
面向无人平台的视觉空间关系模型
2023-11-01 13:02皇甫润南田江鹏屠铱成
测绘通报 2023年10期
皇甫润南,田江鹏,游 雄,屠铱成
(1. 信息工程大学,河南 郑州 450052; 2. 61175部队,江苏 南京 210046)
伴随以大数据和深度学习为代表的新一轮人工智能技术浪潮,人工智能与武器装备的结合日趋紧密,无人平台已成为影响未来战争制胜机理的颠覆性技术,也是形成颠覆性军事能力的重大发展方向。无人平台是一个多学科交叉的前沿领域,涉及的理论问题和关键技术非常广泛,从测绘学的视角来看,最有价值且最富挑战的问题之一是,如何提高无人平台对复杂环境的感知、认知和理解水平。时至今日,这一问题已取得一定突破,特别是传感器技术和机器学习算法的进步将无人平台推向了新的高度。自动驾驶汽车已经开始进入开放环境路测[1],搭载传感器的无人机可在野外环境中自由穿行[2],无人舰艇也逐渐出现在多个行业和领域[3]。然而,无人平台对环境的自主感知与理解、推理和决策的问题并未得到根本性解决,在新一轮人工智能的赋能下,逐渐成为不同领域竞相追逐的前沿热点。
测绘领域已经对这一研究热点产生积极响应。文献[4]指出,新时期测绘与地图的服务领域应实现从地球表面向多维空间拓展,实现为“人”服务的测绘产品拓展到为智能机器人服务的平台或系统提供测绘保障。地学领域与无人系统结合最为紧密的是面向自动驾驶高精地图[5-7]的研究与应用。高精地图是普通导航地图的颠覆性升级,因而以地图作为无人平台记录和传播地理信息的语言,将人类使用地图的模式和机制移植到自动驾驶车辆上,是高精地图作为桥梁衔接地图学与无人平台的内在发展逻辑。事实上,机器人、自动控制等领域已经采用各式各样的地图对客观环境进行抽象和描述,如特征地图、栅格地图、语义地图等。从地图学视角而言,随着交叉研究的不断深入和统一,一种适用于无人系统认知理解环境信息、建立环境认知模型、进行空间推理决策的机器地图[8]将出现在地图家族序列之中。
当认知主体由人类变为无人平台,地图的结构和应用模式也发生了相应的变化,其中较为典型的是关于空间关系的记录和描述。人用地图并非显式地记录要素之间的各种关系,而是通过地图阅读在人类的视觉系统和大脑中重建要素之间的关系[9]。若使得无人平台具备类似于人脑的理解和推理能力,就需要在地图中显式地描述要素间的空间关系,具体表现为3个层次的问题。一是空间关系检测,即无人平台通过各类传感器,实时感知并解译空间关系。其中,引用计算机视觉领域对这一问题的定义[10],本文将通过视觉传感器获得的空间关系称为视觉空间关系。二是空间关系记录,即需要设计一种能够描述地理要素及其相互关系的数据结构,如场景图[11]使用
本文针对无人平台视觉空间关系模型缺失的问题,将地图学和机器视觉中关于空间关系的分类、模型和算法进行交叉融合,提出一种面向无人平台的视觉空间关系模型,并通过试验对模型的可行性进行检验。
1 视觉空间关系模型
1.1 相关研究
地图上表达的空间关系侧重对空间实体对象之间所具有的空间特性的形式化,且大多用于描述空间对象之间的几何关系[14]。文献[15]将空间关系分为5类:拓扑关系(包含、邻接、相交、相离等)、方位关系(东、南、西、北、上、下、左、右等)、顺序关系(在……内部、在……旁边、在……外部等)、距离关系(基于度量表示的地理实体之间的距离远近程度)及模糊关系(接近、疏远、贴近等)。文献[16]认为拓扑关系、方位关系和度量关系是传统空间关系的3种基本关系类型。在拓扑空间中,拓扑关系所表示的关系与实体的位置和距离无关,因而不会因空间实体的放大、缩小和位移而发生变化[17]。地图对空间关系的分类模式系统性更强,实例的定义空间分布特征更为明显,且在拓扑、方位和度量3个基本分类上已经形成共识。
