
基于离散粒子群的Web前端缓存协作任务优化分配方法
2023-11-14 13:38周沭玲侯海平
保山学院学报 2023年5期
周沭玲 侯海平
(1.合肥财经职业学院人工智能学院,安徽合肥 230601;2.安徽财贸职业学院信息工程学院,安徽合肥 230061)
引言
大规模的冗余数据量,对网络节点的缓存与协作带来大量的资源损耗,这直接导致网络传输效率低,网络节点的平均时延久居不下等现象[1]。为从根本上解决网络体系的通信安全问题,以信息为中心,探究Web 前端的缓存协作任务优化分配策略。在现有的相关研究中,左亚兵在无线网络的蜂窝架构中,通过频谱资源的限制与回程容量,设计一种异构网络,并在用户位置分布中,通过请求内容的偏好限制以及节点空间的存储效率,建立一个有关于用户关联联合优化问题的数学模型,并最小化函数时延设计一种任务分配的改进策略[2]。张秋平通过移动边缘计算的方式,改变通信设备的存储与计算资源,以长距离传输和快速响应为核心,解决有效资源和设备负载不均衡的问题[3]。面对多边缘设备的协同合作问题,该方法可以提高任务缓存机制的联合优化,并基于偏好匹配算法,减少任务分配的整体执行时间,从而降低了网络时延。张欢以无线接入网络的硬件设施为核心,设计一种边缘缓存的用户偏好预测与度量算法[4]。在网络设备的拓扑关系中,结合不同基站的相关性,降低冗余文件的内存,并利用强化学习策略优化Q-learning 算法,提高前端缓存协作的效率,同时删除任务分配的冗余数据。上述方法降低不同类型网络任务分配或数据传输时的时延,但是由于Web 前端缓存任务中冗余数据较多,因此其在优化Web 前端缓存协作任务分配效果方面存在一定的局限性。基于此,本文设计一种基于离散粒子群的Web前端缓存协作任务优化分配方法。
1 Web前端缓存协作任务优化分配方法设计
1.1 规划Web前端缓存访问路径
网内的缓存协作是Web 前端网络与传统网络最大的不同之处,也是该网络的重要特征。在提高数据传输效率,减少服务器负载的同时,该网络任务的优化分配方法还可以为用户提供更好的体验,并总结了网络结构[5]。Web前端网络的内容访问路径如图1所示。

图1 缓存访问路径
如图1所示,在缓存访问路径上,在A1-An 之间存在n个相邻的节点,可以设置节点的编号,并保证路径中的其余节点均以1-n编码。在上一条节点的转发请求中,依次设置访问权限,并将其添加到缓存访问路径中,添加节点为IN。连接访问权限后,访问路径就会存在一个转换机制[6-7]。在访问机制以后的路径,可以定义访问路径以外的所有节点请求,包括缓存内容的对象节点。在缓存模型与缓存方案中,还存在一些系统缓存的优化问题,包括系统建模的拓扑优化与共享问题。在现有的拓扑结构中,线性级联结构是一种以层次结构与网状结构为核心的关联性请求模型,各节点之间的协作关系十分简单。而在这些陌生的拓扑模型中,对缓存节点的透明化管理是最重要的一部分。