
暗网网页用户身份信息聚合方法
2023-11-18 03:32:44王雨燕赵佳鹏时金桥申立艳刘洪梦杨燕燕
计算机工程 2023年11期
王雨燕,赵佳鹏,时金桥,申立艳,刘洪梦,杨燕燕
(1.北京邮电大学 网络空间安全学院,北京 100876;2.中国人民公安大学 信息网络安全学院,北京 100038)
0 概述
当前的网络空间可以根据其网页内容是否能够被常规搜索引擎获取分为明网和暗网2 种类型。其中,暗网是深网的子集,需要借助特殊软件(如Tor 浏览器)才能访问。这种特殊的访问方式为暗网带来了匿名性、不可追溯性等特性。随着互联网的飞速发展,暗网网络犯罪案件数量在全球呈现上升趋势。相较于普通的网络犯罪,暗网网络犯罪因其本身具有的匿名性和不可追溯性导致犯罪分子更加难以被追踪。情报分析是追踪暗网犯罪的重要手段,该技术收集犯罪分子在暗网网络活动中留下的相关身份信息(如邮箱地址、比特币钱包地址、社交平台账号等)作为破解用户身份的重要线索。因此,研究自动化识别和聚合同一用户多种身份信息的技术具有重要的应用价值。
针对暗网用户身份信息的识别和聚合问题,当前的相关研究较少。笔者通过广泛调研发现,自然语言处理中的关系抽取和共指消解方法可以解决该问题。关系抽取旨在识别实体对之间的关系类别;共指消解旨在聚合同一句子内指向同一名词的代词。从本质上说,共指消解是一种特殊的关系抽取任务,其特殊在于指定了实体是代词、实体间的关系是共指关系。虽然共指消解与本文研究的任务很相似,都是聚合语义上有关联的对象,但它们依旧存在2 个不同之处:首先,任务关注的对象并不相同,前者是语句中的代词,后者是网页中的用户身份信息;其次,当前流行的共指消解方法将代词识别和代词间共指关系抽取2 个部分联合进行,例如文献[1-3]方法。由于本文研究的用户身份信息的识别和聚合是2 个不同的阶段,不涉及联合抽取的过程,因此本文最终选择使用简单的二元关系抽取方法解决用户身份信息聚合的问题。本文定义属于同一用户的2 个用户身份信息之间包含共指关系,使用关系抽取模型来识别身份信息之间的共指关系。
目前,使用关系抽取方法解决用户身份聚合问题主要存在3 个问题:首先,该场景缺乏公开可用的包含暗网多种用户身份信息的数据集;其次,虽然特征工程对于解决此类问题已经表现出不错的性能,但是随着深度学习的发展,摆脱特征依赖也是目前研究的主流方向,如何选择合适的深度学习方法、构建相应的模型、实现同一用户多种身份信息自动化和高性能聚合,也是难点之一;最后,在暗网用户身份信息聚合的过程中,某些类别可获取的用户身份信息稀少,导致标注样本有限,然而目前的深度学习方法又普遍依赖大规模标注样本来保证识别性能,因此,如何进一步修改深度学习模型来降低模型对大规模训练样本的依赖,是另一个难点。
为了解决这些问题,本文提出一种基于规则的身份信息识别方法,用于识别网页中出现的所有身份标识信息,并构建相应的用户信息聚合数据集。在此基础上,提出一种以有监督的共指关系抽取模型作为用户聚合任务的基线模型,该模型输入一对用户身份信息及其上下文语境,返回该信息对之间是否包含共指关系。基于对数据集的统计分析,用户身份信息的类别对共指关系的识别有一定提示作用,因此,本文在基线模型中引入实体类别信息,提出实体类别敏感的共指关系抽取模型,进一步提高用户身份信息聚合模型的准确率。最后,针对暗网中通过某些身份类别信息无法获取足够多的训练样本这一问题,在基线模型中引入少样本学习任务,构建低资源条件下基于多任务的用户身份信息聚合模型,减少模型对大规模训练集的依赖。
