
基于图神经网络的不平衡欺诈检测研究
2023-11-18 03:32陈安琪邝祝芳黄华军
计算机工程 2023年11期
陈安琪,陈 睿,邝祝芳,黄华军
(1.中南林业科技大学 计算机与信息工程学院,长沙 410004;2.湖南财政经济学院 信息技术与管理学院,长沙 410205)
0 概述
欺诈检测是一种寻找具有虚假行为的数据点的过程,它以欺诈侦测[1]、网络监控[2]、公共安全和保安[3]、入侵检测[4]、医疗问题[5]、金融欺诈[6]等形式在人们身边发生。因此,欺诈检测是保证网络用户安全的一项重要任务。由于图可以对现实世界中的关系进行良好建模[7],随着图形数据变得无处不在,基于图形的欺诈检测[8]已经成为当前研究的焦点。
基于图的欺诈检测可以帮助用户找到垃圾邮件发送者[9]、恶意信息的扩散[10]、虚假评论[11]或恶意活动[12]。通过分析大型图形来发现异常也可以得到关于图形结构的重要和有趣的信息,基于图的欺诈检测旨在区分图数据中的欺诈者和普通用户,本质上是图上的半监督二元节点分类问题。与传统的基于图的模型相比,基于图神经网络(Graph Neural Network,GNN)的方法可以以端到端和半监督的方式进行训练,这节省了大量的特征工程和数据标注成本,被广泛用于检测欺诈者。文献[13]致力于调查基于图的欺诈检测中的上下文、特征和关系不一致问题。为了增强 GNN 中的聚合过程,根据预定义的阈值过滤节点的不同邻居。文献[14]通过强化学习对每个节点的一跳邻域进行自适应采样选择与中心节点更相似的邻居节点聚合。然而,在欺诈检测任务中,欺诈者的人数可能远远少于良性用户,这些模型并未考虑图数据存在不平衡的问题。
文献[15]提出一个以类为条件的对抗正则化器和一个潜在分布对齐正则化器,但不能扩展到大图。文献[16]通过对多数类进行欠采样,对少数类进行过采样来解决类不平衡问题,但它无法自适应更新采样节点的数量,可能会将多数类节点错分为少数类节点。文献[17]提出不平衡导向分类模块检测,通过最小化每个类中误分类错误率的平均值缓解类别不平衡,但时间复杂度过高,且实验效果不明显。
针对图上的类不平衡问题,将其细分为邻域不平衡和中心不平衡。根据节点类型和关系类型可以将图划分为同质图和异质图,同质图表示图中的节点类型和关系类型仅有一种,而异质图表示图中的节点类型和关系类型多于一种。对于同质图上的类不平衡问题,邻域不平衡和图的拓扑结构有关,主要是指中心节点的邻域存在局部的数量不平衡;而中心不平衡是指图中节点的数量不平衡。对于异质图上的类不平衡问题,将异质图转化为多关系图,多关系图中节点类型仅有一种,每对节点可以有不同关系类型的边,邻域不平衡是指每一个关系下中心节点的邻域存在不平衡,中心不平衡是指图节点的数量不平衡。中心不平衡是一定存在的,而邻域不平衡由于图的拓扑结构不一定存在于每个中心节点的邻域中。由于GNN 聚合机制的局限性,GNN 的性能与邻域信息的数量和质量高度相关。在多关系图类不平衡的设置中,中心节点的大多数邻居属于多数类。这也是GNN 模型在类不平衡问题中性能较差的原因。例如,对欺诈中心节点,为了不被欺诈检测器发现,往往会将自己隐藏在良性节点中,此时,欺诈中心节点的邻域大部分都是良性节点,仅有少数为欺诈节点。
