
基于联合注意力机制和一维卷积神经网络-双向长短期记忆网络模型的流量异常检测方法
2023-11-18 08:49尹梓诺马海龙
电子与信息学报 2023年10期
尹梓诺 马海龙 胡 涛
(解放军信息工程大学信息技术研究所 郑州 450001)
1 引言
基于网络的计算服务和应用程序在人们的生活中发挥着重要作用,越来越多的网络节点设备连接到互联网中。据统计研究数据库(Statista)估计,到2025年,将有7.5×1010台设备连接到互联网,构成巨大的网络接入设备规模[1]。随着互联网规模指数级增大,网络攻击所使用的协议、操作系统和应用软件的缺陷和漏洞也在不断更新与增多。流量异常检测是保护网络和信息系统安全的有效手段,被广泛用于检测网络流量恶意行为[2]。
随着流量数据不断增加,研究人员引入机器学习方法对大规模流量数据进行分类和预测,实现流量异常检测。早期,研究人员基于传统机器学习方法进行流量异常检测,使用单个分类器[3,4]或融合多个分类器[5—8]进行检测。但研究发现以传统机器学习算法为基础的流量异常检测结果并不理想,其检测性能较依赖特征。大多强调特征工程和特征选择,具有较高的误报率[9]。
近年来,许多深度学习方法[10,11]通过神经网络的搜索空间从原始流量特征中自动提取高级特征,被应用到流量异常检测研究中,取得了一些较好的研究成果。董书琴等人[12]提出一种结合堆叠去噪自编码器和softmax的流量异常检测方法提高对NSLKDD的检测性能。缪祥华等人[13]将密集连接卷积神经网络应用于流量异常检测,提升对KDD 99数据集的检测准确率。Sivamohan等人[14]对长短期记忆网络(Long Short Term M emory,LSTM)、门控循环单元、双向长短期记忆网络3种循环神经网络在CICIDS2017数据集上的检测性能进行对比评估,发现双向长短期记忆网络(Bidirectional Long Short Term Memory,BiLSTM)的检测准确率最优。
大多数基于传统机器学习模型和深度学习模型的流量异常检测方法都需要大量样本数据进行充分学习来获取更好的检测效果。然而流量数据存在严重的类别不平衡,正常样本往往远多于异常样本,在异常样本中各攻击类流量数据所占的比例差别很大[15]。在异常数据较少、流量数据严重不平衡的情况下,将这种不平衡流量数据训练集直接输入传统分类模型进行学习和训练会导致多数类样本淹没少数类样本,少数威胁程度高的攻击流量有可能被错误检测为良性流量或其他攻击类别,这也对网络、设备、用户构成更高的风险。因此,为有效检测网络中的恶意流量,需要解决网络流量异常检测中的类别不平衡问题。
研究人员主要从数据和算法两个角度解决流量异常检测中的类别不平衡问题。在数据方面,主要通过重采样技术均衡各类流量数据,如合成少数类过采样技术(Synthetic M inority Oversam p ling TEchnique,SMOTE)[16]、自适应合成抽样技术[17]、平衡重采样技术[18,19]等。在算法方面,通过改进算法或使用集成方法[20—23]提升检测能力。但现有研究在少数类攻击流量的检出率方面还存在较大提升空间。为解决流量异常检测中的类别不平衡问题,本文提出一种基于联合注意力机制和1维卷积神经网络-双向长短期记忆网络(One-Dimensional Convolutional Neural Network-Bidirectional Long Short Term M emory,1DCNN-BiLSTM)模型的流量异常检测方法,将数据增强技术与深度学习模型相结合提升少数攻击类的检出率。本文的主要贡献如下:
(1)本文提出一种基于联合注意力机制和1DCNNBiLSTM模型的流量异常检测方法,融合数据不平衡处理技术和深度学习模型,从均衡数据和改进模型两方面出发,提高对高度不平衡流量数据的检测性能。
(2)本文设计一种联合注意力机制和1DCNNBiLSTM的深度学习混合模型用于流量异常检测,分别利用1DCNN和BiLSTM提取网络流量数据的局部与长距离序列特征,同时在1DCNN的每个块和BiLSTM末端添加有效的注意力机制,着重关注对分类起重要作用的特征,提高对少数攻击类的检出率。
(3)本文使用NSL-KDD和CICIDS2017流量数据集进行实验,利用多种评估指标将所提方法与一些现有典型机器学习方法和在流量数据不平衡问题上效果较好的方法进行对比,实验结果表明,本文方法能够显著提升少数类攻击流量的检出率,在对不平衡流量数据的检测性能上表现出优越性。
2 基于联合注意力机制和1DCNN-BiLSTM模型的流量异常检测方法
2.1 流量异常检测框架
本文设计流量异常检测方法的目标是在恶意流量样本数量较少的情况下,对流量数据实现优越的检测性能。对此,本文所提流量异常检测方法结合了数据重采样技术和深度学习网络模型,所提方法的整体检测框架如图1所示,主要包含3个模块:数据预处理模块、流量异常检测模块和分类评估模块。

图1 流量异常检测框架
数据预处理模块负责对原始流量特征数据进行量化、归一化以及训练数据重采样等操作,量化和归一化使数据能满足深度学习模型的输入格式要求,更有利于模型的训练和检测,数据重采样能够使流量数据均衡,减轻原始数据类别不平衡对检测结果造成的影响和偏差。
在流量异常检测模块,本文对预处理后的流量数据设计一种联合注意力机制和1DCNN-BiLSTM的模型进行深度流量特征提取和学习,同时对特征重要性予以考虑,有效检测数量少且威胁程度高的攻击流量。
在分类评估模块中,利用多种检测评价指标对模型的检测结果进行评估和分析。
2.2 数据预处理
(1)量化。流量特征数据包含非数值特征(如NSL-KDD数据集中'p rotocol type','service'和'flag'),需要将这类特征转换为数值特征,本文采用LabelEncoder()函数进行标签编码。同时,样本类别标签也需转换为数字,对于二分类,将正常和攻击标签分别编码为0和1,对于多分类,将各攻击类型进行独热编码。
(2)归一化。为缩小流量数据集中特征值间的大小差异,避免数值量级差异和单位差异对检测结果的影响,保证检测结果有效,采用M in-Max归一化方法将各特征数据映射到[0,1]区间,其公式如式(1)所示
其中,x为特征列X的各特征值,Xmin和Xmax分别为特征列X的最小值和最大值。