1 相关技术
1.1 实体识别技术
传统的命名实体识别是自然语言处理的一项基础任务,其研究的核心是如何在一些特定领域内对文本中的实体名词进行抽取,例如从医药学领域的学术报告中获取药物名称、从报纸中抽取关于机构活动的人名、地名、组织机构名等。基于统计机器学习的命名实体识别方法被广泛应用,包括基于隐马尔可夫模型(Hidden Markov Model,HMM)[4]的命名实体识别模型、基于支持向量机(Support Vector Machine,SVM)[5]的命名实体识别模型、基于条件随机场(Conditional Random Field,CRF)[6]的命名实体识别模型等。当前,基于深度学习的模型效果最佳,在相关研究中:文献[7]提出基于格的长短期记忆(Latticebased Long Short-Term Memory,Lattice-LSTM)网络,结合了词典匹配和条件随机场进行命名实体的识别;文献[8]使用预训练模型BERT[9]获得上下文单词的语义嵌入,提高了模型对实体语义的理解能力。
命名实体识别技术可以实现暗网用户身份信息的自动化识别,但是当前的命名实体识别技术面临多个难题,例如在真实的开放环境中,无法列举所有的实体种类和数量、无法完成实体间的歧义消解、难以对实体边界进行界定等。受以往实体识别工作的启发,本文统计并定义了以下种类的用户身份标识信息:社交平台账号(如Telegram 群组、Raddit 账号、GitHub 账号、Discord 账号、Medium 账号、Facebook账号、Linkedin 账号、VK 账号、Twitter 账号、Instagram 账号等);加密货币钱包地址(如比特币地址、以太坊地址、门罗币等);个人联系方式(如邮箱地址、电话号码等)。这些信息每一类都有其标志性的特征,因此,对不同类别的信息构建不同的匹配规则是一种简单、有效的实体识别方式。
1.2 句子级关系抽取
给定一个句子S,句子中包含一对实体e1和e2,句子级关系抽取的目标是根据S中的语义信息识别出e1和e2之间的关系。基于统计机器学习的句子级关系抽取方法广泛应用于情报抽取领域,包括最大熵模型(Maximum Entropy Model,MEM)[10]、隐马尔可夫模型[11]、条件随机场[12]、核(Kernel)方法[13]等。这些方法严重依赖于手工特征,消耗大量人工成本的同时灵活性低下,更换应用场景或数据内容往往需要构建新的特征集合。基于深度学习的关系抽取方法解决了这一难题,在相关研究中:文献[14]使用卷积神经网络(Convolutional Neural Network,CNN)来学习句子的语义嵌入,之后在CNN 的基础上产生了多个变种,包括使用分类损失函数的CR-CNN[15]、添加分段最大池化操作的Pooling-CNN[16]等。此外,LSTM 网络也用于学习文本序列的语义嵌入,在相关研究中:文献[17]提出的双向长短期记忆(Bidirectional LTSM,BiLSTM)网络结合了前向LSTM层和后向LSTM 层,该方法被证明能同时捕捉词语前的文本信息和词语后续的语义信息;在此基础上,文献[18]将注意力机制用于BiLSTM,得到了Att-BiLSTM。
