
非侵入式负荷动态识别方法的研究及工程应用
2023-11-02 08:17:08刘春蕾庞鹏飞石纹赫孔令号
电气工程学报 2023年3期
刘春蕾 庞鹏飞 石纹赫 孔令号 黄 洵 戚 军
(1.国网河北省电力有限公司保定供电分公司 保定 071000;2.浙江工业大学信息工程学院 杭州 310000)
1 引言
近年来,负荷监测作为智能用电技术体系的重要组成部分[1],实现了电力公司与居民用户之间的双向互动机制,是目前各国研究的热点[2]。负荷监测技术通过对综合用电数据进行深度挖掘,不仅能够为电网侧提供负荷构成信息,为电网的优化调度提供助力,还能够反馈于用户,解析用户电能消费结构[3],有效提高电能的利用率和峰谷电价引导下的削峰填谷积极性。
目前负荷监测可大致分为侵入式监测(Intrusive load monitoring, ILM)和非侵入式监测(Non-intrusive load monitoring, NILM)。ILM 需要在设备上安装监测传感器,虽然监测精度高且无需复杂的识别算法,但其硬件安装成本高,且在更加注重个人隐私的信息化时代,用户接受程度也较低[4-6]。与之相对,由HART 于20 世纪80 年代首先提出的NILM 技术只需要在配电进线处安装监测设备,对监测数据进行负荷分解,即可实现对各设备的监测。该方法硬件成本低,用户接受程度高,在工业设备监测以及常用居民负荷监测等领域得到了广泛的应用[7-11]。文献[8-9]基于低频电力数据,采用稳态功率信息构建负荷识别特征,特征提取速度快,但是实际工程应用中容易出现特征重叠问题导致识别准确率降低。为提高复杂场景下的识别正确率,可采用包含更多信息量的负荷特征。文献[10]基于电流时域波形和频域谐波信息,采用主成分分析法降维构建负荷特征。文献[11]则采用差异分析方法构建易于区分的融合特征作为负荷特征。这两种方法都能提高负荷识别准确率,但与此同时负荷识别的速度也明显降低,在实际工程应用中影响负荷识别的实时性。
本文基于对各类负荷特征的对比分析,综合考虑负荷特征提取代价及识别效果构建双层特征组,采用基于支持向量机(Support vector machine,SVM)多分类算法的负荷动态识别方法按需识别负荷类型。最后通过Matlab 仿真及实际工程应用对所提NILM 动态识别方法的性能进行测试验证。
2 负荷特征分析
负荷特征作为负荷识别的依据,直接影响着NILM 识别算法的识别准确度及速度。表1[12-16]总结了实际工程中较为常用的负荷特征的提取代价:采样频率是线路电压、电流测量装置的采样频率;监测窗口宽度是提取负荷特征所需的测量数据长度;计算复杂度表示负荷特征提取算法的复杂程度;负荷特征存储量是记录负荷特征所需要的硬件空间。

表1 负荷特征综合分析表
从表1 可以看出,稳态特征中除电流谐波特征外,稳态功率特征(P、Q)以及电压-电流轨迹特征对采样频率要求较低,监测窗口宽度普遍较小,电压-电流轨迹及电流谐波特征的计算复杂度和负荷特征存储量明显高于稳态功率特征;暂态特征的采样频率普遍较高,监测宽度窗口宽度取决于具体的负荷类型,一般不超过100 s,除S 变换特征外,其余暂态电流特征计算复杂度都较低且负荷特征存储量较小;时间特征的采样频率和计算复杂度较低且负荷特征存储量较小,但所需监测窗口宽度往往较大。在实际工程应用中,时间特征在负荷停止运行前往往无法识别负荷类型,实时性较差;稳态功率特征容易出现特征重叠问题,通常与暂态特征结合使用。这种结合方法要求NILM 识别方法采用更多的特征或通过复杂的特征融合方法构造新特征,从而导致特征提取代价较高以及实时性较差。
综合考虑工程应用中对识别准确率及速度的要求,本文所提负荷动态识别方法包含两层特征组,如表2 所示。负荷识别时,由简入繁,动态选用负荷特征,首先选用第一层特征组,针对部分无法用第一层特征组区分的相似负荷,进一步采用第二层特征组进行区分。每一层特征组中的多类负荷特征类型,根据负荷特征提取代价进一步区分优先级,根据实际应用场景选取其中的一类或多类负荷特征。