(3)过采样。流量数据集中不同类别的样本数量差异显著,如在NSL-KDD数据集中,正常样本的数量是提权攻击(User-to-Root,U 2R)样本的1 000多倍。深度学习分类器在模型训练过程中,对少数类攻击样本的特征学习不充分,会影响模型的检测性能。因此在数据预处理过程中,需要对少数类攻击流量过采样,使深度学习模型能充分有效地学习流量样本空间中每个类的边界,边界样本对泛化更重要,但它们更容易发生错误分类。对流量异常检测,需要新合成的攻击类样本处于类别边界附近来提供足够的信息用于学习和检测。本文利用borderlineSMOTE算法对异常流量样本进行过采样,首先识别边缘的攻击样本,然后重新生成攻击样本,最后将新生成的样本加入到流量数据训练集。
对于训练集中每个攻击样本x,计算其m个最近邻,若x的最近邻中,正常样本的数量多于攻击样本,那么x作为攻击类的边界样本很可能被错分为正常样本,需对这类边界样本过采样。在采样过程中,计算攻击样本x的k个最近邻攻击样本,并从中随机选择n个(1<n<k)攻击样本,攻击类流量新样本的生成公式如式(2)所示
其中,Tn为新生成的样本,Ti为边界样本,Tj为Ti的邻居,rand(0,1)表示生成[0,1]区间的随机数。
2.3 联合注意力机制和1DCNN-BiLSTM的流量检测模型
流量数据本质上可以看作具有前后关联关系的序列数据,因此流量特征数据也具有显著的前后序列依赖关系和同一序列不同特征间的关联关系,如NSL-KDD数据集的Probe攻击可能表现为流量特征在一段时间的持续变化,对于该攻击类型,可以利用序列学习模型学习数据集中“基于主机的流量统计特征”和“基于时间的流量统计特征”来捕获时间前后流量数据的关联关系和深层特征进行检测。
为提升对少数攻击流量的检出率,本文设计一种联合注意力机制和1DCNN-BiLSTM的流量异常检测模型,对流量特征数据进行充分学习,有效提取其深层复杂特征。在该模型中,1DCNN适用于序列处理,可以实现更多非线性转换,对流量序列特征提供较强的局部特征学习能力。网络流量数据遵循时间序列模式,可以根据过去跨长距离的流量连接记录对当前流量连接记录进行分类,但1DCNN在长距离学习建模方面的能力有限。BiLSTM网络主要用于实现长距离序列特征学习。因此,将1DCNN提取的深度流量特征输入BiLSTM,进一步学习深度流量特征向量之间跨长距离的序列关联模式。为进一步提升模型对不平衡流量数据的检测性能,本文在模型中加入有效注意力层,附加在1DCNN网络的各池化层末端和BiLSTM网络末端,在学习特征的过程中,提高与流量类别相关特征的权重,使模型倾向于注意对异常流量检测更重要的特征。根据特征重要性调整权值,更全面地把握流量特征,提高少数类攻击流量的检出率。
联合注意力机制和1DCNN-BiLSTM的模型可以学习正常和恶意流量数据序列的相关性与局部特征,具有多层结构,包括1维卷积层(Conv1D layer)、池化层(Poo ling layer)、注意力层(A tten tion layer)、双向长短期记忆网络层(BiLSTM layer)、平铺层(F latten layer)和全连接层(Fu ll Connection layer,FC layer)等,其模型结构如图2所示。将经过预处理的流量数据通过输入层输入模型后,利用隐层计算得到检测结果,通过输出层输出。

图2 联合注意力机制和1DCNN-BiLSTM模型结构图
2.3.1 1DCNN
