
基于HSM_LDA模型的在线医院特色挖掘研究*
2023-11-09 10:26:18黄锦泉刘灵涛翟菊叶刘玉文
医学信息学杂志 2023年9期
黄锦泉 张 楚 刘灵涛 潘 玮 翟菊叶 刘玉文
(1蚌埠医学院卫生管理学院 蚌埠 233030 2蚌埠医学院护理学院 蚌埠 233030)
1 引言
随着我国“互联网+医疗健康”事业的迅速发展,以“好大夫在线”“春雨医生”等为代表的在线健康社区(online health communities,OHCs)逐步涌现[1],为在线医院的兴起提供了平台基础。截至目前,众多国内医院已在健康社区内注册账号[2]成为在线医院。与传统线下就医模式相比,在线医院打破时空局限,实现了患者与医生的跨时空交互,对提高医疗资源利用率[3]、促进医疗均衡发展具有推动作用。但OHCs尚缺乏全局性的在线医院特色导航服务,用户在线问诊时无法根据自身病情选择合适的医院[4],这在一定程度上限制了在线医院服务质量的提升。所以,从全局角度挖掘在线医院的医疗特色,实现医疗特色精准导航,对提升在线医院服务质量、改善用户问诊体验具有重要意义。
当前,在线医疗特色识别相关研究主要围绕医生和医院两方面展开。其中,医生特色识别相关研究较多,主要是利用机器学习、自然语言处理等方式探索OHCs中医生的专业领域,为患者提供高效便利的医生推荐服务。例如,孟秋晴等[5]利用文本相似度和隐含狄利克雷分布(latent Dirichlet allocation,LDA)主题模型对患者问诊文本和医生回答文本进行挖掘,试图分析在线医生的诊疗特色。梁建树等[6]利用Word2Vec和LDA等技术对OHCs中的医生特征进行挖掘,并结合三支决策思想提出多维度的三支医生推荐方法。该方法深入挖掘医生特色,大幅度提高医生推荐精准度。Li Y Y等[7]提出一种组合条件的目标医生挖掘模型,该模型分为相似患者、相似领域和医生绩效3部分,最后采用线性加权整合3部分结果,挖掘符合患者需求的目标医生。武家伟等[8]以OHCs中用户评论文本作为数据源,融合知识图谱和深度学习技术挖掘医生服务特色。叶佳鑫等[9]利用Word2Vec模型对OHCs中医生相关文本进行挖掘,从而找寻与目标医生相似的医生人群,进而对目标医生进行标注,丰富医生特征。