
基于改进YOLOv5的农业害虫检测
2023-11-08 02:26:34唐小煜向秋驰黄晓宁张怡丰
华南师范大学学报(自然科学版) 2023年4期
唐小煜, 向秋驰, 黄晓宁, 张怡丰
(1. 华南师范大学行知书院, 汕尾 516600; 2. 华南师范大学物理与电信工程学院, 广州 510006; 3. 华南师范大学数据科学与工程学院, 汕尾 516600)
虫害是影响农作物产量和质量的主要威胁。传统防虫方法通常依赖于农业专家的观察分析,但该方法具有主观性、耗时且缺乏普适性等问题。运用计算机视觉技术对害虫图像检测和识别,可协助虫害防治。害虫图像由于存在形态相似、尺度多变、姿态多样以及背景复杂等问题,传统的图像检测和识别方法在实际应用中面临挑战。近年来,计算机视觉领域的深度学习技术备受瞩目,尤其在图像检测和分类方面表现出色。深度学习技术已逐渐成为解决各行各业图像检测难题的首选,为提高工农业生产的智能化水平和产品质量提供了更准确和更高效的工具。利用深度学习技术解决农作物虫害监测与防治的重大难题,为实现创新发展智慧农业提供一种高效率、高精度、可实时监测的解决方案[1]。鉴于此,探索切实可行的农作物害虫图像检测任务的新方法,提出更有效的害虫目标检测算法具有重要意义。
在对害虫图像预处理方面,方明[2]基于模糊C-均值聚类算法对图像中的害虫进行图像分割。陈树越等[3]改进了Harris算法和凹点检测算法,针对害虫串连、并连和混连情况进行分割。廉飞宇等[4]提出了基于Daubechies小波压缩算法对原始图像进行三级小波分解,且在图像重构之后进行边缘检测,生成的轮廓清晰。这些图像预处理策略仅对特定数据集有效,针对其他数据集往往不能得到理想的增益效果,甚至还会带来负优化的情况,不同害虫的特征差异以及害虫所处环境背景的不同都会影响相关处理策略的性能发挥。
在特征提取方面,吴一全等[5]基于扩展Shearlet变换对害虫的纹理特征进行提取,基于Krawtchouk矩不变量对储粮害虫的形态特征进行提取,最终将提取的纹理特征和形态特征进行归一化并组合成综合特征向量,最后送入支持向量机进行训练。ESPINOZA等[6]将图像处理和人工神经网络(Artificial Neural Networks,ANN)相结合,首先对图像进行分割,根据二值化后的图像计算形态特征,然后提取HSV图像的颜色特征,最终将14个形态特征送入ANN实现完成分类。随着深度学习技术的发展,更多更强大的卷积神经网络和端到端检测模型被相继提出,在现阶段如何针对待测目标的特征设计适配的网络架构或模块是研究重点。
在识别分类方面,罗慧等[7-8]利用提取的边缘特征、相对面积、离心率等8个特征设计分类器,实现对虫的识别。李衡霞等[9]提出的基于深度卷积神经网络的油菜虫检测方法,首先需要生成初步的候选区域,再利用Fast R-CNN算法实现对候选框的分类和定位,由于使用了两阶段的检测方法,检测速度较慢。李想[10]提出的深度学习模型可以实现虫情的全自动化检测,但是该系统只针对一种类型的害虫进行检测,无法实现对多种害虫的检测。
调查结果表明,主流网络在正常尺寸目标中效果较为显著,但在小目标检测中效果一般。近年来,新的小目标网络对小目标识别任务进行了针对性探索和改进[11]。本文数据集中存在部分小目标害虫,直接采用小目标检测网络会导致正常尺寸目标识别精度降低从而影响整体识别效果。因此,本文以深度学习算法为基础,提出改进YOLOv5的农业害虫检测模型,所添加的小目标检测层有效提高了图像中小目标特征信息的提取效率,同时针对数据集中的图像采用数据增强的方法以及一种先分割图像再检测的策略。经实验验证,上述方案在面对背景复杂以及害虫目标大小不一的情况下具有良好的检测精度和速度,鲁棒性较强。本文源代码可从http://dx.doi.org/10.6054/j.jscnun.2023029网页的“资源附件”链接中下载。该研究成果有利于农作物的虫害预防工作,对提高农业生产的产量和促进传统农业的智能化发展具有重要意义。
1 基于改进YOLOv5的害虫检测
1.1 YOLOv5基本原理
基于深度学习的目标检测算法分为 “一阶段检测”和“二阶段检测”两大类。“一阶段检测”算法采用网络提取图像特征,直接预测物体的类别概率,提取图像中位置的坐标信息,即单次检测即可直接得到最终检测结果。虽然这类模型检测精度稍低,但简洁的模型带来了极高的检测效率。“二阶段检测”的基本步骤是输入图片后,先在图像上判定含有待检测物体的候选区域,然后通过卷积神经网络进行分类。由于其更复杂的机制,比“一阶段检测”拥有更准确的检测效果,目前二阶段检测器主要采用Faster RCNN模型[12]。一阶段检测器主要采用YOLO模型[13],因其具有较高的检测速度、良好的检测精度和兼容多种硬件平台等优点而备受青睐,例如可应用于渔业鱼类检测[14]和输电线绝缘子检测[15]等多个领域。虫情实时分析模型在速度与规模上需满足很高的要求,参考不同YOLO模型在同一数据集上的表现[16],YOLOv5与YOLOv3和YOLOv4相比,虽然检测速度略有降低但相比平均检测精度得到大幅提升,因此本文采用YOLOv5模型实现对害虫的高精度检测(表1)。