基于经典的Transformer 模型[19],文献[20]提出了用于语言理解的生成式预训练转换器GPT-2,文献[9]提出了大规模预训练模型BERT。目前,关系提取的最佳模型均使用预训练模型来获得实体的语义嵌入。当前在优化关系抽取模型方面主要有以下2 种方式:
1)优化预训练模型。ERNIE 模型[21]改进了预训练过程中掩盖关键字的方式,与基线预训练模型BERT 相比,其将词掩蔽策略扩展到分词、短语和实体。SpanBERT[22]利用几何分布随机抽取短语片段,并根据片段边界词的向量预测整个掩码词。此外,还可以通过引入外部知识来优化预训练模型,例如KnowBERT[23]和ERNIE 均通过预训练外部知识库来获取实体嵌入。类似地,K-Adapter[24]关注如何向语言模型注入事实和语言知识,LUKE[25]进一步将掩蔽语言建模的训练前目标扩展到实体,并使用了一种实体感知的自我注意机制。
2)对实体的标记进行改进。IREBERT[26]使用一组用于句子级关系抽取的类型化实体标记符号,该方法与传统的实体掩码技术和已有的实体标记技术相比,能得到更符合上下文语义的实体嵌入。当前句子级关系抽取的研究已经取得了令人满意的成果,然而这些方法的性能依赖于丰富的训练资料,随着训练样本的减少,模型性能也随之迅速下降。在暗网用户身份信息聚合的场景中,有多个种类的身份信息在标注样本集合中非常稀缺,在深度学习领域,该问题可以通过少样本学习方法解决。
1.3 少样本关系抽取
少样本关系抽取是指仅通过少量训练样本对实体对关系进行分类的机器学习问题,目前解决该问题的方法主要分为以下3 类:
1)使用数据增强手段增加训练样本数量。EDA[27]是一种用于文本分类任务的数据增强方法,其使用4 种文本变换手段,包括对原数据集样本进行同义词替换、随机插入单词、随机交换和随机删除。但是该方法需要大量手工操作(如定制同义词集合等),且分类器性能提升并不明显。
2)优化模型结构。目前最常见的优化方法是基于度量的方法和基于提示学习的方法。基于度量的方法通过计算实体嵌入与锚点的相似度(或距离)进行分类,例如:匹配网络[28]使用余弦相似度计算相似度;原型网络[29]使用欧氏距离计算相似度。基于提示学习的方法将关系抽取任务转换为提示生成任务,使用预训练模型推理获得有关提示的答案。LAMA 模型[30]将关系抽取任务修改为填空题,在使用相同预训练模型的情况下,相比引入外部知识库等传统方法获得了更好的效果。文献[31]研究表明,将任务描述(即提示)作为预训练模型的输入,能够极大地提高少样本模型的性能。随后,文献[32-33]应用2 种不同策略扩展了该方法。为降低手工生成提示的时间成本,文献[34]提出了一种生成文本分类任务提示的有效方法。为了使提示学习能高效地应用于零样本和少样本关系抽取,文献[35]进一步将关系抽取描述为一个文本蕴含任务。
3)改进模型算法,利用先验知识初始化已有参数来改变模型的搜索方向,达到减小估计误差的目的。OSVOS 模型[36]在解决视频对象分割任务时,使用了预训练的卷积神经网络进行图像分类,首先使用大数据集进行前景分割的调整,然后使用单次拍摄的分割对象进一步调整分割,优化后模型的分割准确率从68.0%提升到79.8%。文献[37]对元学习任务的参数进行初始化,新任务的少量梯度步骤和少量训练数据将在该任务上产生良好的泛化性能。
虽然目前少样本关系抽取技术飞速发展,但是面对暗网用户身份信息聚合等真实的场景,仍然缺乏相关模型的应用实例和实验数据。
2 暗网用户身份信息识别和聚合
