
A UAV collaborative defense scheme driven by DDPG algorithm
2023-11-06 14:19ZHANGYaozhongWUZhuoranXIONGZhenkaiandCHENLong
ZHANG Yaozhong ,WU Zhuoran ,XIONG Zhenkai ,and CHEN Long
1.School of Electronics and Information,Northwestern Polytechnical University,Xi’an 710072,China;2.College of New Energy and Intelligent Connected Vehicle,Anhui University of Science &Technology,Hefei 231131,China;3.China Research and Development Academy of Machinery Equipment,Beijing 100089,China
Abstract: The deep deterministic policy gradient (DDPG) algorithm is an off-policy method that combines two mainstream reinforcement learning methods based on value iteration and policy iteration.Using the DDPG algorithm,agents can explore and summarize the environment to achieve autonomous decisions in the continuous state space and action space.In this paper,a cooperative defense with DDPG via swarms of unmanned aerial vehicle (UAV) is developed and validated,which has shown promising practical value in the effect of defending.We solve the sparse rewards problem of reinforcement learning pair in a long-term task by building the reward function of UAV swarms and optimizing the learning process of artificial neural network based on the DDPG algorithm to reduce the vibration in the learning process.The experimental results show that the DDPG algorithm can guide the UAVs swarm to perform the defense task efficiently,meeting the requirements of a UAV swarm for non-centralization,autonomy,and promoting the intelligent development of UAVs swarm as well as the decisionmaking process.
Keywords: deep deterministic policy gradient (DDPG) algorithm,unmanned aerial vehicles (UAVs) swarm,task decision making,deep reinforcement learning,sparse reward problem.
1.Introduction
Since its emergence,unmanned aerial vehicle (UAV) has been widely used in People’s daily life and scientific research because its good performance and great application potential.Besides,UAV has natural advantages in carrying out military missions because of its concealment and security [1].However,with the continuous advancement of the application of UAVs in the military field,it is difficult to guarantee the flexibility and mission completion rate of a single UAV in the execution of tasks.Therefore,the use of multiple UAVs to form a swarm and utilizing UAVs swarm to perform related military tasks has become one of the important development trends in the militarization applications of UAVs [2].Recently,some researchers have worked on the intelligence algorithms of the UAVs swarm,such as the ant colony optimization (ACO) algorithm and the wolf group algorithm (WGA) to realize the command-and-control process of the UAV swarm [3,4].However,these methods have to take a long time to compute,lack flexibility,and have the weakness of low degree of intelligence.In recent years,the emerging field of artificial intelligence,with its powerful non-linear processing ability and the ability of perception and understanding of high-dimensional information,is expected to enable UAV swarm to have enough intelligence to complete tasks in a complex environment on the battlefield.
At present,some scholars have used artificial intelligence methods to carry out exploratory studies on relevant issues of the UAVs swarm.For example,Chandarana et al.applied classification methods in artificial intelligence to study the human-machine interaction mode of UAV and compared the interactive control methods of UAV based on mouse,voice,and gesture [5,6].Xu et al.developed deep reinforcement learning to research the autonomous target area coverage problem with UAVs swarms,which are used to solve the task planning problem and the challenge of high-dimensional state space under the joint action of multiple UAVs [7,8].Wang et al.proposed a utility maximization approach for tuning the reward generation of a multi-arm bandits (MAB)-based reinforcement learning approach for selecting energy and processing optimized data offload paths between a source and target UAV in a decentralized edge UAV swarm [9].Li et al.[10,11] used deep reinforcement learning methods to investigate the relevant factors that affect the autonomous air combat on UAV,which provides a theoretical basis for future intelligent air combat.The reinforcement learning approach is also applied to the resource allocation problem [12,13],and the global deep reinforcement learning model can be directly downloaded to the newly activated agent,which avoids the time-consuming training process.Wang et al.used deep reinforcement learning for pursuing an omni-directional target with multiple,homogeneous agents that are subject to unicycle kinematic constraints.With shared experience to train a policy for a given number of pursuers,executed independently by each agent at run-time,they achieved good training results [14].Liu et al.employed the deep neural network as the function approximator,and combined it with Q-learning to achieve the accurate fitting of action-value function for the intelligent tactical decision problem [15].Price et al.leveraged the deterministic policy gradient algorithms in an actor-critic construct using artificial neural networks as nonlinear function approximators to define agent behaviors in a continuous state and action space [16].They used the method i n target defense differential game and gained optimal results in both the single and multi-agent cases [16].
