
面向安全匿名集构建的多属性决策方法
2023-11-18 03:32侯占伟申自浩刘沛骞
计算机工程 2023年11期
侯占伟,杨 鑫,申自浩,王 辉,刘沛骞
(1.河南理工大学 计算机科学与技术学院,河南 焦作 454000;2.河南理工大学 软件学院,河南 焦作 454000)
0 概述
近年来,随着第4 代、第5 代通信技术以及智能移动设备和卫星定位技术的发展,基于位置的服务(Location Based Services,LBS)得到了广泛的应用,与之相关的资源也变得更加丰富[1-2]。LBS 可以在娱乐、商业、卫生、办公、紧急情况等不同领域提供多种服务。然而,为了获得LBS 带来的便利,移动用户必须向基于位置的服务提供商(Location Services Provider,LSP)公开实际位置。但位置信息不仅可以展示用户的经纬度,也可以被攻击者用来进行跟踪和分析进而得到关于用户的敏感信息,如家庭地址、用户习惯、健康状况以及宗教信仰[3-4]。他们违法收集的信息可能被用于各种非法活动,导致用户声誉受损。
为防止位置隐私信息的泄露,国内外众多该领域的学者提出了多种位置隐私保护方法,大致可以分为位置泛化、位置扰动和位置加密3 大类。位置泛化[5]利用空间匿名技术来实现,通过使用该技术,移动用户的真实位置将会隐藏在匿名空间区域内。但是匿名区域的大小会成为限制该技术发展的瓶颈。当生成的匿名区域面积过大时,不仅方案的时间开销会增加,查询的准确性也会大打折扣;而当生成的匿名区域面积过小时,隐私保护的质量将会下降,容易被攻击者识破。位置扰动[6-7]是利用具有一定偏移量的位置或者假位置来代替用户的真实位置,这样攻击者或服务器就无法获得用户的真实位置。但是对于某些攻击者而言,他们具备一定的背景知识,通过推理可以轻易排除掉用户生成的一些假位置。在这种情况下如何生成隐私保护度高的假位置成为研究的热点。位置加密[8-9]是利用各种密码学技术对移动用户的位置数据进行加密,在没有相关密钥的情况下无法获取用户的位置信息。尽管使用加密算法在一定程度上提高了用户的位置隐私保护效果,但其算法流程大多过于复杂且计算量较大,导致运行开销大幅增加。
以上方法在面对背景知识攻击、语义攻击等方面存在局限性,而且没有对综合因素进行考量,隐私泄露风险较高。为更好地保护移动用户的位置隐私,本文提出基于多属性决策模型的匿名集构造(Multi-attribute Decision Model-based Anonymous Set Construction,MDMASC)算法。通过分析个体用户和群体用户轨迹位置点的规律,在本文提出的语义敏感等级、位置普遍度、语义跨度等多个属性层面进行综合考量。使用层次分析法(Analytic Hierarchy Process,AHP)分析各属性间的关系,合理确定权重。此外,使用多属性决策方法,经综合决策选出最佳假位置,构建具有不可区分性的安全匿名集。
1 相关工作
在众多位置隐私保护的方案中,大多数学者都致力于研究如何生成与真实位置区分度高、隐私保护效果好的假位置。KIDO 等[10]提出使用假位置来实现位置隐私保护,其主要思想是将用户的真实位置与众多假位置组成匿名集一起发送给LSP。这种方法不需要第3 方匿名服务器加入,避免了因匿名服务器的信任问题或匿名服务器遭受攻击而导致的隐私泄露风险,但由于其没有考虑查询概率等因素,因此容易遭到具有背景知识的边信息攻击。
