
基于代价敏感的细粒度服装图片检索
2023-10-31 11:40:02邹子安何儒汉
软件导刊 2023年10期
邹子安,何儒汉
(1.武汉纺织大学 计算机与人工智能学院;2.纺织服装智能化湖北省工程研究中心,湖北 武汉 430200)
0 引言
随着人们需求的进一步精细化,图片检索技术逐渐向细粒度方向深入发展。细粒度服装图片检索主要通过对图像的相似度进行比较实现[1-4],该类方法在服装图片像素层面构建检索模型提取全局或局部特征进行相似度的排序比较。然而,细粒度服装图片检索中广泛存在类别不平衡问题,即当部分类别数量远高于其他类别数量时,在学习过程中通常会导入有利于数量占比多类别的分布偏差,导致数量少类别的条件概率被低估,从而影响分类和检索结果。
由于相同类别服装图片之间高度相似,以及部分服装图片数据集存在类别不平衡现象,面向服装图像的细粒度检索是一个具有挑战性的课题。对于非平衡问题,目前算法层面的解决方案主要是优化损失函数。该领域最常使用的损失函数为交叉熵(Cross Entropy,CE)损失函数。经典的交叉熵损失函数对每个数据实例具有同等的重要性,这导致网络对较少数量的类别缺少优化监督。因此,在类别不平衡情况下的分类、分割和检索等任务中,CE 损失函数是不适用的。另一种简单固定权重交叉熵(weighted CE)损失函数被广泛用于类别不平衡时的检索任务,其设置类权重与类频率成反比[5-6],然而这种策略在大规模真实数据集中存在困难样本时性能很差。Focal 损失函数采用动态策略分配类的权重,重点关注难以训练的实例,但如果某个样本标注错误,会导致模型训练效果越来越差[7]。
针对细粒度服装图像检索任务中存在的不平衡数据集问题,本文提出基于代价敏感的细粒度服装图片检索模型。该模型通过联合预测服装属性和关键点学习服装特征,采用基于代价敏感的损失函数处理细粒度服装类数据集的不平衡问题,对模型中的关键点检测模块进行改进,提升模型提取特征的性能。为证明该模型的有效性,在DeepFashion 数据集上进行实验,与文献[2,8]中的细粒度图片检索方法进行比较,与文献[9]中的方法进行服装类别、属性识别性能比较。
1 相关研究
1.1 细粒度图像检索
在计算机视觉中,细粒度图像检索比基于内容的图像检索更为困难,这是由于类别之间的差异较大,但同一类别内的差异很小。目前关于细粒度图像检索技术的研究有很多,例如Sathit[8]提出基于自适应深度学习的细粒度文化遗产图像检索方法,该模型可以处理新类别的增量流,同时保持其过去在旧类别中的性能,不丢失文化遗产图像的旧分类。该方法的目标是执行类别检索任务,同时对新类别进行增量学习以减少重新训练的过程;Liu 等[9]通过联合预测服装属性和关键点学习服装特征来进行服装分类和检索;Zeng 等[10]采用分段交叉熵损失函数增强模型的泛化能力并提高检索性能;Xu 等[11]提出一个视觉—语义嵌入模型,该模型使用知识库和文本研究语义嵌入;然后训练一个端到端卷积神经网络框架,将图片线性地映射到丰富的语义嵌入空间中;Liu 等[12]提出一种基于图嵌入的方法学习图像与场景草图之间的相似性度量,该方法对多模态信息(包括对象的大小、外观以及布局信息)进行建模,在细粒度图像检索中有应用潜力;Zhang 等[13]提出一种自动细粒度识别方法,通过汇集深度卷积核空间响应向量并加权组合,从而使训练和测试阶段均不需要任何对象/部件注释;Xie 等[14]引入一个基线系统,使用细粒度的分类分数表示和共享索引图像,将语义属性更好地纳入在线查询阶段,并在合理的时间和内存消耗下获得了良好的搜索结果;Kumar 等[15]提出一种基于卷积神经网络的内容细粒度图像检索框架;Cui 等[16]提出一个端到端可训练网络ExchNet,基于注意力机制和注意力约束分别获得局部和全局特征,并为细粒度图像生成紧凑的二进制代码以改善查询速度慢和冗余存储成本问题;Wang 等[17]提出一种三向增强的部分感知网络,该网络在中层特征空间后加入一个混合的高阶注意力模块,以生成各种高阶注意力图,捕捉中层卷积层中包含的丰富特征。