在机器人领域,目标检测和语义分割技术日趋成熟,推动了视觉空间关系检测技术的发展。当前,视觉空间关系检测最新进展依托于深度学习技术,是一种描述主客体视觉空间关系的数据驱动检测流派。文献[18]提出了首个面向场景图、包含超过30个视觉空间关系类型的数据集Scene Graph。随后,文献[19]又提出了包含70个关系类别的VRD(visual relationship dataset)数据集,其中,描述关系的谓词根据语法被分为活动、空间、介词、比较和谓词5个类别。以此为基础,进一步将静态空间关系拓展为动态空间关系,如在分析实体间空间关系时考虑时间因素影响的VG(visual genome)[18]数据集;聚焦动态场景中时空特征表达的AG(action genome)[19]数据集,通过注意关系、空间关系和接触关系3类关系,描述了视频关键帧中人和其他物体的关系。
上述两方面的现状进一步表明:对机器人领域和经典地图学的空间关系进行研究,并没有得到积极的交叉和相互启发。在机器人领域,目标识别和语义分割的日趋成熟,使得视觉空间关系检测成为研究热点;而在地图学领域,空间关系的研究仍主要面向人类主体,缺乏面向无人主体的拓展。鉴于此,参照地图学在空间关系研究方面的经验,将不同机器视觉算法和数据集中分散的关系实例进行统一整合,建立一种基于空间认知机理,由机器视觉算法支撑的视觉空间关系模型,将会是提高无人平台空间关系认知和表达能力的可行方案之一。
1.2 分类模式
关于空间关系的表达,在人工智能与地学领域存在一定差异[20],人工智能领域更注重空间关系的形式化表达与推理,而地理空间关系则聚焦于空间定位,以及地物的位置和属性特征。二元定性空间关系的形式化表达及其组合是地学研究的核心内容[21],主要体现为拓扑关系、方位关系和度量关系。作为地理学语言的地图,则基于数学、符号和注记等规范记录空间要素,空间关系蕴含在其中。因此,关于位置的相互关系的表示,应是无人平台空间关系描述的关键问题。
综上所述,本文提出了统一的视觉空间关系分类模式,见表1。总体上将视觉空间关系分为位置关系与语义关系两大类。位置关系进一步分为拓扑关系、方位关系和距离关系,继承了地学空间关系的一般表达规律。语义关系包括主体带有目的性的动作关系及主客体自身的属性关系。动作关系受认知与视觉领域的启发,主要应用于人或其他具有执行动作能力主体时的场景,根据主客体之间是否接触及主体对客体的注意力情况分为注意关系与接触关系。属性关系主要对空间对象的类别、特征、属性等其他语义关系进行描述,可分为类属关系、比较关系和相似关系。类属关系主要用于描述具有相同类别或属性的主客体,反映对象之间的特征、层次与实例情况;比较关系侧重对主客体的属性特征进行对比分析;相似关系描述主客体之间某一属性的相关性。

表1 统一的视觉空间关系分类模式
1.3 表达模型
基于上述无人平台环境描述和空间关系表达的特殊性,结合统一的视觉空间关系分类模式,可以进一步建立视觉空间关系表达模型。无人平台在场景S中所建立的视觉空间关系图表达模型,可表示为五元组,即
ReS=(O,R,E,T,F)
(1)
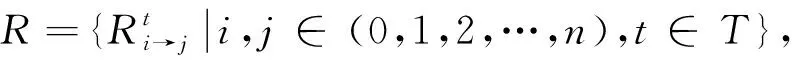
2 数据集设计
构建无人平台视觉空间关系模型,旨在提高其空间关系的预测和表达能力,而这种能力的评测最终需落在机器算法层面。因此,本文在现有视觉空间关系检测算法的基础上,通过构建融合视觉空间关系模型的数据集,训练视觉空间关系检测模型,比较不同模型的视觉空间关系检测能力,从而对关系模型的可行性进行验证。
2.1 数据集构建
数据集构建的步骤主要包括:①数据采集与处理,围绕视觉空间关系模型包含的关系类型和实例,以室内和室外园区环境为原型,以无人平台自主导航寻路为任务背景,通过无人车及其搭载的视觉传感器采集并获得视频数据;同时,采用FFmpeg插件从视频中提取关键帧,并使用Faster R-CNN[22]工具从关键帧中提取视觉目标,以便后续试验处理。②视觉空间关系标注,以视觉空间关系模型规定的关系类型和实例为依据,采用人工标注的方式,标注关键帧图像上目标之间的空间关系,形成视觉空间关系数据集。数据集构建流程如图1所示。