考虑攻击者挖掘用户的历史请求信息,NIU等[11]提出了深度学习搜索(Deep Learning Search,DLS)算法,该算法根据地图上位置单元的历史查询信息计算得到历史查询概率,其次使用熵度量安全性,最终选择符合其要求的假位置构造匿名集。由于需要大量计算匿名集的熵值,致使该算法时间复杂度较高,在某些资源受限的通讯设备上使用时难以实现 很好的 隐私保 护效果。SUN 等[12]在DLS 的基础上,通过分析攻击算法ADLS,提出DLP 算法。该算法在时间复杂度和用户隐私要求之间进行了权衡,在一定程度上具有较好的隐私保护效果,但是其忽略了山川、湖泊等历史查询概率为零的位置单元。杨洋等[13]提出K-DLS 算法,该算法在考虑到位置单元历史查询概率为0 的同时改善了假位置的分布情况,生成的匿名集具有较高的位置熵值,提升了位置隐私保护的安全性。然而在保护用户位置隐私的过程中,若攻击者采用语义攻击等手段时,仅考虑位置单元的历史查询概率显然是不够的。
针对攻击者掌握移动用户位置点的语义信息,文献[14]提出的方案考虑了用户访问地点的语义信息,对用户的隐私保护需求予以满足,但是其未考虑位置分布对假位置集的影响,预期的隐私保护效果在遭受位置同质性攻击时往往难以达到。王洁等[15]提出了MMDS 算法,该算法通过位置语义树计算各位置间的语义差,同时考虑了假位置的查询概率和地理分布,根据以上这3 个维度生成假位置,在衡量位置间的语义差异性上提供了思路。但是,在兴趣点(Point of Interest,POI)类别较少的地区,语义树的子节点较少,而该算法仅通过位置语义筛选假位置,隐私保护效果较差。文献[16]使用了多属性决策的思想来选取假位置,根据历史查询概率、物理距离和语义多样性构建匿名集。但其没有衡量各因素间的相对重要关系,同时考虑因素过少,未对综合因素进行考量,用户的隐私保护强度不够高。
针对同一位置点,不同用户对其敏感程度不同。值得一提的是敏感位置的信息大多与用户身份相关联。当攻击者定位到某一用户的敏感位置点时,将极大可能推测出该用户的身份。YIN 等[17]提出了一种基于位置敏感度划分的位置数据安全保护方法。该方法对位置敏感度级别进行分类,基于此分配隐私预算,有效地保护了用户的位置隐私。LIU 等[18]基于随机匿名区域的概念提出了一种RSABPP 算法,各个区域具有不同敏感值,对手将难以通过推断匿名用户的敏感度去识别真实位置。
本文提出MDMASC 算法,综合考虑用户真实位置所具有的背景知识等信息,使其在不同的场景下具备适应性,有效地降低攻击者在拥有用户行为规律、位置语义等背景知识情况下用户真实位置被识别的风险。
2 预备知识
2.1 语义树
为了从现实生活中细化出兴趣点类型,根据目前主流地图软件(如百度地图、高德地图)和当下比较流行的LBS 应用程序(如大众点评、猫途鹰)去获取到当前地图中所有位置单元和相关的POI,并总结了吃、住、行、玩、游、生活和购物这7 种位置类型。根据获得的相关信息建立一棵语义树(Stree),该树具有4 层结构,根节点为本地地图,第2 层为基本属性,第3 层为次属性,叶子节点为地图上具有特定POI 的真实位置,S-tree 的示意图如图1所示。