虽然以上研究在细粒度服装图像检索方面取得了一定进展,但在处理数据集类别不平衡问题时仍存在困难。
1.2 数据层面非平衡学习
数据层面的非平衡学习方法采用重新取样策略改变原始数据中的类分布,以达到平衡数据集的目的[18-20]。最简单的重抽样形式包括随机过量取样和随机欠量取样,前者处理类的不平衡是通过重复少数类中的实例实现的,而后者是随机从多数类中删除实例,以便与少数类的数量相匹配。研究表明,数据抽样策略对分类性能影响不大[19]。虽然抽样策略被广泛采用,但这些方法操纵了给定领域的原始类表示,并引入了一些缺点,例如过度采样有可能会导致过度拟合并加重计算负担,而欠抽样则可能消除对归纳过程至关重要的信息。此外,采用抽样方法人为地平衡数据可能不适用于具有很大差异的数据集[20]。
1.3 算法层面非平衡学习
算法层面的非平衡学习方法可分为集合方法和对成本敏感的方法两类[21-22]。例如,Liu 等[23]提出一种成本敏感的变分自动编码分类器,通过引入成本敏感因素将高成本分配给少数群体数据的错误分类,从而使分类器偏向少数群体数据以解决不平衡数据分类问题;Wang 等[24]提出一种基于信息熵的两类成本敏感矩阵化分类模型,将信息熵引入到矩阵化学习框架中以降低错误分类成本;An等[25]提出一个基于深度学习的模型,通过强化学习代理指导成本敏感的特征获取过程,以自适应地为每个实例选择信息丰富且成本较低的特征;Aram 等[26]引入一种基于支持向量机的滤波方法,通过选取模型对二次最大边缘特征进行线性化,提高了支持向量机特征选择的泛化能力,使其适用于各种代价错误情况;Losifidis 等[27]针对不平衡数据提出一种成本敏感的提升模型AdaCC,在提升过程中根据模型表现动态地调整错误分类成本,而不是使用固定的错误分类成本矩阵。
以上研究主要通过引入深度神经网络模型、修改损失函数或修改原始数据集的方式处理数据不平衡问题。本文在参考以上研究成果的基础上引入联合预测服装属性与关键点的深度网络模型,通过代价敏感损失函数处理服装类别、属性不平衡等问题。主要创新点为:①与固定权重相比,所提出的代价敏感损失函数既采用固定的权重方案,又根据数据实例的预测难度自适应增加动态权重;②动态权重对实例的错误预测结果进行惩罚,提高困难样本的参数优化程度;③优化了服装关键检测模块,使得模型保留了特征的空间对应关系,提升了服装特征提取性能。
2 检索模型构建
误差的反向传播算法通常用于训练神经网络,其根据训练过程中产生的误差更新模型权重,来自每个类的数据实例错误分类具有相同的重要性。本文基于该算法建立基于代价敏感的细粒度服装图片检索模型。
2.1 细粒度服装图片检索模型结构
细粒度服装图片检索模型依靠大量图片和细粒度标签等数据进行训练,通过损失函数误差反向传播优化模型参数以学习图片包含的细粒度服装属性。然而,细粒度服装图片数据集中的类别不平衡对训练模型性能有很大影响。数据集类别不平衡的解决方法有数据层面和算法层面两种,由于本文数据集类别分布过于极端,图片属性存在各种复杂的包含关系,采用数据集重组方法存在过拟合和加重计算负担等缺点,不适合使用数据层面的方法。因此,本文设计了算法层面基于代价敏感的方法解决数据集类别不平衡问题。
