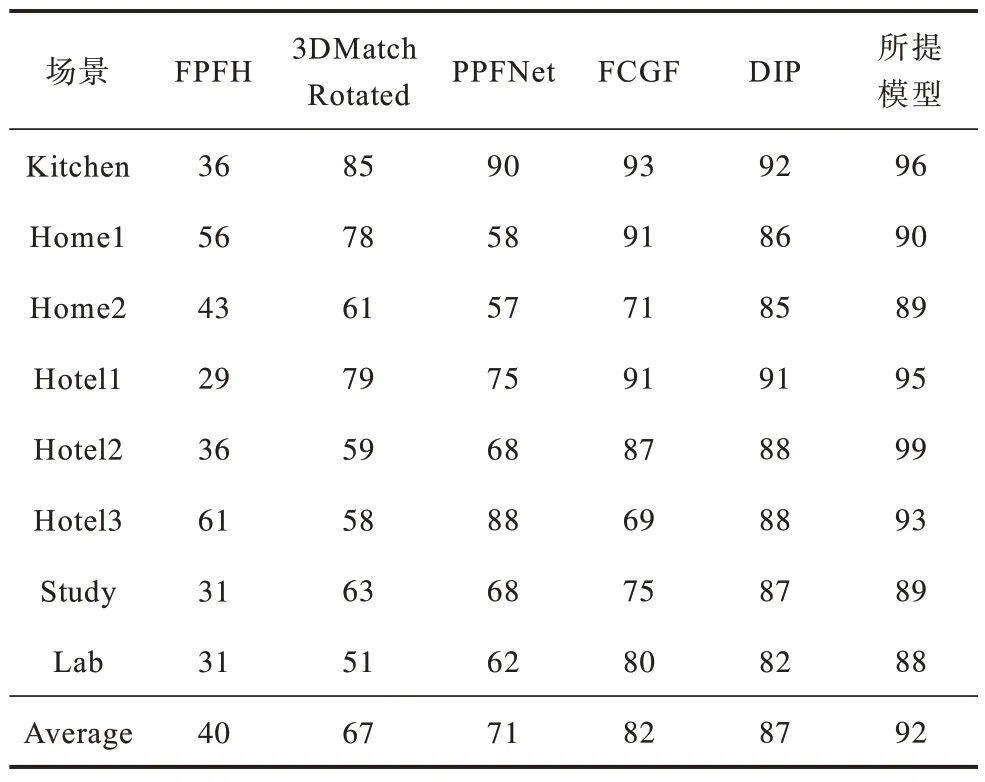
表2 不同模型的配准召回率对比Table 2 Comparison of registration recall of different models %
为了进一步证明所提模型的优越性,将采样点的数量从5 000 减少到2 500、1 000、500 甚至250 来评估不同模型的配准召回率,如表3 所示。由表3可以看出,当采样点从5 000 下降到250 时,即使采样点数只有250,所提模型依然能够保持在80%以上的配准召回率,而其他模型均以一定的幅度下降。

表3 不同模型在不同采样点数下的配准召回率对比Table 3 Comparison of registration recall of different models under different sampling points %
图5 为所提模型配准结果的可视化展示(彩色效果见《计算机工程》官网HTML 版)。由图5 可以看出,所提模型能够精确地将源点云和目标点云对齐。可见,采用AGConv 作为特征提取器在不同的评估度量下都能保持较优的结果。

图5 配准结果可视化Fig.5 Visualization of registration results
3 结束语
本文提出基于AGConv 局部特征描述符的点云配准模型。对输入数据进行局部块规范化,使用基于AGConv 的深度网络学习旋转不变、鲁棒且独特的局部特征描述符,提高模型在真实数据集中的配准精度。在3DMatch 数据集重叠率大于30%的点云对上的实验结果表明,所提模型取得了92%的配准召回率。但由于所提模型中的数据预处理模块、特征提取模块和点云配准模块都是独立模块,运行时间较长,因此下一步可将AGConv 描述符扩展到端到端配准,并在低重叠的点云对上进一步提高模型运行效率。
猜你喜欢
测绘学报(2022年12期)2022-02-13
计算机应用与软件(2020年6期)2020-06-16
计测技术(2020年6期)2020-06-09
电子制作(2018年19期)2018-11-14
数字通信世界(2018年1期)2018-04-18
测绘科学与工程(2017年5期)2017-05-07
自动化学报(2017年11期)2017-04-04
软件导刊(2016年12期)2017-01-21
噪声与振动控制(2015年4期)2015-01-01
轴承(2010年2期)2010-07-28
