
基于改进DeepLabV3p的遥感图像中小目标分割方法
2023-11-17 03:01金芊芊张晓倩
成都信息工程大学学报 2023年6期
金芊芊,罗 建,张晓倩,杨 梅,李 杨
(西华师范大学电子信息工程学院,四川南充 637009)
0 引言
简单来说,遥感图像就是人们利用各类飞行器(包括无人飞机、航空卫星等)远距离对地观测所拍摄记录下来的图像,可以帮助我们实现对地观测的各项数据的分析。遥感图像的获取方式使其具有目标复杂多变、目标形态差异巨大、目标边缘不清晰等特征,因此在提高其分割精度和准确度时会遇到很多困难[1-2]。Maggiori 等[3]使用FCN[4]全卷积神经网络来提取遥感图像的地面特征,相比于传统网络有较好的表现。Li 等[5]在U-Net[6]基础上添加不对称卷积块提高了网络提取特征的能力。Zhao 等[7]提出的金字塔场景分析网络(PSPNet),应用金字塔池化模块获取更多的全局信息。Chen 等[8]提出的DeepLabV3p 模型,使用可以扩充感受野的空洞卷积,减少网络中的池化操作,保留特征层的细节信息,还提出了ASPP(atros spatial pyramid pooling)来提取不同尺度的信息,较大提升了模型的效果。DeepLabV3p 是当前较为流行的遥感图像分割算法之一。杨蜀秦等[9]在DeepLabV3p中添加多头自注意力机制来捕获无人机小麦倒伏图像中的倒伏特征;黄聪等[10]在DeepLabV3p 中引入坐标注意力机制,并且采用联级特征融合的方法来更好地利用图像的语义特征信息。以上研究虽然对Deep-LabV3p 提出一定的改进,但是提升的效果有限,仍然难以提高对遥感图像中小目标的分割精度和准确度。
综上,找到一种更有效地综合利用多尺度信息、捕捉细节信息的方式,是提高遥感图像分割精度的关键之一。因此,本文使用DeepLabV3p 作为基础网络模型,并对其做了以下改进:(1)提出一种多级感受野融合的ASPP 结构(ASPP with multi-level receptive field fusion,Rff-ASPP),获取更多感受野信息;(2)使用SE注意力机制[11]来聚焦目标区域提取全局信息,提高分割效率;(3)使用由CrossEntropyLoss 和LovaszSoftmax-Loss 损失函数[12]构成的混合损失函数替代原有的CrossEntropyLoss,克服样本不均衡问题;(4)引入全连接条件随机场进行图像后处理,将神经网络输出的预测图做进一步处理,最终得到细节分割得更加出色的输出结果。
1 模型与改进
1.1 DeepLabV3p 模型
DeepLabV3p 是DeepLab 系列语义分割网络模型的最新版本,是由DeepLabV1[13]、DeepLabV2[14]、DeepLabV3[15]发展而来。它的整体结构是encoder-decoder 结构,使用先前的DeepLabV3 作为encoder,然后在后面添加一个简单高效的decoder 来进行不同尺度信息的融合。Encoder 把Restnet101 作为骨干网络进行特征的初步提取,然后将初步提取的特征层送进ASPP模块进行加强特征提取,ASPP 通过不同大小采样率的空洞卷积来提取不同感受野的信息,最后拼接在一起得到加强特征层。Decoder 将骨干网络提取出来的低层特征和经过编码器处理的加强特征做进一步的特征融合,将不同尺度的细节信息和语义信息更好地结合在一起,减少了信息的流失,最后再通过两次3×3 的卷积对特征进行细化,通过4 倍上采样恢复图像尺寸得到输出,DeepLabV3p 结构如图1所示。

图1 DeepLabV3p 模型结构图
1.2 改进的模型:RSC-DeepLabV3p
为提高DeepLabV3p 模型对遥感图像中小目标的分割效果,本文在多个方面对模型进行改进,提出一种改进的图像分割模型——RSC-DeepLabV3p。Deep-LabV3p 的编码部分由Restnet101 骨干网络和ASPP 组成,为提高模型对多尺度信息的利用,对ASPP 模块进行改进,提出一种新的多级感受野融合的ASPP 结构。Rff-ASPP 将ASPP 中通过不同采样率卷积获得的5 个特征层,从上往下依次通过contact 函数进行融合,使其在获得不同感受野信息的同时也实现了信息的共享,得到更大范围的感受野。在解码部分,添加SE 注意力机制来聚焦目标区域,用来更好地提取全局信息,提高分割效率。
对损失函数也进行了优化,使用加权的CrossEntropyLoss 和LovaszSoftmaxLoss 损失函数相结合替代原有的多分类交叉熵损失函数。LovaszSoftmax 损失函数适用于样本不均衡的数据集,并且对于小目标比较友好,与其他损失函数一起加权使用时效果较好。为优化从改进DeepLabV3P 卷积神经网络得到的预测图,引入全连接条件随机场进行细分,不仅可以提高模型分割后的结果,而且算法复杂度也较低,RSC-Deep-LabV3p 模型结构如图2所示。