为了解决上述的两类不平衡问题,本文提出一种基于GNN 的邻域与中心不平衡欺诈检测模型(NCI-GNN)。在邻域不平衡中,结合文献[14]提出的CARE-GNN 模型的自适应策略,提出一种多层自适应邻域平衡器,通过一个可学习的权重参数衡量中心节点与其邻居的相似度,考虑到权重参数的误差,使用多层网络实现欠采样过程;在中心不平衡中,优化其训练过程,使用加权交叉熵损失函数为每个中心节点的损失赋予动态权重以此达到中心平衡。
1 理论研究
1.1 定义
1)异质图
2)训练集和测试集
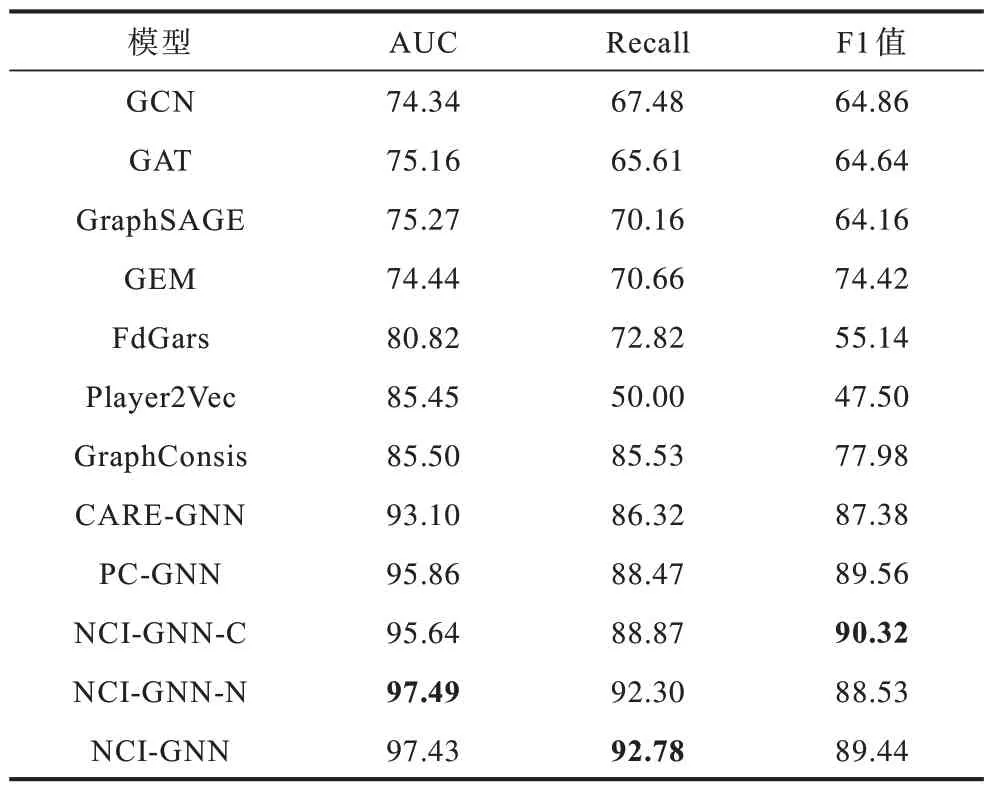
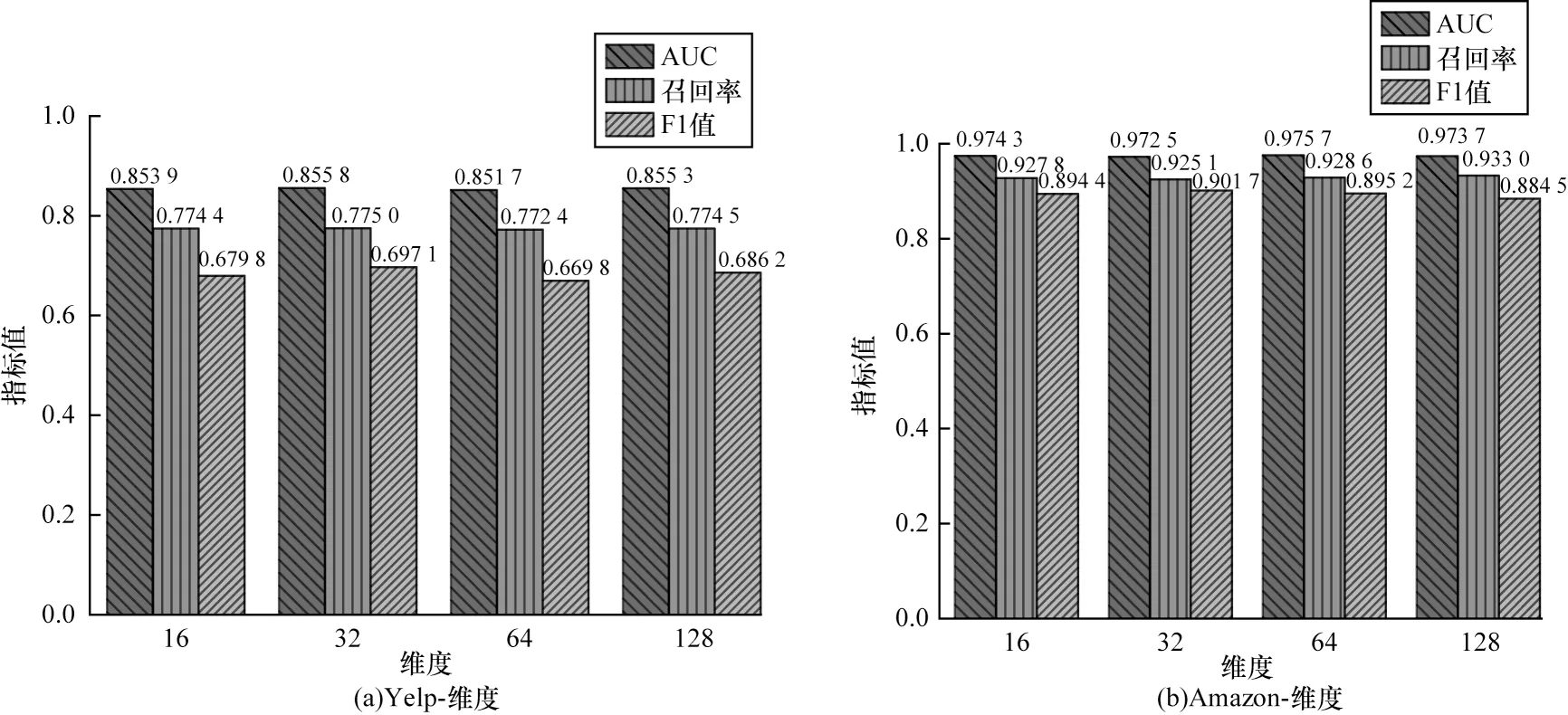
训练集Dk={vk,xk,Yk},其中,0 基于异质图的欺诈检测可以描述为不平衡节点的二分类问题。与传统的不平衡二分类问题不同,节点之间是相互独立的,图上的二分类问题需要考虑节点之间的依赖关系和拓扑结构。本文所研究的问题是如何从海量的图形化数据中寻找异常数据。 NCI-GNN 模型主要包含邻域平衡模块和中心优化模块。邻域平衡模块用于解决邻域不平衡问题,中心优化模块用于解决中心不平衡问题。模型框架如图1 所示,输入为具有关系1 和关系2 的多关系图,大写字母为训练集中心节点,标签已知,小写字母为测试集节点,标签未知,节点U、V为欺诈中心节点,节点B、C、D、E为良性中心节点。中心节点的标签是已知的,而邻域节点标签可能是未知的(当中心节点作为邻域节点时标签已知),xU为节点U的原始特征为节点V在第0 层的隐藏嵌入,也可以表述为表示节点U和节点V在第一层的相似性分数。在邻域平衡模块中,以中心节点V为例,在每一层中做衡量相似度、自适应欠采样、关系内聚合、关系间聚合操作,以此达到邻域平衡。在关系内聚合和关系间聚合时,每一层都是聚合原始特征,每一层的隐藏嵌入为当前层的关系间聚合加上前一层隐藏嵌入;在中心优化模块中,包含两部分损失,即衡量相似度损失Lossmlp和图神经网络损失Lossgnn。 图1 NCI-GNN 模型框架Fig.1 NCI-GNN model framework 在邻域平衡模块中使用多层自适应邻域平衡器对中心节点的邻域进行欠采样,主要包含相似性度量、自适应欠采样和邻居聚合3 个步骤。 步骤1为每个中心节点选择与其最相似的邻居节点。文献[18]提出使用核函数衡量节点相似度,从而把相似性量化到0 和1 之间,中心节点与邻居节点越相似,它们的距离趋近于0,则高斯核函数的值趋近于1,反之则趋近于0。