表1 不同YOLO模型在coco数据集上的表现
YOLO模型的核心思想是将目标检测视为单一的回归问题,直接在输出层回归边框坐标和所属类别。以往的目标检测多采用滑动窗口技术,因而检测的精度与滑动窗口的遍历次数呈正相关,导致这类模型耗时且操作复杂。而YOLO模型则将输入图像分成S×S个网格,每个网格用于预测物体中心落入该网格的物体,该方法大幅减少了模型的运算量,进一步提高模型的检测速度。YOLOv5算法在YOLOv3的基础上优化,在输入端采取Mosaic增强、自适应图片缩放等方法,通过对图片进行随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测能发挥更好的作用(图1)。这种数据增强的策略还能通过减少由图片缩放所带来的冗余信息,从而提高推理速度。

图1 Mosaic数据增强效果
YOLOv5在骨干网络中结合了Focus结构和局部跨阶段(Cross Stage Partial,CSP)[17]结构以及特征金字塔(Feature Pyramid Networks,FPN)[18],路径聚合网络(Path Aggregation Network,PAN)[19]等特征融合技巧,利用跨阶段层次结构融合特征信息,在减少计算量的同时保证了正确率。
在输出端,损失函数由分类损失函数和回归损失函数两部分构成。YOLOv5采用基于CIOULoss的回归损失函数,CIOULoss函数考虑了重叠面积和中心点距离,增加了相交尺度的衡量方式,在此基础上还增加了一个影响因子,将预测框和目标框的长宽比同时考虑进来,解决了当预测框和目标框不相交时2个框交并比为0从而无法反映2个框距离远近,以及当2个预测框大小相同且交并比也相同时无法区分两者相交位置的问题。
通过修改网络的深度和宽度,最终YOLOv5迭代出YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x共4种不同深度的模型,并随着模型的复杂度增加,模型的识别准确率不断提高。4种模型的整体框架一致,差别只在于CSP模块堆叠层数的不同。YOLOv5x的结构如图2所示。
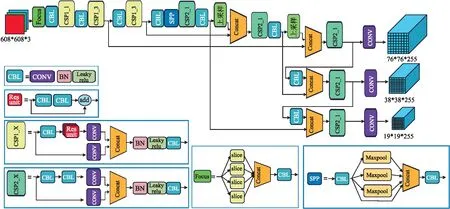
图2 YOLOv5x模型的结构图
1.2 YOLOv5改进和训练
实验发现采用YOLOv5模型可使数据集的训练损失函数迅速收敛,均值平均精度达到较高水平,但在训练过程中发现,由于某些害虫尺度过小(见表2),导致识别成功率低,容易出现漏检和错检等现象。由于YOLOv5模型对正常尺度目标更为适用,本文针对小目标检测提出了相应的改进算法。