联合预测服装属性与关键点的细粒度服装图片检索模型结构如图1 所示。该模型将关键点坐标变为热图的形式,不破坏卷积网络与标签的对应空间关系,有利于服装特征提取。该模型由4 个部分组成:①主干网络模块。用于提取28×28×512 维度的图片特征;②服装关键点检测模块。通过Roi-pooling 层切割图片关键点位置特征,组合成4×4×4 096 维度的卷积层;③服装类别、属性分类模块。服装类别分类模块通过下采样卷积压缩主干网络的图片特征维度至7×7×512,通过全连接分类网络区分服装的类别信息;服装属性分类模块压缩第②部分网络输出信息,通过全连接属性分类网络识别出服装属性;④服装图片检索模块。该模块通过深度网络模型输出的特征信息建立特征索引库,实现服装的检索查询。

Fig.1 Fine-grained apparel image retrieval model structure图1 细粒度服装图片检索模型结构
2.2 代价敏感学习
分类损失函数设定包含n 个样本的数据集表示为D=,其中X⊂表示图片的特征空间域,Y⊂表示标签的空间域。对于每个数据实例i,xi⊂X为输入特征向量,yi⊂Y={1,2,...,c}为真实的类标 签。分类器的训练参数表示为F:=,其将输入的特征向量映射到标签空间向量f :X→Y,并通过最小化损失函数学习L(f(x;θ),y)。定义1 个损失函数L:R×Y→R+和1 个分类器F,模型误差均值被定义为RL(f)=ED[f (x;θ),y],其中期望值与数据集D有关。
模型的细粒度属性为多标签性分类,其最后一层为sigmoid激活函数,那么细粒度属性损失函数的平均误差可表示为:
式中:θ 为模型的参数集,yij为实例xi的编码标签中第j个元素,yi=∈{0,1}c;fj(x;θ)∈Rc为模型输出,fj为f的第j个元素。
代价敏感损失函数在原分类损失函数的基础上引入一个代价矩阵的加权分类目标函数,为少数类和难以训练的实例分配更高权值,表示为:
式中:cost(fj(xi:θ),yij)用于计算模型输出fj(xi:θ)与真实标签yij对应的代价权重wij。将代价权重wij作为一个超参数来处理,设置其与该类出现的类频率成反比,其所有的值表示为一个代价矩阵。
令pj=fj(xi:θ),则代价矩阵定义为:
式中:py表示数据集中真实标签yij的频率。
代价权重既有数据集样本类别不平衡的权重w1=(1-py),又增加了模型预测错误的惩罚项其中因此,代价权重函数可简化为wij=w1+w2,其中w1的特点为数据样本越小,其权重越大;w2表示模型输出结果在向量中与正确标签的距离,作用为控制困难样本的权重。该代价损失函数有两个优点:①当一个训练实例被错误分类时,惩罚项w2能起到修正作用;②当一个训练实例所属类的数量占比很低时,权重w1能减小其带来的负面影响。
3 实验方法与结果分析
3.1 实验设置
在最新DeepFashion 数据集中选取209 222 个样本用于训练,4 万个样本用于验证,4 万个样本用于测试。数据集中服装图片的类别标签有50 种,细粒度属性标签有1 000种。
进行以下比较实验:①以使用损失函数(1)为基线;②使用代价敏感损失函数,仅使用平衡加权项w1;③使用代价敏感损失函数,仅使用错误惩罚项w2;④使用代价敏感损失函数,采用平衡加权项w1和错误惩罚项w2。
3.2 实验评价
