
基于迁移学习的DenseNet模型在植物叶片病虫害分类研究
2023-11-03 14:10刘艺孙延斌翟凤国梁新
新一代信息技术 2023年12期
刘艺,孙延斌,翟凤国,梁新
(1. 牡丹江医学院,黑龙江牡丹江 157011;2. 牡丹江医学院附属红旗医院,黑龙江牡丹江 157011)
1 引言
植物病害影响其各自物种的生长,因此早期识别非常重要。许多机器学习(Machine Learning,ML)模型已被用于植物病害的检测和分类,但是,在ML的一个子集(即深度学习(Deep Learning, DL))取得进展之后,这一研究领域在提高准确性方面似乎具有巨大的潜力[1]。
叶片病斑的颜色和形态特征是病害识别的重要依据[2],传统的机器学习方法在植物病虫害识别中主要依赖图像处理技术来提取叶片病斑的颜色、形状、纹理等特征。这些方法需要手动设计和选择特征提取算法,并且其分类性能很大程度上依赖特征提取的效果。这些方法通常是针对特定的病虫害进行设计的,缺乏泛化能力,难以应用于其他病虫害的识别[3]。相比之下,深度学习技术在植物病虫害识别中具有许多优势。深度学习模型能够自动学习和提取图像中的特征,无需手动设计特征提取算法[4]。通过深层神经网络的层层堆叠和训练,深度学习模型可以学习到更加高级和抽象的特征表示,从而能够更准确地区分不同的病虫害。深度学习模型具有较强的泛化能力,可以应用于多种病虫害的识别任务[5-7]。通过大规模的训练数据集和深度神经网络的结构优化,深度学习模型能够实现快速、准确的病虫害识别。与传统的机器学习方法相比,深度学习技术能够更好地处理图像中的复杂特征和背景噪声,提高识别的准确性和鲁棒性。
许多最先进的深度学习模型/架构在引入AlexNet后发展起来用于图像检测、分割和分类,如图1所示。AlexNet被称为第一个现代卷积神经网络[8]。图像识别性能的关键在于其时间。AlexNet采用ReLU激活函数实现更好的性能,采用Dropout技术避免过拟合。OverFeat是第一个通过单个CNN进行对象检测、定位和分类的模型。与AlexNet相比,有大量的参数。VGG考虑到3×3接收野包含更多的非线性函数,使决策函数具有判别性。由于参数数量多,计算成本高,GoogleNet 与AlexNet模型相比,参数数量更少,即时的准确性更高。ResNet解决了梯度消失问题,精度优于VGG和GoogleNet模型。本文中所提到的DenseNet通过密集连接、梯度传播、参数效率、更好的特征表示和鲁棒性等方面的优势,成为深度学习领域中重要的网络架构之一,被广泛应用于图像分类、目标检测、语义分割等计算机视觉任务中。本文提出一种基于DenseNet的模型,以适应植物叶片病虫害分类任务,并提高模型在该任务上的性能。

图1 从AlexNet到DenseNet的模型演变
2 数据预处理
2.1 实验材料
本实验采用从Kaggle网站获取的患病叶片图像以及相应的标签数据集,原始图像共54 305张。如图2所示,其中包含正常苹果、番茄、马铃薯、玉米、葡萄等农作物正常叶片以及苹果黑霉病、番茄叶枯病、马铃薯晚疫病、玉米叶枯病等病变叶片,共38类。将数据进行划分,训练集占80%,验证集和测试集各占总数据集的10%。

图2 数据集中叶片预览
2.2 数据增强
数据增强是一种常用的技术,用于在训练过程中对输入数据进行随机变换,以增加数据的多样性和泛化能力。使用以下5种数据增强方法。(1)随机高度变换:在每个样本上,将图像的高度随机调整,最大调整范围为原始高度的20%。(2)随机宽度变换:在每个样本上,将图像的宽度随机调整,最大调整范围为原始宽度的20%。(3)随机旋转:在每个样本上,将图像随机旋转,最大旋转角度为20度。(4)水平翻转:在每个样本上,以50%的概率将图像水平翻转。(5)像素值缩放:将图像的像素值缩放到0到1的范围,以便更好地适应模型的输入要求。