从初始暗网网页到完成用户身份信息聚合的流程如图1 所示,其中,用户身份标识信息的识别和聚合是关键技术,前者识别网页中的用户身份信息,构建数据集,后者输出数据集中信息对的共指概率,聚合属于同一用户的信息。
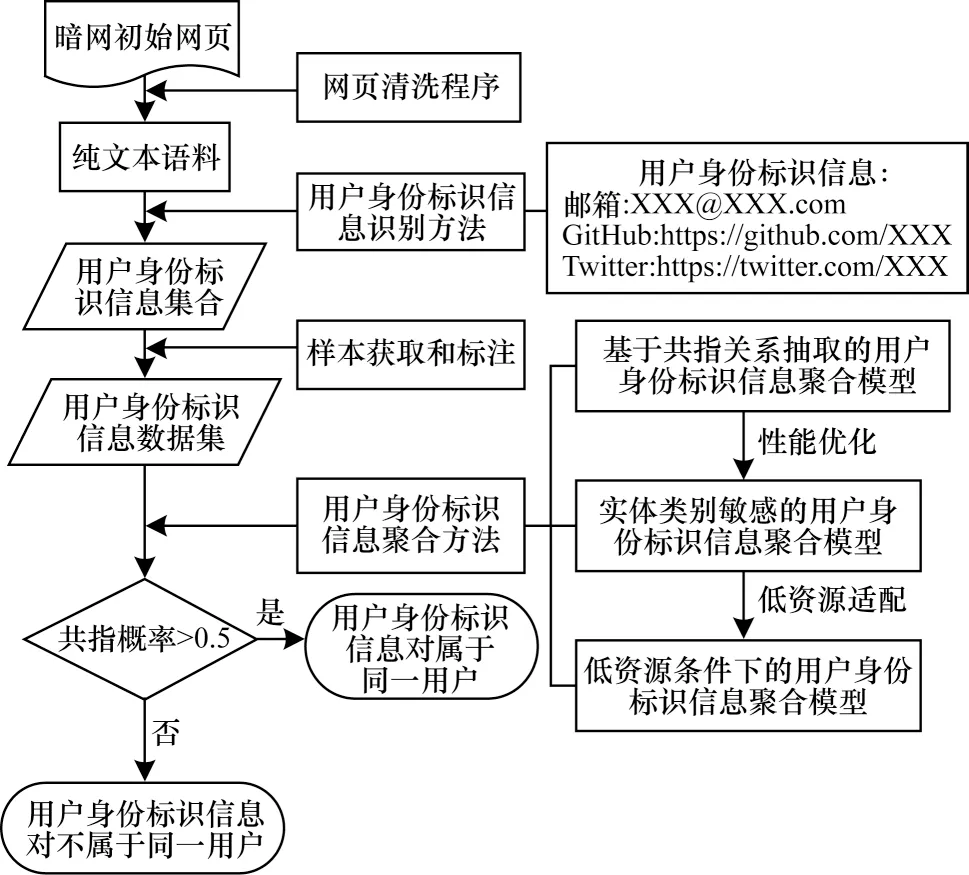
图1 暗网用户身份信息识别与聚合流程Fig.1 Procedure of identifying and aggregating identity information of darknet users
本文提出一种暗网用户身份信息的识别和聚合方法,实现过程包括以下3 个部分:
1)针对缺少公开可用的暗网用户身份信息数据集的问题,提出一种基于规则的用户身份信息识别技术。该技术用于自动化并高效地识别纯文本中的用户身份信息,是构建暗网用户身份信息数据集的关键技术。
2)受现有关系抽取技术的启发,提出一种暗网用户身份信息聚合的基线模型ConRE,然后在ConRE 基础上加入实体类别信息优化,提出ConREtype和ConREtype_description模型。
3)为了降低聚合模型对大规模训练样本的依赖,在ConRE、ConREtype和ConREtype_description的基础上,引入多任务学习来提高模型的F1 值,增强模型在训练样本资源不足(低资源)情况下的稳定性。
2.1 基于规则的用户身份信息识别技术
暗网中的用户身份信息每一类都有其标志性的特征,因此,对不同类别的信息构建不同的匹配规则是简单且有效的用户身份信息识别方式。基于规则的用户身份信息识别技术使用手工定制的正则表达式,匹配同一网页中的所有用户身份信息。该技术输入经过预处理的暗网HTML网页,输出用户身份信息集合。
本文定义以下4 种暗网用户身份信息类别:1)社交平台账号,如Discord 账号、Instagram 账号、GitHub账号、VK 账号、Twitter 账号、Medium 账号、Telegram账号、Facebook 账号、Linkedin 账号、Reddit 账号等;2)个人联系方式,如邮箱地址、电话号码等;3)加密货币,包括比特币、以太坊;4)其他种类数量极少的用户身份信息,如电话号码、门罗币等,统一归纳为其他类别。基于规则的用户身份信息识别技术在特定的领域内准确率极高,是一种简单、有效的匹配暗网用户身份信息的方式。
基于规则的实体识别方法根据文本特点,手工定制规则匹配模板以完成实体识别。此类方法往往基于知识库和词典,以指示词、标点符号作为抽取依据。本文针对每一类别的用户身份信息制定了相应的正则匹配规则。表1 列举了常见的14 种用户身份信息以及匹配规则,其中:“X”指匹配任意字符;“[]”表示或运算;括号中每个选项用“|”分隔;“^”指匹配开头字符“;$”指匹配结尾字符“;{}”表示匹配次数。
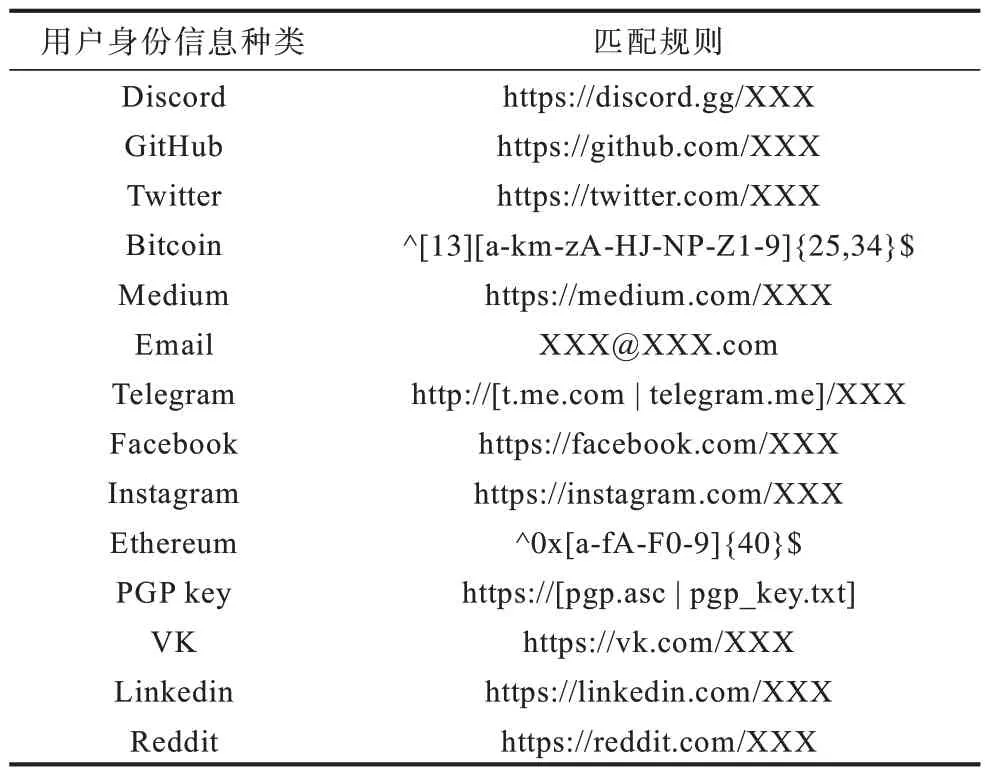
表1 用户身份信息种类及相应匹配规则Table 1 Types of user identity information and corresponding matching rules
2.2 基于共指关系抽取的用户身份信息聚合方法