Moreover,some experiments on the application of artificial intelligence in UAV swarm have been undertaken in many countries,and the United States has also experimented with many UAV swarm projects.Especially in 2016,the UAV swarm experiment conducted by the U.S Army in California successfully applied artificial intelligence to the action decision-making of UAV swarm,and this experiment realized UAV swarm autonomous collaboration in the air,formed UAV cluster formation,and completed the scheduled tasks,which have been fully embodied the drone of the cluster’s decentralized,selfindependence and autonomous.These research results show that the ad-hoc network and task in UAV swarm decision-making is ready for commercial use [17].Hu et al.[18] presented an actor-critic,model-free algorithm based on the deterministic policy gradient (DPG) that can operate over continuous action spaces.Based on the DPG algorithm [19],they also combined the actor-critic approach with insights from the recent success of deep Q network (DQN) [20].The model-free approach,deep DPG (DDPG),proposed by Timothy et al.requires only a straightforward actor-critic architecture and learning algorithm with very few “moving parts”,and it is easy to implement and scale to more difficult problems and larger networks.
This paper investigates the UAV swarm defense mission using the DDPG algorithm.Due to the use of neural networks in DDPG,its powerful simulation ability makes the state space and action space of agents be extended from limited discrete type to infinite continuous type,which is closer to the real scene of UAVs defense missions.We successfully overcome the "sparse reward"problem by setting the reward function to obtain the appropriate reward value before an episode ends,thus making the algorithm easier to converge.At the same time,we also add random noise elements to the act selection to improve the random exploration ability of the UAV in the early training,which can obtain more abundant experience.
2.Task description
Among the numerous UAVs swarm tasks,the defense task is always the typical one of them.The defense task is to deploy the UAVs cluster around the defense target to prevent the possible attack from the incoming enemy and achieve the defense mission of the target.
2.1 Environment description
In this paper,a continuous two-dimensional battlefield map is constructed to serve as the exploration environment for UAV swarm defense task.The position of UAVs,incoming enemy,and the defended target are represented by continuous coordinate position,and the original state of the defensive task is shown in Fig.1.

Fig.1 Schematic diagram of UAV swarm defensive mission
As shown in Fig.1,there are insurmountable battlefield boundaries in the environment.It is stipulated that the defended target is generated in the lower left part of the environment and moves horizontally to the right and assumed that the movement of the defended target is not affected by the movement state of the incoming enemy and the UAV swarm.The initial region of the UAV swarm is on both sides of the defended target.The UAV swarm is randomly generated from the two initial regions of the UAV and it is accompanied by a certain random initial speed.In the upper right,there is the initialization region of the incoming enemy.The incoming enemy is randomly generated in this area.
It is assumed that there is only a single incoming enemy in the mission,and the incoming enemy aims to destroy the defended target.The incoming enemy knows the position and speed of the defended target,so it can maneuver according to the two guidance methods,and the movement of the incoming enemy will not be affected by the movement state of the UAV swarm.
The objective of the UAV swarm is to eliminate the incoming enemy and achieve defensive missions.To realize the destruction of UAVs to an incoming enemy,it is assumed that the UAV carries a weapon unit.To simplify the model,there is no limit on the number of weapons.It is only possible for an incoming enemy to be destroyed by UAVs when it enters the attack range of UAVs.
Therefore,there are three end states for UAV swarm to perform defense tasks: the incoming enemy is destroyed and the defense mission is completed;the defended target is destroyed and the defense mission fails;UAVs hit battlefield boundary and the defense mission fails.
2.2 Incoming enemy model
As the purpose of the incoming enemy is to destroy the defended target,the movement of the incoming enemy should be modeled.It is assumed that the position,speed,and other information of the defended target can be obtained by the incoming enemy,and the movement of the incoming enemy is guided through the information.It is known that the movement speed of the incoming enemy is 1.5 times the maximum movement speed of the UAV’s.In other words,The movement model of the incoming enemy is constructed based on the fire-control attack seeker which has two kinds of motion rules.
(i) Pure tracking attack
Pure tracking attack is an easy and common attack method,which is often used as the guidance method of infrared-guided missiles and other controllable weapons.The core of the pure tracking guidance method requires that the velocity vector of the incoming enemy always points to the center of the defended target at every moment,as shown in Fig.2.

