
基于特征用户选择的停电范围判定方法研究
2023-11-01 01:50胡筱曼林文浩
自动化仪表 2023年10期
李 蓓,胡筱曼,林文浩,熊 力
(南方电网广东中山供电局,广东 中山 528400)
0 引言
目前,配网台区用户侧的信息化水平低下、管理混乱,电力用户服务水平仍然存在用户停电信息不准确、无法实现主动告警、供电恢复时间长等问题。当低压侧发生故障时,由于台区低压接线信息缺失或不准确,低压台区停电故障多依靠用户电话报障以及抢修人员逐户排查,难以实现低压侧主动抢修。这影响了用户用电服务体验满意度。当前,通过低压侧加装大量监测装置实现停电告警的技术存在前期投资大和后期维护成本高的问题,难以推广应用[1]。
文献[2]提出1种基于方向分层拓扑的算法,从而确定低压台区发生故障的位置。文献[3]通过数字孪生技术在低压台区的应用,在线路发生异常时能够及时判断出停电范围。文献[4]设计了1种基于馈线终端单元的配电网故障定位系统,根据发生故障时的故障电流确定故障所在区段。文献[5]提出基于配网拓扑矩阵的供电可靠性评估方法,根据故障率关联矩阵与故障时间关联矩阵确定负荷点平均故障时间向量。文献[6]通过配网设备的连接关系使系统快速地定位停电范围,再根据营销系统数据库查询得出停电的影响范围。由于目前低压台区信息化水平不高,拓扑接线信息容易缺失或不准确,导致这些方法存在较大的误差。而配网管理缺乏完整的维护体系,较少涉及低压系统的其他高级应用。
针对以上问题,本文提出1种基于特征用户选择的停电范围判定方法,从而实现低压配网的故障停电主动告警,以减少设备的前期投资、全面提升用户的舒适用电感受和服务体验。该方法首先使用K-means++聚类算法对台区用户进行聚类划分,并计算用户间的停电相关性系数;然后,对相关性系数高的用户加装智能电表,根据用户停电状态进行台区停电范围判定;最后,结合具体台区算例验证方法的准确性。
1 基于停电相关性的主动告警技术
为了实现低压台区的智能化,目前的主要方法是针对低压侧的台区、电表等设备对象,更换集中器、新一代计量表以及加装其他智能控制设备等。
①针对台区侧,通过更换集中器设备,对分路实现本地化实时监测,以提升台区、分路停电告警及台区运行状态统计分析的本地智能化水平,并实现用户用电状态召测及用户停电告警信号的收集。对于用户停/复电,则通过集中器对台区全部用户或任意设定的特征用户召测的方式判断。
②针对用户侧,可加装含停电主动告警功能的智能电表。根据建设原则和预期目标,台区全部用户电表可更换为含停电主动告警功能的智能电表。当部分区域发生停电事件时,区域内的智能电表将停电信息主动上送,以实现目标台区用户停电范围的判定。
由此可见,若要实现台区用户的主动告警,需要安装大量的智能电表。考虑到智能电网建设的经济性,本文提出1种基于特征用户选择的停电范围判定方法。该方法根据同相且电气距离相近的用户在停电方面具有较强相似性的原则[7],对台区全部用户进行聚类划分,筛选出部分停电相关性较强的用户加装含停电主动告警功能的智能电表。当台区发生停电事件时,停电区域内加装智能电表的用户将停电信息上传至集中器,由集中器对其余用户进行轮询,从而实现用户停电范围的判定。台区停电告警技术方案原理如图1所示。