1DCNN是一种以1维网格形式获取序列数据进行特征识别的CNN。虽然1DCNN只有1个维度,但它在特征识别方面同样具有2DCNN的平移不变性优势。基于此,本文将流量特征数据构建为具有良性和恶意标签的序列数据,首先应用1DCNN实现对流量数据的局部特征提取。1DCNN模型通过堆叠1维卷积层和池化层来实现局部空间特征提取功能,解决局部特征丢失问题,其结构如图3所示。
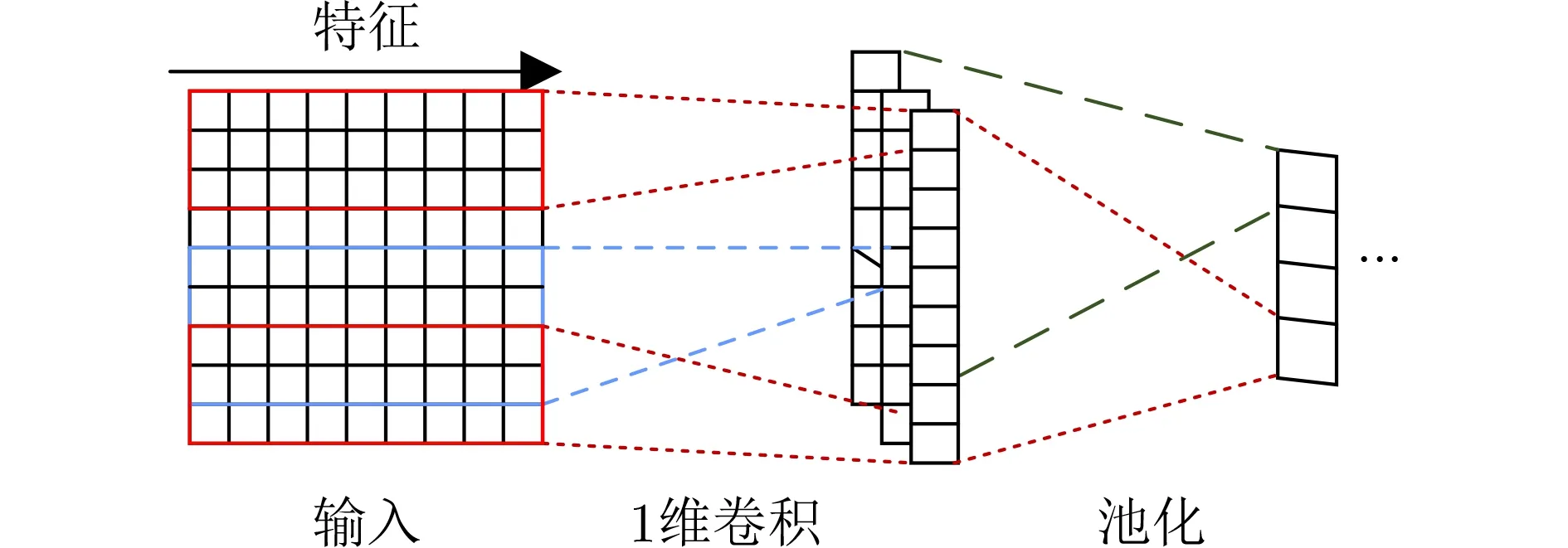
图3 1DCNN结构图
1维卷积层是特征提取的关键,它通过训练流量数据得到一组具有最小损失的最优卷积核,利用卷积核(滤波器)自动提取复杂流量特征。流量数据的第i个样本可表示为m维特征向量xi∈R m,多个连续向量x i,x i+1,...,x j可表示为xi:j,1维卷积仅在流量特征数据序列的垂直方向进行卷积,因此其卷积核的宽度即为流量特征的维度,通过使用滤波器w对输入流量数据应用卷积操作来构建一个特征映射,实现局部空间特征提取,其计算公式如式(3)所示
其中,b为偏置值,f(·)表示卷积计算的非线性激活函数线性整流函数(Rectified Linear Unit,ReLU)。
池化层进一步聚集和保留了卷积层所提取的短期特征,得到最重要的特征。常用的池化方法是最大池化和平均池化。本文利用最大池化层将各卷积层特征向量的最大值合并,作为最终特征值。在1维卷积层和池化层进行操作后,得到了一个1×n维的数据特征,很好地分析并保留流量数据序列的局部特征。
2.3.2 BiLSTM
BiLSTM是一种LSTM变体,它不仅具有LSTM模型的远距离序列学习能力,而且进一步改进LSTM,能够学习序列数据正向和反向的关联关系,使模型在分类问题上更具优势。本文利用输入流量数据训练BiLSTM的正向LSTM和反向LSTM,其结构如图4所示,包含输入层、正向隐层、反向隐层和输出层。正向LSTM提取输入的深度流量特征序列的正向特征,而反向LSTM与之相反,提取深度流量特征序列从后往前的反向特征。输出层对二者的输出数据进行整合。在时间步t利用BiLSTM模型对当前时刻的输入序列元素值xt进行特征提取的正向LSTM和反向LSTM计算如算法1所示。

图4 BiLSTM结构图
时间步t上输出向量计算公式如式(4)所示

算法1 正向LSTM和反向LSTM计算
其中,xt为t时刻的输入序列,Ct为t时刻的记忆细胞状态,ht-1为隐层状态,Wc,W f,W i,W o分别为记忆细胞状态、遗忘门、输入门和输出门的权重矩阵,bc,b f,b i,b o分别表示对应偏置,⊙表示两个向量对应元素相乘操作,分别表示正向和反向输入到隐层权重矩阵。
BiLSTM有效利用网络流量前后数据中存在的时序特征来改进模型训练,使模型全面学习序列特征。
2.3.3注意力机制
注意力机制的原理是:在大量信息中,将有限的注意力资源聚焦于需要关注的少数关键信息上,忽略无用和不相关信息,对更关键重要的信息进行特征提取。在流量异常检测领域,通过引入注意力机制,对用于检测攻击的不同流量特征赋予对应的权重,更有利于提高少数攻击样本的检出率。本文在1DCNN网络和BiLSTM网络中分别引入注意力机制。对于1DCNN,将注意力层附加在卷积块末端,改善卷积神经网络仅关注局部特征而导致对全局特征学习不准确的情况。对于BiLSTM,注意力机制对其隐层向量输出表达式进行加权求和,检测效果更优。注意力机制通过分配概率代替原始随机分配权重。将卷积块或BiLSTM得到的隐层向量ht作为注意力层的输入,其处理过程如式(5)—式(7)所示
