
视觉SLAM环境感知技术现状与智能化测绘应用展望
2023-11-02 01:44:34张继贤
测绘学报 2023年10期
张继贤,刘 飞
1. 国家测绘产品质量检验测试中心,北京 100830; 2. 北京建筑大学测绘与城市空间信息学院,北京 102616
SLAM技术作为一种即时汇集未知环境几何、拓扑、语义等信息的前沿科技,逐渐成为一种集导航定位、地图构建、目标检测和场景识别为一体的测绘技术,在自动驾驶、智能机器人、增强现实等领域发挥了重要作用[1-5],逐渐形成了以激光和相机为主的激光SLAM、视觉SLAM两种技术模式,其中前者起步早、发展相对成熟,后者正处于快速发展与完善阶段[6]。通常情况下,人类从外界获得的信息约90%来自眼睛,而视觉SLAM具有类似特点,可以从周边环境中获取海量、冗余纹理等测绘要素,并拥有优异的场景辨别能力,配合其优异的性价比,受到诸多学者的青睐。为此,本文重点围绕视觉SLAM环境感知技术及其在测绘方面的应用进行论述。
视觉SLAM环境感知技术是指搭载视觉传感器的载体在没有环境先验信息的情况下,在运动过程中建立环境模型,同时估计载体运动[7-9],先后经历了传统时代(1986—2004)、算法分析时代(2004—2015)、稳健性-预测性时代(2015至今) 3个发展阶段[10],形成了VO(visual odometry)、VIO(visual-inertial odometry)、SLAM等典型算法模型,涌现出了适用于单目、双目、RGB-D等多种传感器的视觉SLAM环境感知技术路线,促进了视觉SLAM环境感知技术在导航、定位和制图等方面的快速发展,并在自动驾驶、航空摄影测量、地面移动测量、信息提取与场景重建等测绘业务中的得到应用[11-13]。
当今,人类社会正逐渐向智能化时代迈进。我国在《2019年政府工作报告》中将人工智能升级为“智能+”,美国、欧盟等全球38个国家、地区制定了国家层面的人工智能战略和政策,推动了人工智能技术研究不断走向深入。随着大数据、人工智能、物联网等新一代信息技术更新发展,推动智能化测绘技术进步和事业转型升级,已成为测绘业界关心的热门话题[14]。视觉SLAM技术可以实时获取位置、地图、纹理、语义和文字等环境信息,成为环境感知的主要途径之一,但如何通过新一代信息技术的加持,深入探索基于视觉SLAM的环境感知“眼睛”、深度学习算法的“大脑”和众包地理信息的“课堂教学”之间的耦合发展方式,攻克基于视觉SLAM环境感知技术的地理信息环境感知、知识汇聚和智能化应用技术,进一步提高测绘生产力和生产要素的智能化水平,成为当前亟待解决的技术难题。
为了深入探讨基于视觉SLAM环境感知技术支持的智能化测绘发展,需要厘清视觉SLAM环境感知技术概念、理论、技术发展动态,以及当前的测绘应用特点。为此,笔者分析了视觉SLAM环境感知技术的发展现状,探讨了智能化时代的视觉SLAM环境感知技术发展方向,进而提出了智能化时代基于视觉SLAM环境感知技术的智能化测绘应用模式。
1 视觉SLAM环境感知技术研究进展
经过30多年的发展,视觉SLAM环境感知技术的理论框架已经逐渐清晰,包括前端、后端、回环检测和制图4个主要的技术环节。前端的任务是估算相邻图像采集时相机的运动和计算局部地图;后端主要是基于回环检测信息对图像位姿和地图信息进行优化;回环检测则是根据图像信息识别已经出现的场景或位置,如果检测到回环,然后把信息提供给后端进行处理;制图环节主要根据估计的轨迹,建立对应的地图[7]。近年来,随着4个主要环节技术的不断发展变化,逐渐形成了以特征点法SLAM、直接法SLAM、视觉指纹库SLAM、语义SLAM和类脑SLAM等为主体的视觉SLAM技术框架和算法模型,并在智慧交通、场景测绘、防灾减灾、虚拟(增强)现实和智慧医疗等领域开展了产业化应用探索。表1列举了30多年来典型的实时视觉SLAM环境感知算法模型。