Fig.2 Schematic diagram of pure tracking attack
The speed direction of the incoming enemy always points to the defended target,that is,
wherevrepresents the velocity vector;drepresents the distance vector from the incoming enemy to the defended target.Given that the velocity of the incoming enemy is a constant asvenemy,the movement strategy of the incoming enemy in the pure tracking attack mode can be obtained.
(ii) Pure collision attack
Pure collision attack is another common attack guidance method,which is often used for weapons that cannot be controlled autonomously after launching and the main guidance method of tactical contact with the enemy.Its core is that the velocity vector of the incoming enemy always points to the predicted impact point between the incoming enemy and the defended target,as shown in Fig.3.

Fig.3 Schematic diagram of a pure collision attack
According to the characteristics of pure collision guidance,in the process of navigation for an incoming enemy,it is necessary to calculate the expected impact point through the initial position,speed of the target,initial position,and speed of the defended target in the process of navigation.Then the velocity vector of the incoming enemy always points to the expected impact point with a constant velocity.And according to the characteristics of a pure collision attack,the speed of the incoming enemy always points to the defensive target relative to the defensive target’s velocity.
According to the sine theorem,it can be obtained that
whereρis the angle between the line connecting the positions of the attacker and the target and the velocity vector of the attacker,η is the angle between the line connecting the positions of the target and the attacker and the velocity vector of the target,vattackeris the speed of the attacker,andvtargetis the speed of the target.
It is assumed that the speed ratio between the incoming enemy and the defended target is=k,and sin η=,yis the ordinate distance between the incoming enemy and the defended target,dis the distance between the incoming enemy and defended target.Therefore,it can be known that
Therefore,the direction of the incoming enemy can be obtained.According to the guidance mode of pure collision attack,the incoming enemy will keep this speed direction until it hits the target.
The incoming enemy uses the above attack guidance method to attack the defended target.Each turn randomly selects one of the above attack guidance methods to attack the defended target.
2.3 Model of the UAV swarm
This paper uses a deep reinforcement learning algorithm to study the UAV swarm defense missions.Different from the traditional grid-based dimensionality reduction method used in the interaction between UAV and environment under the deep reinforcement learning algorithm,we construct a continuous UAV exploration environment,that is,the UAV can reach any point on the map,and the UAV has an infinite state space.The continuous environment greatly improves the authenticity of the environment model,which makes deep reinforcement learning an important step to practical application.Based on the continuous environment space,the UAV is modeled as follows.
(i) UAV kinematics model
For the continuous environment model,acceleration is used as the action control unit of the UAV,and the specific acceleration action space is shown in Fig.4.

Fig.4 UAV acceleration model diagram
The UAV is modeled because the UAV swarm defends the mission environment and uses acceleration to control its action.Moreover,the DDPG algorithm can control the continuous action of the UAV.As shown in Fig.4,the action space of UAV is controlled by its tangential accelerationa//and normal accelerationa⊥,and the value range of acceleration is limited.
Then the next state of a UAV is calculated according to the basic kinematic formula for each state.As shown in Fig.5,the kinematic model is given by

Fig.5 UAV kinematics model diagram
(ii) UAV detection model
It is assumed that the UAV can sense its environment globally.To make the model closer to the real environment,a normal distribution error is added to the UAV sensor information.The relevant parameters of the error are determined as follows:
Therefore,the UAV detection results are as follows:
wherexgetis position in thex-direction of the incoming enemy detected by the UAV;ygetis position in theydirection of the incoming enemy detected by the UAV;xis truex-direction position of the incoming enemy;yis truey-direction position of the incoming enemy;ε is a random value that follows a normal distribution.
The detection results of the UAV on the incoming enemy’s speed are as follows:
wherexnow,xold,ynow,yoldrespectively represent the incoming enemy’s position detected under the current conditions and the previous conditions andtrepresents the detection cycle of the UAV swarm.Because of the detection error of the UAV swarm to the incoming enemy’s position,the detection error of the UAV swarm to detected velocity state always exists.