其中,at为权重,st为对ht加权求和得到的高级流量特征。最后将st输入到全连接层,得到检测结果。
3 实验分析
3.1 实验环境、评估指标和超参数配置
本文的所有实验均在一台具有32 GB内存、In tel Core i7-8700 3.20 GHz CPU和Nv id ia GeForce GT 730 GPU的台式机上进行,使用Python3.5编程,对NSL-KDD和CICIDS2017数据集进行实验,以评估其检测多种经典攻击和现代攻击的有效性。本文使用评估指标准确率(Accuracy)、精确率(Precision)、检出率(Detection Rate,DR)、误报率(False Positive Rate,FPR)和F1-score来评估模型的检测性能。评估指标的计算公式如式(8)所示
其中,TP为正确预测为攻击样本的数量,TN为正确预测为正常样本的数量,FP为错误预测为攻击样本的数量,FN为错误预测为正常样本的数量。
由于深度学习模型具有参数化特性,模型的训练和检测结果受参数的影响较大。本文设计的联合注意力机制和1DCNN-BiLSTM的模型结构同2.3节的结构图一致。3个卷积层的卷积核数为64-128-32,3个最大池化层的poolsize设置为1。池化层的输出作为注意力层输入,1DCNN网络中最后一个注意力层的输出作为BiLSTM网络的输入,BiLSTM包含64个单元,其后的dropout层参数为0.5,用于防止过拟合,其后附加注意力层,之后连接Flatten平铺层用于将多维输出1维化,输出层使用全连接层,将模型的输出向量转换为类别标签的维度。对于二分类,输出层包含1个单元,激活函数为sigm oid,用于区分正常和攻击类型;对于多分类,输出层包含n个单元(n为样本类别数),激活函数为softm ax,用于区分多个攻击类型。经过多次调整模型的超参数,得到使模型学习效果最佳的超参数配置。模型的超参数配置为:训练过程损失函数为categorical_crossentropy,采用Adam优化器,学习率为0.001,Epoch=30,Batchsize=32。
3.2 数据集
NSL-KDD数据集KDD CUP 99数据集的改进,广泛用于流量异常检测。尽管还有其他更新的数据集,但它仍然被许多最先进的流量异常检测文献用于性能评估。它删除了数据集中的冗余记录,包含正常样本和4种攻击样本,攻击类别包含DoS,Probe,U2R,R2L。该数据集包含41维流量特征和1维类别标签。在实验中,将KDDT rain+_20 Percent作为训练集,KDDTest+为测试集。其数据分布如表1所示。

表1 NSL-KDD数据集数据分布
CICIDS2017数据集由通信安全机构(Communications Security Establishment,CSE)与加拿大网络安全研究所(Canadian Institute for Cybersecurity,CIC)在2017年收集,是一个具有复杂现代攻击类型的流量数据集。该数据集含有3 119 345个网络传输样本、78维流量特征和1维类别标签,包含正常样本和14种攻击样本。此外,该数据集中包含一些标签和特征缺失的样本,删除这些样本后,共得到2 824 876个样本,其数据分布如表2所示。