表1 典型视觉SLAM环境感知算法模型
1.1 特征点法视觉SLAM
特征点法视觉SLAM技术是建立在图像特征信息处理基础上,基于同名像点之间的最小欧氏距离或者像平面重投影误差(reprojection error)最小化原理进行估算相邻图像间相机的运动、定位信息和构建局部地图的技术[7,15],是视觉SLAM发展较早的一种方法。文献[16]首次实现了基于滤波算法的实时SLAM技术,文献[17]发展了基于非线性优化的多线程并行处理PTAM(parallel tracking and mapping)算法。文献[18]提出S-PTAM(stereo PTAM)算法,将姿态估计与地图构建等并行处理。文献[19]提出ORB-SLAM算法,并经过ORB-SLAM2[3]和ORB-SLAM3[20]算法的完善和提升,发展成了一套适用单目、双目和RGB-D相机,且可实时处理的特征点法视觉SLAM技术框架,在精度方面,ORB-SLAM2算法可以实现百米距离内优于1%的相对定位精度和0.21°的姿态测量精度[3]。滤波和非线性优化是早期两种不同后端处理方式的技术框架,前者计算效率高,后者计算精度高,目前二者逐渐朝着相向的方向发展[21-22]。随着S-PTAM、ORB-SLAM、ORB-SLAM2和ORB-SLAM3等特征点法典型模型的提出,特征点法视觉SLAM的技术框架基本确定,其中ORB-SLAM系列凭借支持多种传感器、优异的计算性能和精度、 有效的回环检测算法和并行计算等特点,成为特征点法视觉SLAM的基础参考,图1展示了特征点法视觉SLAM的技术框架[3,19-20,23]。

图1 特征点法视觉SLAM技术框架Fig.1 The technical framework of feature-based visual SLAM
特征点法视觉SLAM技术是多种方法中研究时间较久,较为成熟的方案之一,美国“机遇号”“勇气号”和“好奇号”火星探测车,以及中国的“月兔号”月球车采用光束法平差(bundle adjustment,BA)方法进行着陆过程中的位置和姿态解算,支撑了探测车安全避障与路径规划所需的基础地图制作[33],而BA方法也是视觉SLAM位姿估计和图优化的重要方法之一。文献[34—35]实现了基于无人机视觉SLAM技术的DOM(数字正射影像)、DSM(数字表面模型)和DEM(数字高程模型)等测绘产品的实时制作。文献[36]采用单目SLAM技术实时构造不同高度的网格地图,为无人机平台动态选择合适的着陆区域,为交互式路径规划技术提供了支撑。由于受稀疏的纹理环境、复杂的光照和高动态场景影响比较严重,且在特征提取、描述和匹配等方面需要较大的计算资源,特征点法视觉SLAM技术的产业应用受到了一定限制,尤其是构建稠密地图受到影响更甚。
1.2 直接法视觉SLAM
为了降低图像特征处理时间和计算资源的消耗,直接法视觉SLAM技术应运而生。直接法视觉定位技术假设两帧图像中的匹配像素的灰度值不变,构建光度误差函数,基于图像间光度误差(photometric error)最小化原理进行位姿变化计算。过程中仅需特征提取,无须特征描述与匹配[37]。相比于特征点法只能构建稀疏点云地图(构建半稠密或稠密需要采取其他技巧),直接法可以利用图像上全部像素信息,具备构建半稠密和稠密地图的能力,在纹理稀疏场景具有一定优势。
