
基于混合分割的图像边缘提取算法研究
2023-11-02 07:34叶勇健朱荣钊
安阳师范学院学报 2023年5期
叶勇健,朱荣钊
(1.厦门华天涉外职业技术学院 信息技术学院,福建 厦门 361102;2. 湖北大学 计算机与信息工程学院,湖北 武汉 430062)
0 引言
随着移动终端设备的快速发展,消费者对图像的清晰度要求越来越高,图像处理技术成为了各大品牌厂商竞争的核心。随着信息技术的快速发展,在同等硬件基础上,图像语义分割的性能得到了很大程度的提升。然而,随着硬件设备的更新换代,图像的像素密度更高,图像的表现力也更加细腻,这对图形语义分割算法的性能要求也越来越高。如在室外取景拍摄,受到气候、光照等条件的影响,终端设备也需要对图像进行精细化处理。采用传统的图像处理方式成本过高,同时也无法满足终端设备用户的使用愿望。迁移学习是机器学习的一种,能够有效降低传统机器学习的基础成本。研究在迁移学习的基础上提出了基于Deeplab空洞卷积的混合分割优化算法,并将其应用于具体的图像分割中,期待对提升图像分割的性能提供一定的参考。
1 迁移学习与图像语义分割
1.1 迁移学习
迁移学习是在深度学习中需要多次训练的深层神经网络,训练学习成本高。迁移学习的目的是在一个任务上学习一个模型,以此来解决相关的其他任务,通过将结果知识迁移到类似场景,从而大大降低了机器学习的基础成本[1-3]。随着迁移学习理论的不断成熟,其在医疗、行为预测、智能汽车等领域得到了广泛的应用。不妨定义源观测数据样本为{(Dsi,Tsi)|i=1,…,mS},目标观测数据样本为{(DTi,TTi)|i=1,…,mT},mS和mT分别为2个样本集所包含的数量。fTj(j=1,…,mT)为目标领域学习的性能[4]。
1.2 生成对抗网络(GAN)
生成对抗网络由生成模型G和判别模型D所组成,生成对抗结构原理如图1所示。