(iii) UAV attack model
It is assumed that the UAV has an attack mode,which is set as a circular attack area to simplify the model.Assuming that the attack radius of the UAV isrwhen the incoming enemy enters the attack area of the UAV,the UAV begins to attack,and the UAV can launch an attack on the incoming enemy every three simulation cycles.In each launch,the UAV has a certain probability of destroying the incoming enemy,and the probability of destroying is related to the distance between the incoming enemy and the UAV.The probability of destroying an incoming enemy in each attack is assumed to be as follows:
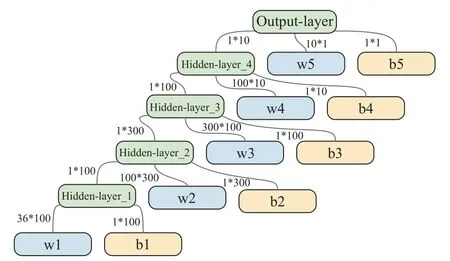
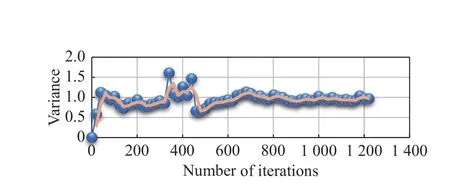
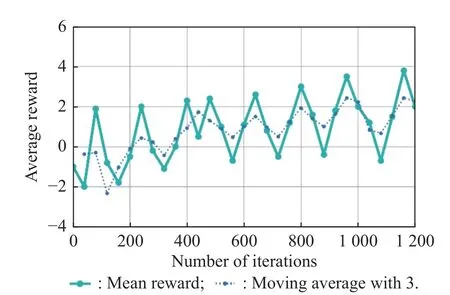
wheredageng_targetrepresents the distance between the drone and the incoming target.Whendageng_target (iv) UAV communication model To make UAVs have better action decisions,local communication between UAVs is required.Different from centralized communication which needs the central node,we adopt the flat distributed communication structure.Assume that each UAV can communicate with its adjacent drones,and each drone can obtain its three nearest neighbor’s position,velocity,and other related information,as shown in Fig.6. Fig.6 Schematic diagram of UAVs communication The arrow direction in the figure shows the process of the UAV transmitting its position,speed,and other state information and corresponding detected information to the adjacent UAV.Besides,the state of the UAV itself and the state of the adjacent UAV transmitted by communication is taken as the perception state of the UAV to the current environment. In this paper,the UAVican sense the following properties about other UAVs within its neighborhood: di,jis the distance to its neighboring UAVs; φi,j=arctanis the bearing angle to its neighboring UAVs; viis the velocity of the UAV itself.denotes the absolute bearing angle of UAVito the closet battlefield boundary segment. The DDPG algorithm is a deep reinforcement learning algorithm combining value iteration and policy iteration[21,22].The DDPG algorithm uses neural networks to learn and preserve the UAV action strategy,which can explore the environment and learn optimal strategy in infinite size state space and action space. DDPG algorithm combines advantages of the “actor &critic” algorithm and the DQN algorithm,which is a new deep reinforcement learning algorithm [23,24].The algorithm structure is shown in Fig.7. Fig.7 Structure of the DDPG algorithm The actor part and the critic part each have a pair of artificial neural networks with exactly the same structure,which is called Eval neural network and Target neural network respectively.Among them,Eval neural network is used for training and Target for updating the parameters of Eval network,which are followed by periodic soft update strategy and assist in the training process of the neural network. The actor neural network determines the probability of UAV’s action selection.When the UAV makes behavioral decisions,it will interact with the environment according to the probability provided by the actor neural network.The critic neural network receives the state and action and generates the value evaluation of the “stateaction”,in which the Eval neural network is used to judge the value of the current state and action,and the Target neural network receives the state at the next moment and the action at the next moment from the actor Target neural network and makes the value judgment. Actors and critics have different training processes using different loss functions.For the critic network,TDerror is used to update the parameters of Eval neural network to minimize loss during training,as shown in (11)and (12). For the training process of actors neural network,it is necessary to maximize the value function of state and action,so the mean value of evaluation of state and action is used as the loss function,as shown in (13): Although the DDPG algorithm outputs the probability distribution of UAV’s action selection in the process of UAV’s action selection,in the final process of UAV interaction with the environment,the only action is still selected according to the given probability distribution[18].Therefore,in the process of UAV interaction with the environment,it always uses a deterministic strategy,which will lead to insufficient exploration of the environment by UAV.Therefore,it is necessary to add some exploration to the strategy selection of DDPG algorithm[25]. The exploratory method to increase the exploration ability for the DDPG algorithm needs to add some random noise to the action selection process of UAV.As shown in (14): where action is the interaction between the UAV and the environment;action′is action selected according to the probability distribution of actions given by the actor-network;Noise is the random noise. The action decision made by the DDPG algorithm can output the continuous action of UAV.Therefore,it is feasible to enhance the exploratory performance of the DDPG algorithm by using the above method,and the random noise is normally distributed: The