由于存在邻域不平衡问题,欺诈节点通常隐藏在良性节点中,不易区分,使用原始特征的欧氏距离衡量相似度,误差较大,本文将多层感知机(Multilayer Perceptron,MLP)和高斯核函数相结合,提出一种可学习的适用于图结构数据的相似性度量,节点vi和它的邻域节点uj在l层关系r的相似性分数如下: 步骤2自适应欠采样,通过步骤1 的操作,得到为了解决邻域不平衡问题,仅进行一次采样操作是不够的,对中心节点的邻域进行多层自适应欠采样,在训练过程中,通过增加层数进行多次采样来增加模型的选择能力,为每个节点找到最相似的邻居节点。CARE-GNN 使用强化学习中的多臂老虎机算法为每个关系找到一个过滤阈值,但它的奖励为确定性奖励,无法精确地更新阈值,且根据两个epoch 之间的邻居平均距离来确定每个节点的过滤阈值,误差较大。本文基于CAREGNN 的强化学习算法,提出使用马尔可夫决策来为每个节点找到最佳的采样邻居。马尔可夫决策过程可以表述为一个四元组决策过程为A0,S0,R1,S1,…,使用即时奖励来更新动作和状态,其 中,A为动作空间,即为采 样阈值为状态 空间,表示每个batch 中的节点的邻居平均距离。 步骤3邻居聚合。GNN 通过消息传递聚合邻域信息,异质图的聚合包括关系内聚合和关系间聚合。GNN 模型由于存在过平滑问题一般无法拓展到多层,本文提出的NCI-GNN 是一个多层欺诈检测模型,这里的多层并不是GNN 传统意义上使用每一层的隐藏嵌入聚合多跳邻居。NCI-GNN 在每一层聚合操作都是针对其原始邻域和原始特征而言的,多层的目的是衡量相似度,减少MLP 层带来的误差,以此来增加模型的选择能力。在l层对中心节点vi,首先进行关系内聚合。本文使用注意力机制进行聚合: 其中:⊕表示合并操作符。在关系内聚合中,每一层聚合都是对原始特征而言的,而不是上一层的隐藏嵌入。如果在每一层中都使用上一层的隐藏嵌入来聚合邻居,必然会造成比较大的偏差,这个偏差是由于上一层的隐藏嵌入可能聚集了不相似邻居造成的。得到了节点vi在关系r下l层关系内聚合的隐藏嵌入后进行关系间聚合,依然使用注意力机制进行聚合。模型是一层一层训练的,每一层都会纠正前一层所犯的错误。此外,每一层的输入包括原始特征,这一事实使每一层能够对采样邻居做出更好的选择,但仅通过原始特征聚合无法覆盖足够多的节点信息,上一层的隐藏嵌入仍然蕴含着丰富的信息。因此,本文的目标嵌入融合了原始特征及上一层的隐藏嵌入,并将在自适应欠采样中学习的采样阈值作为关系间注意力权重。针对多层NCI-GNN,节点vi的最终嵌入如下: 中心优化模块为每个中心节点的损失进行动态加权是为了解决中心不平衡问题,这里的中心不平衡就是样本不均衡现象,现有的不平衡解决方法可分为两组,即数据采样和代价敏感学习,数据采样在一定程度上解决了正负样本比例的失衡,但其默认错误分类代价是对称的,即没有考虑分类代价的不平衡。