在医院特色识别方面,诸多学者开始挖掘目标医院的特色科室,帮助患者解决挂错号等问题。例如,宁建飞等[10]使用词向量和句子相似度方法分析患者在线问诊文本的语言特征,并进一步以词向量代替词频比对问诊文本和问答知识库的相似度,从而挖掘目标医院特色科室。郑姝雅[11]提出一种基于线性支持向量机的医院科室匹配方法,利用科室内的接诊记录推算符合目标患者需求的特色科室。何慧茹[12]利用统计学原理对医疗资源进行收集与分析,通过径向基函数(radical basis function,RBF)神经网络模型和模糊算法模型推导医院中不同科室具备的特色。以上研究使用不同方式对在线医院特色进行挖掘,虽然有助于改善OHCs的患者体验,挖掘用户需求,但无法从全局角度挖掘不同医院之间的特色差异,且患者与医院匹配不精准问题仍未得到较好解决。
因此,本研究将医院ID融入传统LDA模型中,构建医院特色识别模型(hospital special medical based LDA,HSM_LDA)。该模型将原始的“文本-词汇”矩阵转化为“医院-词汇”矩阵,联合医院、主题、词汇3个变量进行建模,生成“医院-主题”(E)和“主题-词汇”(F)两个分布矩阵,从而识别出医院特色。
2 相关技术介绍
2.1 词频-逆文本频率指数算法
词频-逆文本频率指数[13](term frequency-inverse document frequency,TF-IDF)是文本数据挖掘的重要方法,主要用于度量文本中词语的重要程度。一般情况下,词语的重要程度不仅与该词在文本中出现的次数有关,还与包含该词语的文本数量有关。如果某个词语在文本中出现的次数越高,且包含它的其他文档数量越少,则该词的重要程度就越高。
TF-IDF(wi)=TF(wi)×IDF(wi)
(1)
其中,TF(wi)表示词语wi在文档di中出现的频率,IDF(wi)表示词语wi的逆向文档频率。
2.2 LDA模型