直接法视觉SLAM是建立在图像亮度一致性假设和光流法基础上发展起来的。文献[15,24]提出了完整的直接法SLAM框架DTAM(dense tracking and mapping),通过稠密、亚像素和精确多视立体重建等进行轨迹跟踪和三维模型重建。LSD-SLAM(large scale direct SLAM)的问世,成为第一个大尺度直接法单目视觉SLAM方法[25,38],利用图像中像素梯度显著的区域进行位姿跟踪和深度重构,可以恢复半稠密的三维场景地图,文献[38]将其拓展到双目与大视角相机,实现了手机端的AR应用等其他功能,成为了直接法中最具代表性的技术框架[39]。文献[26]在2013年基于图像中全部像素光度误差和深度误差最小化原理提出了DVO-SLAM(dense visual odometry SLAM)算法框架,定位精度可达0.19 m,成为了基于RGB-D相机进行视觉SLAM技术的基础。作为视觉SLAM的前端技术,DSO(direct sparse odometry)视觉里程计出现和发展,凭借良好的运算速度与跟踪精度,将直接法视觉SLAM技术推向了一个新的高度[40-41]。文献[40]提出了半直接法(semi-direct monocular visual odometry,SVO),利用直接法估计相机运动及特征点位置,又对关键帧影像的路标点进行了优化,该方法可以获得更精确、稳健和高效的结果,也被广泛研究。图2展示了直接法视觉SLAM算法的技术框架,不同于特征点法视觉SLAM技术的是前端和制图两部分内容,其中前端主要基于图像灰度信息进行位姿估计和跟踪,建图部分半稠密和稠密地图是直接法的特色和亮点。
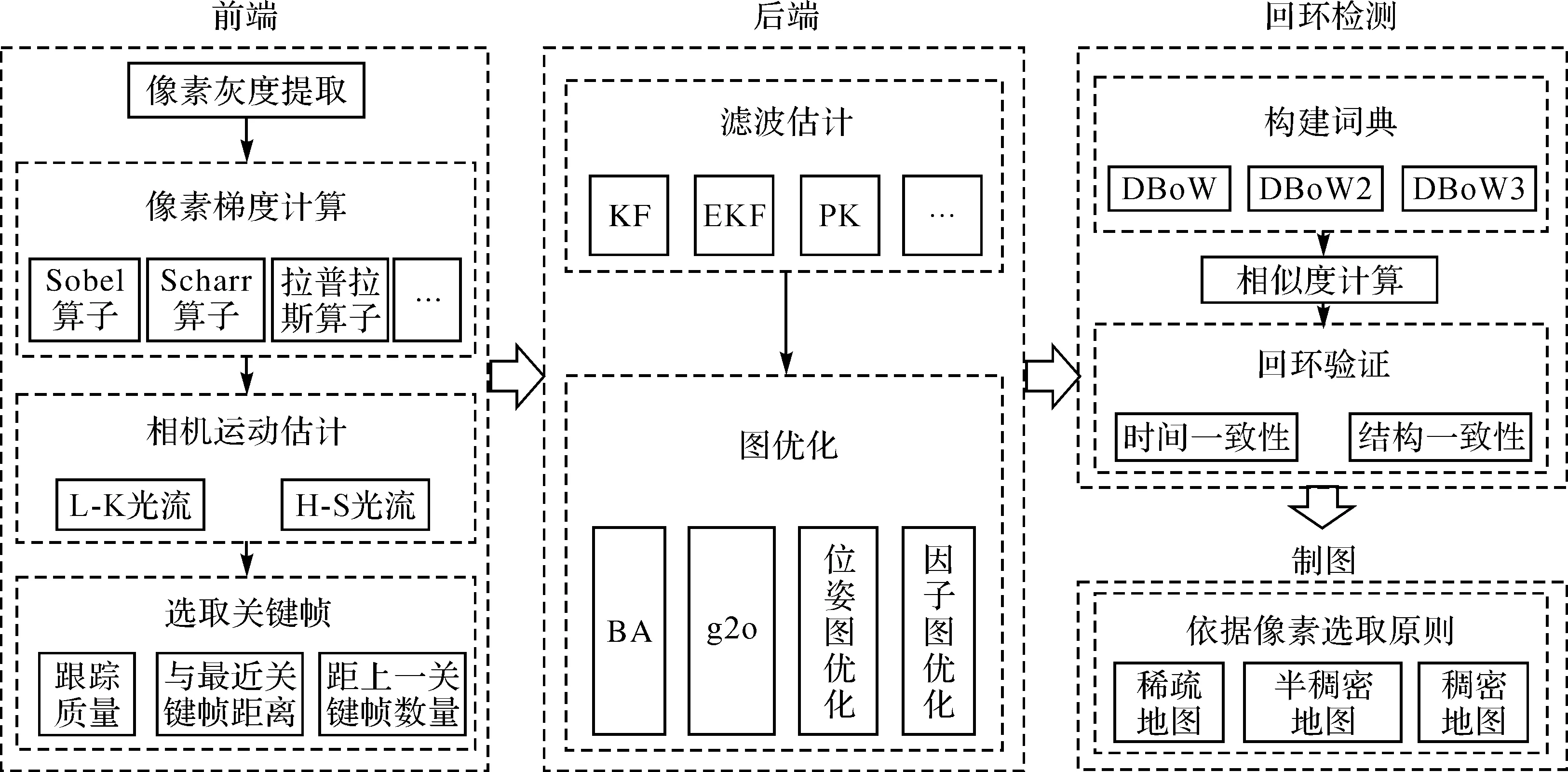
图2 直接法视觉SLAM简要技术框架Fig.2 The brief technical framework of direct-based visual SLAM
直接法视觉SLAM无须计算特征描述子,结合像素梯度计算结果即可完成跟踪和半稠密或稠密地图的构建,对计算资源要求低,消耗时间短,成为近年来应用研究的重点。意大利Leonardo军工公司在无人机军用编队项目中将LSD-SLAM(large-scale direct monocular SLAM)算法与无人机集成,开展障碍物识别工作[42]。地平线公司采用StereoDSO算法进行稠密地图重建、3D环境感知与语义重建,研制了系列适用图像处理的自动驾驶应用芯片,推动了视觉SLAM技术的智能化发展[43]。直接法SLAM由于存在图像灰度一致性假设、较小运动场景适用和图像块相关性计算等问题,在一定程度上限制了直接法SLAM的发展,为此未来需要进一步地攻克上述问题。
1.3 视觉指纹库SLAM
人类可以通过回忆判断曾经到达过的位置,而视觉指纹库SLAM技术赋予了机器人构建地图和场景识别的能力。该技术根据预先构建的物理世界视觉指纹库[44]与当前位置的视觉词袋模型进行匹配,利用场景外观概率识别算法,确定机器人位置,并基于环境信息更新指纹库。
早期基于整体或者局部特征相似度的视觉指纹库SLAM方法虽然得到了大量的研究和尝试,但是在应用方面仍然存在较大的局限性。文献[45]提出了视觉词袋模型(bag of words,BoW),推动了基于BoW和回环检测结合的视觉指纹库SLAM技术得到快速发展。文献[27,46]提出了FAB-MAP算法,其2.0版本的模型在1000 km的路线测试中被证明是一种成功的场景识别算法,在100%的精度下,召回率为6.5%,足以支持一个好的尺度SLAM系统,成为了基于视觉指纹库SLAM方法的城市或者更大尺度场景定位和建模的重要基础。图3展示了简要的技术框架:首先对物理世界进行建模,构建物理世界的视觉指纹库,也即先验地图;其次将感知的图像信息转换成视觉单词;然后计算视觉单词与视觉指纹库的相似度,进而实现位置确定,并将物理世界的信息更新至视觉指纹库中[27]。具有类似原理的视觉场景识别(visual place recognition,VPR)技术也是视觉指纹库SLAM感知技术的一种重要形式,得到了广泛的研究和应用[47-48]。