表2 分层特征组
3 负荷动态识别方法
基于上述负荷特征分层思想,本文所设计的负荷动态识别方法由分类模型训练和在线负荷识别两部分构成,详细流程如图1 所示。其中,分类模型训练基于已标定负荷类型的训练/测试数据集,提取各层特征进行模型训练和检验,形成分层的负荷识别模型供在线负荷识别使用;在线负荷识别部分实时采集电压电流数据进行投切事件监测,然后按需提取特征输入至对应层的负荷识别模型进行判断,最后输出负荷类型识别结果。针对流程图中的关键步骤,下文将详细展开介绍。
3.1 分类模型训练
步骤1:获取负荷投切事件数据。针对于待识别的负荷群,试运行一段时间并记录共m次投切事件ETp(p=1,2,3,…,m)的暂态电压vp(n)、暂态电流ip(n),然后根据实际负荷投切情况标定ETp的负荷类型并记为yp。
步骤2:设置负荷特征层及准确率阈值δ。首先根据实际工程需求设置识别准确率阈值δ,然后根据表2 所述特征选取优先级并结合实际工程应用场景,确定第一层特征组及第二层特征组所采用的特征。
步骤3:提取第一层负荷特征。根据步骤2 所设置的负荷特征层,结合表1 所述提取方法,提取所有负荷投切事件的第一层特征数据集FL=[FL1…FLp…FLm]T,其中FLp为第p次投切事件的第一层特征向量。
步骤4:训练第一层识别模型。考虑到训练数据集的样本数量较少且负荷类型往往不止两类,采用小样本环境下识别准确率较高的SVM 多分类OAA(One-against-ALL)方法。识别模型的构建步骤如下[17-19]所示。
(1) 针对c种负荷类型,OAA 共需要构建c个SVM 模型。首先训练第一类负荷的SVM 模型,即初始化λ=1。
(2) 基于训练数据集中的负荷类型标记yi以及第一层负荷特征集FL构建负荷特征样本训练集S以及测试集S',其中若ETp为第λ类负荷,则将目标值yp设置为λ,若否则令yp设置为-1。
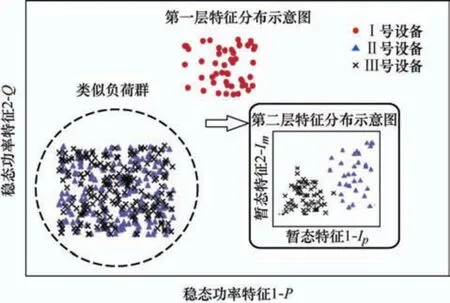
式中,0.5 m (3) 由于负荷特征分类通常不可能是简单线性可分的,因此需要引入SVM 核函数将其映射到高维空间实现线性可分。常用的核函数包括线性核函数、多项式核函数以及径向基函数(Radial basis function,RBF)等,在非线性情况下通常采用性能最优的RBF 核函数,对应核函数表示如下 式中,σ为高斯函数标准方差。构建凸二次规划问题如下 得到最优解α*=()T。 根据最优解计算最优超平面的偏移量 得到分类决策函数 式中,FX为待识别事件的输入特征向量。 (4) 判断λ是否等于c,若否则令λ=λ+1,并返回步骤(2),若是则训练完成,得到分类函数集如式(7)所示,至此第一层负荷特征识别模型构建完成。 步骤5:测试各类型负荷识别准确率ωp1。将由第一层负荷特征向量构成的测试集S'中的特征向量FL代入式(7)并统计各类型负荷识别准确率为 式中,Mp1为第p类负荷事件识别正确次数;Mpt1为第p类负荷事件总识别次数。 步骤6:判断是否为类似负荷群。构建目标值集合A 及B,若ωp1≥δ,则表示第p类负荷事件可通过第一层识别模型直接识别负荷类型,并将yp加入集合A,若否则标记第p类负荷为类似负荷群,并将yp加入集合B,进入步骤7 进行后续处理。 步骤7:提取类似负荷群第二层负荷特征。根据步骤2 所设置的负荷特征层结合表1 所述提取方法,提取所有属于类似负荷群的负荷类型的第二层特征数据集FH=[FH1…FHp…FHk]T,其中FHp为第p次投切事件的第二层特征向量,k为类似负荷群的投切事件总数。 步骤8:与步骤4 类似,训练得到分类函数集如式(9)所示,至此第二层负荷特征识别模型构建完成。 步骤9:测试类似负荷群识别准确率ωp2。与上述步骤5 类似,统计属于类似负荷群的各负荷类型的识别准确率ωp2(p=1,2,3,…,k)。 步骤 10:检验第二层识别模型。若ωp2(p=1,2,3,…,k)均不低于δ,则第二次识别模型检验合格,可在后续在线负荷识别流程中用于识别负荷类型,若否则模型检验不合格重新进入步骤2。 