LDA模型[14]是一种无监督学习的文档生成模型,于2003年被提出,可以计算文档集中每篇文档的主题概率分布和每个词语的概率分布,主要用于文档主题的聚类和分类。LDA建模过程可以分为4步:一是选择一篇文档,以α为超参数进行Dirichlet分布采样生成“文档-主题”概率θ;二是由θ分布生成所有文档中词语的主题Z;三是以β为超参数进行Dirichlet分布采样生成“主题-词汇”概率φ;四是由φ分布生成词语W。
3 基于HSM_LDA模型的医院特色识别方法
基于HSM_LDA模型的医院特色挖掘过程主要包括3个步骤:下载在线医院问诊数据,并对问诊文本进行分词、去停用词等,生成问诊文本语料库;将预处理后的文本进行TF-IDF运算,计算文本中词汇的重要程度;建立HSM_LDA模型并对问诊语料库进行建模,生成“医院-主题”(E)和“主题-词汇”(F)两个分布矩阵;根据分布F人工标注特色主题含义,再根据分布E获取特色主题在医院的分布,见图1。
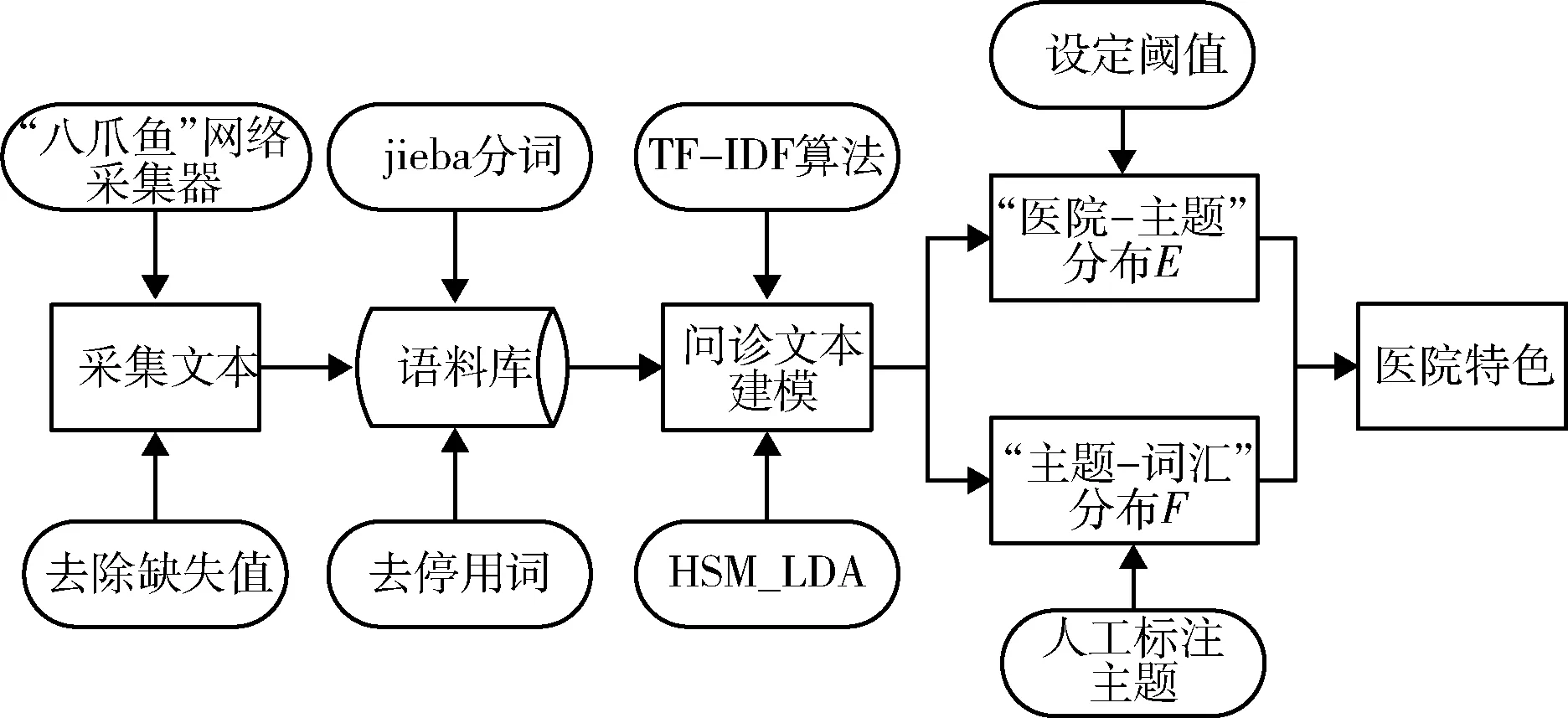
图1 研究总体框架
3.1 HSM_LDA模型建立
设在线医院的问诊文本语料库为D=[d1,d2,…,dm]T,其中,di=
3.1.1 定义1:“医院-主题”分布E对任意医院Hi的问诊文本,生成主题的概率分布为EHi=
(2)
3.1.2 定义2:“主题-词汇”分布F对任意主题zi,生成词汇的概率分布可表示为Fzi=
(3)
与LDA模型相比,HSM_LDA通过医院ID参数在迭代采样时,将属于同一医院ID的文本进行连接视为一条文本,从而将传统LDA模型生成的“文本-主题”分布转化为“医院-主题”分布,见图2。
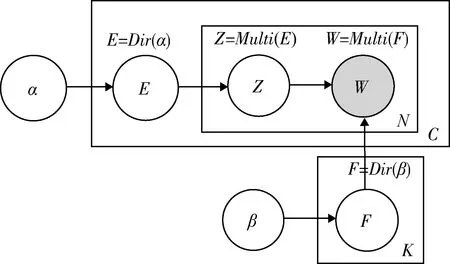
图2 HSM_LDA模型结构
HSM_LDA与LDA的不同之处表现在以下两方面:框架的外层表示医院层,C表示医院数量;E表示“医院-主题”分布,F表示“主题-词汇”分布。
3.2 模型公式推导
HSM_LDA模型运用超参数α生成一个“医院-主题”概率分布,再运用β生成N个“主题-词汇”概率分布,最后再生成问诊文本的N个词的联合概率公式:

(4)
由于只有W是唯一可观测值,如果要计算W的生成概率就需要对E和Z进行边缘概率求解,从而消除E和Z。最终的词汇生成概率计算方式如下:
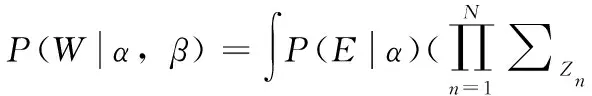
(5)
得到词汇生成概率后,可以通过采样算法对模型中的E和F参数进行估计。常用估计方法是吉布斯采样,通过期望最大化(expectation-maximum,EM)算法对E和F进行反复迭代,使其逐步收敛。基于HSM_LDA模型的医院特色识别算法描述如下:
Input:α,β
Output:E,F
(1)Get{D,V} //读入文本语料库
(2)Fork=1 toK
(3) //计算问诊文本主题
(4)Computeα,β
(5) //计算模型超参数
(6)Run Gibbs (α,β)
(7)//进行Gibbs采样
(8) For eachwd
(9) Choose awfromEw~Multi(α)
(10) Choose awfromFw~Multi(β)
(11)End For
(12)GetE,F
(13) End For
3.3 最优主题数计算
在运用HSM_LDA模型进行主题挖掘时,主题数K是影响主题挖掘效果的关键因素,本研究采用主题困惑度曲线估计K值。困惑度是主题不确定性的一种表达方式,困惑度越低表明主题聚类效果越好,其计算方式如下:
(6)
其中,N表示语料库中的词语总数,p(w)表示词语w出现的概率。利用困惑度P和主题数K建立主题困惑度曲线,当P值最小时K最优。但困惑度只是判定最优主题数的一个粗略指标。所以,本研究在实验过程中以困惑度最低点作为参考值,在最低点两边取值进行多次实验,选择效果最好的K值作为HSM_LDA模型的主题数。
4 实验分析
4.1 数据来源及预处理
“好大夫在线”是我国常用的网络医疗资源平台,集合了1万多家在线医院,注册医生近60万人[15]。众多访问用户在平台内积累了大量问诊数据。以“好大夫在线”为数据源,运用“八爪鱼”网络数据采集器获取2022年4—5月患者问诊数据148 376条,每条数据包括医院ID、医院名称、患者性别、患者年龄、问诊时间、问诊文本和科室等信息。然后,按照问诊数量由高到低对医院排序,并选择前100家医院的问诊记录作为实验数据集。运用jieba分词工具[16]对问诊文本进行分词,并去除停用词、介词以及无用词,建立医院问诊文本矩阵D。