采用3 种指标评估模型性能,分别为:①精度(Precision,Pr)。表示正确预测的正例占所有预测为正例的比例;②召回率(Recall,Re)。表示预测属于某类,且真正属于该类的比例;③F1-分数(F1-score)。其为精确和召回率的加权调和平均值。将指定的类j定义为一个正实例,所有其他类定义为负实例,则指定类标签j的性能指标分别表示为:
式中:TP表示正样本且预测正确,TN表示负样本且预测正确,FP表示负样本但预测为正样本,FN表示正样本但预测为负样本。
3.3 代价敏感损失函数的消融实验
细粒度服装共有50 类。如图2 所示,各类别分布非常不平衡,图片数量为10 000 张以上的类别有6 个,由少到多分别为第33、17、32、3、18、41 类,其中第41 类图片有5万多张;有15 个类别的图片数量为1 000-10 000 等级;有14 个类别的图片数量为100-1 000 等级;有15 个类别的图片数量为0-100 等级。细粒度服装图片属性有1 000 个,而且一个图片可以有多个细粒度属性。由于数据集类别不平衡,细粒度的属性也分布极不平衡。此外,细粒度属性数量比服装类别数量更多且为多标签,因此细粒度服装属性的检索更加困难。
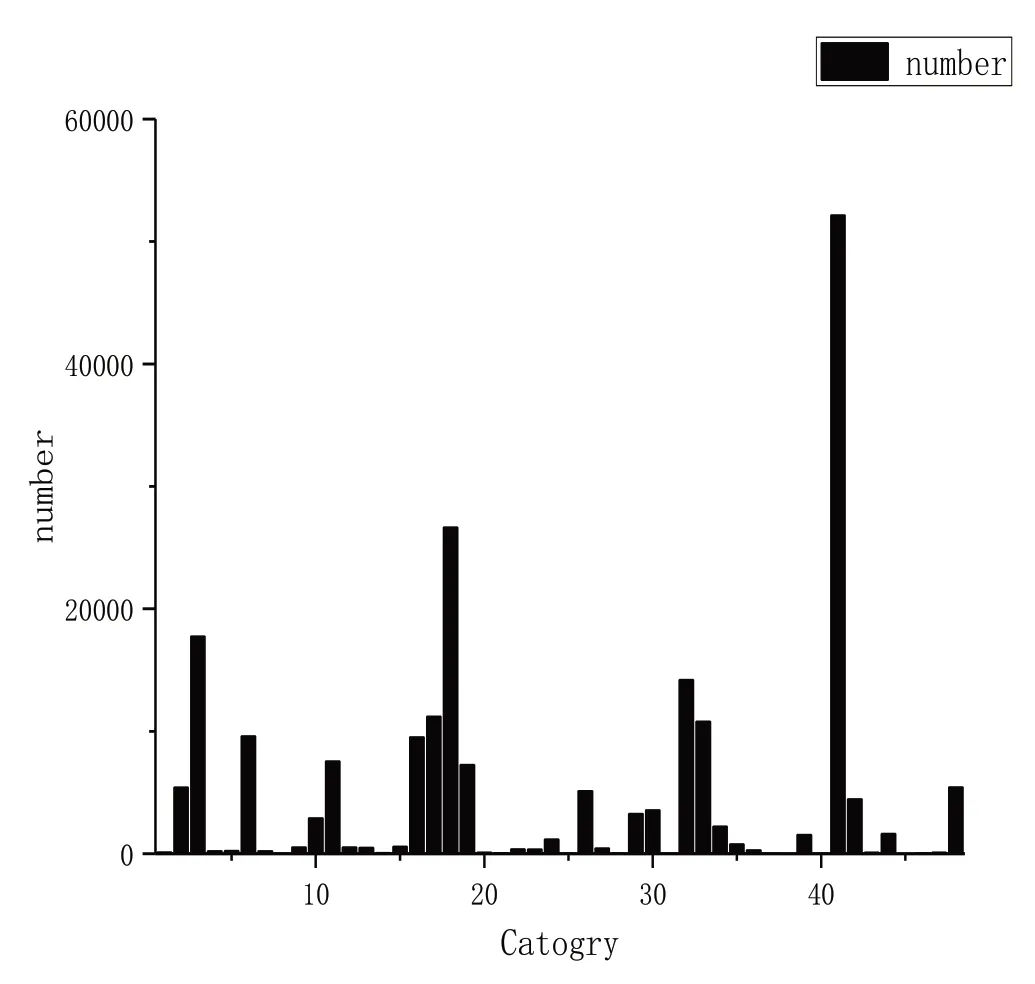
Fig.2 Fine-grained apparel category distribution图2 细粒度服装类别分布
代价敏感损失函数固定权重和动态权重的消融实验结果如表1 所示,其中Category-Average 表示服装类别的平均性能指标,Attribute-Average 表示服装属性的平均性能指标。实验结果表明,不论是使用w1加权、w2加权还是w1+w2加权,均比使用原损失函数效果好。此外,w1权重的作用大于w2权重,w1和w2权重联合使用有相互加强的作用。

Table 1 Ablation experiment of fixed weight and dynamic weight of cost-sensitive loss function表1 代价敏感损失函数固定权重和动态权重的消融实验(%)
3.4 代价敏感损失函数性能
细粒度服装图片检索模型使用不同损失函数进行实验得到的精确率、召回率、F1-分数性能指标结果如表2所示。使用到的比较损失函数包括:①二分类交叉熵损失函数(Binary Cross-Entropy Loss,BCE Loss),其特点为优化整个模型,最小化代价函数。当数据集分布不平衡时,其优化结果偏向于数量更多的类别,因此其实验结果最差;②固定权重二分类交叉熵损失函数(Weighted Binary Cross-Entropy Loss,Weighted CE),其对不平衡数据进行加权处理,与BCE loss 相比能提升数量少的类别性能;③Focal Loss 与前两个损失函数相比不仅对不平衡数据进行加权处理,还针对样本难易增加了权重控制;④本文损失函数除对不平衡数据进行加权处理外,还增加了错误惩罚项,对分类错误的样本进行动态加权,使得损失函数优化偏向于分类困难的类别。代价敏感损失函数使用固定权重和动态权重的方法处理数据集的非平衡问题,在关键点检测中通过将坐标转换为热图的方式保留图像空间特征的对应关系。因此,本文损失函数检索性能优于其他3个损失函数。
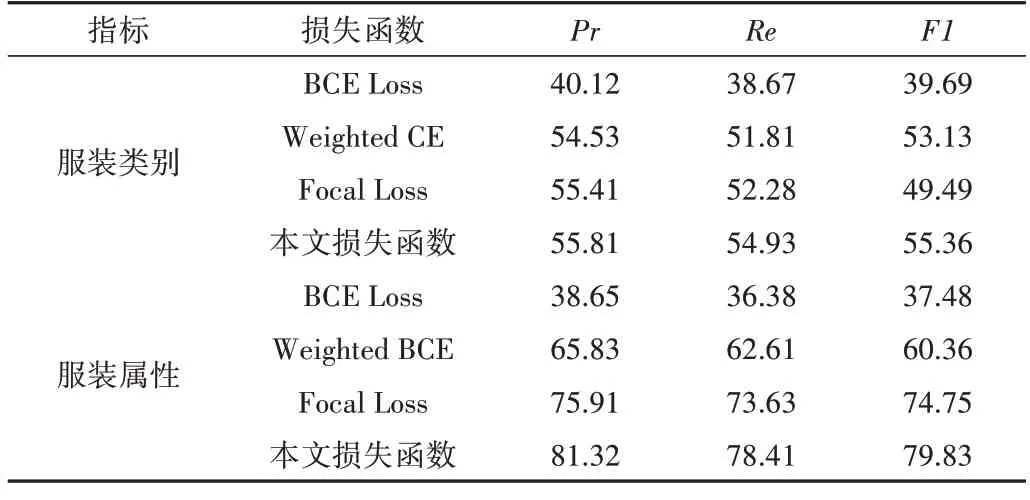