步骤1:监测投切事件。通过测量装置采集总线电压电流曲线,随后进行滤波处理并通过算法分析实时曲线的变化情况,检测是否产生负荷投切事件,若是则提取目标负荷电压电流波形,然后进入后续负荷识别步骤,若否则继续采集监测实时测量数据。 步骤2:提取第一层负荷特征。结合第3.1 节中步骤2 所设置负荷特征层,根据表1 中的计算公式提取负荷特征构建第一层特征向量FX。 步骤3:第一层识别模型识别负荷类型。将第一层特征向量FX输入模型求解得到初步的负荷识别目标值y,即y={fHi(FX)}。 步骤4:判断是否能够直接识别负荷类型。若y∈A,则该负荷类型能够通过第一层识别模型直接识别,转入步骤7,若y∈B 则进入步骤5 进行后续处理。 步骤5:提取第二层负荷特征。结合第3.1 节中步骤2 所设置负荷特征层,根据表1 中的计算公式提取负荷特征构建第二层特征向量FY。 步骤6:第二层识别模型识别负荷类型。将第二特征向量FY代入模型求解,更新负荷识别目标值,即y={fHi(FY)}。 步骤7:输出识别结果。输出目标值y对应的负荷类型至终端显示平台,完成负荷在线识别。 BLUED(Building-level fully-labeled dataset for electricity disaggregation) 数据库是 2012 年ANDERSON 等[20]公开的专门用于负荷识别和暂态事件检测的电力数据库。BLUED 数据库包含多种负荷类型,包括冰箱、计算机、显示器以及电灯等电气设备,数据的采样频率为12 kHz,适用于稳态和暂态负荷特征的分析。 图2 给出了计算机、厨房顶灯、办公室灯等七类负荷的暂态电流波形图。从图2 可以看出,大部分负荷类型的暂态电流波形较为接近,很明显无法用单层特征对所有类型进行很好的区分。故本文选取稳态功率特征P、Q作为第一层特征组,暂态特征Ip及Im作为第二层特征组,对BLUED 数据库中的七类负荷进行动态识别测试。 图2 常用负荷暂态电流示意图 图3 是七类负荷的特征分布图,除餐厅顶灯与后院灯外,其余负荷在第一层特征即P-Q坐标系下即可实现特征分离,将这些负荷标定为易区分负荷;餐厅顶灯与后院灯在P-Q坐标系下存在特征重叠,标定为类似负荷群。对类似负荷群进行第二层特征提取,在Im-Ip坐标系中,餐厅顶灯与后院灯也实现了特征分离,这说明上述分层负荷特征组的选取是合理的。 图3 负荷特征分布示意图 进一步将本文所提动态识别方法与传统的静态识别方法进行对比:识别方法①采用单层稳态功率特征(P、Q);识别方法②采用单层暂态特征(Ip、Im);识别方法③采用动态识别方法(第一层采用单层稳态功率特征(P、Q),第二层单层暂态特征(Ip、Im))。负荷识别正确率如式(8)所示,定义识别时间百分比Tf(%)如下 式中,TN为当前识别策略特征提取计算耗时;T1为识别方法①特征提取计算耗时。 表3 记录了3 种方法识别负荷的准确率和识别时长百分比。从表3 可以看到,对于前五类负荷(易区分负荷),各识别方法的分类效果相近且保持着较高水准,识别方法②的Tf(%)值远高于识别方法①和识别方法③;对于由餐厅顶灯负荷与后院灯负荷构成的类似负荷群,识别方法①无法获得较好的分类效果,其准确率略高于50%,而识别方法②和识别方法③分类效果都保持着较高水准。虽然识别方法③的Tf(%)都略高于识别方法②,但是综合考虑所有负荷类型的识别时长即综合Tf(%),识别方法③显然优于识别方法②。综上,相对于识别方法①和识别方法②,本文所提的动态识别方法③在付出较少时长代价的前提下,总体识别准确率有了明显上升。 表3 三种识别方法的对比 某工矿企业的入户总线上安装了NILM 装置,其中负荷类型识别环节采用上述基于多层特征组的动态识别方法。工业企业重点设备监测平台显示终端如图4 所示,通过实时高频采集工厂进线上的电压和电流数据,并在本地边缘计算后获取投切设备的负荷特征,然后将负荷特征上传到云端服务器作进一步的负荷识别,最后监测显示终端从云端数据库提取负荷识别结果进行统计分析和可视化展示。 