图1 生成对抗结构原理

图2 空洞卷积金字塔
由图1可知,生成对抗网络样本数据集包括模拟样本数据和真实样本数据。模拟噪声pz(Z)经过生成器G产生模拟样本G(z),Pdadt(x)为真实样本数据,Dx为识别器对真实数据的识别成功率[5]。由二元极大极小博弈理论可得
+Ez-p(z)[log(1-D(G(x)))]
(1)
1.3 Deeplab网络
语义分割是在像素级别上进行分类,其发展与Deeplab系列语义分割网络密不可分。Deeplab是谷歌公司开源的图像语义分割与边缘提取算法,是在全卷积网络FCN基础上发展而来的,和FCN相比图像像素的精细化程度大大提高。具体而言,其包括两个方面的内容[6]:
1)空洞卷积率越高,其能够获得的样本数量输入信息越大;
2)同等条件下,由于Deeplab网络在图像特征提取中采用了条件随机场,这使得图像分割精度大大提升。
2 空洞卷积识别混合语义分割算法
为最大化抓取图片上下文信息,传统卷积神经网络采用连续池化操作和卷积操作。连续池化操作和卷积操作将导致图像识别精度下降,进而造成数据层次上的语义分割性能下降[7-9]。
Deeplab网络是将空洞卷积应用到语义划分中,采用孔卷积法进行语义划分。该方法可以有效获取图像深层特征,不会影响图像的识别精度。考虑到识别网络不仅要区分目标区域的输入图片,同时还要确保图像的分辨率,因此研究提出一种新的域鉴别网络方法。
由于构建传统的识别网络常常采用五阶长度为二的卷积结构,因此会导致图像特征提取的过程中所提取的特征在空间上的损失,进而影响图像分割效果。为提升图像分割效果,利用多个平行叠加的空洞卷积层来获取更多背景信息。以Deeplab-v2作为分割网络架构,采用识别网络识别图像源域,并利用分割网络和识别网络进行对抗性训练,有效减少源域和目标区域之间的差异。
2.1 算法整体框架
图像边缘提取算法以GAN作为基准网络,并在此基础上利用DeepLab-v2架构对ImageNet数据集进行预训练。选择ResNet-101网络,根据经验剔除末位分层。为缩小图像特征图,对卷积长度进行调整,特征图为原始图像的1/8。进行反卷积操作,确保输出层与输入层的特征尺寸相匹配。另外,在算法框架设计时设计了3个不相交的空洞卷积以降低训练误差。算法框架如图3所示。
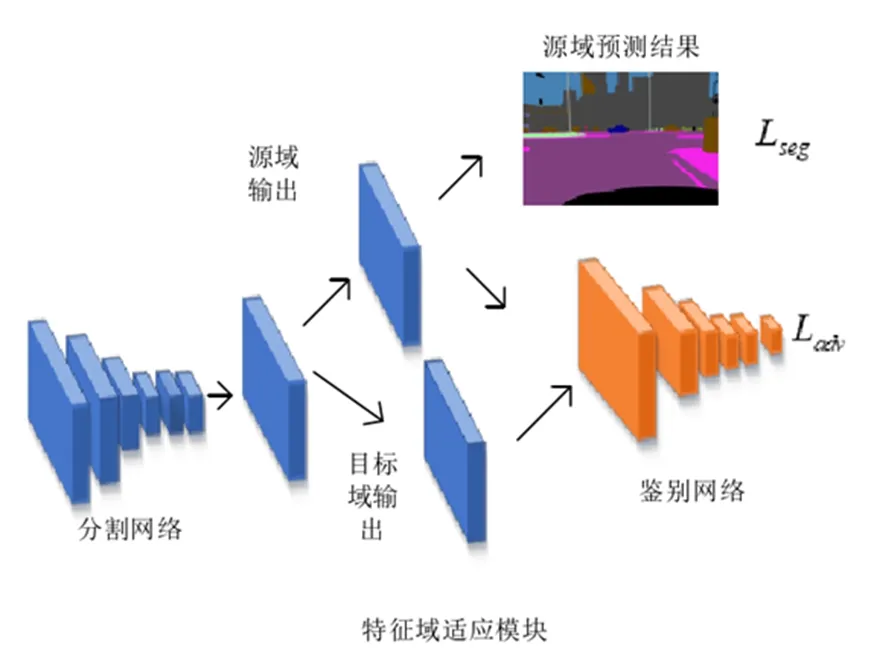
图3 算法框架
2.2 空洞卷积识别器与迁移图像混合语义分割
2.2.1 空洞卷积
由于深度卷积神经网络进行连续卷积与池化操作,使得输出图像的分辨率降低进而影响到图像语义划分。空洞卷积避免了连续卷积与池化操作,它被广泛应用于图像边缘提取中[10-11]。不妨设f为二维信号,g[i]为输出信号,h[l]为卷积核,那么
(2)
式中:i为坐标信息,r为空洞卷积率。
空洞卷积率r影响感受野,图4为不同r的感受野差异。
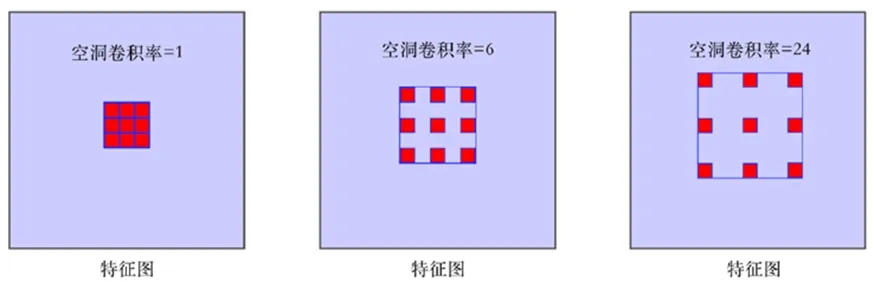
图4 不同的感受野差异
由图4可知,增加空洞卷积率能够增强卷积核感受野的量级。设卷积核自身大小为k,那么卷积核尺寸o为
o=k+(k-1)(r-1)
(3)
由此可见,通过改变空洞卷积率r能够在不增加运算复杂率的情况下增强了感受野。
2.2.2 空洞卷积识别器
采用空洞卷积来构造识别器,所构造的识别器第1级是二阶的常规卷积,其输出图像的解析度降低到1/8。第4层次是空洞卷积率为1,3,6,步数为1的空穴卷积平行叠加,这一层次可以获得更多的空间数据,而不会影响到系统的输入精度;与常规 ASPP的层叠法相比[12]增加了运算,减少了网络参数,在生成网络和最终输出中能够达到1/16的精度。图5为识别器构造流程,其详细参数如表1所示。

