
用于小样本的网络安全领域信息抽取统一模型
2023-11-06 05:59顾杜娟章瑞康李文瑾
信息安全研究 2023年11期
卜 天 张 龙 顾杜娟 袁 军 章瑞康 李文瑾
(绿盟科技集团股份有限公司 北京 100089)
(butian1997@163.com)
随着信息化时代的到来,网络安全在国家安全的地位愈发重要,如何分析安全情报成为网络安全领域的重要课题.安全情报的数据来源多、内容复杂、差异性大,其分析过程的成本较高,通常需要较高的专业领域知识.因此,各大网络安全平台均趋于使用自动化方法,即利用信息抽取技术提取威胁情报报告中的重要信息.
信息抽取任务主要包含实体识别、关系抽取和事件抽取3类任务,大多数方法都是对不同的抽取任务分别建模.He等人[1]使用BERT+BiLSTM+CRF对网络安全领域的命名实体进行识别;陈浩等人[2]在He等人[1]研究的基础上引入图注意力网络实现威胁情报中实体间关系的抽取;Lin等人[3]基于卷积神经网络提出了PCNN+ATT模型,该模型通过定位文本位置实现关系抽取;秦娅等人[4]引入深度残差学习(deep residual learning,DRL)的方法将Lin等人[3]的关系抽取应用在网络安全领域;黄振洋等人[5]使用机器阅读理解(machine reading comprehension,MRC)方法实现网络安全领域安全事件的抽取.
尽管不同任务分别建模的抽取方式简单且易于操作,但对于集成多个抽取任务的网络安全平台,该方法存在较大的限制与缺陷.首先,针对不同的抽取任务构建的多个模型增大了模型的管理难度和机器成本;其次,完全重新训练特定领域的独立模型对标注数据量的要求较高,并且将实体类型编码到模型内部,难以引入新的实体类型;最后,不同的抽取任务存在部分通用知识和能力,训练不同任务的独立模型严重限制了相关任务和环境之间的知识共享.
Raffel等人[6]提出了一种T5框架,采用seq2seq框架,通过问答的形式统一了多种自然语言处理任务的模型、目标、训练程序和解码方式;Lu[7]提出了统一式信息抽取模型(universal information extraction,UIE),该模型设计了统一的结构化抽取语言SEL,将不同的抽取任务结构转化成统一的表现形式,实现了不同信息抽取任务的统一.但是,该模型采用了生成式的抽取方法,抽取结果稳定性不佳;Lu[8]提出了双向语言理解模型UBERT,该模型通过biaffine网络对不同NLU任务进行通用建模.
目前的统一式信息抽取模型虽然在通用领域实现了较好的效果,但其和网络安全领域的关联性较低.并且,对prompt的利用方式较为简单,如UIE模型中的prompt仅使用schema中的实体名称拼接生成,未能充分利用专业领域的先验知识.同时,各个模型基本都将prompt和文本拼接后输入,prompt和文本两两组合编码导致预测效率较低,难以在工程中使用.
因此,本文提出了一种针对于网络安全领域的统一式信息抽取(machine reading comprehension based universal information extraction,MRC-UIE)方法.该方法对不同的抽取任务统一建模,不同的信息抽取任务共用底层的通用知识和抽取能力,使用单一模型实现不同的信息抽取任务,降低了模型的管理难度.同时,模型使用大量开放领域信息抽取数据进行预训练,使模型具备通用的信息抽取能力.并且,模型中的prompt方法增强了模型在不同领域、不同待抽取实体类型中的迁移能力,减少了模型训练的数据量需求,在小样本情况下仍然能取得较好的抽取效果,在30shot的情况下,模型达到了70.30%的F1值.
此外,本文对网络安全领域中不同的待抽取信息设计了特殊的prompt,采用实体的注释描述作为prompt,并在其后拼接常见的关键词和句式结构.将特殊领域的先验知识以prompt的形式传入模型,让模型更专注于通用抽取能力的学习.针对prompt与文本输入拼接导致的预测效率低的问题,模型设计为文本和prompt分别输入.在工程使用中,通过预先存储prompt的编码向量提升模型的预测速度.
本文的主要贡献有3个方面:
1) 提出了一个统一式信息抽取的MRC-UIE模型,该模型可以自适应匹配抽取类型,并完成多项抽取任务;
2) 针对网络安全领域进行如下研究工作:网络安全领域实体的构建、适用于网络安全领域的prompt模板设计以及模型的优化等;
3) 在网络安全领域验证了模型的能力,模型在不同抽取任务上效果较好,同时具有一定的小样本能力.
1 基于MRC-UIE的信息抽取模型
1.1 统一式抽取
不同的信息抽取任务存在不同的抽取结构,如NER(named entity recognition)任务中仅抽取文本中的命名实体,而RE(relation extraction)任务还需要抽取关系类型并关联对应的头尾实体,EE(event extraction)任务则需要抽取触发词及其关联的论元实体,故需对不同的抽取任务进行统一.
如图1所示,MRC-UIE将不同的信息抽取任务分解为实体提取和标签分类2个任务的组合:1)实体提取任务用于选择文本中的词语,包括NER中的命名实体、RE中的头尾实体、EE中的触发词和论元实体,提取的结果由头尾指针共同输出;2)标签分类任务通过分类指示器的形式实现,MRC-UIE预定义了一个拼接在文本头部的占位符〈holder〉,该符号用于指示文本是否存在prompt查询的类型,当指针指向〈holder〉时表示文本中存在prompt对应的查询信息,否则不存在.
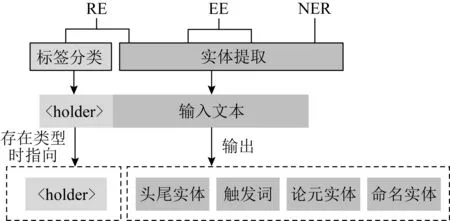
图1 统一式抽取下的2大任务
以句子“Seeing they can lure thousands of users into installing their deceptive applications”为例,统一后的抽取目标如图2所示.