代价敏感学习通过将不同样本的误分代价体现在学习过程中,对样本进行加权,使错误分类的总代价最低,解决比例失衡问题。在训练过程中将错分代价与损失函数相结合,通过将不同类别的错分代价加权到损失函数上,对损失函数进行优化,给一个非代价敏感分类算法添加代价敏感因子,得到一个具有倾向性的算法[19]。本文的损失L 包含MLP损失和GNN 损失。 其中:Lmlp为MLP损失函数;Lgnn为GNN损失函数;λ为超参数。通过重写交叉熵损失函数,并对其进行加权来训练MLP 和GNN 的参数以最小化损失。二分类交叉熵损失函数如下: 其中:p为真实标签集;q为预测标签集。 本文将二分类交叉熵损失函数重写为: 其中:p(x)表示x元素的真实标签;q(x,p(x))表示x元素的标签为真实标签p(x)的预测概率。对L 使用该损失函数,计算总损失。MLP 损失如下: 其中:ci表示节点vi的真实标签表示节点vi的标签为真实标签ci的预测概率,通过softmax 函数归一化得到。对MLP 仅考虑节点的原始特征,不考虑其拓扑结构,因此节点之间是相互独立的。在相互独立的节点中考虑到中心节点不平衡问题,在Lmlp中添加了两个权重参数α和β,其中,α表示易分错样本的参数,β表示数量不平衡样本参数,即: 其中:γ为超参数,一般取为2;|Vb|表示一个batch 的节点集的数目;Vc表示一个batch中标签为c的节点集,c∊{0,1};参数α主要针对难分类样本,当趋近于1 时,α趋近于0,说明该节点是易分样本,被正确分类,对损失贡献较小,相反当很小时,样本被错误分类,α趋近于1,损失函数几乎不受影响;对参数β,本文欺诈节点数目远小于良性节点,需要给欺诈节点赋予更高的权重。MLP 的损失函数如下: 在GNN 中,通过节点之间的依赖关系得到节点的最终嵌入,使得欺诈节点中难分样本较于MLP 层减少,而参数α是针对难分样本的,对GNN 的优化并不大,所以对GNN 计算损失时,不考虑易分错样本的参数α,仅考虑数量不平衡参数β。GNN 的损失函数如下: NCI-GNN 的训练过程如算法1 所示。 算法1NCI-GNN 算法 本节评估NCI-GNN 模型在两大真实的数据集上欺诈检测的有效性,介绍实验设置在数据集中的展示结果,并对NCI-GNN 进行消融实验和敏感性分析。 Yelp 数据集[15]:Yelp 数据集是美国最大的评论网站Yelp 的公开内部数据集,涵盖业务、评论、用户信息等。实验中使用评论来构建包含45 954 个节点(14.5%是欺诈评论)和3 846 979 条边的图。图中的节点之间存在3 种类型的关系: 1)R-U-R:同一用户发表的评论; 2)R-S-R:同一产品在同一星级下的评论; 3)R-T-R:同一个月发布的同一产品的评论。 Amazon 数据集[20]:是由Amazon 平台创建的开源数据集,包含24 个产品类别下的超过1.4 亿条评论和产品元数据。