图1 台区停电告警技术方案原理Fig.1 Principle of outage alarm technology scheme of the station area
2 基于K-means++算法的用户聚类划分
K-means++聚类算法使用点与点之间的欧氏距离作为区分的度量。区别于传统K-means算法,K-means++聚类算法基于事先指定簇的数目或聚类中心,经过反复迭代,直至达到“同簇内各点的距离足够近,各簇间点距离足够远”的目标[8]。
2.1 K-means++算法的数学原理
K-means++算法流程如图2所示。
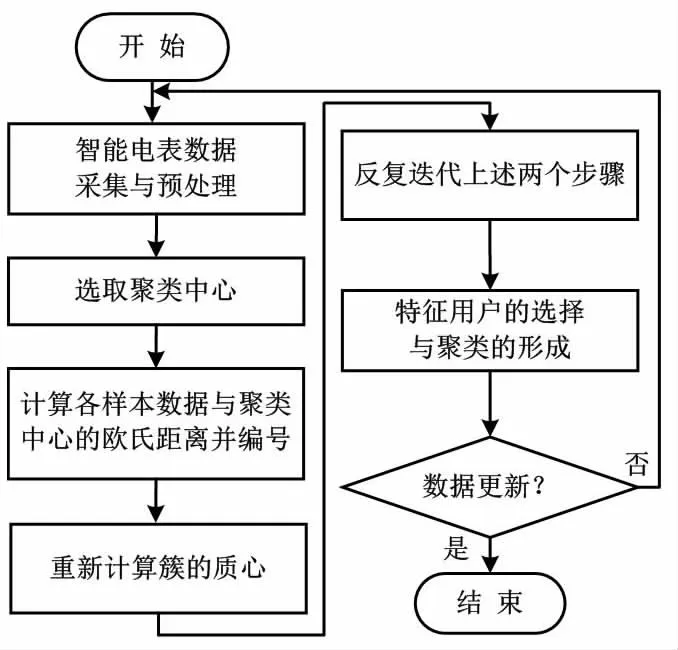
图2 K-means++算法流程图Fig.2 K-means++ algorithm flowchart
K-means++聚类算法的目的是把所有样本划分到不同区域中,使每个区域中样本间的方差最小。
(1)

(2)
每个样本被选为下个聚类中心的概率P(x)为:
(3)
式中:D(x)为每个样本与当前已有聚类中心之间的最短距离。
本文选出所有的聚类中心后,计算所有样本到已经确定的聚类中心的距离,将样本重新划分至对应的类中。根据所得到的分类结果,本文重新计算聚类中心。
2.2 聚类评价指标与参数选择
由于聚类属于无监督学习范畴,在缺少数据标签的情况下,其评价指标不同于有监督分类算法。本小节以无监督学习和高维数据为出发点,介绍几种内部聚类评价指标。
①轮廓系数(silhouette coefficient,SC)结合了聚类簇的凝聚度以及簇间分离度[9],取值范围为-1~+1。SC得分越高,则聚类结果越好。SC的定义为:
(4)
式中:a为样本数据与同簇内其他数据之间的平均距离;b为样本数据与距离其最近的其他簇中所包含的所有数据的平均距离。
②卡林斯基-哈拉巴萨(Calinski-Harabasz,CH)指数通过计算簇中数据与簇中心距离的平方和定义簇内凝聚度,计算各簇的中心与数据集中心距离的平方和,从而定义分离度。CH指数的定义是分离度和凝聚度的比值:
(5)
式中:nD为样本数据集;Btr为簇间协方差矩阵B的迹;Wtr为簇内协方差矩阵W的迹。
由式(5)可知,CH指数值越大,聚类后簇自身越紧凑,簇与簇之间越分散,聚类效果越好。B、W分别如式(6)、式(7)所示。
(6)
式中:nq为第q个簇内的数据数目;CD为数据集D的中心;Cq为第q个簇内数据点的集合;T为转置。
(7)
③戴维森堡丁(Davies Bouldin,DB)指数表示簇间的平均相似度。DB指数将不同簇中心的距离与不同簇内数据到其簇中心的平均距离进行比较,为:
(8)
式中:Wi和Wj分别为第i个、第j个簇中所有数据到其所在簇中心的平均距离;dij为第i个、第j个簇的簇中心之间距离。
不同于上述SC、CH指数,DB指数越低(最小值为0),则集群之间的分离越好,聚类效果也越好。
基于已经预处理的电表数据集,本文以用户为单位采用K-means++算法进行聚类,并分别计算不同k下SC、CH、DB这3个无监督聚类评价指标,以实现在不同参数下聚类性能的评价,从而确定最优的聚类参数值。