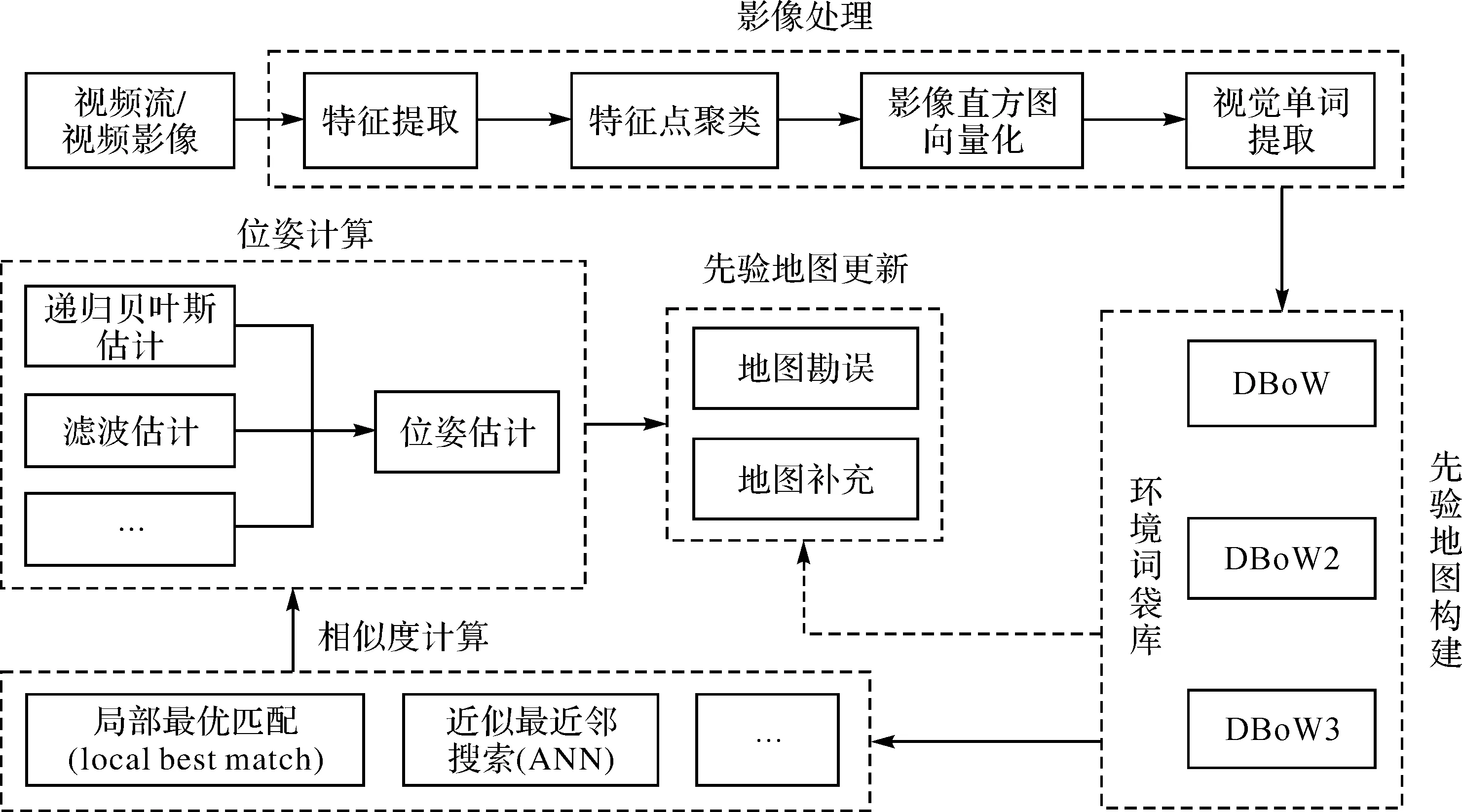
图3 视觉指纹库SLAM技术框架Fig.3 The technical framework of fingerprint-based visual SLAM
视觉指纹库SLAM技术属于一种长时间序列、大空间尺度的视觉SLAM感知方法。文献[49]提出了SeqSLAM(sequence SLAM)算法,即使存在因季节、天气、昼夜变化等因素引起的极端环境变化导致基于特征的算法失败时,该方法仍然能够以100%的准确率和60%的召回率实现轨迹匹配,被认为是最成功的环路闭合检测算法。为了降低计算资源消耗和大型地图的处理,文献[50]提出了Fast-SeqSLAM算法,进一步降低了计算复杂度,提高了计算效率。文献[51]采用混合紧凑型神经网络模型进行视觉位置识别,取得了比SeqSLAM更加优异的结果。文献[52]基于改进的VPR提出更具潜力的适用于自动驾驶需求的大范围场景识别技术。当前视觉指纹库SLAM技术已经解决了物理视觉的数据表达、关联和搜索等问题,被广泛应用于大范围场景的定位和识别,通过与无人机、无人车、无人潜航器等智能化装备结合应用[48],成为推动人工智能技术发展的重要因素。
1.4 语义视觉SLAM
语义视觉SLAM是一种汇聚语义和SLAM技术的具有尺度、拓扑和语义地图构建功能为一体的视觉环境感知技术,可以基于典型的SLAM技术结合物体类别、目标检测、语义分割等语义信息,实现物理环境几何、拓扑和语义信息的获取和地图构建,并用于导航定位等功能,是当前视觉SLAM领域的一个热点研究方向[10,53]。
20世纪中叶美国心理学家E·C·托尔曼提出了认知地图(cognitive map)的概念,拉开了语义地图相关技术研究的序幕,到了70年代语义地图和机器人技术紧密结合起来[54]。然而,语义视觉SLAM则是近年来随着典型SLAM技术发展而来的新技术[55]。按照算法集成模式划分,可以分为两类处理方式,一类是独立的SLAM与目标识别算法结合方式。文献[54]提出空间和语义结合,到文献[29]提出的SLAM++算法,是比较早期整合语义信息进行定位和制图的算法,其中YOLO(you only look once)系列目标识别算法被广泛用于语义视觉SLAM技术研究[56-57]。另一类是将语义与SLAM耦合处理的方式。文献[58]首次将几何、语义和IMU(inertial measurement unit)信息统一到单个优化框架中,用语义信息辅助提高定位精度,取得比单目ORB-SLAM更加优异的结果。按照模型中语义作用划分,可以分为服务于特征选择算法,获得对光照和视角变化稳健性更好的特征点[59];服务于减弱图像中动态物体影响,提高系统的稳健性[60];服务于单目视觉SLAM尺度恢复[61];服务于长时间序列定位[62]和定位精度提高[57]等方面。近年来随着深度学习算法的发展,如文献[30]提出的CNN-SLAM(convolutional neural network SLAM)算法,深度估计误差低于真实值10%,位姿估计精度优于LSD-SLAM方法,推动了深度学习支持的语义视觉SLAM技术成为了研究热点[63]。图4展示了语义视觉SLAM算法的技术框架,包括跟踪与位姿计算、地图构建、回环检测和语义重建等部分[64]。其中前3部分是传统SLAM的技术框架,语义重建部分通常结合本文归纳的两种处理方式实现。