图2 RSC-DeepLabV3p 模型结构图
1.3 SE 注意力机制
SE 注意力机制主要是仿照人类的眼睛对图像重要信息的“聚焦”,只是“聚焦”的是特征层中重要的通道特征。在模型训练过程中,SE 模块通过自适应学习找出比较重要的通道特征,并且赋予其更大的权重,使模型对目标特征进行关注。这不仅可以节省计算量,还保证其在各种网络架构中的通用性。其结构如图3所示。
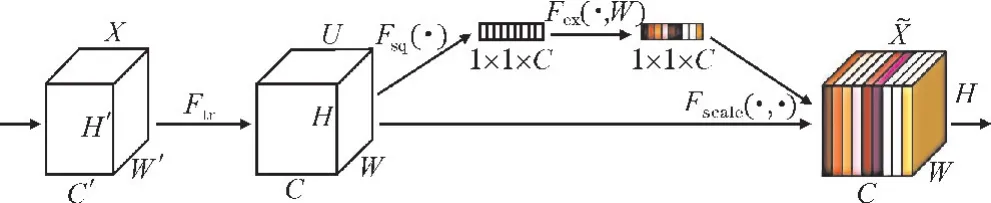
图3 SE 注意力机制结构图
SE 注意力的实现主要有以下3 个步骤:
(1)Squeeze:对获取到的多个特征图进行全局平均池化,把每个通道的特征压缩为一个数来表示,获取到每个通道的全局信息。其表达式:
式中,H为特征图的高,W为特征图的宽,c为特征通道数。
(2)Excitation:通过两个全连接层和一个sigmoid激活函数,实现权重的学习,从而找出比较重要的特征信息,减少对其他信息的关注。其表达式:
s=Fex(z,W)=σ(g(z,W))=σ(W2ReLU(W1z))
式中,σ代表sigmoid 激活函数,W1、W2代表两个全连接层。
(3)Reweight:将前面所得的权重赋值到各特征图,即将学习的权重与各个通道的原始特征相乘。其表达式:
式中,s代表学习到的权重信息,u为原始特征图。
SE 注意力机制最终能实现通道特征的增强,并且不改变其大小。因此,SE 注意力机制能够提高模型的精度,并且不改变特征图的大小。这样,在网络中添加SE 模块不用添加参数或者改变结构,SE 常被用在各种网络模型中。本文方法将SE 注意力模块添加到decoder 中层卷积之前,提高了模型对于全局特征的提取能力。
1.4 改进ASPP
ASPP 由多个不同采样率的空洞卷积并行卷积然后拼接组成,目的是为进一步提取多尺度信息。ASPP顶部使用1×1 的卷积提取特征层,第二、三、四层则使用采样率为6、12、18 的空洞卷积进行采样,提取具有不同大小的感受野的特征层,最后一层使用全局平均池化,目的是提取全局信息;然后,通过contact 函数拼接在一起;最后,通过1×1 的卷积调整特征层的形状。
本文的多级感受野融合的ASPP 结构是在FPN[16]的启发下提出的,FPN 是2017年提出的一种网络。FPN 提出了一种新的想法,就是将通过下采样获得的高层特征进行上采样然后与低层特征逐层相连接,并且在每一层都进行预测,这样就使得低层特征图得到了更充分的利用。改进ASPP 的结构为沿着ASPP 模块从上往下的方向,首先对最顶层进行一个1×1 的卷积,然后通过contact 函数将该特征层和相邻特征层拼接在一起,接着对拼接后的特征层重复刚才的操作,直到最后的池化层。这样就实现了不同感受野的特征层的信息共享,提高对感受野的利用。改进后的ASPP结构如图4所示。

图4 改进的ASPP(Rff-ASPP)
1.5 优化损失函数
损失函数是用来对模型训练效果好坏进行评判的方法,其值越小,模型训练效果就越好。遥感图像包含的目标又多又杂,并且类别十分不均衡,DeepLabV3p模型原有的多分类交叉熵损失函数虽然可以处理多分类分割问题,但是对于遥感图像这种背景像素所占比例较大且中小目标较多的图像,训练效果较差。
为了达到更好的分割效果,将CrossEntropyLoss 和LovaszSoftmaxLoss 损失函数加权结合来训练改进后的DeepLabV3p 网络模型。Berman 等[12]提出LovaszSoftmaxLoss 用于样本不均衡的数据集,并且对于小目标比较友好,但是使用该损失函数优化时主要针对的是image-level mIoU,适用于微调的过程。因此LovaszSoftmaxLoss 与其他损失函数一起加权使用时效果更优。
多分类交叉熵损失函数计算公式如下:
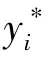
Softmax 函数公式:

Jaccard 索引,即IOU 值,图像语义分割中常使用IOU 作为评价指标,计算公式:
LovaszSoftmaxLoss 的作者使用Jaccard 索引作为损失函数,因此最终的LovaszSoftmaxLoss 表达式:
式中,y*为真实值,为预测值。
最终的损失函数为CrossEntropyLoss 和LovaszSoftmaxLoss 加权结合的混合损失函数,因此最终表达式:
式中,a、b为权重,a+b=1。
1.6 全连接条件随机场
全连接条件随机场CRFs 能够对模型预测的分割结果做进一步的处理,以改善分割图像中的边缘模糊问题[17]。一张图片由很多个像素点组成,CRFs 做的工作就是找出原始图片中各个像素点的位置信息以及颜色信息,结合改进DeepLabV3p 模型的预测概率分布图来计算像素点归类概率,然后进行推理,找出每个像素最可能的类,推理次数不同,优化效果也就不同。其推理流程如图5所示。
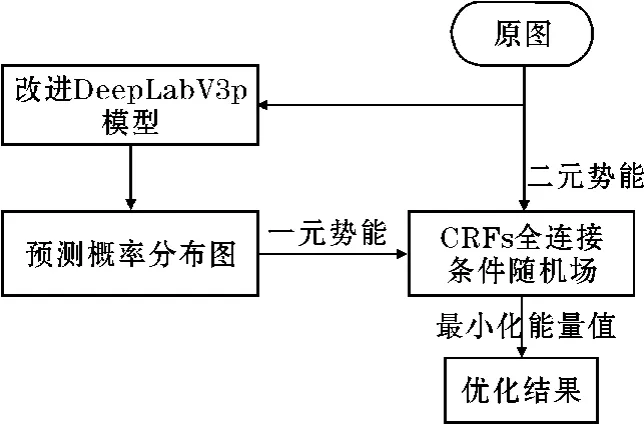
图5 CRFs 流程图
全连接条件随机场符合吉布斯分布,如下:
式中,x是观测值,E(X|I)是能量函数,该能量函数由一元势函数ψu(xi)和二元势函数ψp(xi,yi)构成,如下:
一元势函数ψu(xi)通过模型输出的预测图计算像素点i的类别为xi的概率,二元势函数ψp(xi,yi)则是通过原图中像素点的颜色值、像素点间的距离等来判断两个像素之间的关系,全连接条件随机场中的二元势函数计算每一个像素点和其他所有像素点之间的关系。通过推理,使得E(x)能量值越小,则最终相似像素点为相同类别的概率就越大。通过反复迭代最小化能量函数,可以得到最终的后处理结果。
本文将原始特征图与模型输出的预测图放入全连接随机场进行实验,进行一元势和二元势,然后通过设定推理次数来确定优化次数。利用全连接条件随机场对模型输出的预测图进行6 次推理,推理后的对比结果如图6所示。由图6 可以看出,前3 次推理取得的效果较好,后3 次由于过度推理,受颜色信息影响过大,反而优化效果不好。因此,本文选择使用3 次推理的CRFs 全连接条件随机场对模型预测图进行优化。

图6 原图与不同推理次数优化图对比
2 实验结果与讨论
2.1 数据集与实验环境
使用DLRSD 数据集,该数据集是武汉大学基于UCMerced_LandUse 数据集标注的,包括17 个类别,共2100 张图片,且大小均为256×256,其中包括建筑物、飞机、船、汽车、树木等中小目标类别。按照7 ∶2 ∶1将数据集划分为训练集、验证集以及测试集,其中对训练集采用缩放、随机裁剪、随机水平翻转、归一化等数据预处理操作。
本文实验均在百度的AI Studio 平台进行,选用PaddlePaddle 2.3.0 框架,选用硬件环境如表1所示。

表1 实验的硬件环境
使用SGD 优化算法,PolynomialDccay 学习策略,实验的各项参数如表2所示。

表2 实验的训练参数
2.2 实验评价指标
使用mIoU(交并比)、Dice(相似系数)、Kappa 系数、ACC(准确率)作为模型性能的评价指标。这几个值越大,则模型的性能越好。各指标的计算公式如下:
式中,k表示类别,k+1 表示加上背景类,tp表示预测值属于该类别并且真实值也属于该类别的像素点数目,fn表示预测是此类别但是真实类别是另一种的像素点数目,fp表示预测为其他类别而真实值属于此类别的像素点数目;A表示预测图,M表示真实标签图;po为分类器的准确率,pe为随机分类器的准确率;N表示总的像素点数目。
2.3 实验结果
2.3.1 对比实验结果与分析
基础DeepLabV3p 与改进后的DeepLabV3p 在验证集上的mIoU 值和在训练集上的loss 值曲线如图7所示,蓝色线代表本文提出的RSC-DeepLabV3p 模型,黄色线代表DeepLabV3p 模型。损失值随着迭代次数增加而降低,mIoU 值随之增加,当训练到1000 个Iters时,mIoU 值与loss 值均开始收敛。改进后的Deep-LabV3p 不仅在损失值和mIoU 值曲线的收敛速度上表现更好,并且最终的损失值更低,mIoU 值更高。