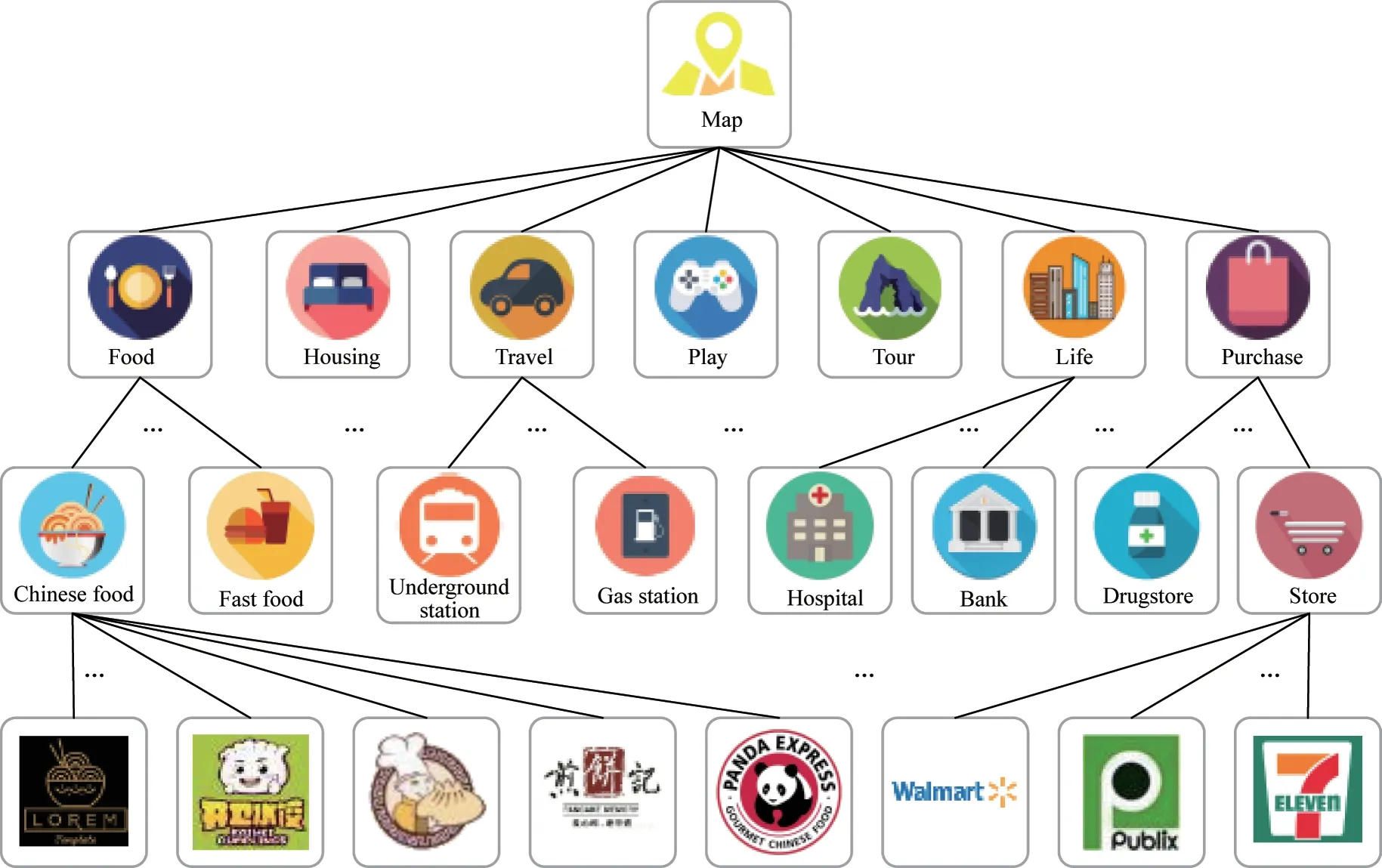
图1 S-tree 示意图Fig.1 Schematic diagram of S-tree
2.2 相关定义
定义1隐私要求:移动用户个性化的隐私需求,表示为req(k,q1,q2),其中k是匿名度,q1,q2分别是用户事先设定的假位置距真实位置的最小距离和最大距离。
定义2边信息:地图上不同的位置点都具有边信息,攻击者拥有边信息有助于推断移动用户的真实位置[19]。本文中的边信息是指位置单元的历史查询概率、POI 类型等信息。显然,用户具有这样的信息,有助于其选择最优假位置。
定义3历史查询概率pi:将地图划分成网格,不同网格代表不同的位置单元,历史查询概率由用户过去访问该位置单元的概率表示。查询概率的计算式如下:
其中:Ni表示网格划分后位置单元i的历史查询次数表示所有位置单元的历史查询次数之和。
定义4位置地理距离d:本文采用Haversine 公式来计算两位置点间的地理距离。本文计算地理距离只是用来在构建匿名集时使用,所得出的结果不涉及到更深层次的应用,使用Haversine 公式能在保证精度足够使用的前提下减少时间开销。Haversine公式如下:
由式(2)化简可得:
定义5POI 评分Si:在LBS 的应用程序中,例如yelp!和大众点评,每个POI 的打分值基于历史用户对该POI 的打分和评判,故而每个POI 的分值影响着用户的选择意愿。
定义6语义敏感等级Li:表示用户根据位置语义信息所定义的不同敏感度级别。其用来判别位置敏感程度,分为一级、二级、三级和四级,敏感程度随等级的升高而增强。语义敏感等级由用户事先设定,它是选取假位置的重要依据。
定义7位置普遍度Di:如果单个位置在某一特定用户轨迹数据集中出现的频率较高,而在其他用户的轨迹数据集中很少出现,那么对于攻击者而言,该位置具有很好的类别区分能力,根据该位置极易推测出用户的身份。根据TF-IDF 技术[20]定义位置普遍度,位置li的位置普遍度可以表示为:
定义8语义跨度语义跨度是S-tree 中li和lj两个位置对应的叶子节点之间需要经历的跳数[21]。语义跨度是衡量候选假位置优劣的重要指标,其大小通过S-tree 计算。
3 基于多属性决策模型的匿名集构建算法
假位置的选择过程具有多维度、多属性的特点,属于多属性决策的范畴。假位置的选择需要从多方面考虑,最终构建不可区分性高、位置熵大的匿名集,尽最大可能降低用户真实位置被识别的概率。在多属性决策理论中,层次分析法在信息安全领域已被用于社交媒体隐私安全量化评估研究、构建泄露数据价值评估模型等实际工作,具有良好的效果。因此本文采用多属性决策模型对假位置选择问题进行研究,且其中用到了层次分析法来计算各评价指标的属性权重。
3.1 系统架构
本文提出的基于多属性决策模型的假位置集构建算法是基于用户移动终端,采用分布式的系统架构,如图2 所示。因为该架构没有第3 方服务器参与,所以有效避免了单点泄露等问题的出现。本文系统架构主要由3 个实体组成,即移动终端、通信基站和LBS 服务器,具体介绍如下:
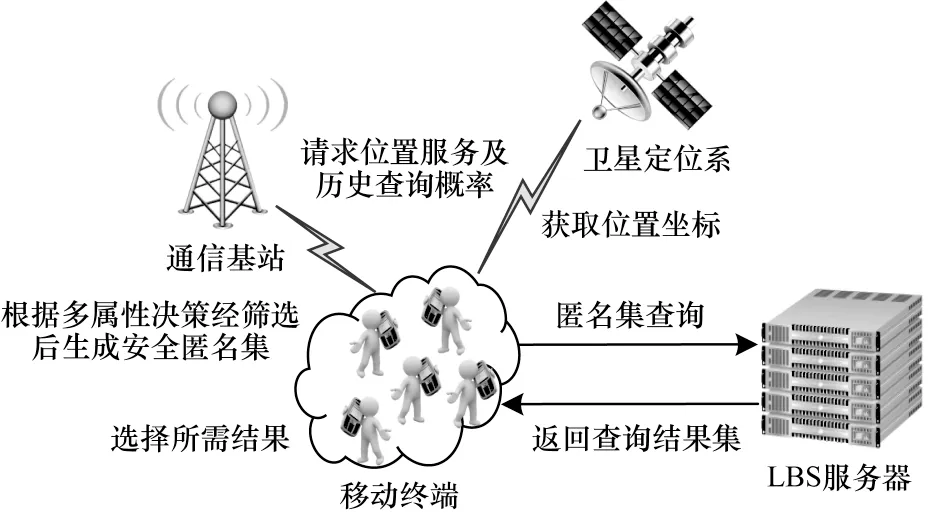