3 停电相关性系数与特征用户的选择
停电相关性系数的计算数据来源于“营-配”业务深度融合的数据平台。该平台可用于获取不同时刻的电表数据。由于台区用户数目众多,电表数据随时间不断更新且增长迅速,对所有用户进行停电相关性系数的计算显得不切实际。因此,本文将用户划分为若干聚类簇,在聚类簇内进行分析研判更为方便。
图3为停电相关性系数计算流程。
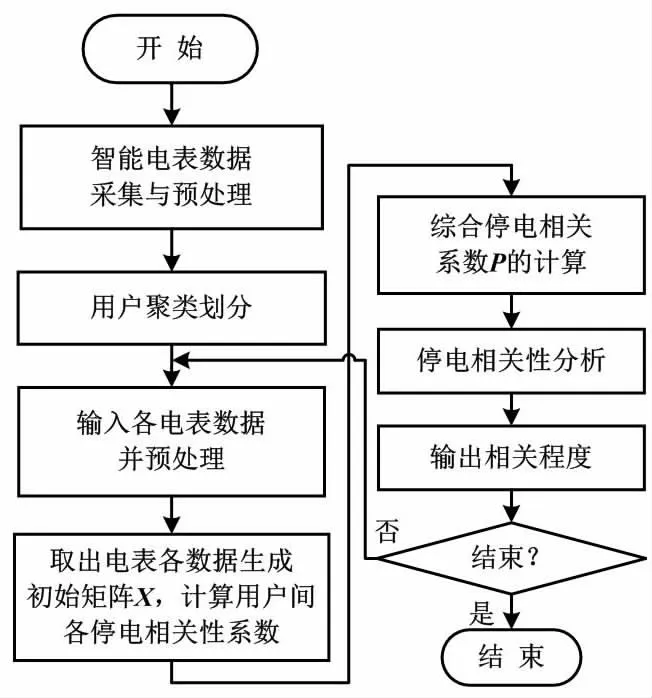
图3 停电相关性系数计算流程图Fig.3 Outage correlation coefficient calculation flowchart
在台区用户聚类基础上,本文提取并预处理同簇内所有用户电表数据,通过相关性定义算法[10]依次计算同簇内所有用户间的停电相关性系数ρ。
(9)
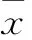
基于同簇内用户间停电相关性系数,本文得到相应属性与停电相关性关联度等级。所述的相关性系数介于-1~+1。相关性系数绝对值越大,所代表的用户间停电关联度越高。
基于上述所得聚类结果,对于簇内只含2个用户的聚类簇,可随机选择特征用户。若聚类簇内用户拥有3个及以上用户,基于相关性系数矩阵,本文选取综合停电相关性系数最高的用户作为特征用户。
(10)
基于特征用户选取结果,可对特征用户加装含超级电容器的智能电表。通过智能电表实时告警上传技术,主站可实时监测各特征用户的停用电状态。
4 算例验证
为验证所述停电范围分析的有效性,本文采用某地区实际低压台区拓扑结构进行试验。该台区共有100个用户。
台区结构如图4所示。
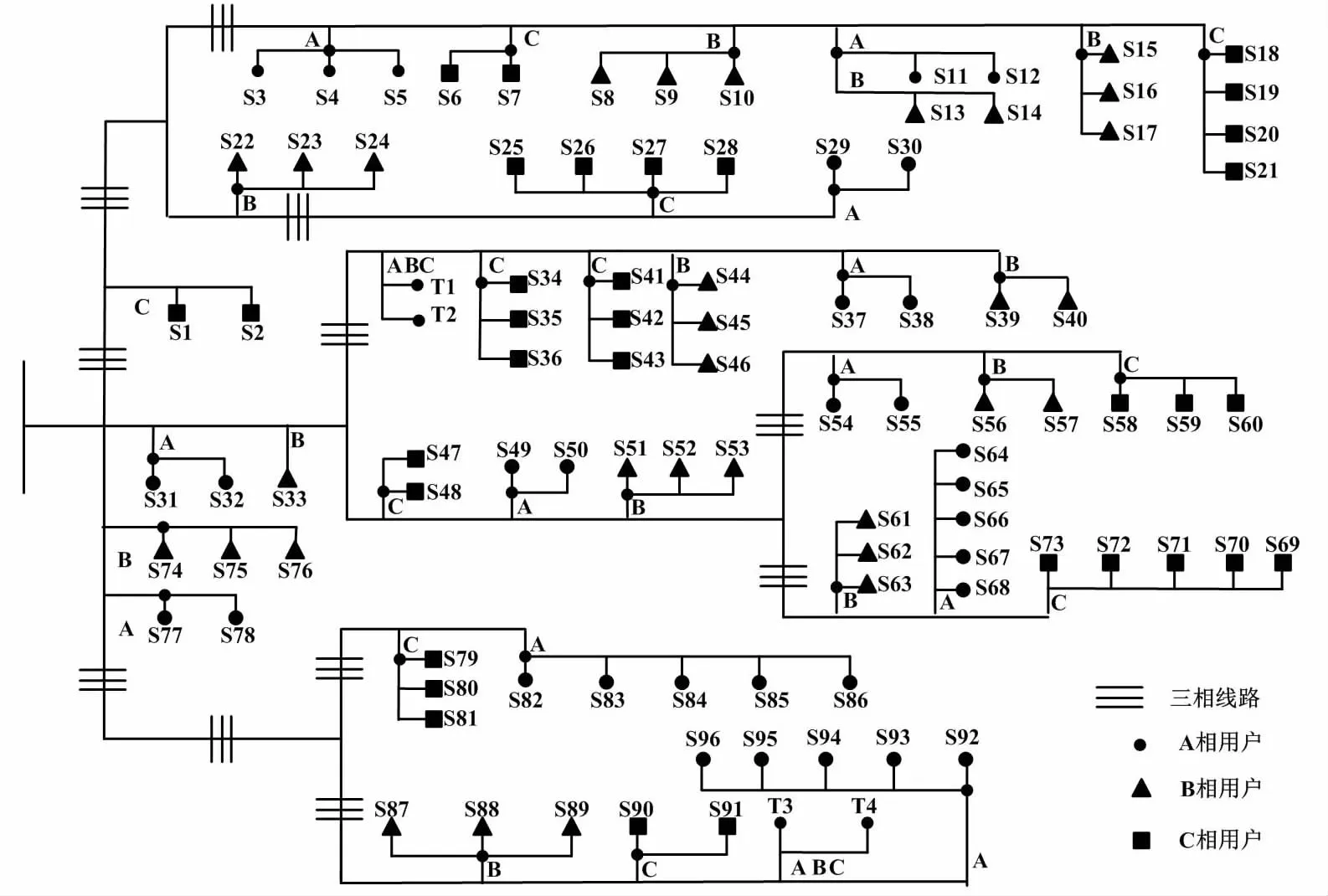
图4 台区结构示意图Fig.4 Schematic diagram of station area structure
图4分别用不同符号表示A、B、C三相线路用户。本文记录100个用户在60个不同时刻内的电压数据,并以用户为单位对处理后的数据采用K-means++算法进行聚类。预估聚类参数取值范围为[36,43]。
本文分别计算不同聚类参数下SC、CH、DB这3个无监督聚类评价指标,进而实现在不同参数下聚类性能的评价。
不同聚类参数下各聚类指数得分如图5所示。

图5 不同聚类参数下各聚类指数得分Fig.5 Score of each clustering index under different clustering parameter
由前文可知,SC和CH得分越高、DB得分越低,说明聚类效果越好、参数选择越合理。由图5可知,当聚类参数分别为39、40、41时,SC具有较高的得分;随着聚类参数的不断增大,CH指数呈逐步增高的趋势,DB指数呈现先降低再缓慢上升的趋势。同时考虑兼顾多个聚类评价指标,本文选择聚类参数为39,即将原始100个电表聚成39类以进行后续研究。
当聚类参数为39时,SC、CH、DB这3个指数均具有较好表现。故在此参数下,K-means++聚类算法能够在相应算例数据集上取得较好的结果。