表2 CICIDS2017数据集数据分布
3.3 二分类实验
本节基于NSL-KDD和CICIDS2017数据集对流量异常检测方法进行二分类实验。
为验证本文模型的检测性能,实验先比较了3种机器学习的典型分类方法以及在类别不平衡问题上当前较流行且检测效果较好的3种模型在NSLKDD数据集上的检测性能。3种机器学习方法分别为典型的随机森林(Random Forest,RF)、多层感知机(M u ltiLayer Percep tron,M LP)和组合模型1DCNN-BiLSTM,3种文献模型分别为文献[14]提出的BiLSTM模型,文献[19]提出的深度CNN模型以及文献[23]提出的朴素贝叶斯决策表和多目标进化特征选择(Naïve Bayes Decision Tab le and M ulti Objective Evolutionary Feature Selection,DTNB+MOEFS)组合模型。同时为验证BorderlineSMOTE的有效性,本实验还比较了模型在不采用重采样方法、采用随机过采样(Random Over-Sam p ling,ROS)方法以及采用Bo rder lineSMOTE过采样方法3种情况下对NSL-KDD数据集的检测性能。其中,ROS方法的采样思路是:从少数类攻击流量样本中随机采样复制样本,使少数类流量与多数类流量的样本量相同,从而得到新的均衡数据集。实验结果如表3所示。
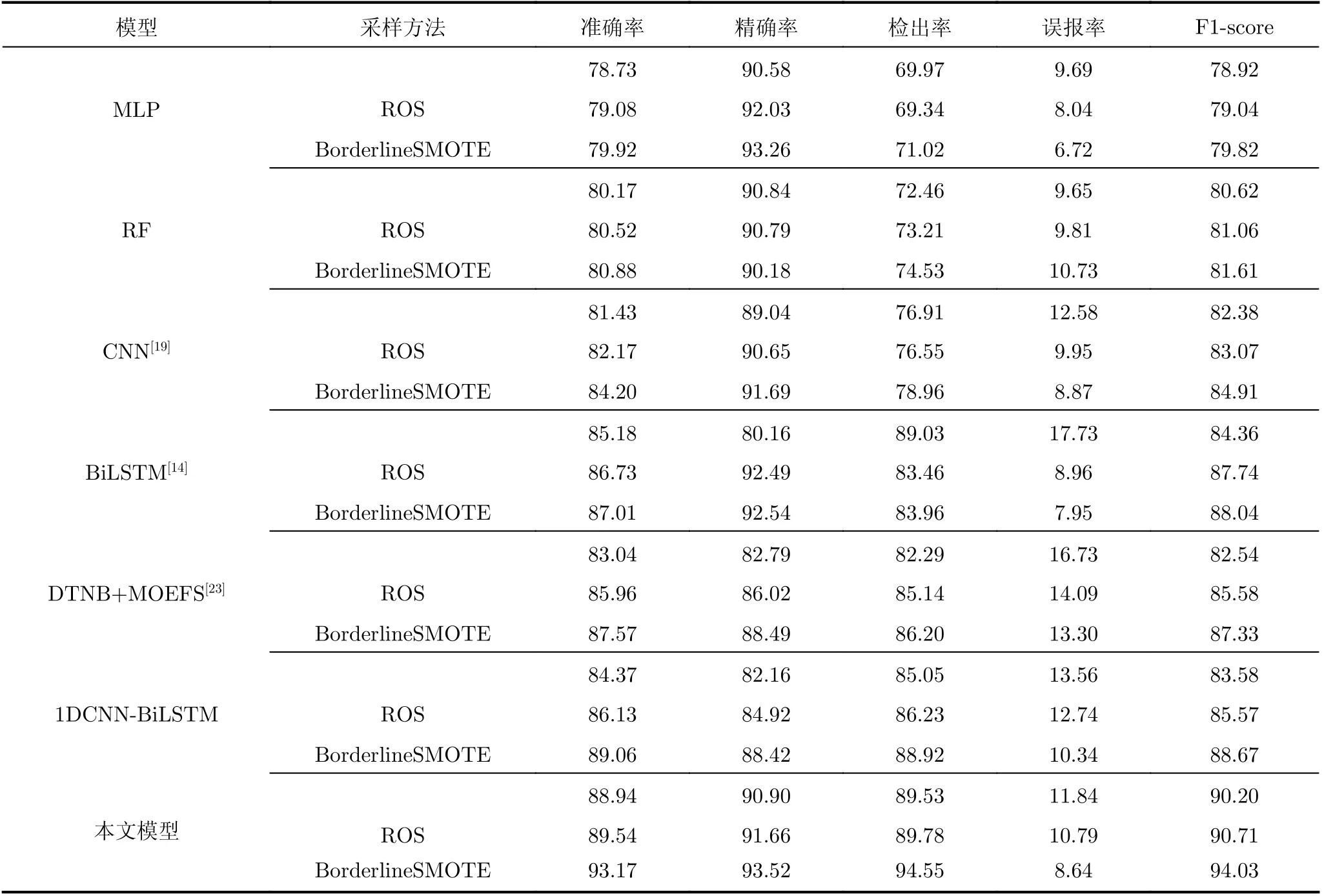
表3 基于NSL-KDD数据集的二分类检测结果(%)
从表3中观察到,在异常流量样本少于良性样本的情况下,本文方法对攻击流量取得了最高的检测准确率、精确率、检出率和F1-score,分别为93.17%,93.52%,94.55%,94.03%。本文方法的检测误报率为8.64%,相比其他模型中最低的误报率仅增加了0.69%。对于本文模型,采用BorderlineSMOTE过采样方法的检测准确率相比不采用重采样提升了4.76%,相比采用ROS过采样方法提升了4.05%。M LP和RF模型的检测准确率较低,分别为80.88%和79.92%。这是由于这两种模型在样本量较少的情况下,挖掘能力略差。因此在仅用原始训练集KDDTrain 20%样本构成的训练集KDDTrain+_20Percent进行学习时,准确学习数据特征的能力较差,检测准确率低。相比于CNN模型[19]、BiLSTM模型[14]、DTNB+MOEFS模型[23]和组合模型1DCNN-BiLSTM,本文模型的检测准确率分别提升了10.65%,7.08%,6.39%和4.61%,在精确率方面也分别提升了2.00%,1.06%,5.68%和5.77%,在检出率方面分别提升了19.74%,12.61%,9.69%和6.33%,检出率大幅提升,说明本文方法在区分正常流量和异常流量方面的检测性能优于其他模型。综上分析,本文方法对经典NSL-KDD数据集进行检测时,在正常流量与异常流量不平衡的情况下,检测性能优于其他方法,这验证了本文方法面对经典流量数据集正常和异常数据不平衡问题上的有效性。