4.2 实验结果及分析
4.2.1 医院医疗特色识别 HSM_LDA模型需要设置4个参数:超参数α、β,主题数K以及迭代采样次数。通常情况下:α设置为0.5/K,β设置为0.1,迭代次数设置为1 000。当K设置为13时,主题困惑度最低。因此以13为主题数参考点,在13±5范围内进行多次实验,最终结果显示当主题数设置为15时主题识别效果最佳。运行HSM_LDA模型得到“主题-词汇”(F)和“医院-主题”(E)两个分布矩阵。在F分布中,主题生成词汇概率越大,词汇的主题属性越强。按照生成概率的大小选择生成概率前15位的词语作为主题关键词,然后,根据词汇表达出的语义,对特色主题含义进行人工标注,见表1。

表1 医院特色主题识别结果(主题前10位)
从F分布中只能识别出特色主题的含义,不能确定医院特色主题。因此,还需要进一步结合E分布来确定医院的特色主题。问诊量排名前10位的医院主题识别结果,见表2。
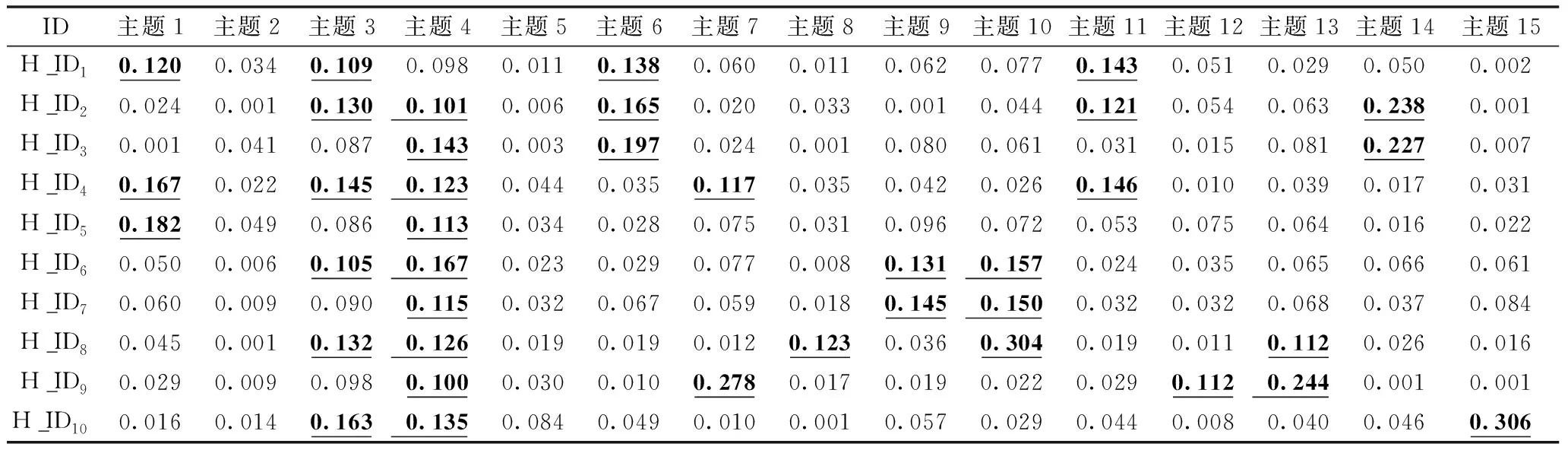
表2 “医院-主题”识别结果(H_ID前10位)
根据医院生成主题的概率结果,在保证医院特色主题有较高鲜明度的情况下,特色主题不至于太多。设置医院特色主题概率阈值为0.1,高于阈值的主题定义为医院特色主题。例如,编号为H_ID1的医院特色主题包括主题1、主题3、主题6和主题11。
结合表1和表2可以得出医院诊疗特色。例如,编号为H_ID1的医院诊疗特色有:心血管系统疾病、耳鼻喉科疾病、男性生殖系统疾病与肛肠科疾病。依此类推,获得每家医院的医疗特色。
4.2.2 医院医疗特色对比 由于多家医院中会存在相同医疗特色,不利于患者选择就诊医院,所以对相同医疗特色下的医院进行排名。以医院主题概率值表示医院特色强度,对比同一特色下的多家医院,见图3。该排名有助于患者在多家医院特色相同的情况下优先选择特色强度最高的医院进行就诊。
以安徽医科大学第一附属医院为例,统计并分析其各科室问诊量条数,见图4。
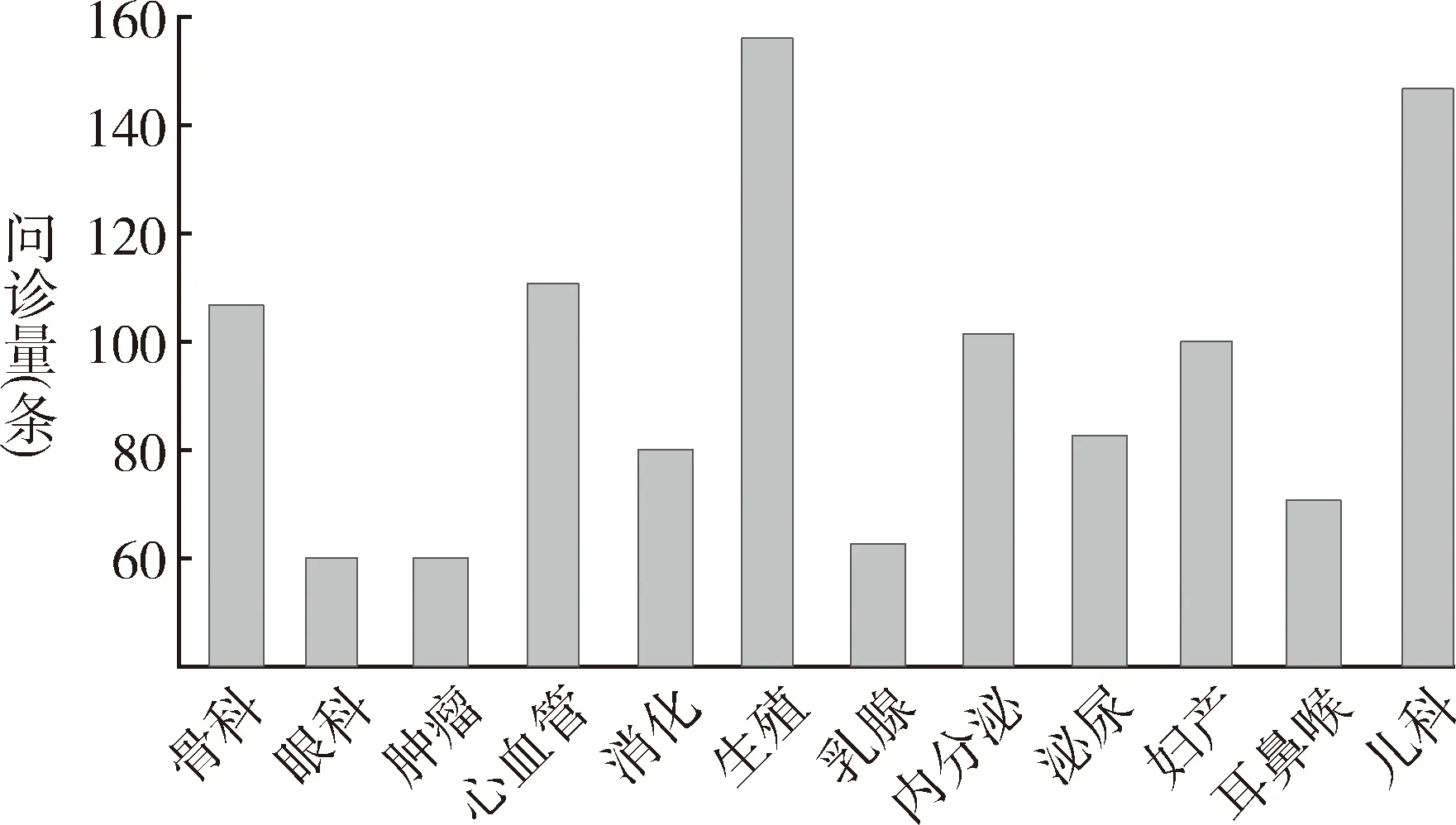