以A相为例,基于停电相关性系数的计算,A相用户S3、S4、S5之间停电相关性系数计算结果如表1所示。

表1 停电相关性系数计算结果Tab.1 Outage correlation coefficient calculation results
对同簇内停电相关性系数求和后可知,取系数最高的用户S3加装含超级电容器的智能电表。当特征用户停电时,智能电表实时向主站发送告警信号。
主站在接到告警信号之后,利用采集器实时采集同簇内其余用户的电表数据,从而分析同簇内其余用户的停电状态。由此可基于各特征用户停电告警的先后顺序进行分级研判。
为了验证本文方法的正确性,本文依据实际电网停电的范围给出3种不同场景下的停电情况。
台区特征用户选择及装表情况如图6所示。

图6 特征用户选择及装表情况示意图Fig.6 Feature user selection and meter installation schematic
图6中,A、B、C三相的聚类结果如图6中虚线框所示。停电区域如图6中的3个阴影部分所示。场景一中,C相线路发生单相接地故障,特征用户S25发出告警信号。通过集中器对其同簇用户S26、S27、S28分别进行轮询,发现用户S26、S27、S28均停电,则判断停电范围为图6中场景一所在阴影区域。场景二中,馈线分支发生三相短路故障,特征用户S55、S57、S60发出告警信号。集中器对其同簇用户S54、S56、S58、S59分别进行轮询,发现4个用户均停电,则判断停电范围为图6中场景二所在阴影区域。场景三中,当整条馈线发生三相短路故障,特征用户S81、S86、S87、S91、T4发出告警信号。集中器对其同簇用户分别进行轮询,发现14个用户均停电,则判断停电范围为图6中场景三所在阴影区域。由此表明,本文方法判断的停电范围与实际设定停电区域一致。
5 结论
本文针对配网台区停电范围的判定成本高、实施难度大等问题,提出了1种基于特征用户选择的停电范围判定方法,并基于实际算例验证了所提方法的可行性与有效性。本文所得结论如下。首先,通过综合考虑SC、CH、DB这3个聚类评价指标,确定最优聚类参数值,以提高台区聚类的有效性,从而提高停电范围判定的准确性。其次,通过对停电相关性系数高的用户加装智能电表,减少了设备配置,降低了设施投入的成本。所提方法根据各特征用户停电告警的先后顺序进行分级研判,可以准确判断停电范围。这提升了低压台区的供电可靠性,为低压配电网的建设提供了参考。
猜你喜欢
中学生数理化·中考版(2022年10期)2022-11-10
中学生数理化·中考版(2021年10期)2021-11-22
电子测试(2017年15期)2017-12-18
数学小灵通·3-4年级(2017年2期)2017-05-30
电子制作(2017年2期)2017-05-17
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
电测与仪表(2014年16期)2014-04-22
电测与仪表(2014年13期)2014-04-04
电力需求侧管理(2014年6期)2014-03-20