表2 部分害虫检测框尺寸对比
研究发现在训练过程中模型无法学习到足够的小目标害虫特征信息(图2),以输入尺寸608 px×608 px的图像为例,经模型的下采样处理,得到3种尺寸的特征图。76 px×76 px的特征图用于检测小目标,对应的原图网格特征感受域为8 px×8 px,如原始图像中目标的宽或高小于8 px,则难以从中识别出特征信息,导致模型召回率低。针对此问题,本文提出增加特征提取层的改进方案(图3)。
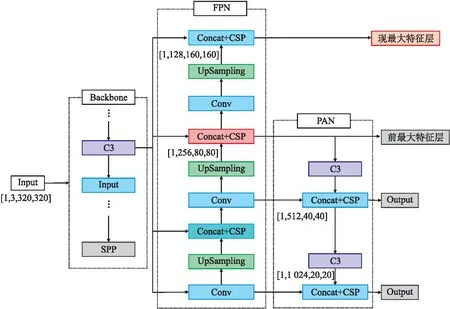
图3 改进后YOLOv5x模型的部分框架
以输入尺寸为640 px×640 px的图像为例,在2次上采样获得最大特征图尺寸(80 px×80 px)后,继续对特征图进行上采样处理,使得特征图继续扩大为160 px×160 px,以此得到最大的第4种尺寸特征图并进行小目标检测。最大特征图经过多次上采样处理后可能存在部分重要特征丢失的问题。在接入PAN层并继续下采样经过C3模块和Concat之后会扩大特征丢失的影响并影响其余检测层。依据实验数据,网络在设计时不将最大特征层接入PAN,而是直接输出。本文提出的融合设计既考虑深层特征图所包含的语义信息,又考虑了浅层特征图的位置、边缘等特征信息,可以有效解决小目标害虫特征在模型中多次卷积操作后特征信息丢失的问题,同时提高模型对小目标害虫的检测能力。
2 数据分析处理与检测优化
2.1 数据分析与数据清洗
本文数据来源于第十届泰迪杯全国大学生数据挖掘挑战赛(https://www.tipdm.org)。数据包含28种害虫在探照灯背景下的图片,数据集由576张图片组成。在所提供的害虫样本数据中存在着严重的类别不平衡问题(图4)。在1 019个标签中,八点灰灯蛾样本数量最多,占全体数据的24.24%;褐飞虱属次之,占比14.72%;干纹冬夜蛾和豆野螟的样本数量最少(仅占0.09%)。如此类别不平衡的数据集将导致模型容易过度拟合那些样本更多的类别,同时忽视对小样本类别的学习。因此使用合理的数据增强策略对数据集进行扩充是有必要的。数据集的576张图片中包含大量错标和不完整检测框(图5),害虫微小的类间差异和类内差异很容易掩盖错误标注的样本,从而误导模型在训练时的优化方向,降低模型的识别能力。
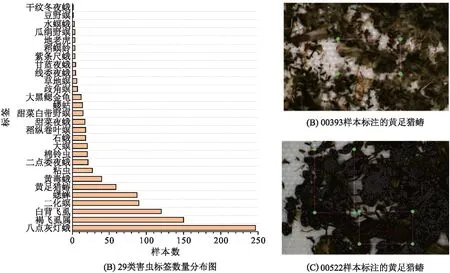
图4 29类害虫标签数量分布以及样本图片