很多自主命名区域内都与缓存应用之间建立私有协议,缓存区域与应用软件之间没有特殊的关联,以至于缓存协作对上层的应用软件而言是一种属性透明的基础服务。在传统的应用中,缓存网络是通过先验协同运算得到的树状层次结构,而在Web 前端的缓存网络中,则以缓存节点为中心,呈现出一种抽象的泛化特征。缓存节点不再停留在一个固定的地区,以高度动态的网络环境为中心,保持已有的应用性,是整个缓存内容的具象化产物[8]。在缓存内容文件中,则会依据整个文件的操作速度,实现一种线性的结构,将所有前端协作的内容全部整合成大小不同的分块,并在更加细粒度化的对象体系中,以不同的访问频率,实现文件传输操作。这样一方面可以降低用户的访问时延,另一方面还可以优化服务器负载,减少带宽消耗。
1.2 基于离散粒子群建立任务优化分配模型
为解决任务优化分配的问题,可以使用离散粒子群优化算法,确定模糊矩阵中粒子的最佳位置与速度。首先需要初始化粒子的初始位置与速度,设为(X0,V0),其中X0表示粒子的初始位置,V0表示粒子的初始速度[9-10]。在不断迭代的过程中,建立位置与速度的矩阵,矩阵中的元素需要满足:
式中,(Xi,Vi)表示时间为i 时的位置与速度。计算粒子群的更新坐标,检测矩阵内的粒子是否清零,若可以直接对矩阵进行归一化计算,则直接负值清零,若不能归一化计算,则需要通过最大数采样法,将粒子更新位置的矩阵模糊化处理,得到位置的可行解[11-12]。离散空间的离子群优化算法中,有关于离散变量的排列优化方法是左右速度位置更新的最佳变量。在布尔运算中,将连续空间的修改方案作为算法运算的迭代结果。在分配模型中加入扰动因子,使其作为最大的参数,参与种群的多样性,可以得到修改后的位置更新矩阵:
式中,Xm表示时间为m时的粒子位置最优解;xnn表示在第n个最大采样法中得到的第n个粒子的更新坐标;x1i表示粒子i时的位置变动值。通过重复迭代的方式,可以求出离散粒子群算法的全局最优解,并基于排序优化问题,获取替代向量以及离散矢量空间中的最优参数。在惯性的部分添加代表社会认知的权重,可以及时增加粒子群的多样性,避免参数过早地进入局部极值的收敛中[13]。当粒子群的多样性减少时,可以同步降低算法的收敛速度,并降低局部极值的解。通过线性阶段的算法收敛与精度收敛,可以将两个不同的概率作为粒子的相似性,自适应调整后可以得到粒子的系数概率公式为:
式中,Pnm表示粒子相似性下的自适应调整概率;Pi表示第j个粒子的种群大小;Df表示粒子的总位数。通过粒子维度的大小,计算每个粒子的总位数,可以得到:
通过目标函数的部署,以及节点请求对象在任务优化分配中的缓存需求,可以计算节点的位置路径,得到替代节点的目标函数为:
式中,Fc表示节点路径中替代节点的目标函数;f(dc,ny)表示路径与节点代价在物理意义上的最大差异。将该数据映射在区间内,可以保证节点在每一个内容中均可以以最小的缓存节点得到最大的响应结果,此时需要满足的约束条件为:
式中,U表示网络节点的集合;dc和ny分别表示链路的容量与需求。根据以上目标函数和约束条件,可以实现缓存协作任务的优化分配。
1.3 设计缓存协作任务分配优化算法
结合上文中的规划的缓存访问路径,以及目标函数和优化条件,可以得到缓存协作任务分配优化的算法流程,如图2所示。

图2 算法流程
结合图2 中的流程图可知,在优化任务分配结果时,首先初始化处理所有系统中的任务,计算网络节点的路径,读取Web 前端缓存协作的代价函数,并规划缓存访问路径。当路径上存在非法访问节点时,可以以节点数量为计算代价,将初始的内容分配给一个具备初始价值的回转缓存路径,将上述兴趣包中的内容保存在节点命中信息中。在基于隐式协作策略的缓存任务中,以最新的缓存收益为核心,分配空闲节点中的非法访问节点,并使用新的节点替换此类节点。此时的协作机制需要预先处理大量的访问信息,在每一个节点的缓存状态中,均选择最佳的访问节点,并通过计算得到内容对象的最佳速度与位置。在这种机制中,获取缓存节点的最优路径,并分解不同的内容区块[14]。若能够获取此类节点,则可以直接丢弃分解内容,并获取任务分配的优化结果。但是若不能得到该类缓存节点,需要重新初始化任务参数,继续迭代处理,直至最佳缓存节点被计算出来。此时得到的任务优化分配方法,即为本文设计的基于离散粒子群算法的Web前端缓存协作任务优化分配方法。
2 实验研究
2.1 设置实验环境与参数
以本文设计的基于离散粒子群算法的Web 前端缓存协作任务优化分配方法为核心,以用户偏好方法、多边缘设备协作方法和Q-learning 方法为对比,设计对比实验,以判断所提方法是否更具优越性。在Web 前端的缓存协作中,主要可以分为两种拓扑类型,依据内容分布以及缓存大小的不同,可以提前设置实验环境与实验参数,如表1所示。

表1 实验参数
如表1 所示,在Web 前端的网络环境中,生成40 个缓存节点,在这些缓存节点中,服务器的节点数量为3。同时建立两类实验机制作为背景环境,主要以内容分布为主体,将其分为固定内容与随机内容。每个源节点中设置20 000个单位的内存,在不同的内容单位间,受欢迎程度有很大差别,且基本服从Zipf 参数。在内存分布固定的前提下,Web 前端的单节点缓存大小分别为50、100、150、200、250 MB,在内容随机分布的情况下,Web 前端的单节点缓存大小为100、200、300、400、500 MB,此时数据的传输效率分别为50 KB/ms和100 KB/ms。
2.2 选取专属缓存节点
以内容的固定与随机为分区,验证20个缓存网络节点的权重,得到的结果如图3所示。
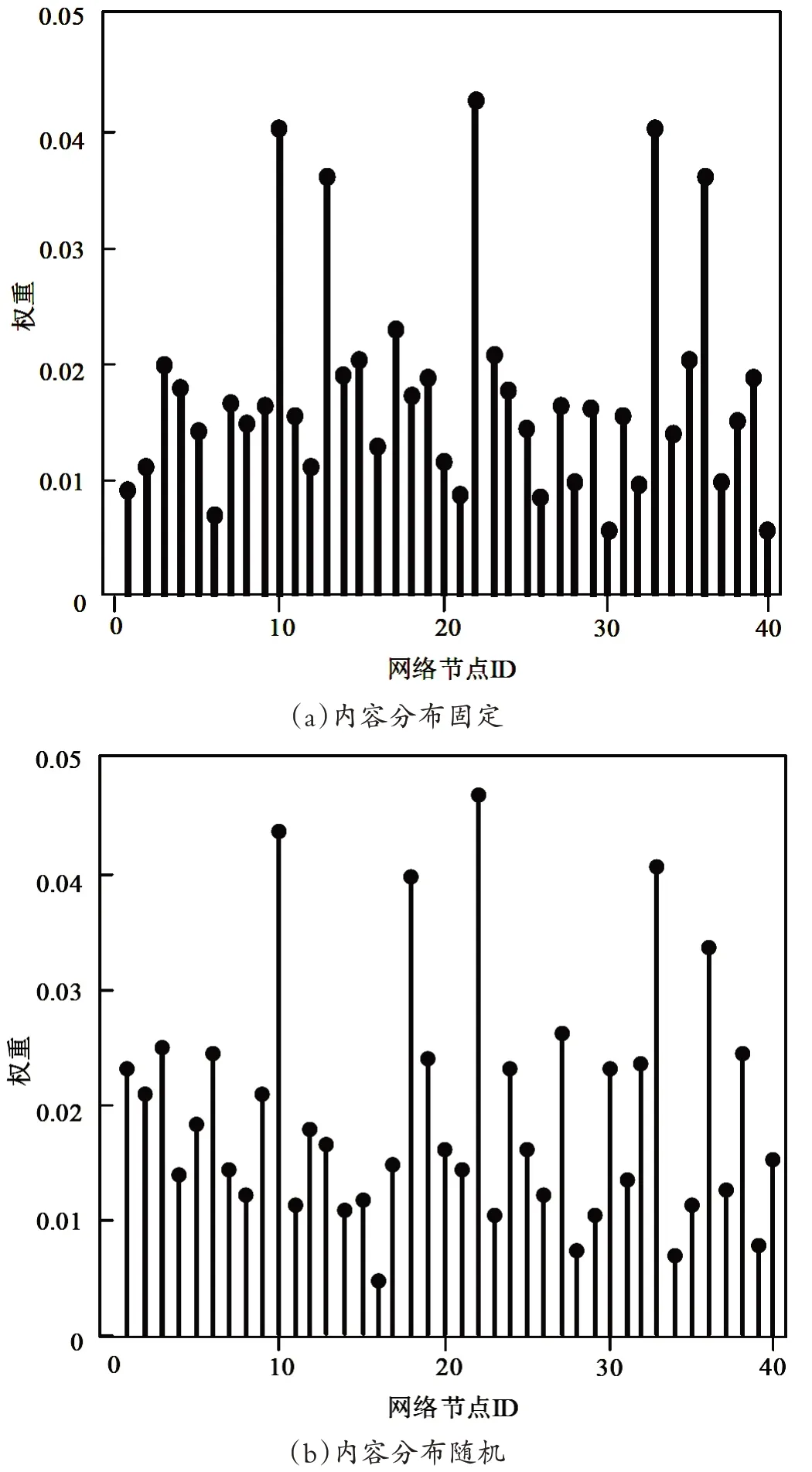
图3 缓存节点权重