使用乐器下的评论,并将用户作为图的节点,图中包括11 944 个节点(9.5%是欺诈者)和4 398 392 条边。图中的节点之间存在3 种类型的关系: 1)U-P-U:至少评论过同一产品的用户; 2)U-S-U:在一周内打过相同星级的用户; 3)U-V-U:评论在TF-IDF 相似度方面排名前5%的用户。 实验将数据集中40%的数据作为训练集,60%的数据作为测试集。在模型优化中,选择一种Adam优化算法并将学习率设置为0.01。利用小批量训练技巧来提高训练效率[21],批量大小设置为256(Amazon)和1 024(Yelp)。节点的最终嵌入维度为16,NCI-GNN 模型层数为3 层。 本文研究的问题是图上不平衡节点的欺诈检测,采用曲线下面积(Area Under Curve,AUC)、召回率(Recall)和F1 值作为评估指标。AUC 表示分类模型正确判断欺诈节点的值高于良性节点的概率。Recall 表示分类模型正确分类的欺诈节点与真实数据集中欺诈节点的比值。F1 值可以看作是分类模型准确率和召回率的一种加权平均。3 个指标的值越大,模型效果越好。 邻域不平衡:使用邻域节点的标签信息表征邻域不平衡。在不同关系中,和CARE-GNN 类似,计算相邻节点对的平均标签相似度: 其中:I(u,v)∊{0,1}为指示函数;Er为边的集合。数据集统计分析结果如表1 所示。在Yelp 数据集中的R-T-R、R-S-R 和Yelp-ALL 关系中,相邻节点之间的标签相似度不足10%,在Amazon 数据集的所有关系中相邻节点之间的标签相似度不足20%,这意味欺诈中心节点在这些关系中连接大量的良性节点导致其邻域不平衡。 表1 数据集统计分析Table 1 Statistical analysis of data sets 中心不平衡:在Yelp 和Amazon 数据集中仅有14.5%和9.5%的欺诈节点,剩余为良性节点,存在数量不平衡。 基准模型如下 : GCN[22]:该模型通过在谱域中扩展图卷积来表示节点。 GAT[23]:该模型采用注意机制并构建图注意网络以提高嵌入性能。 GraphSAGE[21]:是一种空间GNN 方法,提出了4 种聚合机制,并从固定数量的采样节点聚合信息来表示节点。 GEM[24]:该模型是一个异质图神经网络模型,用于在支付宝中检测恶意账户。 FdGars[25]:该模型基于图卷积神经网络(Graph Convolutional Network,GCN)的模型,专用于检测垃圾邮件。 Player2Vec[26]:与GEM 类似,Player2Vec 也是基于GCN 的模型,专用于检测地下论坛的非法交易。 GraphConsis[13]:该模型 考虑了 图的不 一致性,并通过基于固定阈值过滤节点的不同邻居来实现。 