在基于共指关系抽取的用户身份信息聚合方法中,定义了同一页面中属于相同用户的信息之间包含共指关系,用户身份信息聚合任务被转化为共指关系抽取任务。针对上一阶段抽取的用户身份信息实体,本文构建了有监督的共指关系抽取模型ConRE、实体敏感的共指关系抽取模型ConREtype和ConREtype_description。这些模型均通过学习实体对及其上下文语境所包含的语义信息,判断实体对之间是否具有共指关系。本节将详细介绍构建这些聚合模型的关键技术,包括获取实体嵌入、实现共指关系二元分类器和引入实体类别信息特征来优化模型性能。其中:ConRE 模型由获取实体语义嵌入的预训练部分和二元分类器组成;ConREtype和ConREtype_description模型是在ConRE 的基础上,引入实体类别的信息特征优化后的模型。
2.2.1 实体语义嵌入的获取
本文通过BERT 预训练模型获得实体对嵌入。BERT 是由Transformer 编码器在大规模语料库上训练得到的模型,也是目前使用最为广泛和成熟的预训练模型。Transformer 使用自注意力机制代替CNN 的卷积和LSTM 的门控机制来计算权重,在保证计算速度的情况下,能够平等地捕捉到文本序列更长距离的上下文信息。本文通过BERT 提供的实体表示来完成二分类任务。
获取实体嵌入需要对句子执行预处理程序,具体如下:1)将句子转换为token 序列;2)为序列添加特殊符号,在序列开头添加“[CLS]”作为分类标识符,在序列结尾或2 个序列分界处添加“[SEP]”作为句子分割符,在实体开始和结束的分界处分别添加“$”和“#”作为实体标记符。
将处理后的token 序列输入BERT。假设句子S的2 个实体为e1和e2,对于BERT 输出的完整隐藏状态V,取出V中e1和e2对应的初始向量v1和v2,计算其平均值后经过同一个全连接层,获得最终实体嵌入实体1 嵌入的计算过程如式(1)所示,其 中,W1和b1是可学 习的参 数,j和k分别表 示e1在句子中的起始token 编号和终止token 编号;e2嵌入的获取同理,计算过程如式(2)所示;取出V中对应“[CLS]”的初始向量vc,然后经过一个全连接层获得分类标识嵌入,分类标识符嵌入的计算过程如式(3)所示,其中,Wc和bc是可学习的参数。
2.2.2 二元分类器
分类器负责对输入的每一个嵌入预测实体对之间是否存在共指关系。首先拼接2 个实体嵌入和分类标识嵌入,然后经过一个全连接层得到分类嵌入,式(4)为的计算过程,其中,Wp和bp是全连接层参数。最终共指分数由Softmax 层组成的分类器获得,将分类嵌入输入分类器,输出实体对共指的概率P,如式(5)所示,当P大于阈值0.5 时,分类器预测实体对之间存在共指关系。
2.2.3 实体类别信息的引入
根据统计信息,实体类别信息对共指关系的判断有一定指示作用,为了提高模型识别准确率,本文在基线模型ConRE 的基础上,采用2 种不同的方法添加实体类别辅助信息:方法1 直接使用实体类别的名称作为辅助信息,拼接于原句子结尾,并添加符号“[SEP]”分割原句与辅助信息,得到模型ConREtype;方法2 引用Wiki 知识库中相关实体类别描述作为语义辅助信息,将拼接辅助信息后的句子输入关系抽取模型,得到模型ConREtype_description。此时模型训练所得到的和为额外获得的实体类别语义信息。
2.3 低资源条件下的用户身份信息聚合方法
本文提出的低资源用户信息聚合方法以模型ConRE、ConREtype和ConREtype_description为基础,添加实体类别辅助信息提升模型识别能力,并且引入度量学习任务提高模型在低资源条件下的鲁棒性。