通过图3所示的权重结果可以得知,在内容固定分布与内容随机分布两种优化分配方法中,40 个缓存节点的权重指标存在较大差异。大多数网络节点的权重均不超过0.03,当内容分布固定时,权重指标大于0.03的网络节点ID分别为10、13、22、33、36,当内容分布随机时,权重指标大于0.03的网络节点ID分别为10、18、22、33、36。在这两类不同的计算机环境下,存在四个同样权重指标较大且重合的网络节点ID,分别为10、22、33、36,因此,可以在网络路由器中选择这些网络节点作为专属缓存节点。
2.3 不同网络节点平均时延测试
本实验选择平均网络时延,作为网络节点在Web 前端缓存协作任务优化分配的测试指标,用户在各专属缓存节点上所用到的时延越长,则该节点的性能越好。对比四种任务优化分配算法的不同网络节点平均时延,得到如图4所示的测试结果。

图4 平均时延测试
由图4可知,随着任务量的增加,四种任务分配优化算法的平均时延均以不同的比例逐渐增加。在缓存节点10中,离散粒子群算法在任务量为1时的平均时延为2 ms,在任务量为8 000 MB时的平均时延为6 ms。用户偏好方法的平均时延由5 ms提升为15 ms,多边缘任务协作算法的平均时延由1 MB时的5 ms提升为8 000 MB时的12 ms,Q-learning算法的平均时延则由10 ms变为14 ms。在以上四组数据中,离散粒子群算法在任意任务量中的平均时延均小于其他三种算法。在缓存节点ID为22和33时,离散粒子群算法的平均时延同样远小于其他三种算法。只有在缓存节点ID为36中,当任务量为1 MB-2 000 MB时,离散粒子群算法的平均时延为4 ms-5 ms,略大于用户偏好方法的3 ms-5 ms。其他任务量下,离散粒子群算法的平均时延均小于其他三种算法。通过以上数据可知,本文设计的基于离散粒子群算法的Web前端缓存协作任务优化分配方法在四种对比算法中平均时延最小,性能最佳。由此可见,本文的设计实现了优化目标。
3 结束语
本文设计一种基于离散粒子群的Web 前端缓存协作任务优化分配方法。在合适的信息节点上部署足够的信息,通过降低缓存开销,设计路径访问代价的替换优化算法,在目标函数与约束条件的作用下,完成任务优化的分配。并设计相应的算法流程,实现用户网络任务分配的优化。实验结果表明,该方法的网络平均时延更低,可见本文的优化分配实现了设计目标,能够在一定程度上降低缓存协作的时延。
猜你喜欢
铁道通信信号(2020年9期)2020-02-06
作文成功之路·小学版(2019年8期)2019-09-18
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
经济技术协作信息(2018年30期)2018-11-22
读者(2017年14期)2017-06-27
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