图5 识别器构造流程
2.2.3 生成对抗学习模型
研究提出的图像边缘提取算法由识别器网络D和分割网络G构成,将通过ImageNet进行预训练的Deeplab-v2作为分割网络。G损失函数为:
(4)
式中:h、w、c分别代表图片的height、wide和分类数量,YShwc为源标签。
定义生成对抗网络损失函数为:
(5)
混合分割损失函数为:
L(IS,It)=Lseg(IS)+λadvLadv(It)
(6)
(6)式中:λadv是作用上述两损失函数的比率。
定义混合分割训练目标为:
(7)
那么识别网络的损失函数为:
+zlog(D(P)hw1)
(8)
识别网络目标为:
(9)
明确识别网络目标的函数后,定义原始噪声源为:
x=G(z)⟹z=G-1(x)⟹dz=(G-1)′(x)dx
(10)
将其代入式(9),化简整理可得,
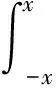

(11)
求目标函数关于D的最大值:
(12)
其最优解表达式:
(13)
此时求解G的最优:
(14)
式中:KL代表拟合和真实分布的差异。
当KL=0时,差异消除,生成网络的最小值为-log4,即当鉴别网络达到最优时,GAN无限接近-log4。同时通过不断调整识别网络参数使得识别网络损失函数达到无穷小,从而达成准确判断的目标。
3 实验结果与分析
3.1 实验配置
实验使用的电脑GPU为P40,具体软硬件配置如表2所示。

表2 算法运行环境
实验选择Adam为优化器,最初学习率设置为3.5e-5,数据集为GTA5和SYNTHIA,其中GTA5用于模型训练,SYNTHIA用于模型测试。GTA5>Cityscapes和SYNTHIA>Cityscapes作为重点验证对象。Cityscapes图片公开数据集主要是针对城市场景中的街道,图片来源于不同国家、不同城市取景,其中像素级别较高的图片有5 000多张。训练数量均为10个,λadv设定成0.01。
3.2 评价指标
像素精度和平均交并比(mIoU)是图像分割性能评价的重要指标,像素精度的评价函数为:
(15)
式中:pij为预测像素符合标签的像素点。
在不同分类图像的语义分割评价中,可以使用平均像素精度来进行对比,其公式为:
(16)
3.3 实验结果与分析
3.3.1 mIoU对比
选取原图、AdapSegNet[4]和DCAN[13],以及所提算法进行对比,表3为数据集GTA5的域适应效果。AdaptSegNet和 DCAN中的试验结果采用所提出的算法进行验证,图6为模型在GTA5中被训练的结果。表4显示从SYNTHIA>Cityscapes的域适应结果,为了公平比较,与其他文献相符合,只选取9种试验结果在表格中列出。