图2 系统架构Fig.2 System architecture
1)移动终端。移动终端用来执行本文提出的多属性决策方法,接着发送安全匿名集进行查询,最后在查询结果集中选择自己所需结果。各位置点的坐标由移动终端设备通过覆盖全球的卫星定位系统获取。
2)通信基站。通信基站为移动终端设备提供网络通信服务,同时对其覆盖范围内所有位置的历史查询概率进行计算并存储。如今通信基站不仅信号覆盖面广,而且其计算和存储信息的能力也较强,故可以实现本文所需功能。
3)LBS 服务器。LBS 服务器用于接收用户的位置服务请求,并返回查询结果,为用户提供位置服务。
3.2 多属性决策模型的构建与求解
多属性决策也称有限方案多目标决策,即综合考虑多种属性来选择最优备选方案,在当今决策科学中占据重要地位[22]。移动用户向LBS 服务器提交不同查询内容的假位置以及用户的真实位置,并请求获取相关服务信息。S-tree 为本文方案建立了基本的前提。这里采用基于加权算术平均(WAA)算子的多属性决策方法来进行假位置的选取。
3.2.1 基于WAA 算子的多属性决策方法
WAA 算子对决策矩阵每行中的各个数据按照权重值进行集结,以此来评估方案的优劣。其定义如下:
设WAA:Rn→R,若存在WAAw(α1,α2,…,αn)=其 中,w=(w1,w2,…,wn)是(α1,α2,…,αn)的加权向量,则称WAA 是加权算术平均算子。
明确WAA 算子的定义后,下面给出决策步骤:
步骤1确定本文所提方法的决策目标,明确方案集与指标属性集。本文的决策目标为选择符合用户隐私保护要求的最佳假位置来构建安全匿名集。设CLS 和U 分别为方案集和指标属性集。CLS=(l1,l2,…,ln)是候选假位置集,w=(w1,w2,w3,w4,w5)为决策者对5 个属性给出的属性权重。
步骤2对于任一位置li,根据不同属性的类型计算相应的属性值aij,从而构建决策矩阵A=(aij)n×m。由于各属性间量纲不同,因此需要对矩阵A进行归一化处理。归一化矩阵A后得到A'=
步骤3确定本文定义的各属性之间的优先级,利用层次分析法赋予与之对应的权重。
步骤4候选假位置集中各位置点在各目标下属性值已知时,通过WAA 算子对规范化矩阵A'中的第i行(i=1,2,…,m)数据进行计算,得到假位置的li综合属性值
3.2.2 决策矩阵的建立及归一化处理
多属性决策解决特定问题中重要的一环就是建立决策矩阵,在本文选择假位置问题上有m个备选假位置l1,l2,…,lm,5 个影响匿名集安全性的因素,包括属性POI 评分、地理距离、语义敏感等级、语义跨度、位置普遍度。利用查询概率初次筛选后得到的假位置集,根据假位置li对各属性的取值建立决策矩阵A,如表1 所示。

表1 决策矩阵Table 1 Decision matrix
多属性决策的前提是决策需要根据多个属性值来进行,这其中属性的类型一般有效益型、成本型、固定型、偏离型、区间型等,各类型的计算方法具体如下。
1)效益型。属性值越大越好,计算式如式(5)所示:
2)成本型。属性值越小越好,计算式如式(6)所示:
3)固定型。属性值与设定的固定值α间的差值越小越好,计算式如式(7)所示:
4)偏离型。属性值与设定的固定值β间的差值越大越好,计算式如式(8)所示:
5)区间型。属性值越接近设定的区间[q1,q2]越好,计算式如式(9)所示:
根据位置隐私保护的需要,将前面2.2 节定义的各种属性的类型进行分类。选取的假位置的POI 评分越高越具有真实性,较高的评分能达到更好的保护效果,故将POI 评分归类为效益型;根据用户在隐私需求中设定的假位置距真实位置的最小距离和最大距离,将地理距离归类为区间型;为了抵制基于位置语义等信息的语义攻击,选取的假位置与真实位置的语义应尽量不同,即语义跨度的值越大越具有迷惑性,能达到更好的保护效果,故将语义跨度归类为效益型;对于语义敏感等级较高的位置点,用户显然是不想暴露给他人的,而对于等级较低的位置点用户是不敏感的,所以将语义敏感等级归类为成本型;对于各位置点,在大众数据集中出现越多,位置普遍度越低,反之位置普遍度越高,应该选择相对普遍的位置来构造安全匿名集,所以将位置普遍度归类为成本型。
在确定各属性的类型后对决策矩阵A进行归一化,归一化处理后的决策矩阵如表2 所示。

表2 归一化处理后的决策矩阵Table 2 The normalized decision matrix
使用假位置生成技术构建匿名集的传统方法大多只考虑单个或少数指标属性对匿名集安全性的影响,未实现综合因素的考量,在不同程度上具有局限性,无法应对多种攻击手段。基于此,本文定义了多个指标属性,根据历史查询概率过滤掉与真实位置概率不相似的位置,有效避免了遭受基于背景知识的边信息攻击。在决策的指标属性集中加入地理距离改善位置分布,避免遭受位置同质攻击。定义语义跨度实现匿名集中假位置所包含语义信息的多样性,降低在遭受语义攻击时隐私泄露的风险。本文方案也考虑了各候选假位置的语义敏感等级、POI评分和位置普遍度,这三者在提高安全匿名集中各假位置真实性的同时增强了其与真实位置的不可区分性。综上所述,本文方法实现了综合因素的考量,在保护用户的位置隐私方面具有完备性。
3.2.3 层次分析法计算属性权重
层次分析法[23]通过分析每两个属性之间的关系构建成对比较矩阵,根据要实现的目标把问题分解成不同层次,经过比较和计算,从而较为合理地确定各属性的权重。在本文基于AHP 的位置隐私评价体系的构建中,主要有以下4 个步骤:
步骤1层次分析法首先对问题进行层次化处理,依据问题的本质及要实现的总目标将问题分解成不同的组成要素,按要素之间从属关系和相互间的联系形成多层次分析结构模型。本文将语义跨度、位置普遍度、语义敏感等级、地理距离和POI 评分这5 个影响匿名集安全性的因素作为选取假位置的主要依据。图3 给出了本文提到的多种属性的层次结构模型,该图建立了3 个层次结构,分别是目标层、准则层和方案层。
“按行消元,逐行规格化”的计算过程决定了其不适合应用对角元以右元素与对角元以下元素的对称性进行计算,因为在这种计算方式下,对第i行元素进行消元,要通过赋值分别或者一次性地得到其对角元以左的第1~i-1个元素就显得极为不便。因此这种计算方式对A阵元素的前代过程有大量的多余计算,从而导致计算效率不高。如果仅计算包括对角元素的上三角元素或包括对角元素的下三角元素,而通过对称性来获得另一半元素,则由于上下三角元素的不等,在对A阵或F阵元素的前代过程中会出现大量乘或除对角元素的重复计算,同样影响计算效率。