CARE-GNN[14]:该模型考虑了图中节点的伪装行为,通过自适应阈值过滤节点的邻居。 PC-GNN[16]:该模型提出对少数类节点的邻域使用过采样,对多数类节点的邻域使用欠采样来解决图类不平衡问题。 NCI-GNN-N:本文所提出的模型的变体。在NCI-GNN-N 中使用固定阈值过滤邻域节点。 NCI-GNN-C:本文所提出的模型的变体。在NCI-GNN-C 中不考虑中心不平衡问题,使用标准的交叉熵损失函数进行训练 表2 和 表3 展示了100 个epoch 中NCI-GNN 模 型以及基准模型在两个数据集最好的测试数据,其中,加粗字体为最优值。表2 和表3 可以看出,NCI-GNN模型的性能优于11 个基准模型。对实验结果进行分析如下: 表2 100 个epoch 中Yelp 数据集欺诈检测模型的性能Table 2 Performance of the fraud detection model in the Yelp dataset in 100 epochs % 表3 100个epoch中Amazon数据集欺诈检测模型的性能Table 3 Performance of the fraud detection model in the Amazon dataset in 100 epochs % 1)GCN、GAT、GraphSAGE 为GNN 的经典模型,将这些模型直接应用于欺诈检测问题时,并未考虑现实世界中欺诈者远远少于正常用户的问题,导致性能较差,在这3 种模型中,GAT 的效果最好,这是由于GAT 使用注意力机制为不同的邻居分配不同的聚合权重,使得不相似邻居的聚合权重非常小,在一定程度上缓解了类不平衡问题。 2)GEM、FdGars、Player2Vec、GraphConsis 和CARE-GNN 都是基于图的欺诈检测模型。GraphConsis 和 CARE-GNN 分别研究了图不一致和图节点的伪装问题,其中CARE-GNN 是目前基于图的欺诈检测中最先进的模型。NCI-GNN 同样研究图的欺诈检测,但更关注图类不平衡问题。实验结果表明,在Yelp 数据集中,NCI-GNN 模型在3 个评价指标上 分别提升了8.16%、6.79% 和7.19%。在Amazon 数据集中,NCI-GNN 模型在3 个评价指标上分别提升了4.33%、6.46%和2.06%。 3)PC-GNN 是目前基于图类不平衡的欺诈检测中最先进的模型。在Yelp 数据集中,NCI-GNN 模型在3 个评价指标上分别提升了5.52%、5.42% 和4.98%。在Amazon 数据集中,NCI-GNN 模型在AUC和Recall 评价指标中分别提升了1.57%、4.31%,F1 值与PC-GNN 基本持平。 为了证明NCI-GNN 模型的有效性,本文进行了消融实验。 1)模块有效性。为了证明邻域平衡模块和中心优化模块的有效性,提出了两个变体模型:NCIGNN-C 和NCI-GNN-N。