度量学习通过计算实体嵌入与锚点的相似度(或距离)进行分类。这种方法在少样本学习领域得到了广泛的应用,并且大量实验证明,这种方法能显著提高低资源条件下模型的识别能力。引入度量学习任务需要解决以下3 个问题:
1)设置锚点。对于分类模型,需要为每一个类别定义一个锚点。锚点的设置是度量学习的关键,其定义某类别样本在高维空间中的投影中心,某样本与该类别的锚点在高维空间中距离越近,表示该样本属于此类别的概率越大;相反地,某样本与其他类别的锚点距离越远,表示该样本属于这些类别的概率越小。为保证锚点在空间中的位置符合共指关系与非共指关系在现实世界中的语义,在暗网用户身份信息集合的场景下,本文参考Wiki 百科手工定制共指关系和非共指关系的语义描述S1、S2,输入BERT 获得描述句子嵌入,即模型的2 个锚点。计算过程如式(6)和式(7)所示:
2)相似度计算。此处选择内积计算实体嵌入与锚点嵌入的相似度,如式(8)所示,函数d接收实体嵌入和锚点嵌入。
3)修改损失函数,把度量学习任务与原任务组合为多任务模型。此时损失函数由两部分组成,分别是基线模型的二元交叉熵损失L1和度量学习任务的三元损失L2。计算过程见式(9)和式(10):
式(11)是加入度量学习后模型的损失函数,由基线模型的交叉熵损失和度量学习的三元损失2 个部分组成,其中,∂和γ是超参数,前者用于调节损失占比,后者表示相似度阈值,若空间距离远于阈值,则认定2 个向量不属于同一类别。
本文定义共指关系的锚点以a'S1表示,非共指关系的锚点以a'S2表示,多任务的暗网用户身份信息聚合模型架构如图2 所示。

图2 多任务的暗网用户身份信息聚合模型架构Fig.2 Architecture of multi-task darknet user identity information aggregation model
3 实验
本文实验对应上文内容验证所提方法的性能。实验分为3 个部分:第一部分使用第2.1 节中提出的基于规则的用户身份信息识别技术,生成数据集Duad;第二部分给出第2.2 节中所提出的基线模型和多个主流的关系抽取模型的性能对比;第三部分对应于第2.3 节的内容,描述本文针对基线模型所提出的改进方法在数据集Duad 上的优化效果。
3.1 数据集的获取
本文通过Tor浏览器提供的接口爬取50 000 个暗网初始网页(已去除重复网页和同源网页)。该网页集合需要经过特定的清洗模块,模块去除初始网页多余的图片、HTML 标签、网页格式符号后,将其转换为纯文本,方便用于获取用户身份信息及其上下文语境。
根据第2.1 节所提出的基于规则的用户身份信息识别技术,构建相应的自动化规则匹配模块。基于制定的14 种用户身份信息匹配规则,模块依次对每一个纯文本网页执行匹配程序,得到用户身份信息集合。
最后,针对匹配模块得到的用户身份信息集合,语料生成模块对属于同一网页的用户身份信息对,即可能属于同一用户的实体对,生成共指关系抽取语料。模块以实体为中心,截取3 个短句作为其上下文语境,列举同一网页所有用户信息实体,选择任意一个实体ei,将它与同网页另一个实体ej组合,拼接ei和ej对应的上下文得到句子S,S是本文共指关系抽取模型的输入。对所有网页执行以上操作,最终获得21 531 个实体。在所生成的Duad 数据集中,通过某些种类的用户信息难以获取大量训练样本,例如电话号码、门罗币等,Duad 将其归类为其他类别,所有实体类别及其数量如表2 所示。