图4 语义视觉SLAM技术框架Fig.4 The technical framework of semantic visual SLAM
语义视觉SLAM环境感知技术目前处于快速发展的阶段,逐渐成为了推动智能装备从被动规划式环境感知技术向主动交互式环境感知技术发展的重要力量。文献[60]利用语义视觉SLAM技术在高动态环境中克服了传统视觉SLAM技术静态环境假设的应用前提,提高了车辆导航时与动态环境的交互性。文献[65]开展了道路环境下的快速3D语义地图构建技术研究,能够识别道路、人行道、墙体、地形、植被、交通标识和汽车等物体。文献[66]利用语义和粒子滤波技术自动构建了城市场景车道级高精度地图,伴随该方向的深入研究,相关成果可以为自动驾驶车辆提供地图支撑。文献[67]详细地描述了语义视觉SLAM环境感知技术在动态环境理解与制图、静态场景理解、与人类和环境的交互,以及机器人改善工作能力等方面的作用,进一步为语义视觉SLAM环境感知技术的应用拓展指明了方向。未来,随着语义视觉SLAM技术在目标检测、数据关联准确性方面的提高,以及复杂算法与计算资源之间矛盾的优化,将会进一步促进该技术在语义地图、场景解译、高精度导航定位等领域的应用。
1.5 类脑视觉SLAM
人类和动物在陌生环境的导航能力,吸引了对类脑导航与空间认知结合的仿生导航技术的不断探索。随着视觉SLAM技术的发展,采用脑科学、人工智能有机结合的类脑视觉SLAM技术开始崭露头角,成为近年来的研究热点。类脑视觉SLAM指智能设备依靠视觉传感器,依赖大脑导航机制,具有自主学习进化、环境感知、认知地图构建于一体的一种新型视觉SLAM技术方法[68]。
自1971年O'Keefe和Dostrovsky发现啮齿动物具有方向细胞和导航细胞,到2014年O'Keefe等人发现“构成大脑定位系统的细胞”获得诺贝尔医学奖。研究发现哺乳动物海马体中的“位置”细胞(place cell)、“网格”细胞(grid cell)、“方向”细胞(head direction cell)、“边界”细胞(boundary vector cell)和“条纹”细胞(band cell)等是哺乳动物感知环境、构建环境认知地图和导航的主要支撑[69]。相关研究人员基于哺乳动物海马体对环境的认知和导航机理,提出了仿生导航概念,类脑视觉SLAM技术逐渐开展起来[70]。文献[31,71—72]利用相关支撑条件,提出RatSLAM算法模型,并不断发展完善,实现了2D郊区地图绘制和超过2周时间的办公环境导航功能,开创了类脑SLAM算法的先河,为众多改进型算法模型的研究奠定了基础。文献[70]基于3D网格细胞和方向细胞提出了适用3D环境下的NeuroSLAM算法,在大型、非结构化、不可预测的环境中推动了脑感知SLAM的进一步发展。另外,基于仿生眼技术的视觉SLAM解决方案,能够在纹理稀疏环境主动搜索丰富的纹理环境,提升视觉SLAM的稳健性,也为类脑视觉SLAM提供一种新的解决方案[73]。图5展示了脑感知SLAM的简要技术框架,主要由4部分内容组成。首先,图像预处理部分基于图像信息进行图像特征或视觉单词提取、位姿估计和路径整合等;其次,物体感知部分进行物体感知和闭环检测,服务于过往场景识别或新场景补充;然后,位置感知部分利用相关定位细胞进行位姿计算;最后,利用物体感知和位置感知的结果构建具备环境拓扑和局部度量的环境地图,也即情景认知地图[32,74]。

图5 类脑视觉SLAM技术框架[74]Fig.5 The technical framework of brain-like visual SLAM[74]