在表2 和表3 中,NCI-GNN相比两个变体模型,在两个数据集中的AUC 和Recall 指标上都取得了较好的性能,这说明了邻域平衡模块和中心优化模块在基于图的欺诈检测类不平衡问题的有效性。 2)采样方法有效性。NCI-GNN 使用马尔可夫决策进行自适应欠采样,为了证明采样方法的有效性,设计NCI-GNN-M1 模型,该模型使用CARE-GNN 的采样方法进行自适应欠采样。不同采样方法有效性分析如图2 所示。 图2 不同采样方法有效性分析Fig.2 Effectiveness analysis of different sampling methods 从图2 的Yelp 数据集中可以看出,本文使用的采样方法在AUC 上取得了更好的结果,在Recall 指标上提升效果不明显,而Recall 指标是AUC 的纵坐标,这说明了NCI-GNN 减少了将良性节点分类为欺诈节点的概率。从Amazon 数据集中可以看出,本文使用的采样方法在Recall 上取得了更好的结果,性能也更稳定,在AUC 指标上提升效果不明显,这是由于Amazon 数据集数据量较少,节点之间联系较为密切,NCI-GNN 的采样方法能获取更精确的采样阈值,提升正确分类欺诈节点的概率。 3)层数有效性。NCI-GNN 模型是一个三层模型,为了证明三层模型的性能,将NCI-GNN-1、NCI-GNN-2和NCI-GNN-4 分别表示一层、二层和四层模型,在图3 中的Yelp 数据集中,可以看出将一层NCI-GNN模型拓展到多层对模型性能有较大提升,但多层NCI-GNN 模型之间性能差异受层数影响较小,二层模型已经拥有了较好的选择能力,四层模型效率较低且稳定性较差。在Amazon 数据集中,一层模型较为稳定,但性能相对较差,将其拓展到多层时会降低稳定性,这是因为Amazon 数据集中数量较少且每个中心节点都有许多邻域节点,多层模型会导致过拟合现象,图中四层模型的AUC 和Recall 不如二层和三层模型,三层模型在AUC 指标上表现最好,在Recall 指标中表现也相对稳定,综合两个数据集考虑,选定NCI-GNN 模型为三层,这也说明了本文模型在大数据集中表现更好。 图3 层数有效性分析Fig.3 Effectiveness analysis of layer number 4)聚合方法有效性。NCI-GNN 在每一层隐藏嵌入都是用原始特征聚合加上前一层隐藏嵌入,为了证明聚合方法的有效性,设计NCI-GNN-M2、NCIGNN-M3 模型。NCI-GNN-M2 使用传统的聚合方式,仅使用前一层的隐藏嵌入作为下一层的输入特征;NCI-GNN-M3 在每一层中仅使用原始特征聚合。