图3 层次结构图Fig.3 Hierarchy diagram
步骤2层次分析法要求使用者在每两个指标间比较两者的相对重要程度,根据其重要性的量化值,进而构造出成对比较矩阵。本文采用表3 所示的1-9 标度来评估每两个属性间的相对重要性。

表3 指标相对重要性等级Table 3 Index relative importance level
根据表3 对5 个属性构建成对比较矩阵B5×5,B5×5=aij(i,j=1,2,3,4,5),其 中aij为属性i相比于属性j的重要程度。
步骤3为了确保最终结果的科学性和可靠性,需要对该矩阵进行一致性检验。一致性检验的标准为当CR<0.1 时,说明成对比较矩阵通过了一致性检验。CR的计算式如式(10)所示:
其中:CI指标的计算如式(11)所示,RI为与n对应的平均随机一致性取值。
其中:λmax为成对比较矩阵的最大特征根;n为矩阵的阶数。λmax的计算式如式(12)所示:
由式(12)计算可得到成对比较矩阵B的最大特征根λmax,进而求得CI。根据表4 得出当n=5 时RI=1.12。当CR<0.1 时,说明该矩阵通过了一致性检验。
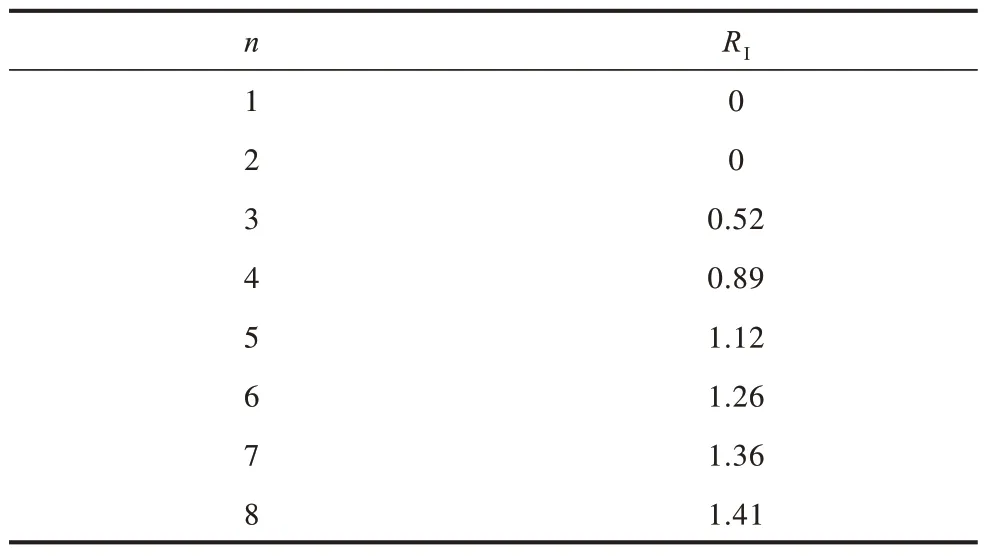
表4 随机一致性指标RI 的数值Table 4 Value of stochastic consistency indicator RI
步骤4在矩阵通过一致性检验之后,根据成对比较矩阵计算出w1到w5的属性权重。本文为了获取较为理想的权重准确度,根据对位置隐私的了解和参与程度,选取该领域多名教授组成专家组,对其进行问卷调查后得到各指标之间的相对重要程度,并分别构建成对比较矩阵。接着依据群决策数据集结方式中的结果权重加权算术平均法得到地理距离、语义跨度、POI 评分、位置普遍度、语义敏感等级的属性权重依次为0.068 8、0.324 5、0.048 3、0.315 4、0.242 9。
值得一提的是,权重值越大的指标,说明其对匿名集安全性的影响越强,与其他属性的差异也越大。某候选假位置在这些属性值高的情况下,经多属性决策被选为最优假位置的可能性也较高。
3.3 算法描述
本文提出MDMASC 算法,该算法充分考虑了多个维度的影响因素对假位置安全性的影响,最后构造出一组包含用户真实位置且大小为k的安全匿名集SAS。该算法的主要流程如图4 所示。
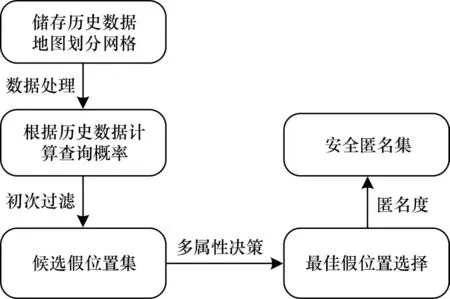
图4 MDMASC 算法的流程Fig.4 Procedure of MDMASC algorithm
下面给出了本文算法的伪代码表示。
算法1MDMASC 算法
4 实验与结果分析
4.1 实验环境
本文使用真实数据集GeoLife[24]来进行实验仿真。该数据集包含了不同用户大量的轨迹数据,其中不仅包括上下班通勤、购物等日常生活常规的生活轨迹,还包括餐饮、就医、健身、登山等遍及不同领域的户外活动轨迹。数据集中大部分轨迹都是在中国北京市创建的,市区已经被通信基站全面覆盖且拥有大批的移动用户,各用户的轨迹数据集中都包含不同位置点的纬度、经度,使用这些位置点信息作为用户的历史信息来计算历史查询概率。