图7 改进前后DeepLabV3p 的损失函数和mIoU 值曲线
为进一步证明改进的DeepLabV3p 模型的确在遥感图像中小目标的分割上表现优秀,对当前常用的一些分割网络如U-Net、FCN、PSPNet 也进行对比实验,实验环境、数据集、训练参数等实验条件均一致,实验结果如表3所示。由表3 可知,Deeplabv3p 模型在DLRSD数据集上的综合表现均优于其他模型,而本文改进的DeepLabV3p 模型在各方面表现都优于Deep-LabV3p 模型,mIoU 为73.22%、准确率为86.48%、Kappa 系数为84.44%、dice 为82.03%,其中mIoU 和dice 较基础模型DeeplabV3p 提高了3.78%、2.58%。说明本文改进的方法分割效果较好,有利于遥感图像中小目标的分割。

表3 不同网络模型评估对比 单位:%
为更直观地体现改进模型的性能,分别使用不同模型进行推理,并对其中部分结果进行可视化分析。图8 的4 组图片是各模型分别对包含飞机、住宅、港口等目标的遥感图像进行分割的结果。可以看出,与UNet、FCN 等相比,DeepLabV3p 模型在分割轮廓上表现更好。如图8(a)所示,DeepLabV3p 完整地分割出了港口上每一艘船的轮廓,其中穿插的道路的分割形状也比较完整,而U-Net、FCN 分割边缘十分粗糙,FCN只能分割出船只的大体位置,且部分道路分割不完整;与DeepLabV3p 相比,RSC-DeepLabV3p 则表现更好,本文模型在船只和道路的细节上分割得更加清楚,每一艘船中间间隔的道路也能够分割出来,整体表现最好。
2.3.2 消融实验结果及分析
为验证改进模块的有效性,分别添加改进模块逐个进行实验,以验证多级感受野融合的ASPP、Mixed-Loss、SE 模块对模型性能的提升效果。由表4 的实验结果可知,各改进方案对模型性能均有提升。改进ASPP,能够提高不同感受野的利用率,mIoU 较原模型提高了2.12%;添加SE 模块,提高了模型在通道上的信息的聚焦,mIoU 较原模型提高了1.75%;使用MixedLoss,模型收敛速度加快,改善了样本不均衡的问题,mIoU 较原模型提高了2.26%。每添加一个改进模块,模型的总体性能都有所提高,最终结合所有改进模块的模型表现最好,mIoU 较基础模型提高3.78%。

表4 消融实验
3 结论
通过对比实验发现,当前常用的语义分割模型在遥感图像中小目标的分割上还存在不足,比如边缘分割模糊,细节分割不到位等,不利于各项遥感工作的开展。本文针对这一问题,使用在遥感图像分割中表现较好的DeepLabV3p 模型作为基础模型,对其进行多方面的改进,得出以下结论:
(1)改进的多级感受野融合ASPP 能够进一步对不同采样率卷积出来的特征层进行感受野融合,更大程度发挥了ASPP 模块的作用。
(2)在解码器添加SE 注意力机制能够使模型对通道信息中的目标信息更加专注,减少了其他通道信息对训练的干扰。
(3)使用加权的混合损失函数(LovaszSoftmaxLoss和CrossEntropyLoss),结合二者的长处,样本不均衡问题得到了改善。
(4)全连接条件随机场对模型预测图进行精细化处理,可以改善物体分割边缘粗糙的问题。
(5)融合以上的改进方案能够更大程度提高模型的性能,为遥感图像中小目标分割的边缘不清晰、细节不准确的问题提供了一种解决方案,本文模型最终mIoU 提高3.78%。
当然,因为网络模型的训练过程十分复杂并且缺乏可解释性,本文的研究还不够深入,在后续工作中将重点研究如何在不增加复杂计算量的情况下实现更高精度的分割。在进行CRFs 图像后处理时发现,推理次数较少时,优化效果不够明显,推理次数较多时又容易受到颜色信息的影响,因此后续还将对图像后处理算法进行研究和优化。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
上海大学学报(自然科学版)(2018年5期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