3.2 基于共指关系抽取的用户身份信息聚合模型性能
本文参考关系抽取领域,使用F1 值作为模型性能的评估指标。F1 值由模型的正确率和召回率决定:正确率也称为查准率,是指所有样本中正确预测为真的样本数量占全部预测为真的样本数量的比例;召回率也称为查全率,是指所有样本中正确预测为真的样本数量占全部实际为真的样本数量的比例;F1 值是准确率和召回率的加权平均值。准确率、召回率和F1 值的计算公式如式(12)~式(14)所示:
其 中:PPrecision表示正确率;RRecall表示召回率;F1表示F1 值;TP表示模型预测为真、真实情况也为真的样本数量;TN表示模型预测为真、真实情况为假的样本数量;FP表示模型预测为假、真实情况为真的样本数量;FN表示模型预测为假、真实情况也为假的样本数量。F1 值越高,表明模型的性能越好。
为了证明本文所提出的ConRE、ConREtype和ConREtype_description模型能更有效地应对暗网网页用户身份信息聚合这一新的应用场景,本文选择了多种当前流行的关系抽取方法作为对比方法,包括基于卷积神经网络的模型(CNN)、按排名执行分类的卷积神经网络(CR-CNN)[32]、带注意力机制的双向长短时记忆网络(Att-BiLSTM)。同时,本文也对比了当前先进的关系抽取模型,包括基于双向Transformer 的预训练模型LUKE、将关系抽取转换为文本蕴含任务的NLI-Roberta模型等在数据集Duad上的性能差异。
笔者认为,用户身份信息的类别对共指关系的识别有一定的指示作用。首先,根据对数据集Duad 的统计显示,相同类别的信息对之间共指的比例仅为12%,远远低于不同类别的信息对;其次,某些类别的信息共指的概率更高,如实体对中存在一个邮箱类别的信息则共指概率更高。ConREtype引入实体类别名称,ConREtype_description引入实体类别描述,它们从这些信息中获得类别语义,进而优化共指关系的识别。实体类别信息的引入过程如下,其中,斜体表示用户身份信息实体,加粗表示引入的信息。
表3 列出了各模型在训练样本数量分别占总数据量10%、5%、2.5%和1.25%时的F1 值,其中,训练集占比=(参与训练集的样本数量/总样本数量)×100%,下标“type”表示引入用户身份信息类别编号信息的模型,下标“type_description”表示引入用户身份信息类别描述信息的模型。可以看出,当训练样本数量占数据集总量10%时,CR-CNN、Att-BiLSTM、LUKE 模型均能获得较好的性能。然而,随着训练样本数量的迅速减少,这些方法F1 值迅速下降。当训练样本占比从10% 降到1.25% 时,LUKE模型的F1 值下降约25 个百分点,由此可见,越复杂的模型对于训练数据量越敏感。ConREtype_description模型在不同训练集中均获得了最佳性能,该结果证明,用户身份信息类别的引入能有效提高用户信息聚合模型在训练样本数量减少时的性能。

表3 各模型在不同训练集占比情况下的F1 值Table 3 F1 value of each model under different training set proportions %