实验选用数据集中北京市中心城区10 km×10 km 矩形区域内位置地理信息,将样本空间均匀划分为100×100 个位置单元。将得到的样本轨迹点作为历史数据,基于此来计算网格划分后各位置单元的历史查询概率。为了得到S-tree 中的各个节点,从谷歌地图API 和大众点评中收集,得到7 548 个叶子节点。
实验运行的环境是Intel®CoreTMi5-9300H 2.40 GHz 处理器,16 G 内存的Windows10 操作系统。实验参数如表5 所示。
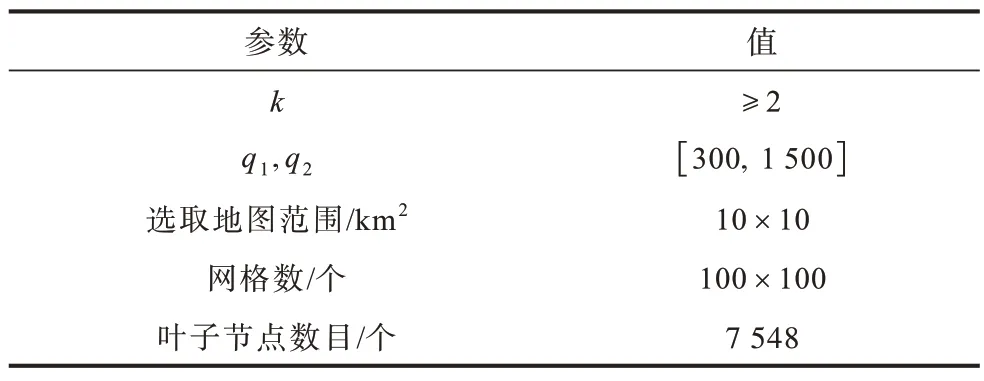
表5 实验参数Table 5 Experimental parameters
4.2 结果分析
实验从匿名集生成时间、语义多样性、攻击算法识别概率以及位置熵这4 个方面评估本文算法,并将其与同样使用假位置生成技术的DLP 算法[12]、MMDS 算法[15]、K-DLS 算法[13]进行比较。
4.2.1 匿名集生成时间
构建匿名集的一个重要指标就是匿名集的生成时间,本文算法的时间开销主要集中在多个指标值的计算上。图5 为本文算法与DLP 算法、MMDS 算法和K-DLS 算法的实验结果对比,其中图5(a)为不同算法生成匿名集的平均时间对比。由图5(a)可以看出,4 种算法构建匿名集所需要的时间均随着匿名度k的增加而增多。当k较小时,几种算法假位置生成时间相差无几。随着匿名度k的增加,DLP 算法假位置生成时间最少,MDMASC 算法次之,另外两种算法所需时间高于本文算法,MDMASC 算法相对于MMDS 算法降低了约10.3%的时间开销。由于DLP算法在构建匿名集时没有考虑到语义信息,故运行时间最少,而本文算法在考虑各位置单元查询概率的同时还要进行语义跨度、语义敏感等级等多种属性的决策过程,需要消耗一定的时间,因此其匿名集生成时间略高于DLP 算法。

图5 不同算法的实验结果对比Fig.5 Comparison of experimental results of different algorithms
4.2.2 语义多样性比较
采用文献[15]提出的θ-安全值评估算法提交匿名集的语义多样性,θ-安全值越大表示构建的匿名集中各假位置所属的语义信息越丰富,攻击者越难确定用户的真实位置。图5(b)为本文算法与DLP算法、MMDS 算法和K-DLS 算法的语义多样性对比。
由图5(b)可以看出,随着匿名度k的增加,MMDS 算法的θ值变化幅度最小且维持在较高的水平。本文算法的θ值也能维持在相对较高水平,可以满足语义多样性的要求。但本文算法略低于MMDS 算法,这是因为MMDS 只关注了位置语义对匿名集的影响,而本文算法在构建安全匿名集时虽然也考虑了位置语义,但是语义信息并不是构建安全匿名集的唯一标准,在现实生活中的不同场景下显然本文算法更具实用性。DLP 算法和K-DLS 算法的θ值均处于相对较低水平,这是因为它们在构建匿名集时只关注了查询概率,没有注意到选取的假位置可能与用户真实位置具有相同语义信息的情况。
4.2.3 攻击算法识别概率
尽管用户提交了匿名集,但是仍存在被攻击算法识别的可能,用户的真实位置被攻击算法识别的概率Q的计算式如下:
其中:C是根据假位置生成算法得到的匿名集,C={l1,l2,…,lk},|Cnum|=k。