为了评估本文方法检测新型现代攻击样本的有效性,实验在CICIDS2017数据集上进行进一步验证。由于CICIDS2017数据集数据量较大,其中良性样本占80.30%,攻击样本占19.70%。为提高实验效率,抽取10%的数据作为实验数据,训练集和测试集按照7:3的比例划分。由于上一实验已证明BorderlineSMOTE过采样方法的有效性,因此,本实验仅对比不同模型的检测性能,实验结果如表4所示。

表4 基于CICIDS2017数据集的二分类检测结果(%)
由表4可以观察到,本文的流量异常检测的准确率相比RF模型提升了2.11%,相比M LP模型提升了4.94%,相比深度CNN模型[19]提升了3.10%,相比BiLSTM模型[14]提升了0.52%,相比DTNB+MOEFS模型[23]提升了1.91%,检测效果有明显提升。所提模型的检测精确率、检出率和F1-score均高于其他方法,FPR均小于其他方法。进一步验证了本文方法对新型数据集中不平衡流量样本的检测有效性。
3.4 多分类实验
为了验证本文的流量异常检测方法区分不同攻击类型的检测有效性,实验基于NSL-KDD数据集进行模型多分类性能评估。实验对比了机器学习典型算法M LP,RF和现有流行的3种面对流量数据类别不平衡问题效果较好的模型CNN[19],BiLSTM[14],I-Siam IDS[22],不同模型的检测性能见图5—图8。

图5 基于NSL-KDD数据集的多分类检出率
图5为6种方法的检出率对比图,其中蓝色、红色、绿色、紫色、黄色分别表示各模型对正常流量、DoS攻击流量、Probe攻击流量、U2R攻击流量、R 2L攻击流量的检出率。由图5可以观察到,本文方法在正常类流量数据的检出率上略小于其他算法,其检出率为92.07%,相对于最高的RF算法,降低了5.46%。但对DoS攻击流量以及样本量较少的U2R和R2L攻击流量,本文方法相比其他方法均取得了最高的检出率,分别为93.66%,83.00%和84.66%。对U2R攻击流量的检出率,本文方法相比其他方法至少提升了13.70%。对R2L攻击流量的检出率,本文方法相比其他方法至少提升了9.78%。这一结果表明,与基准分类器相比,本文方法能够提高对样本量较少的各攻击样本的检出率,对少数类攻击样本的识别能力较好。
图6为6种方法的检测精确率对比图,其中各颜色分别表示模型对各类别流量的检测精确率。由图6可知,本文方法对DoS,Probe,R2L的检测精确率分别为98.21%,74.55%,80.08%,虽略小于个别分类器,但在所有分类模型中,本文方法对正常类和样本量较少的U2R攻击流量均取得了最高的精确率,分别为95.47%和79.05%。对于正常类和4种攻击类,本文方法相对其他方法的检测精确率更稳定。这一结果表明,本文方法对各类样本的检测精确程度良好。

图6 基于NSL-KDD数据集的多分类检测精确率