Table 2 Experimental results of using different loss functions for clothing categories and attributes表2 模型使用不同损失函数的实验结果 (%)
3.5 服装类别和属性识别性能
模型检索性能与其区分服装属性的能力有关,因此本文选择与文献[18]中的FashionNet(FN)及其相似版本进行服装属性识别比较实验,比较模型包括使用Joints 的关键点检测方法(Joints、Poselets)[28]代替FN 模型关键点检测部分模块 的FN+Joints 和FN+Poselets;使用VGG-16 与ResNet50 等替换FN 主干网络的FN-VGG16 和FNResNet50。评价指标包括服装类别、纹理、布料、形状、组件、风格等属性的预测准确率和平均准确率,结果如表3所示。可以看出,在使用top-3、top-5 准确性进行评估时,本文模型表现优于其他比较模型。

Table 3 Experimental results of models for recognizing clothing categories and attributes表3 模型识别服装类别和属性实验结果(%)
3.6 细粒度服装检索性能
将本文方法与以下细粒度检索方法进行比较:①基于局部化三联体损失的细粒度时尚图像检索(Localized Triplet Loss for Fine-grained Fashion Image Retrieval,Localized Triplet)[2];②基于自适应深度学习的细粒度文化遗产图像检索(Adaptive Deep Learning for Cultural Heritage Image,ADLCHI)[8];③三向增强的部分感知网络模型(Three-way Enhanced Part-aware Network,TEPN)[17]。表4 实验结果表明,本文方法的评价指标优于3种比较方法。

Table 4 Retrieval performance comparison of different methods表4 不同方法检索性能比较 (%)
4 结语
为提高服装图片检索效果,本文提出一种代价敏感适应加权方法,并引入代价敏感损失函数,其中加权方案基于训练数据的类频率和单个数据实例的预测难度实施,动态权重由神经网络产生的输出结果分数决定。本文损失函数在细粒度服装类别和多标签细粒度服装属性检索中展示出一致结果,表明代价敏感损失函数提升了模型性能,能有效处理数据集类别不平衡问题。如果能获取更多数据集,模型的检索准确率可能会更高。目前模型使用K-means 分类的方式加速检索过程,比传统穷举方法速度提升了许多,但检索准确率有所下降。未来可构建一个分布式检索系统,以应对大规模检索数据时速度变慢的问题。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
高技术通讯(2021年1期)2021-03-29 02:29:24
电脑与电信(2018年11期)2018-02-16 05:41:32
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
信息安全研究(2016年3期)2016-12-01 06:06:41
新校长(2016年8期)2016-01-10 06:43:59
中学生(2015年12期)2015-03-01 03:43:53
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