通过这些数据增强方法,每个训练样本都会在每个训练迭代中以随机的方式进行变换。这样可以增加数据的多样性,使模型能够学习到不同角度和样本变化下的特征,从而提高模型的泛化能力。
3 迁移学习和DenseNet模型
3.1 迁移学习
迁移学习是一种有效的机器学习方法[10],可以利用预训练的模型在新任务上进行训练。在植物叶片病虫害分类任务中,选择使用迁移学习的原因是该任务与其他相关的图像识别任务存在相似的特征。
植物叶片病虫害分类任务的核心目标是对不同类型的叶片病虫害进行准确分类。这些病虫害可能表现出特定的形状、颜色、纹理等特征,这与其他图像识别任务中的对象分类任务具有相似性。以预训练的Densenet模型作为基础模型,可以利用其在大规模图像数据集上训练的能力,从中学习到普遍的特征表示。
3.2 DenseNet模型
在计算机视觉领域,卷积神经网络(Convolutional Neural Networks,CNN)已经成为最主流的方法,比如最近的GoogLenet、VGG-19、Incepetion等模型[11]。CNN史上的一个里程碑事件是ResNet模型的出现。ResNet可以训练出更深的CNN模型,从而实现更高的准确度。另一个在CNN领域具有重大影响的里程碑事件是DenseNet模型的出现。DenseNet(Densely connected convolutional Networks)是一种能够训练出更加密集连接的CNN模型[12],它通过引入密集连接块(dense block)的结构,进一步推动了模型深度的增加,从而实现了更高的准确度。
DenseNet的核心思想[13]是在每一层中将前面所有层的特征图(feature map)连接到当前层的输入,这样每一层都能直接访问之前层的输出。这种密集连接的设计带来了以下几个重要优势。(1)参数和特征重用。由于每一层都能直接访问前面层的输出,DenseNet能够充分利用之前层的信息,并将其传递给后续层,从而实现参数和特征的重用。这使模型更加高效,并且可以使用相对较少的参数来实现更深的网络结构。(2)梯度传播和特征传递。密集连接的结构使梯度能够更快地传播,有助于解决梯度消失或梯度爆炸的问题。同时,前面层的特征也能够直接传递给后续层,这有助于缓解信息丢失的问题,提高特征的传递效率。(3)特征融合和多尺度表示。DenseNet中密集连接块的设计使网络能够同时学习不同层级的特征表示,从而实现多尺度的特征融合。这有助于模型捕捉不同尺度下的图像特征,提高模型的表达能力和泛化能力。
对于一个n层的网络,DenseNet共包含个连接(图3),相比ResNet,这是一种密集连接。而且DenseNet是直接连接来自不同层的特征图,这可以实现特征重用,提升效率。

图3 DenseNet网络的密集连接机制
用公式表示,传统的网络在n层的输出为
在DenseNet中,会连接前面所有层作为输入,即
其中,上面的Hn( )代表是非线性转化函数(non-liear transformation),它是一个组合操作,其中可能包括一系列的BN(Batch Normalization)、ReLU、Pooling及Conv操作。这里n层与n-1层之间可能实际上包含多个卷积层。
4 实验方法
4.1 实验设置
所有试验均在Ubuntu 20.04 LTS 64位系统环境下运行,模型采用深度学习开源框架Pytorch1.10.1和Python3.8.0 搭建。计算机搭载的处理器为 Intel Core i7-12700H @八核,运行内存16 GB,GPU为RTX 3060。输入模型的图像尺寸大小为224×224像素。受硬件条件的约束,批处理大小(batch-size)设置为16,模型迭代次数15 epoch,初始学习率设置为0.001。使用默认的更新策略。进行微调参数后,继续训练,模型迭代次数15 epoch。本文采用准确率(accuracy)、精确率(precision)、召回率(recall)、准确率与召回率加权调和平均值—F1值(F1-score)来衡量模型的分类性能。以上评价指标数值越高,模型性能越好。