图1 数据集构建流程
2.2 数据统计情况
本文构建了3种测评数据集,以满足试验方案中设计的3个模型评测需求。①自建数据集(self build dataset,SBD):严格按照视觉空间关系模型进行数据采集和关系标注构建的数据集,以较为客观地反映一个完整任务的视觉数据闭环,该数据集主要用于空间关系分布特征分析试验和模型有效性分析试验。②AG抽样集(Sampling AG,SamAG)[19]:是研究视觉关系检测与动态场景图生成的常用数据集,可作为本文视觉空间关系模型和数据集的比照对象。考虑数据规模、关系分布等一致性问题,本文采用随机抽样方法构建SamAG数据集,以支撑与SBD数据集的横向比较。③认知数据集(Cognition Vision Relation Dataset,CogVRD):以自采数据集和AG数据集为基础,以视觉空间关系模型为依据进行图像筛选(按照场景和任务的相似性选取了部分图像)、关系补齐等操作获得的数据集,主要用于空间关系预测能力分析试验。4种试验数据集的详细统计信息见表2。

表2 试验数据集统计数据
2.3 空间关系分布特征分析
以SBD数据集和SamAG数据集为基础,对空间关系构成、分布特征和独立性进行分析,验证基于视觉空间关系模型构建的数据集是否反映模型的结构。
图2为两个数据集包含的空间关系分布情况。可以看出:①以视觉空间关系模型中的关系类型为比较依据,SBD比SamAG具有更好的空间关系覆盖度,基本保证了每种空间关系都具有一定的出现频次,说明了数据集构建遵循空间关系模型的结构;②两个数据集中少部分空间关系频次很高,而大部分空间关系出现的次数很少,空间关系分布均呈现典型的长尾分布特点,一定程度上能够说明基于空间关系模型构建的数据集符合统计学特征;③SamAG中“in_front_of”“holding”“not_contacting”等关系出现频次较多,SBD中“meet”“not_contacting”“in_front_of”等关系更为集中,两者有所重叠但不完全一致。

图2 数据集空间关系分布情况
图3更为细致地比较了两个数据集中空间关系分布的差异性。可以看出,SamAG的关系分布与SBD关系曲线具有一定的差异,两个数据集中频次靠前的空间关系也不尽相同,因而两种数据集在一定程度上是相互独立的。为进一步验证这种独立性,将两个数据集的空间关系频次归一化到[0,1]区间内,使用欧式距离函数对两个数据集的空间关系分布拟合度进行计算,得出相似度为11.66%。
结果表明,SBD数据集和SamAG数据集在关系分布上具有独立性,且SBD数据集具有更丰富的空间关系类型。一定程度上证明了SBD数据集能够反映本文所提出的视觉空间关系模型,且数据集的独立性特点为后续的比较试验奠定了基础。
3 基于STTran的视觉关系检测
3.1 时空Transformer
本文采用时空Transformer方法[13]完成视觉空间关系检测模型的训练。时空Transformer是Transformer模型在视觉语言领域的拓展,由一个空间编码器和一个时间解码器构成,能够有效利用时空上下文信息进行空间关系动态预测,适用于本文无人平台时空连续视觉数据的处理需求。
3.2 评测任务和策略
引入视觉空间关系检测常用的3个评测任务[23],即谓词分类(predicate classification,PredCls)、场景图分类(scene graph classification,SGCls)、场景图预测(scene graph detection,SGDet)。其中,谓词分类任务是根据对象标签和位置预测空间关系;场景图分类是根据对象位置预测对象标签及其相互之间的空间关系;场景图预测则是从关键帧中预测出标签、位置和空间关系。