variance of the random noise is the quantity related to the iteration round.As the training progress goes on,the variance decreases gradually.According to the characteristics of the normal distribution,we give the initial value of the variance as follows: The variance change of random noise used to increase the exploratory of DDPG algorithm is shown in (16) and (17),and here based on the training experience κ=0.999 5,episode represents the training cycle,which can ensure that the action selection of UAV has a large exploration rate.At the same time,when the action selection of UAV exceeds the maximum range,it is restricted to the corresponding action boundary. The network structure diagram of the DDPG algorithm is constructed by using an artificial neural network,where the “actor” and “critic” parts of the DDPG algorithm have a pair of neural networks with the same structure,and the two neural networks will be introduced below. (i) “Actor” part of artificial neural network It is well known that the neural network of the “actor”part is used to select the action of UAVs,that is,to realize the mapping of the state space of UAV swarm to the action space of UAVs. In UAV swarm defense mission scenario,the state space for the UAV swarm is defended target positionxcenter,ycenter,UAVs’ positionxagent,yagent,UAVs’ speedvx_agent,vy_agent,and the incoming enemy’s positionxtarget,ytarget,the incoming enemy’s speedxtarget,ytarget,and other information that gained by the interaction with other UAVs in the swarmxagent_comm_i,yagent_comm_ivx_agent_comm_i,vy_agent_comm_i,as well as the other UAVs to detect the incoming enemy’s informationxagent_comm_i_get,yagent_comm_i_get,vx_agent_comm_i_get,vy_agent_comm_i_get,a total of 34 dimensions for the UAV swarm state space.These state data are sorted and coded in a fixed order to form the state space structure of the UAV swarm,as shown in Fig.8. Fig.8 State space of UAV swarm Therefore,for the “actor” part: the Target andEval neural network,two fully-connected artificial neural networks (excluding the input layer) with the same structure are constructed,and we have a six layers neural network,the number of neurons in each layer is respectively[100,100,300,100,10,2].Neurons in the last layer of the neural network use tanh(x) as nonlinear activation functions to realize the mapping between the network output and UAV’s action,while other neurons use relu(x)=max(0,x)as nonlinear activation functions.And the root mean square prop (RMSP) algorithm is used as the optimization algorithm of training.The neural network structure is shown in Fig.9. Fig.9 Artificial neural network structure of the “actor’s part” (ii) “Critic” partial artificial neural network Through the determined value of “state-action”,the critic’s partial neural network guides the training process of the “actor” neural network [26].Therefore,the input state of the critic neural network is the state information and action information of the UAV swarm,and the state space structure of the critic network is shown in Fig.10. Fig.10 Input data structure of “critic section” neural network It is also built via two completely identical 5-layer all connected artificial neural networks (excluding the input layer) for the “critic” part of the Target and Eval artificial neural network,the number of neurons in each layer is respectively [100,300,100,10,1].The neurons of the last output layer use tanh(x) as a nonlinear activation function,while the other neurons use relu(x) as a nonlinear activation function,and the RMSP algorithm is used as the optimization algorithm for training.The structure of the neural network is shown in Fig.11. Fig.11 Artificial neural network structure of the “critic” part For the “actor” part and the “critic” part,there exist simultaneously the Target and Eval neural networks,Evalis used for the training process,and the parameters of the Target neural network change periodically with the corresponding parameters of the training network.For the parameter update of Target neural network,the soft update strategy based on the sliding average value is adopted,namely, where θTargetrefers to Target neural network parameters;θEvalrefers to Eval neural network parameters;kis the sliding factor,with a value of 0.2. Since the continuous state space and action space are used in this research,the UAV will undergo a long interaction with the environment to reach the final state after initialization [24].At this point,the method of rewarding UAV only after it reaches the final state has the defect of too long return period,which leads to the failure of effective learning in reinforcement learning,that is,the problem of sparse reward. For the sparse reward problem,there are two common solutions: one is to divide the main task and set related small goals for the main task so that the UAV starts learning from the small goal first,to speed up learning [27].Another one is to modify the goal to increase the effective reward,to speed up learning.We adopt the second method to accelerate the training and construct the reward function of UAVs to guide the learning direction of deep