图4 终端展示界面 本案例应用的负荷监测背景为:通过对工厂进线数据的监控,准确识别出Ⅰ、Ⅱ及Ⅲ号设备的投切事件。经过前期对工厂设备的负荷特征及提取数据分析发现,三种设备可以在P-Q特征及Im-Ip特征构成的双层特征组下实现完整的特征分离,图5是该工厂其中3 类重点设备的两层负荷特征分布图。由图5 可见,Ⅰ号设备可通过第一层特征识别出来,而Ⅱ号及Ⅲ号设备在第一层特征组P-Q坐标系下出现了特征重叠现象,因此需要对两类设备进行第二层特征提取。在Im-Ip坐标系中,Ⅱ号设备与Ⅲ号设备可以实现特征分离,至此实现了所有负荷的分类,最终确定两层负荷特征组的选取与第4.1 节相同。 图5 特征分布对比示意图 分别采用三种识别方法进行一星期的工程实测,记录其实际工程识别正确率如表4 所示。进一步根据实测数据构建模拟设备频繁投切运行场景,将平均识别时长、系统监测时延记录在表4 中,平均识别时长为100 次不同负荷投切事件单次识别时长的平均值;系统监测时延为不同负荷频繁投切时的累积识别时长,即完成所有投切负荷类型识别的时刻与最后一次投切事件发生时刻之间的时间差。 表4 工程案例中负荷识别结果对比 结合表4 可见,识别方法①识别速度快,平均识别时长及系统监测时延均较低,且负荷投切频繁时不会出现时延累积现象,但识别正确率过低无法满足工程准确率要求;识别方法②识别正确率为三种方法最高,但平均识别时长过长,并且在负荷投切频繁时,系统监测时延过长且在不断累积,无法满足工程实时性要求;识别方法③则综合了识别方法①及识别方法②的优点,识别准确率处于较高水准的同时平均识别时长只是略微高于识别方法①,并且在负荷投切频繁时,系统监测时延较低且不会累积,同时满足了工程应用的准确率及实时性要求。工程案例验证了动态识别方法在实际工程应用中能够较好地区分各类型负荷并兼顾识别速度的优异性,适用于负荷相似且负荷事件频发的实际应用场景。 针对单层识别方法的局限性,提出基于负荷特征分层和SVM 多分类算法的NILM 动态识别方法。首先针对负荷类型的各种负荷特征进行提取分析,构建多层特征组从而以尽可能小的特征提取代价实现所有负荷类型的特征分离,随后基于SVM 多分类算法实现对负荷类型的动态识别。 (1) 通过BLUED 数据库的仿真及实际工程应用验证了本文所提方法的识别准确度。针对于差别较大的简单负荷群,分层动态特征组的识别精度并不低于采用复杂特征的单层静态特征组;针对于相似负荷群,分层动态特征组的识别精度仅低于采用复杂特征的单层静态特征组2.6%,高于采用简单特征的单层静态特征组163.9%。 (2) 分层动态特征组有效地克服了单层静态特征组在复杂负荷环境下无法兼顾识别速度与精度的问题,在实际工程应用下,分层动态特征组的识别识别速度高于单层静态特征组238.96%,并且在实际工程应用中不会出现识别延时累积问题,具有良好的实时性。 综上所述,动态识别方法准确性高于传统的单层识别方法,同时在略微增加识别代价的情况下能够大幅度提高识别速度,在实际工程应用中具有良好的实时性,非常适合负荷类型相似且投切频繁的应用场合。3.2 在线负荷识别
4 仿真与工程验证
4.1 BLUED 数据库仿真分析



4.2 工程案例验证


5 结论
猜你喜欢
大电机技术(2021年5期)2021-11-04 08:58:28
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
能源工程(2020年6期)2021-01-26 00:55:22
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子制作(2018年14期)2018-08-21 01:38:28
电子测试(2017年23期)2017-04-04 05:07:02
电测与仪表(2016年9期)2016-04-12 00:29:50
电测与仪表(2015年9期)2015-04-09 11:59:30