为了对比考虑位置语义信息、语义敏感度等属性对用户真实位置保护的优势,采用式(13)度量匿名集的安全性,将本文算法与DLP 算法、MMDS 算法和K-DLS 算法在语义攻击下被识别的概率进行对比,结果如图5(c)所示。
由图5(c)可以看出,随着匿名度k逐渐增大,各算法被攻击算法识别的概率逐渐降低,这是由于匿名集扩大导致其中各假位置间的语义差异性逐渐减小,攻击者使用语义攻击的成功率更高。DLP 算法和K-DLS 算法在选取假位置时未考虑位置语义信息对匿名集安全性的影响,所以隐私保护效果较差,在攻击算法下的位置识别率高于另外两种算法。尽管MMDS 算法关注了位置语义信息,但其对位置敏感程度等属性未做分析,衡量结果不够精确。
本文算法的被识别概率要略低于其他3 种算法,比MMDS 算法和K-DLS 算法分别降低了14.9%和25.5%。这是因为用户在构建安全匿名集时,不仅考虑了历史查询概率,也考虑到了位置普遍程度、语义信息以及各用户设定的不同敏感等级等属性对其安全性的影响。攻击者在进行语义攻击的同时即使具备边信息也难以提高推测概率,同时本文算法对不同用户在位置敏感等级的设定上满足了个人需求,体现了一定的个性化。
4.2.4 位置熵
应用文献[25]中的位置熵度量位置隐私保护的有效性。位置熵值与匿名化程度呈正相关,两者的变化具有同向性,熵值越大,匿名化程度越高。图5(d)为本文 方法与DLP 算 法、MMDS 算法和K-DLS 算法在不同匿名度下生成匿名集的位置熵对比。
由图5(d)可以看出,随着匿名度k的增加,各算法的位置熵值都在增大。但是不难发现本文算法的位置熵提升幅度要高于另外3 种算法,这是因为在构建安全匿名集时本文算法综合考虑了假位置的位置语义、位置普遍度、位置敏感程度等多种属性值可能对匿名安全性造成的影响,增强了用户真实位置的不确定性,匿名集的安全性得到了保障,有利于用户位置隐私的保护。
5 结束语
本文提出的MDMASC 算法综合考虑位置所具有的多种因素来构建安全匿名集所需的假位置。通过历史查询概率判断得到构建候选假位置集,对定义的5 个属性值进行数据预处理,通过分析属性间的关系确定属性权重,最终进行综合决策以筛选出最优假位置。实验分别从匿名集生成时间、语义多样性、攻击算法识别概率、位置熵等4 个方面将本文算法与DLP 算 法、MMDS 算 法、K-DLS 算法进行比较,实验结果显示,使用本文MDMASC 算法构建的安全匿名集位置熵值更高,能够生成区分度高、合理性强的安全匿名集。然而本文只是在单位置点上研究了隐私保护,未考虑位置随时间的变化问题,而在短时间内用户位置大多以轨迹呈现,因此下一步将通过研究用户轨迹的隐私保护,从而完善隐私保护方案。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
自动化学报(2021年8期)2021-09-28
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
开放教育研究(2020年2期)2020-03-31
爱你(2018年16期)2018-06-21
现代语文(2016年21期)2016-05-25
指挥与控制学报(2015年4期)2015-11-01
大连民族大学学报(2015年2期)2015-02-27