从图4 的Yelp 数据集中可以看出,在42 次epoch 之后,3 个模型性能趋于稳定,NCI-GNN 的性能明显优于另外2 个模型的性能,NCI-GNN-M2 模型优于NCI-GNN-M3,这是因为原始特征聚合不足以辨别节点属性,而NCI-GNN-M2 使用前一层的隐藏嵌入作为下一层的输入特征会造成比较大的偏差,这个偏差是由于前一层的隐藏嵌入可能聚集了不相似邻居造成的,而在Amazon 数据集中,NCI-GNN 在42 次epoch 之前的AUC 和Recall 中表现最好,但 在42 次epoch 之后,3 种聚合方式的性能总体来说差异并不大,这是因为Amazon 数据集节点之间联系较为紧密,通过中心优化模块和自适应欠采样操作就足以达到目前最优的性能,聚合方式不再是主要影响因素。 本文研究NCI-GNN 的不同嵌入维度对模型性能的影响,NCI-GNN 最终嵌入维度为16,将其修改为32、64、128,并分别在Yelp 数据集和Amazon 数据集上进行实验,实验结果如图5 所示。从图5 可以看出,NCI-GNN 模型具有鲁棒性,在嵌入维度为16时具有很好的性能,但太大的嵌入维度会给内存和计算带来负担。 图5 不同维度对模型性能的影响Fig.5 Influence of different dimensions on model performance 本文提出NCI-GNN 模型来解决基于图的欺诈检测的两个不平衡问题,在邻域不平衡中,对中心节点邻域进行多层自适应欠采样平衡邻域,在中心不平衡中,采用动态加权交叉熵损失函数平衡中心节点。在Yelp 和Amazon 两个欺诈数据集上的实验结果证明了NCI-GNN 模型的有效性。下一步将研究图的拓扑结构对图不平衡的影响,并把NCI-GNN 模型扩展到图神经网络的更多应用领域,提高该模型的泛化能力。1.2 问题描述
2 NCI-GNN 模型框架
2.1 框架描述

2.2 邻域平衡模块
2.3 中心优化模块
3 实验结果与分析
3.1 数据集
3.2 实验设置及实施
3.3 评价标准
3.4 图不平衡分析

3.5 基准模型
3.6 结果分析

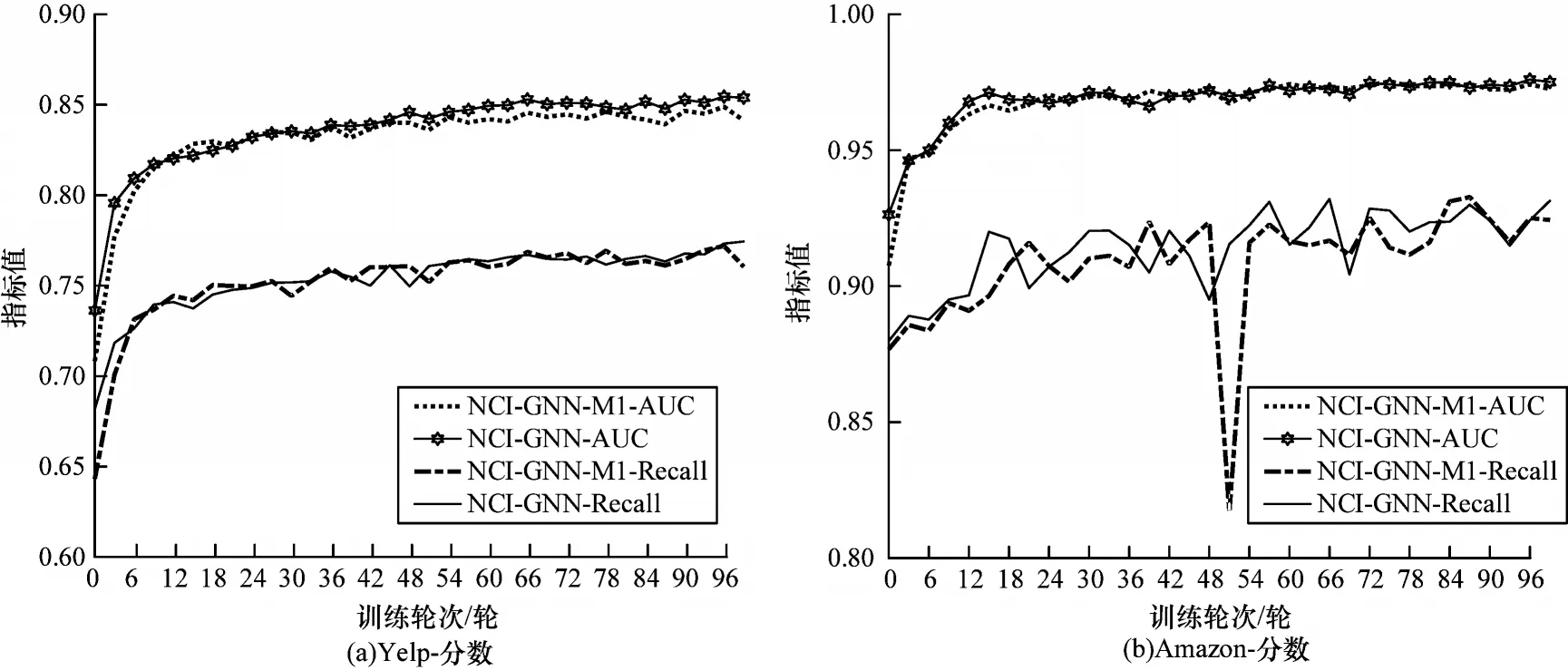
3.7 消融实验

3.8 敏感性分析
4 结束语
猜你喜欢
眼科新进展(2022年12期)2022-12-29
数学小灵通·3-4年级(2021年5期)2021-07-16
吉林大学学报(理学版)(2020年3期)2020-05-29
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
今日农业(2019年15期)2019-01-03
自动化学报(2018年7期)2018-08-20
周口师范学院学报(2016年5期)2016-10-17
公民与法治(2016年24期)2016-05-17
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