图4 不同科室问诊量大小
再利用本文提出的HSM_LDA模型识别该医院特色包含男性生殖系统疾病、心血管系统疾病和儿科疾病。与前文图4中问诊量前3位的科室相符,说明该模型识别出的医院特色具有一定准确性。
4.2.3 模型评价 为验证HSM_LDA模型的有效性,以医院特色官方介绍作为评价标准,用准确率作为评价指标。准确率表示模型识别结果中符合官方特色数量(DS)除以模型识别出的特色总量(HS):
(7)
结果发现,本文提出的HSM_LDA模型识别准确率达87%(100家医院识别准确率均值),见表3。

表3 官方特色与模型识别结果对比(H_ID前5位)
5 结语
本文在梳理OHCs相关研究时发现其无法从全局角度衡量不同医院之间的特色差异。为弥补这一缺陷,提出一种基于在线医院问诊文本的医院特色挖掘模型(HSM_LDA)。该模型在传统LDA模型3层结构的基础上,用医院层代替文本层,建立医院、主题、词汇之间的依赖关系,通过吉布斯多次采样生成“医院-主题”和“主题-词汇”两个分布矩阵,利用人工标注对主题词汇进行识别,从而挖掘医院特色。实验证明,HSM_LDA模型在医院特色识别中能达到较好效果。
本文提出的HSM_LDA模型易于挖掘OHCs中的医院特色,有助于满足患者选择最佳就诊医院的需求,对推动OHCs发展具有一定积极意义。在后续研究中,可加入医院官网公布的问诊记录,以增强医院特色的鲜明程度;进一步细化特色主题含义,提高特色判定的准确性。目前模型的评价指标较少,后续研究会加入多种定量指标,以更好地展示模型性能以及更全面、细致的医院医疗特色。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
中华胰腺病杂志(2021年1期)2021-02-26 11:28:36
小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32
山东医药(2020年34期)2020-12-09 01:22:24
中华胰腺病杂志(2019年4期)2019-08-29 08:52:20
作文评点报·低幼版(2016年42期)2017-01-23 11:45:27