图2 不同任务统一后的抽取目标
通过这种分解,将不同的抽取任务转化为实体抽取或分类任务,模型每次完成单一类型的子任务.
1.2 prompt模板
本文参考BERT-MRC[9]引入机器阅读理解模式完成单一类型的实体识别任务.为每一种待抽取实体类型都设计了一个对应的上下文,并通过该上下文帮助模型确定文本中的待抽取信息.具体而言,该上下文是一种基于自然语言的prompt模板,prompt模板既能自适应调整不同的抽取实体类型,又能通过自然语言扩充专业领域的先验知识.
MRC-UIE设计了一种基于自然语言主导(natural language instructor,NLI)的prompt模板:
p=[query+type_prompt],
(1)
模板包含query和type_prompt2部分,query用于确定抽取的任务类型,type_prompt用于确定抽取的信息,并引入领域知识.
query=[find,t,〈task〉],
(2)
t∈{relation,subject,object,event,role,entity},
query包含3部分,find和〈task〉是固定的引导词,t用于确定待抽取的任务类型.由于NER中包含实体抽取(entity)任务,RE中包含关系识别(relaiton)和头尾实体抽取(subject/object)2种任务类型,EE中包含触发词抽取(event)和论元抽取(role)2种任务类型,故query中的t∈{relation,subject,object,event,role,entity}.
type_prompt=[explain+grammar],
(3)
type_prompt包含自然语言释义(explain)和常见句式(grammar)2部分信息.释义描述了抽取实体类型的定义.网络安全领域的实体具有一定特殊性,如实体类型“Threator”表示网络攻击的攻击者或攻击组织,而非通用领域中物理上的攻击或威胁.因此,本文没有直接使用实体名称作为prompt,而是针对每个实体类型重写了标注注释作为prompt.常见句式则列举了抽取类型所涵盖的部分内容,如常见的关键词和句式等,让模型专注于学习较为通用的抽取能力.MRC-UIE中不同抽取任务类型使用的prompt模板如表1所示:

表1 不同任务类型及抽取标签对应的prompt模板
1.3 样本构造
MRC-UIE模型的输入层包含文本、prompt和前置限定3部分:文本指待抽取的目标文本;prompt指抽取类型对应的prompt模板;前置限定作用于关系抽取任务和事件抽取任务,当抽取头尾实体和论元实体时提供如关系类型、触发词等限定信息.图3所示为不同抽取任务对应的输入样本.接下来详细描述各个信息抽取任务的样本构造方式.
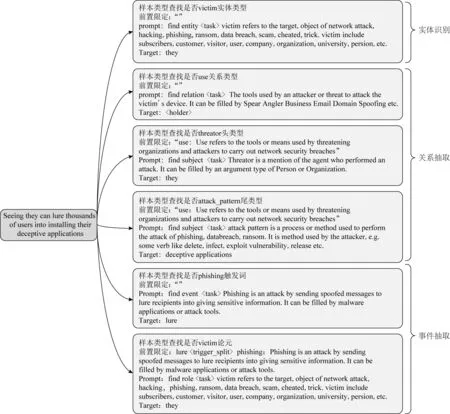
图3 不同抽取任务的输入样本结构
命名实体识别:prompt输入为实体类型的prompt模板.命名实体识别任务没有前置限定输入,所以输入设定好的空占位符作为代替.
关系抽取任务:将一个完整的关系抽取任务分为3个子任务:先识别是否存在prompt匹配的关系类型,如果存在再分别抽取该关系对应的头尾实体.关系识别子任务中,prompt输入为要查找的关系类型的prompt模板,前置限定输入使用空占位符替代.头尾实体识别任务中,prompt输入使用头尾实体的prompt模板,前置限定输入为关系类型的prompt模板.
事件抽取任务:事件抽取任务分为触发词抽取和论元抽取2步.触发词抽取类似于实体识别,prompt输入为事件类型的prompt模板,前置限定输入使用空占位符代替.存在触发词才能进行论元抽取,论元抽取的prompt输入为论元类型的prompt模板,前置限定输入为触发词和事件类型的prompt.
1.4 模型结构
MRC-UIE的模型架构如图4所示,编码器使用预训练语言模型Deberta进行初始化[10],解码器使用指针标注的方法,通过头尾指针输出抽取的文本块.设输入文本为x,各任务对应的prompt为p,前置限定为r.使用Deberta作为编码器对文本、prompt和前置限定进行编码:

图4 MRC-UIE模型架构
(4)
Encoding表示编码过程,x′,p′,r′分别为文本、prompt和前置限定的编码结果.为了生成带注意力的编码向量,本文使用Attention[11]机制计算文本向量在前置限定和prompt模板上的注意力权重:
(5)
fattn为self-attention机制,cprompt和crest表示文本分别与前置限定和prompt模板交互后的信息,⊕表示按位相加操作,将带注意力权重的前置约束和prompt整合为编码向量H.最后将编码向量输入到双向GRU中,并添加2个全连接层作为解码器,使用指针解码span的头尾位置:
s,e=GRU(H),
(6)
s为解码得到的头指针(start pointer),e为解码得到的尾指针(end pointer),y(s,e)为文本x上的第s个到第e个词语,即模型实体提取的结果.
1.5 损失函数

(7)
1.6 模型优化
BERT-MRC[9]将prompt与文本拼接在一起作为输入,导致prompt模板和文本都被重复编码,效率较低.因此,MRC-UIE将文本、prompt和前置限定分开输入,并对prompt和文本的编码向量预先存储,减少重复编码,有效提升预测速度.使用这种方法,每个prompt和文本只进行了1次Deberta编码,表2所示为编码向量预存储前后的速度对比.