图3 为本文工作的一个具体实例,其中展示了一个暗网的毒品销售网页,网页中出现了4 个用户身份标识信息:1)比特币钱包地址“17gLLy NaEsaHuZ9r8XEfbs7kedVexrzasa”;2)比特币钱包地址“3Q2Pt9dD1AVD5Mzr78jUjXZ48CrafWH8Wv”;3)邮箱地址“Email-example@Email.com”;4)Telegram平台群组链接“https://tg.me/buydrugs”。
根据手工语义分析可知,第1、2 条信息来自于2 位用户在该网页的留言,第3、4 条信息属于网页负责人的联系方式。通过第1、2 条信息所组成的实体对得到的训练样本如图4 所示(彩色效果见《计算机工程》官网HTML 版)。由于2 条信息实体在网页文本中的实际距离较近,样本中截取的上下文语境有重叠部分,而语境的重叠也是判断实体对是否共指的特征之一,在没有使用信息实体类别特征时,ConRE 模型认为该信息实体对共指,加入实体类别信息后,ConREtype和ConREtype_description模型能学习到相同类别的实体之间共指概率较低,得出该实体对非共指的正确结果。

图4 训练样本示例Fig.4 An example of training sample
3.3 低资源条件下的用户聚合方法
暗网网页中通过某些种类的用户身份信息难以获取大量训练样本,为提高模型在低资源条件下的鲁棒性,以作为ConRE 基线模型,分别引入用户身份信息类别、用户身份信息类别描述以及度量学习任务进行优化。在训练集占比为1.25%的条件下,评估优化后模型的性能。如表4 所示,其中,针对基础模型ConRE,ConREtype添加用户身份信息类别名称作为辅助信息,ConREtype_description添加用户身份信息类别描述信息作为辅助信息,ConREmul是引入度量学习任务后的多任务关系抽取模型。同时,列出对模型ConREmul添加了用户身份信息类别名称和用户身份信息类别描述后的结果,分别由ConREmul+type和ConREmul+type_description表示。可以看出,本文引入的辅助信息和辅助任务均在一定程度上提升了模型的性能,其中,ConREmul+type获得了最佳F1 值,为87.03%,相较于基线模型ConRE 提高了11.98 个百分点。

表4 各模型在Duad 数据集上的性能Table 4 Performance of each model on Duad dataset %
4 结束语
本文针对同一个暗网网页中的多个用户身份信息,提出一种基于规则的用户信息识别技术,用于自动抽取网页中的用户身份信息。在此基础上,根据从暗网中获取的用户身份信息,提出基于共指关系抽取技术来解决同一用户多个身份信息的聚合问题。最后,提出在低资源条件下的用户身份信息聚合方法,解决暗网场景下聚合模型依赖训练样本数量的问题。目前,本文所提出的用户身份信息识别技术仅支持解决封闭域的问题,在暗网用户身份信息聚合的场景下,需要手工定制用户身份信息的类别,并根据每一种类别生成抽取规则。后续将重点研究开放域下的用户身份信息识别技术,进一步提高识别准确率。
猜你喜欢
法制博览(2021年1期)2021-11-25 19:18:02
检察风云(2020年20期)2020-12-03 13:49:22
方圆(2020年16期)2020-09-22 07:03:44
党员生活·中(2020年4期)2020-07-04 02:27:23
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