4.2 模型设置
以在大规模图像数据集上训练得到的预训练的DenseNet-169模型作为基础模型,并在植物叶片病虫害分类任务上进行微调,可以加速模型的训练过程,并且由于模型已经学习到了一些与图像识别任务相关的特征,可以提高模型在植物叶片病虫害分类中的性能。
DenseNet-169是一种深度卷积神经网络模型[14],其结构可以分为以下几个主要部分。(1)输入层。接收输入图像的张量,通常是具有固定大小的图像。(2)预处理层。对输入图像进行预处理操作,如归一化、缩放等,以便适应网络模型的输入要求。(3)初始卷积层。由一系列卷积操作组成,用于对输入图像进行初步特征提取。在DenseNet-169中,初始卷积层通常包括一个7×7的卷积核,用于捕捉更大范围的特征。(4)密集块(dense block)。DenseNet-169由四个密集块组成,每个密集块由多个卷积层组成,且每个卷积层的输入都来自于前面所有层的级联连接。这种密集连接的结构使特征可以在网络中充分传播和重用,有助于提取更丰富的特征表示。(5)过渡层(transition layer)。在相邻的两个密集块之间,DenseNet-169引入了过渡层。过渡层通过使用1×1卷积核和2×2的平均池化操作,将特征图的通道数减少,并将空间维度进行下采样。这有助于控制特征图的大小和参数数量,同时降低计算复杂度。(6)全局平均池化层。在最后一个密集块之后,通常会添加一个全局平均池化层,将特征图的高度和宽度降低为1,同时保留每个通道的平均值。这有助于进一步减少参数数量,并提取整个图像的全局特征。(7)全连接层。在全局平均池化层之后,可以添加一个或多个全连接层,用于将提取到的特征映射到分类输出空间。通常,最后一层使用softmax激活函数,以得到每个类别的概率预测。
4.3 微调参数
预训练模型已经在大规模数据集上学习到了有效的特征表示,只需要针对特定任务进行微调。首先解冻靠近输出层的最后30层,并允许它们在叶病分类数据集上进行训练,而不是使用预先训练的权重。通过解冻这些层,模型能够展示与叶病分类的特定任务相关的更具体和细粒度的特征。网络中较早的层更接近输入,已经从大型数据集的预训练中学习了一般特征。
为了优化参数微调过程,需仔细调整学习率等优化参数。通常情况下,微调过程需要使用较小的学习率,以确保模型在特定任务上收敛得更好。可以选择使用适当的优化器Adam优化器[15],并设置较小的学习率0.000 1来进行微调。这有助于在微调过程中更精确地调整模型参数,以使其适应叶病分类数据集。
解冻更多图层需要仔细考虑,因为可能会增加过度拟合的风险,尤其是在数据集大小有限的情况下。使用正则化技术(如dropout或权重衰减)来缓解过度拟合[16],并确保模型很好地推广到看不见的数据。
5 结果与分析
5.1 模型训练过程分析
在初始的几个epoch中,训练集和验证集的损失和准确率都有明显的改善,如图4、图5所示,这表明模型在学习数据集的特征和模式。随着训练的进行,训练集和验证集的损失逐渐减小,模型逐渐收敛到更好的解决方案。训练集和验证集的准确率也逐渐提高,表明模型在分类任务上的性能在不断提升。验证集的准确率在前几个epoch之后基本稳定,这可能表示模型已经趋于收敛。

图4 模型损失函数曲线
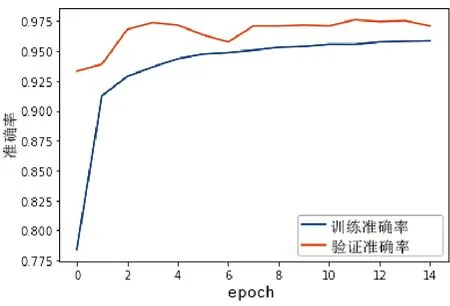
图5 模型准确率曲线
再对模型进行了15个epoch的训练后,执行额外的操作来进一步提高模型的性能。这些操作包括:解冻靠近输出层的层,继续训练过程,从上一个训练中断的点开始,增加了几个时期。这使模型能够进一步完善其学习的表示,并专门为本研究的数据集优化其参数。应用学习率计划或学习率降低策略来控制持续训练阶段的学习率。这有助于微调模型的权重,而无需进行剧烈更新,并确保更稳定的收敛。