作为新兴的仿生导航技术,类脑视觉SLAM环境感知技术仍然处于发展的初级阶段,众多学者围绕定位、制图等方面进行研究,但是在赋予机器人自主交互能力和算法应用等方面仍然面临着较大的挑战。随着类脑视觉SLAM技术与传感、认知、学习和控制等技术的深度融合,将会赋予下一代机器人智能感知、自我学习与认知、与人类和环境交互的能力[75],推动机器人环境感知技术更加拟人化[76]。
制图是视觉SLAM的重要功能之一,图6展示了视觉SLAM方法可以形成的6种地图形式。其中图6(a)、(b)、(c)是尺度地图的3种表示形式,也即根据地图的稀疏程度精确地表示了地图中物体的位置关系;拓扑地图不具备真实的物理尺寸,只表示不同地点的连通关系和距离,常用于路径规划和定位约束;语义地图是加标签的尺度地图,常用于人机交互,可提供目标物体类型、空间形态及位置等信息;情景认知地图(cognitive maps of city)是人脑中再现的环境意象,由路径、标志、节点、区域、边界5个基本要素组成。上述地图类型覆盖了尺度、拓扑、语义等环境信息,是测绘全息要素的重要组成部分。
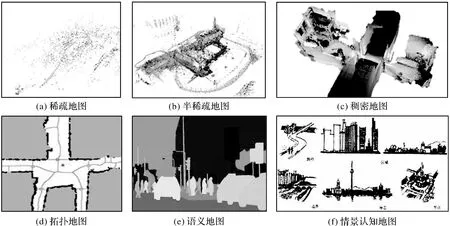
图6 视觉SLAM地图表达形式Fig.6 The map representation of visual SLAM
综上,特征点法视觉SLAM发展较早,相对成熟和完善,但是受光照、纹理等环境特征影响较大;直接法视觉SLAM回避了特征点法中的特征处理环节,在稠密地图重建方面更具优势,但是受到图像灰度一致性假设的限制;视觉指纹库SLAM借助词袋模型优势,更加适应大场景的应用需求,但需对物理世界预先建模,且易受到季节、昼夜、天气等因素影响;语义视觉SLAM技术,立足上述算法,引入了基于深度学习算法的环境语义提取,提升了对环境的理解和交互能力;类脑视觉SLAM采用仿生机理建立的一种新型SLAM方法,在拟人化方面具有较大的发展潜力。然而,面向智能化时代特点,单一的视觉SLAM方法难以满足复杂的应用需求,而建立在新一代信息技术基础之上的多种视觉SLAM方法融合更具发展优势。
2 智能化时代视觉SLAM环境感知发展趋势
视觉SLAM技术对比激光SLAM技术具有成本低、语义信息丰富、可实时传输,以及符合人类的感知习惯等特点[77],成为近年来的研究热点,通过与物联网、5G、云计算、深度学习等技术的结合,将会进一步促进当前的技术进步,在智能化环境交互感知、众包化数据汇聚、网络化实时处理、大数据知识服务和多样化应用等方面快速发展,呈现出智能化时代视觉SLAM环境感知技术的新特点和新面貌。
2.1 智能化环境感知交互
随着视觉SLAM技术与智能芯片、深度学习算法的融合不断加深,利用智能芯片和算法赋能视觉SLAM技术,提升在环境感知、交互响应等方面的智能化水平成为视觉SLAM技术的重要发展方向。在环境感知方面,基于视觉SLAM几何环境信息获取手段,深入研究基于深度学习算法支持的环境语义信息同步感知技术,实现时空属性与物体属性同步认知的功能;在交互响应方面,利用脑感知视觉SLAM、语义视觉SLAM等主动性地判别场景物体,自主跟踪有效目标,对环境观测信息进行有效的综合和取舍,并做出相应的执行动作,推动现在的“眼观六路”感知技术,向未来的“所见即所得”感知与交互融合方向发展,即在观测信息的支持下,对环境情况做出即时的理解和响应。
2.2 即时众包化信息处理
视频作为一种流媒体数据[78],为视觉SLAM技术在即时、众包信息感知处理方面发展奠定了基础。在即时信息处理方面,研究视觉SLAM与互联网、物联网、移动通信网等手段深度耦合方式,攻克基于即时通讯手段支撑的云-边-端协同的位置、制图、几何、拓扑、语义等实时处理技术,打造“感知-信息”联动的在线应用模式,提升视觉SLAM技术的即时服务能力;在众包感知处理方面,利用视觉SLAM的即时处理能力,攻克基于网联汽车、无人车、无人机、机器人、手机等设备云-机交互反馈的众包信息处理技术,满足大众化智能装备在线导航、定位、避障、路径规划等需求,同步构建基于云端的测绘产品[79],打破传统依赖专业团队获取与处理数据的局面,推动众包化环境物联感知技术发展,进一步地解放生产力,提高工作效率。