图7为6种方法的多分类检测误报率对比图,其中各颜色分别表示模型对各类别流量的检测误报率。由图可知,本文方法对正常类、DoS类均取得了最低的检测误报率,分别为3.30%和0.84%。对Probe,U2R,R2L 3类的检测误报率略高于个别基准模型,这是由于在检测过程中,本文方法将一定量正常类和DoS攻击流量数据误判为这3类数据,导致检测误报率略高,但本文方法对5类数据的误报率较小,均不超过4%。其他方法对正常样本的检测误报率较高,这是由于其他对比方法在检测过程中将一些攻击样本识别为正常样本,识别不准确,检测误报率较高,这也说明所对比其他算法无法有效应对数据不平衡问题。

图7 基于NSL-KDD数据集的多分类检测误报率
图8是6种方法的多分类检测F1-score对比图,其中各颜色分别表示模型对各类别流量的检测F1-score。F1-score更能反映模型的整体检测性能。由图8可知,本文方法对各类流量数据均取得最高的F1-score,对正常流量,DoS,Probe,U 2R,R2L攻击流量的检测F1-score分别为93.74%,95.88%,82.56%,80.98%,82.31%。这表明本文方法在保证检测精确率的同时,提升了对少数攻击流量数据的检出率。

图8 基于NSL-KDD数据集的多分类检测F1-score
从图5—图8的各项性能参数对比可以看出,本文模型无论是对样本量较多的正常流量和DoS,Probe攻击流量,还是对样本量较少的U2R,R2L攻击流量,在各个检测性能指标上都较好,虽然在个别评价指标上略差于某个分类器,但在少数攻击流量的检出率等性能上效果最好,相比其他典型模型具有明显提升,能够对少数类攻击流量有效分类。由此验证了本文方法对不平衡流量数据多分类任务的有效性和优越性。
4 结束语
考虑到流量异常检测中类别不平衡问题严重影响了对攻击流量数据的检测准确率和对少数攻击类流量的检出率,本文提出了一种基于联合注意力机制和1DCNN-BiLSTM模型的流量异常检测方法,该方法结合了类不平衡处理技术BorderlineSMOTE和混合深度学习模型。通过BorderlineSMOTE生成新的攻击数据,使各类数据均衡。同时设计了联合注意力机制和1DCNN-BiLSTM的模型对流量数据进行训练,充分提取流量数据的局部特征和长距离序列特征,更好地学习流量特征数据的前后关联关系,并对特征按重要性赋予权重,充分发挥重要特征在流量异常检测中的作用,从而提高检测准确率和检出率。本文使用NSL-KDD和CICIDS2017数据集进行训练与测试。实验结果表明,与一些现有典型的和较为流行的机器学习算法相比,本文方法在二分类和多分类的检测准确率、精确率、检出率、误报率和F1-Score 5种性能评估指标上取得了良好的效果,验证了本文方法检测不平衡攻击流量的有效性。在未来的研究中,将探索其他检测模型和方法,提高对恶意流量的检测性能,以增强模型用于实际网络流量的可能性。
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
昆明医科大学学报(2021年12期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
现代临床医学(2021年2期)2021-03-29
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国纤检(2015年8期)2015-05-08