图5 数据增强实例
在进行数据扩充之前,首先以检测框内是否含有完整昆虫个体、框内昆虫是否在背景中出现为标准,对数据进行清洗,数据清洗后得到533张标签图片,以这些标签图片作为原始数据集进行后续的模型学习训练。
2.2 基于检测背景的数据增强与检测优化
由于原始数据集图像过少,模型无法充分理解害虫特征,本文选择旋转、裁剪、镜像、平移等方法进行数据增强。数据集中存在大量复杂背景图片,害虫与背景难以分辨。在增强数据的基础上,批量调整HSV降低亮度以模拟复杂背景,进一步增强数据,最终形成1 599张图片组成的训练数据。对增强后的图像进行划分时,为避免随机分配导致测试集和验证集含有的图片与训练集内图片相似而影响实验结果,划分时将原始数据集中图片与其对应扩增图片划分为一组,统一对所有组图片进行划分。以图片数量8∶1∶1的比例划分为训练集、验证集和测试集。部分图片经过数据增强后如图5所示。
针对图像分辨率高,背景复杂、害虫目标小等特点和改进后YOLOv5模型计算量增大的问题,本文提出一种切割图像并检测的方法(图6)。为了在模型主干网络的卷积操作时不丢失高分辨率图像中小目标的特征信息,并防止显卡存储器超载,在目标图像分辨率过大时,将目标图像切割为多个图像并送入YOLOv5网络中检测,再回收所有图像,计算坐标的相对值,集体进行非极大值抑制计算,得到最终检测框并输出。此方法能一定程度上提升准确性,将切割后的图像输入目标检测网络中,会有效降低最小目标图像的像素。
3 结果与讨论
本实验在colab平台上进行,所分配GPU型号为Tesla K80,GPU 显存为 12 G,内存为16 G。训练参数设置:图片输入尺寸为640 px×640 px,学习率由余弦退火算法进行更新,可降低过度拟合的概率,最大迭代次数为200。本文选取YOLOv5x模型,一定程度上提高了模型的鲁棒性。判断指标选取均值平均精度(mean Average Precision,mAP):
(1)
(2)
其中,r1、r2、rn是按升序排列的精确率(P)插值段第一个插值处对应的召回率,K为检测任务所含类别数。mAP是目标检测领域的重要衡量指标,表示对目标检测中每个类别的平均精度求和后取平均。
3.1 数据集的处理结果
对数据集进行数据增强后得到的1 533张图片投入训练,并将增加图片切割检测机制与改进之前对比,收敛后结果如图7所示。模型能更快收敛且mAP明显提升。可见扩充数据样本并结合虫情探照灯捕获图片背景环境,对图像做降低亮度处理以模拟实际背景情况的策略得到较好的训练结果。

图7 训练过程loss和mAP曲线
3.2 改进YOLOv5模型的检测结果
在基本模型训练参数相同的情况下,模型改进前和改进后的准确率如表3所示。经算法改进和增强后,数据集训练损失曲线震荡减轻并得到较好的收敛(图8)。从表3的box_loss和mAP可看出,经过检测优化后的YOLOv5模型在识别精度上大幅提升。不但在本文数据集有进步且在害虫数据集IP102[20]上也有2%的提升,检测优化后的YOLOv5也能很好应对复杂背景下害虫图像的检测(图9),该结果进一步验证了本文模型的可靠性与实用性。
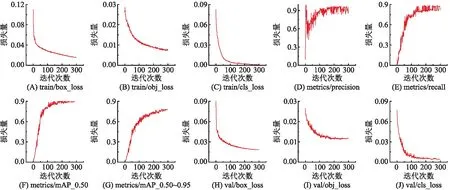
图8 优化后训练过程的loss和mAP曲线

图9 优化后测试的结果

表3 YOLOv5x模型优化前后的性能
4 结论
针对虫情探照灯捕获高分辨率图像中害虫识别统计的问题,本文提出基于深度学习模型的解决方案。首先对数据集进行数据增强的操作扩充数据样本,并结合虫情探照灯捕获图片背景环境,提出对数据集降低亮度处理,模拟实际背景情况,增大训练难度以达到更好的训练效果;其次改进YOLOv5模型的结构,增加检测层,不对原有正常尺寸目标识别产生影响,提高对小目标害虫的识别和定位准确率;同时结合数据集中图像分辨率较高的特点采取了先分割图像后进行检测的策略,一定程度上提高了检测准确率。结果表明以上方法均能有效提高识别准确率和鲁棒性。采用第十届泰迪杯全国大学生数据挖掘挑战赛的测试数据集验证,本模型具有可靠性和实用性。该成果获得了2022年第十届泰迪杯数据挖掘挑战赛全国一等奖。该方案对农业上害虫治理具有一定参考意义,也有助于提高农业现代化、智能化水平,具有较高的应用价值。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
好孩子画报(2021年9期)2021-09-26 12:26:31
今日农业(2020年23期)2020-12-15 03:48:26
作文小学中年级(2020年6期)2020-07-24 08:33:10
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
现代园艺(2017年21期)2018-01-03 06:42:15
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
现代农业(2016年5期)2016-02-28 18:42:39
河南科技(2014年23期)2014-02-27 14:19:15