2.3 多样化感知数据服务
视频蕴含着纹理、颜色、几何、位置、拓扑、语义、POI(point of interest)等众多信息,是测绘地理信息产品的重要构成。通过培育视觉SLAM新型数据服务技术,能够为测绘行业发展提供新动能。通过研究视觉SLAM、GNSS、IMU、超声波雷达等多模态集成算法,有助于推动攻克自动驾驶领域及未知环境区域的导航定位、路径规划、障碍物规避等难点;探索基于视觉SLAM的DOM、DSM、DEM和实景模型在线处理技术,构建新型遥感制图和实景三维的服务模式,为应急测绘等对时效性要求强的应用场景提供支撑;攻克语义视觉SLAM技术支撑的众包POI获取、在线地表变化研判等技术,支撑导航地图更新和自然资源监测等需求。未来可以进一步利用大数据技术,深入挖掘视觉SLAM环境感知成果中蕴藏的丰富地理信息,有效发挥视频数据的潜在价值。
3 视觉SLAM智能化测绘应用模式展望
在新一代信息技术快速发展的形式下,视觉SLAM环境感知技术将会不断取得突破和进展,推动其与传统测绘技术的深度融合,有助于打造基于视觉SLAM环境感知技术的导航定位、地图制图、实景三维、遥感解译等智能化测绘应用模式,促进传统测绘服务方式向智慧化、精准化方向发展。图7基于视觉SLAM技术在位置、制图和语义等方面的优势和发展延伸,提出了6种测绘应用方式。

图7 智能化测绘应用展望Fig.7 Prospect of intelligent surveying and mapping application scenarios
3.1 交互式导航定位
智能装备通过集成视觉、激光、超声波等多种传感器,以及深度学习芯片等,具备了较强的环境感知能力和一定的认知能力,如大疆无人机采用视觉和超声波组合进行避障等。当前视觉SLAM技术多以环境感知的方式使用,随着语义SLAM、脑感知SLAM等技术的不断发展,基于深度学习算法的视觉感知与SLAM技术不断融合,推动智能装备朝着感知与自主决策方向发展,类似火星车自主判断与选择降落点、自动驾驶车辆自动感知周围静态和动态的物体和属性做出行动决策、智能机器人根据环境信息自主决策下一步的行动计划等,基于视觉SLAM和深度学习算法的交互式导航定位技术将会得到进一步的发展。
3.2 数字孪生城市建设
数字孪生城市建设是未来城市发展方向之一,三维地理空间数据是数字孪生的基础。基于视觉SLAM的制图和语义提取技术,可以采用KinectFusion[80]、Openrealm[12]等算法对室内外、地上下空间及附属设施构建BIM/CIM(building/city information modeling)模型,并基于CNN-SLAM赋之真实的语义属性,实现现实世界与虚拟世界的精准映射。融合互联网、物联网、5G、人工智能、区块链等数字技术,构建城市智能运行的数字底座,催生城市治理思维和方式的转变与范式重塑。
3.3 实时化地表监测与解译
视频流从无人机、视频卫星等平台传输至地面或者云服务平台,利用TerrainFusion[35]等视觉SLAM技术获取实时的DOM、DEM、DSM等测绘产品。利用云-边-端等跨终端协同处理技术,结合深度学习、迁移学习、强化学习等多种智能计算模型和专家经验,开展地表空间遥感数据要素智能提取、“数据-模型-知识”驱动的地表要素智能解译、自然资源要素画像和图谱构建技术,实现自然资源要素、场景、知识的快速智能提取和表达[81],推动传统数据服务向知识服务的转变,服务于国土普查与动态监测等业务[82]。