评测策略方面,引入文献[13]的无约束(no constraint)、有约束(with constraint)和半约束(semi constraint)3种策略。其中,对于空间关系三元组,无约束策略允许每个主客体对有多个谓词猜测,可以反映多标签预测的能力,但错误率较高;有约束策略允许每个主客体对中最多一个谓词,要求更为严格;半约束方法可以允许主客体有多个谓词,当且只有对应关系的置信度高于设定阈值时,才认定该谓词有效。
对于空间关系预测结果的评价,本文使用召回率(Recall@K)作为评估指标。召回率[10]是指对预测得到的空间关系三元组进行排序,在排序为前K(本文取K=10,20,50,100)个预测中,计算预测正确关系所占的比例。
3.3 关系预测能力分析
对本文构建的CogVRD数据集进行空间关系预测试验,与AG数据集的预测结果进行对比分析,从而对比本文模型的空间关系预测能力。
表3为AG数据集与CogVRD数据集在3种评测任务和成图策略下的预测结果。可以看出,整体上,CogVRD基于视觉空间关系模型和AG数据集进行构建,类似于AG数据集,任务难度越高,建模策略越复杂,召回率越低。数据细节上,CogVRD和AG数据集的表现总体趋于同等,在不同任务下各有优劣:对于谓词分类(PredCls)任务,AG数据集训练的模型整体优于CogVRD数据集;对于场景图分类(SGCls)任务,4种召回率下,CogVRD数据集均有所提高,CogVRD数据集训练模型的场景图分类能力在局部略优于AG数据集;难度较高的场景图预测任务中,CogVRD数据集和AG数据集在不同策略下表现基本等同。
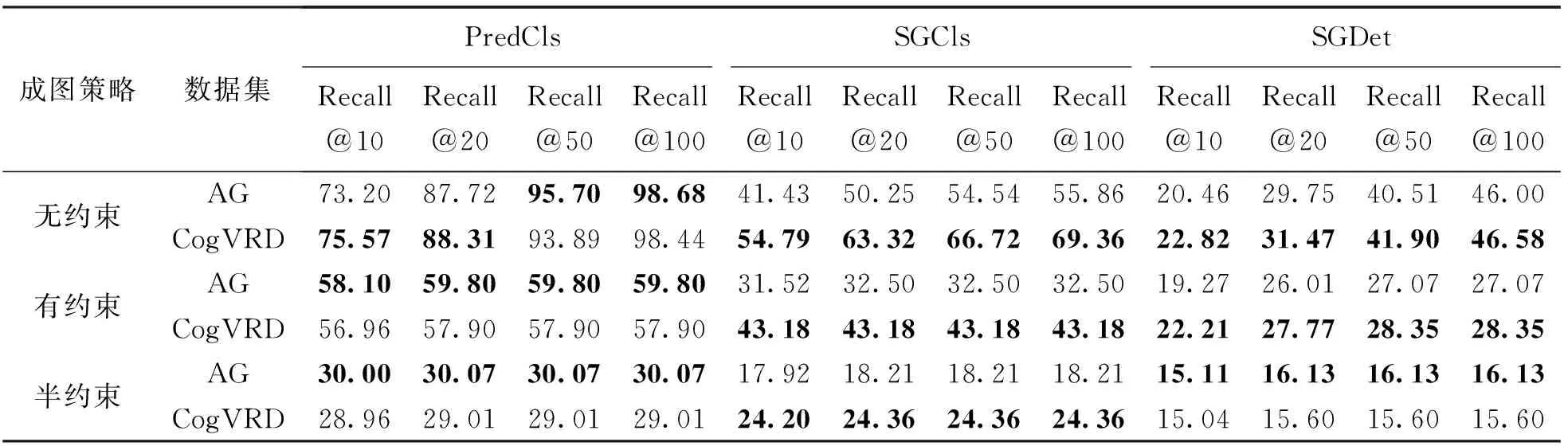
表3 CogVRD数据集和AG数据集的空间关系预测对比结果 (%)
试验结果表明,基于视觉空间关系构建的CogVRD数据集,在保证与AG数据集相媲美的空间关系预测性能基础上,拥有更加适合无人平台环境地图建模的空间关系分布情况,表明本文构建的视觉空间关系模型在一定程度上优化了视觉空间关系的建模能力。
4 结 论
无人平台对环境理解能力受限是影响其自主能力整体提升的瓶颈之一,而为无人平台构建更加科学和智能的地图模型,是未来提高其自主能力的重要方向之一。本文针对无人平台视觉空间关系模型缺失问题,将地图学和机器视觉中关于空间关系的分类、模型和算法进行交叉融合,提出了基于空间认知的无人平台视觉空间关系模型。将地图学中空间关系的分类和描述方法,与机器视觉领域的视觉空间关系检测和建模算法相结合,采用交叉融合式研究范式建立视觉空间关系模型,能够改善当前机器视觉领域空间关系不统一的问题,对提高无人平台视觉关系检测、实现空间关系记录和地图模型构建等具有一定的研究意义。
本文的局限性为:①视觉空间关系模型的进一步完善,可根据应用场景的差异性建立场景相关的视觉空间关系模型,提高关系预测的准确性,推动模型的应用落地;②加强空间关系标注准确度和数据集建设,以关系模型作为约束条件进行数据标注,也是非常耗时和耗力的工程,数据集的扩充、优化、按应用场景分化等,都需要投入更多的努力;③深化视觉空间关系检测与地图建模的衔接,打通观测、制图和推理决策的一体化建模流程。
猜你喜欢
大科技·百科新说(2021年1期)2021-03-29
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
动漫界·幼教365(中班)(2020年8期)2020-06-29
数学物理学报(2020年2期)2020-06-02
小哥白尼(军事科学)(2019年2期)2019-04-17
小哥白尼·趣味科学画报(2019年12期)2019-02-28
岷峨诗稿(2017年4期)2017-04-20
新高考(英语进阶)(2017年12期)2017-02-26
光学精密工程(2016年6期)2016-11-07
核科学与工程(2015年4期)2015-09-26