表3 算法性能mIoU对比(GTA5)
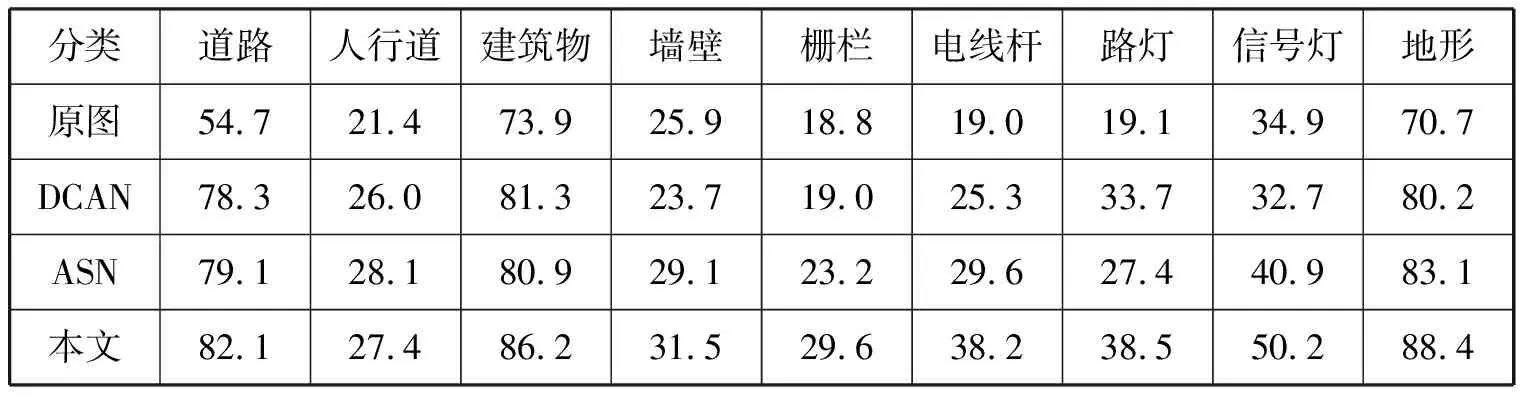
表4 算法性能mIoU对比(SYNTHIA)

图6 可视化效果对比
研究给出了一种新的基于空洞卷积识别的混合语义分割迁移算法,该算法利用空洞卷积来实现多层次背景信息,并在保证像素分辨率的前提下获得多层次的信息,从而提高了混合分割网络和识别网络的收敛性。通过对GTA5和 SYNTHIA 2种合成数据集的验证试验,证明了所提出算法的有效性。GTA5的平均交并率(mIoU)为44.1%,而SYNTHIA(mIoU)则为44.9%。
3.3.2 像素精确度对比
选取原始的Deeplab v2和v3算法作为对比目标,使用单尺度评价办法,同时对比像素精确度和平均交并比,实验结果如表5所示。
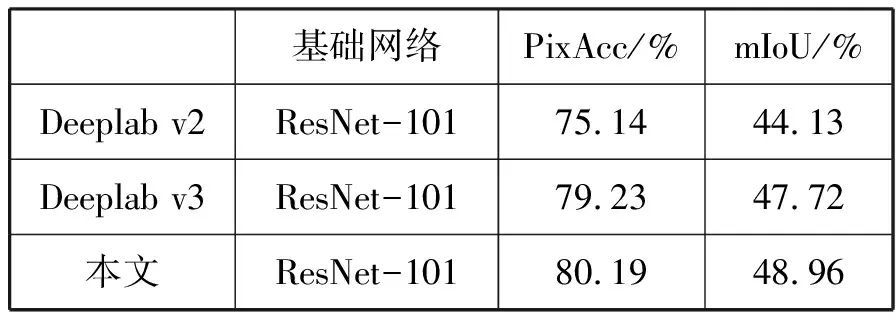
表5 对比结果
由表5可知,本文算法相较于基准的v2框架像素精确度提高了5%左右,比v3提高了0.9%左右,同时平均交并比也大于2个基准算法,即图像分割精度得到了显著提升。
4 结语
针对传统图像边缘提取存在的缺陷,研究提出了基于空洞卷积的区域识别算法。在域识别器中加入空洞卷积以增强域识别系统的识别性能,实现了在没有附加学习条件下对卷积感知范围扩展的目的。将提出的算法应用于GTA5和SYNTHIA数据集,结果表明所提出的空洞卷积区域识别技术与Deeplab网络联合的混合分割算法对图像边缘提取的性能显著提升。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
故事作文·高年级(2017年2期)2017-03-01
现代语文(2016年21期)2016-05-25
新闻传播(2015年20期)2015-07-18
大连民族大学学报(2015年2期)2015-02-27
电视技术(2014年19期)2014-03-11
世界科学(2013年11期)2013-03-11