reinforcement learning. wheredagent_targetis the distance between the UAV and the incoming enemy at the current state;is the distance between the UAV and the incoming enemy in the next state;β is angle between speed direction of the UAV and connection line between the UAV and the incoming enemy at the current state;vagentis the velocity of the UAV at the current state;dcenter_targetis the distance between the defended target and the incoming enemy. According to the above different termination states,there are different reward function values.When the UAV swarm completes the defense task,the UAV swarm that destroys the incoming enemy will receive a positive rewardr=100.When the collision boundary of UAV swarm leads to the early end of this turn,the UAV colliding with the battlefield boundary is given a negative rewardr=-10.If the UAV swarm fails to complete the task and the defended target is destroyed,the UAV will be given a negative rewardr=-100.For the exploration phase of UAV in the environment,the reward function with enlightened characteristic is adopted: The reward function of the enlightened property is composed of the distance between the UAV and the incoming enemy,the speed and direction of the UAV,and the distance between the defended target and the incoming enemy.Obviously,in defense missions,the reward function corresponding to the smaller distance between UAV and the incoming enemy is positive.When the UAV’s velocity vector points to the incoming enemy,the higher the UAV’s velocity is,the higher the reward function will be.When the UAV’s velocity vector deviates from the incoming enemy,the higher the UAV’s velocity is,the higher the negative reward function will be.At the same time,it increases the distance between the incoming enemy and the defended target as the reference of time and the threat of the incoming enemy to the defended target.The closer the distance between the incoming enemy and the defended target is,the greater the negative reward will be.To sum up,(19) reward function can accurately reflect the state value of UAV swarm. A detailed description of DDPG algorithm is provided in Algorithm 1. The DDPG algorithm is used to study the defense task of UAV swarm against the incoming enemy which is randomly generated using either pure pursuit or pure collision attack mode against the defended target.The initial position of the UAV swarm is generated randomly in the designated area,and its initial state is random.Therefore,the DDPG algorithm is used to command the action decision of UAV swarm,to observe the performance of UAV swarm in defense tasks. The artificial neural network constructed above is used for training,during which five isomorphic drones are used for defense missions.It is assumed that each UAV receives relevant information from three adjacent UAVs to assist in decision making and the maximum training epoch is 1 250.The snapshots of the training peocess are shown in Fig.12. Fig.12 Snapshots of different training epochs Fig.13 Mean changes of network parameters in “critic” section from Eval network Fig.14 Variance changes of network parameters in “critic” section from Eval network Fig.15 Mean changes of network parameters in “actor” section from Eval network Fig.16 Variance changes of network parameters in “actor” section from Eval network Firstly,the convergence of the artificial neural network is analyzed,and the parameters of the neural network layers of “critic” and “actor” are selected for relevant statistics.Since there are massive parameters in the neural network,the mean and variance of the parameters are statistically observed.The statistical results are shown in Figs.13-16. The parameter statistics of the above figure are selected from the parameter statistics of all neurons in the neural network of the “critic” part and “actor” part.The solid line is the statistical truth value of the parameter,while the dotted line is the result of sliding average processing of the statistical truth value with a period of 3.In Fig.17 and Fig.18,it can also be seen from the distribution trend of target network parameters of actor and critic that the parameters of neural network are constantly changing during training and eventually tend to be stable.It is proved that the neural network tends to converge during training.It can be seen from the above statistics that the artificial neural network converges during the training process. Fig.17 Changes of Target network parameters distribution in the“actor” section Fig.18 Changes of Target network parameters distribution in the“critic” section This paper processes the data in the UAV training process and uses memory playback unit to store the samples,and the reward value in each sample is the return of the interaction between the UAV and the environment,as well as the performance reference index when the UAV interacts in the environment.Fig.19 shows the reward values of the samples selected for training against the increase of training rounds. Fig.19 Mean reward of samples in different epochs As shown in Fig.19,with the increase of training rounds,the average reward of training samples