3.4 众包地图POI生产
视觉感知技术是地图POI数据获取的主要手段之一,基于深度学习算法支持的语义视觉SLAM、词袋模型等技术,可与高德等厂商的STR(自然场景文字识别)技术结合,实现实时获取地图POI数据。通过智能手机、智能网联汽车等在使用过程中的视觉传感器采集到的图像、位置等数据,通过5G等通讯网络传输到后端云平台,可以实时的转换为POI数据,推动地图POI数据感知的众包化,革新地图POI数据获取的技术方法,打破专业人员人机交互获取的模式,提升地图POI数据获取的智能化、实时化程度。
3.5 无人值守地质灾害监测
艰险山区崩滑地质灾害突发性强、危害性大,基于GNSS变形监测技术对地质灾害监测的实景展示稍显不足。基于Openrealm等视觉SLAM与设备自动换/充电、无人值守[83]等技术的发展与融合,无人机遥感监测系统可以根据GNSS等预警预报信息联动自主观测灾害体,并实时回传数据构建灾害体实景三维模型,且可以利用视觉感知技术规避三维空间的障碍物,保障飞行安全,实现地质灾害的无人机值守监测与孪生展示。
3.6 深度空间自主交互探测
面向深空、深海、深地等深度空间的探索已成为人类科技竞争的焦点之一,针对陌生甚至未知的深度空间,类似祝融号火星车、玉兔号月球车[33]等智能装备对其环境感知、深度交互和主动决策能力的需求愈发凸显。利用视觉SLAM的导航、定位、制图和语义等技术可以实现对深度空间地形、地貌获取,以及场景和空间要素的识别与解译,并可解决探索过程中的障碍物检测与规避等问题,提高智能装备在深度空间探测过程中的自主性。
4 结 语
随着智能化、云计算、大数据时代的来临,测绘行业面临着重要的转型升级的发展机遇,对测绘装备、数据感知和数据应用模式的发展提出了更高的要求。视觉SLAM环境感知技术经过30多年的快速发展,在定位技术方面形成了多种稳健、可靠的技术框架、算法模型和测绘应用工艺,在大场景制图、语义和类脑技术支持的交互式主动服务等方面取得了较大突破和进展。随着视觉SLAM环境感知技术与人工智能、深度学习、大数据、云-边-端计算等技术的深度交叉发展,将会推动视觉SLAM环境感知技术朝着智能化、众包化、即时化等方向快速发展,进一步推动测绘生产方式和生产力的变革与提升。
位置、几何、拓扑、语义等信息是赋能未来测绘业务智能化发展的重要基础,在当前的新发展格局下,单一的视觉SLAM方法存在巨大应用挑战,需要与新一代信息技术融合发展,研究与完善复杂场景多方法融合的视觉SLAM环境感知技术理论、算法框架,突破实时主动环境感知、场景深度交互自主导航与路径规划、全息要素地图构建与要素识别等关键技术,打造基于行业与大众结合的开放、创新测绘技术服务模式,满足新形势下的测绘应用需求。
猜你喜欢
中老年保健(2021年12期)2021-08-24 03:30:40
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09 08:43:00
开放教育研究(2020年2期)2020-03-31 01:54:14
中国生殖健康(2020年6期)2020-02-01 06:28:50
浙江国土资源(2019年10期)2019-10-31 03:17:00
建材发展导向(2019年10期)2019-08-24 06:25:28
中国生殖健康(2019年11期)2019-01-07 01:28:02
中国公共安全(2017年7期)2017-10-13 08:18:11
电子制作(2017年9期)2017-04-17 03:01:00
现代语文(2016年21期)2016-05-25 13:13:44