在上一次训练结束的轮数开始继续训练,如图6所示,模型在第25个epoch时触发了早停。这意味着在前面的epoch中,验证集的性能指标没有明显提升,并且模型可能已经达到了较好的泛化能力。

图6 微调参数后模型训练周期图
在最初的15个epoch中,训练集上的验证准确率为95.1%,损失函数值为0.147。微调参数后,训练集上的验证准确率提高到98.2%,损失函数值下降到0.060 1。经过微调后模型的性能有所提高,训练集上的准确率更高,损失更小。
5.2 模型评估分析
如表1和图7所示,在测试集中,不同植物名称的精确率表现良好,大多数类别的精确率超过了95%甚至接近或达到100%。这意味着模型在预测这些植物类别时能够准确地识别出大部分正样本。召回率也表现较好,大部分类别的召回率超过了95%。召回率衡量了模型对于正样本的检测能力,高召回率意味着模型能够较好地找到正样本。F1分数综合了精确率和召回率的表现。绝大多数类别的F1分数都在95%以上,说明模型在植物分类任务中具有较好的综合性能。每个植物类别的样本数(support/count)也给出了测试集中每个类别的样本数量。这些数字可以用于了解不同类别之间的数据分布情况。

表1 对不同类别植物叶片病虫害分类模型评估
综上所述,模型在测试集上取得了较高的分类性能,对于多个植物类别的识别都表现出很好的准确率、召回率和F1分数。这说明模型经过训练和微调后在植物分类任务上取得了较好的结果。
6 讨论
本研究提出了一个基于Densenet的高效准确的植物病虫害识别模型。通过使用迁移学习和微调参数,以预训练的DenseNet模型作为基础模型,并在特定植物病害数据集上对模型进行进一步训练。该模型经过两个训练阶段,最终的识别准确率达到96%。
通过利用从大规模预训练数据集中学习的知识,该模型能够捕获与植物病害相关的一般和信息特征。微调过程允许模型适应并学习与手头的分类任务相关的更具体和更细微的特征。结果取得较高的识别精度,表明了所提方法的有效性。
使用迁移学习和预训练模型有几个优点。它减少了对大量标记训练数据的需求,因为预训练模型已经拥有有价值的学习表征。这使模型即使在有限的训练样本下也能获得良好的性能。同时微调过程允许我们根据模型数据集中植物病害的特定特征定制其学习特征,增强其判别能力。
然而,本研究也存在一些局限性。首先,模型的性能很大程度上依赖训练数据集的质量和多样性。虽然叶病分类数据集是多种常见植物叶片组成的,但仍有一些罕见或新颖的植物病害病例未被包括在内,这可能会影响模型推广到未见数据的能力。其次,对预训练模型进行微调需要仔细考虑要解冻的层数和正则化技术,以减轻过拟合风险。可以进行进一步的优化和实验,以探索适合特定任务的最佳微调策略。
尽管存在这些限制,本研究显示了在植物疾病诊断和识别中使用预训练模型和迁移学习的潜力。所获得的高识别精度验证了所提方法的有效性及其在实际应用中的潜力。在未来的工作中,可以扩展数据集,探索不同的预训练模型,并进一步优化微调过程,以提高模型的性能和泛化能力。
猜你喜欢
今日农业(2021年7期)2021-11-27
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2021年12期)2021-10-14
中老年保健(2021年5期)2021-08-24
电子制作(2019年11期)2019-07-04
电线电缆(2018年2期)2018-05-19
北京航空航天大学学报(2018年1期)2018-04-20
家庭影院技术(2017年10期)2017-11-23
电视技术(2014年19期)2014-03-11
教育科学论坛(2014年8期)2014-03-01