rises slowly,that is to say,the UAV behavior represented by the samples in the memory playback unit is trying to be beneficial to the direction adjustment of the task target,and the UAV training will have better and better performance,while the dotted line is the result of sliding average processing of the statistical truth value with a period of 3. Fig.20 shows the evolution of the average episode rewards in different rounds during the training process. Fig.20 Mean episode reward under different training rounds Fig.20 shows that DDPG achieves very good performance on our task.As expected,we see that with the increase of the total training rounds,the total rewards of the round increases steadily.When it reaches 800 rounds,it is close to convergence. Using the above method to train five UAVs,and the mission success rate of each round is shown in Fig.21. As can be seen from Fig.21,the UAV clusters after training can well complete the defense task,with an average success rate of 95%. After the completion of the defense task training with five UAVs,the artificial neural network verifies the completed training model.The artificial neural network model completed by training is used as the behavioral decision-making unit of the UAV swarm.The UAV has a certain random initial state,and the initial position of the incoming enemy is also randomly generated in the designated area.Firstly,the behavioral decision of using five UAVs for defense missions is verified,and the movement trajectory of the UAV swarm is obtained,as shown in Fig.22. Fig.22 Trajectory of five UAVs in a defense mission As shown in Fig.22,the trained model can well accomplish the defense tasks of the cluster of five UAVs.Then,increasing the number of UAVs to 30 without changing the state space structure of the UAVs cluster.It is to verify the UAV swarm defense mission by using the trained network (in the cluster defense mission environment composed of five UAVs,the artificial neural network has undergone 1 250 epochs of training).Also,the initial position and initial velocity of the UAV swarm are random to some extent.The performance of the swarm composed of more UAVs when the defense task is verified,and the mission trajectory of the UAV swarm is shown in Fig.23. Fig.23 Trajectory of 30 UAVs in defense mission As shown in Fig.23,the decision-making model of UAV swarm defense mission obtained by training with five UAVs can be applied to the swarm defense mission composed of more UAVs without modifying the state space structure.At the same time,it also shows that the behavior decision of UAV swarm using DDPG algorithm can well meet the challenge of UAV swarm to a dynamic number of individuals,reflecting the characteristics of UAV cluster autonomy. In this paper,the DDPG algorithm is used to study defense task of the UAV swarm,which have a continuous state space and action space.To balance the contradiction of “experience-exploration” in the DDPG algorithm,we add random noise elements to the act selection to improve the exploration ability of the algorithm.At the same time,the random noise will decrease with the increase of iteration epochs to ensure the convergence of the algorithm.To improve the performance of the algorithm,the parameter updating process of a neural network is optimized.To solve the problem of “sparse reward” in deep reinforcement learning,we build a guiding reward function to give the UAV swarm appropriate reward when an episode is not over,which effectively improves the convergence of the algorithm. According to simulation results,we use the DDPG algorithm to guide the UAV swarm for decision making which successfully defend the target from the incoming enemy.Meanwhile,under the same state space,the model trained from a small number of UAVs can be directly applied to more UAVs to form swarm to perform the corresponding tasks,which fully embodies the characteristics of UAV swarm,such as decentralization and autonomy.This also reflects the use of artificial intelligence method to study the strong generalization ability of the UAV swarm decision-making problem.
3.DDPG algorithm
3.1 Algorithm structure

3.2 Balance of DDPG algorithm in exploration and experience
3.3 Network model of DDPG algorithm



3.4 Sparse reward problem of DDPG algorithm
3.5 DDPG algorithm flow

4.Simulation results
4.1 Training process






4.2 Execution process


5.Conclusions
 Journal of Systems Engineering and Electronics2023年5期
Journal of Systems Engineering and Electronics2023年5期
- Journal of Systems Engineering and Electronics的其它文章
- A spawning particle filter for defocused moving target detection in GNSS-based passive radar
- Cuckoo search algorithm-based optimal deployment method of heterogeneous multistatic radar for barrier coverage
- Radar fast long-time coherent integration via TR-SKT and robust sparse FRFT
- Robust dual-channel correlation algorithm for complex weak target detection with wideband radar
- Deep convolutional neural network for meteorology target detection in airborne weather radar images
- Super-resolution parameter estimation of monopulse radar by wide-narrowband joint processing