表2 信息抽取的速度对比 s
MRC-UIEsave-为不引入预存储的模型,其预测速度慢于引入预存储的MRC-UIE模型.
2 实 验
2.1 数据集及实体类型
本文实验分别从网络安全领域的信息抽取论文中搜集了Automatic_extraction[12-13],Automatic_Labeling[14-15]和Automatic_Identification这3个数据集,其中Automatic_Labeling为Metasploit,MS_Bulletin和nvd 3个数据集合并的结果,同时引入了CASIE[16]和Conll[17]2个常用数据集.本文实验使用的数据集及描述如表3所示:

表3 数据集及其对应描述
本文将多个不同的数据集中的实体类型重新整合定义,整合后实体库共包含26个实体类型,如表4所示.

表4 实体库
本文实验中的事件类型和论元类型均引用CASIE数据集的定义.事件是指某个网络安全事件,包含phishing,databreach,patch vulnerability,discover vulnerability,ransom等.而论元是事件的参与主体,主要包含实体、值、时间组成,如victim,attacker,attack pattern,purpose,time,tool等.
2.2 模型配置
对得到的所有样本进行拆分,80%作为训练集,20%作为验证集,实验的正负样本比例为1∶5.使用deberta-v3-large[18-19]初始化模型,利用全部网络安全数据对初始化模型进行预训练.使用Adam optimizer[20]作为优化器,初始学习率设为1E-4,并使用线性调度,warm up比例设为5%.
2.3 实验结果
本文将MRC-UIE模型分别和各数据源下的最优模型进行对比,实验结果如表5所示.MRC-UIE在Automatic_extraction,CASIE,Automatic_Identification和Automatic_Labeling 4个数据集上都取得了最优表现,对于合并后的Automatic_Labeling数据集,本文也将原文所示指标进行加权平均操作,作为原模型的整体结果.

表5 对比实验结果 %
本文对BERTbase-CRF,BERTdwm-CRF和MRC-UIE在不同实体上的F1值进行对比,其中,BERTbase-CRF仅使用了基础的BERT模型和通用语料,而BERTdwm-CRF额外引入了领域语料的预训练。结果如表6所示,在Automatic _Identification数据集上,MRC-UIE模型在55%的实体类型上的得分高于其余2种模型.

表6 Automatic _Identification数据集不同实体F1值 %
表7所示为对MRC-UIE在Automatic _Identification数据集上的小样本能力进行的检测,发现模型仅需数十条样本即可具备较好的抽取能力.

表7 小样本能力检测实验结果 %
3 结 论
本文提出了一种基于MRC-UIE的信息抽取方法,可以从非结构化文本信息中抽取实体、关系和事件.针对网络安全领域,本文对不同数据源的网络安全实体进行了统一,构造了包含26种实体的实体库;设计了一种基于自然语言主导的prompt模板,引入先验知识的同时,解决了抽取新实体的问题.除此以外,本文还对模型的预测速度进行了优化,通过拆分输入层和编码器有效提升了预测速度.
通过将MRC-UIE 和5种信息抽取方法进行对比实验,结果表明,MRC-UIE在83%数据集上的表现均有明显优势,在NER和RE这2个任务上的F1值分别达到66.88%和92.33%.此外,还对MRC-UIE在小样本上的信息抽取能力进行测试,发现模型仅需要10-shot就能得到较好效果.
猜你喜欢
中国生殖健康(2020年5期)2021-01-18
教书育人(2020年11期)2020-11-26
当代陕西(2020年13期)2020-08-24
中国外汇(2019年18期)2019-11-25
中国生殖健康(2019年10期)2019-01-07
信息安全研究(2018年12期)2018-12-29
中国生殖健康(2018年5期)2018-11-06
小学生必读(中年级版)(2018年4期)2018-07-05
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
