
民间文学文本命名实体识别方法
2023-10-31 11:39:36黄健钰王笳辉
软件导刊 2023年10期
黄健钰,王笳辉,段 亮,冉 苒
(1.云南大学 信息学院;2.云南省智能系统与计算重点实验室;3.云南大学 文学院,云南 昆明 650500)
0 引言
民间文学是由人民群众以口头方式创作并传播,且经过不断集体修改与加工的文学,常以民间传说、民间故事、神话诗歌等形式存在。保护民间文学有利于传承中华民族的传统文化,建立文化自信。命名实体识别(Named Entity Recognition,NER)任务旨在从非结构化文本中判别实体并将其分类为预定义的语义类别(如人名、组织和位置)[1-2]。NER 技术可以快速识别民间文学文本中的关键词汇,在信息检索、自动文本摘要、问题回答等[3-4]各种自然语言处理任务中扮演着重要角色,为民间文学的保存与传播提供了技术支撑。
与通用语言文本不同,民间文学文本语言特点不一、形式混杂,对其进行NER 具有一定挑战。首先,民间文学文本中的一词多义问题突出,如语句“池塘生长着千瓣莲花”中的“千瓣莲花”表示一种物品,而语句“千瓣莲花姑娘”中的“千瓣莲花”表示角色“仙女”;语句“英勇的勐兰嘎”中的“勐兰嘎”表示一个角色,但在“勐兰嘎部落”中则表示一个组织;“赞颂”不仅为非实体动词,还在语句“他们给孩子取名叫做赞颂”中表示角色。由以上示例可以看出,如何准确识别民间文学文本中的实体及其具体类型十分困难,需要NER 模型能够在给定语境中将该类多义词判定为其正确的实体类型,从而获得高质量的实体数据。此外,民间文学文本中存在较多领域专有名词,如“俄耶”在民间文学文本中表示“阿妈”;“粑粑”表示一种饼类食物;“国哈火塔”表示“凶猛的人”;“卡”表示“毒药”。这些领域名词未采用现代汉语中的常见释义,使得通用模型难以理解其语义,从而影响实体判定,导致识别结果无法达到预期。
传统的NER 方法通常采用Word2Vec 技术[5]计算词之间的语义相似度,将文本字符转化为词向量,通过BiLSTM-CRF(Bidirectional Long Short-Term Memory-Conditional Random Fields)模型进行序列建模与特征提取并输出预测标签,难以针对一词多义问题准确划分实体类型,也难以识别具有领域特色的实体。BERT 预训练模型能够抽取文本特征,产生蕴含丰富句法与语义信息的词嵌入[6],但一般中文BERT(Bidirectional Encoder Representation from Transformers)预训练模型基于维基百科与大型书籍语料训练获得,在民间文学文本NER 中存在一定局限性,仍有改进空间。
1 相关研究
NER 技术主要分为基于规则的识别方法和基于语言模型的识别方法两大类[7]。基于规则的识别方法要求研究者对于领域知识具备一定了解,能够根据研究领域的知识特点总结出相关规则并应用于问题的解决方法中;基于语言模型的识别方法则不要求研究者具备专业领域知识,其将NER 作为一种序列标注和预测任务,通过对现有机器学习模型迁移学习后再进行识别。
在通用领域,郑玉艳等[8]利用元路径探测种子实体间的潜在特征以扩展实体集合,尝试解决最优种子的选择问题;Ju 等[9]在BILSTM+CRF 模型上叠加平面NER 层以提取嵌套实体特征,该方法对于深层次实体的识别效果较为明显;琚生根等[10]利用关联记忆网络结合实体标签信息特征以提高模型的整体分类能力,但对部分少样本实体分类效果不明显;Xu 等[11]在字符嵌入中添加汉字部首特征,获得了良好的模型表现,证实了在不同粒度中同时利用多个嵌入的有效性;武惠等[12]利用迁移学习算法缓解了模型对于少量实验数据学习能力不足的问题,以自动捕获特征的方式有效解决了领域知识的需求问题;Wang 等[13]利用已训练完成的NER 模型提取旧类数据特征以合成新数据,通过实体数据增量方法提升了模型训练效果;Nie 等[14]提出一种对语义进行扩充的方法,提升了模型对于稀疏实体的识别效果。以上方法考虑了中文通用领域知识的特点,通过提取汉字特征、实体结构特征等方式提升模型性能,而民间文学中存在着大量领域专有名词,以上方法难以识别。
在垂直领域,余俊康[15]利用交叉共享结构学习多个相关任务的特征,克服了通用模型需要大量领域标注数据的问题;杨锦锋等[16]分阶段规范标注法则,借助领域知识特点抽取中文电子病历实体关系,但该方法对实体的一致性要求较高;Li等[17]建立临床命名实体识别(CNER)模型,分别使用LSTM 和CRF 提取文本特征和解码预测标签,同时在模型中添加医学字典特征,可有效识别和分类电子病历中的临床术语;Wang 等[18]提出一个建立在BiLSTM-CRF模型基础上的多任务学习方法,通过共享不同医学NER 模型的特征提升性能;李丽双等[19]利用大量未标记的生物医学语料与医学词典进行半监督学习,获得了更深层次的语义特征信息,提高了模型性能;王得贤等[20]利用自注意力机制获取法律文书的内部特征表示,有效确定了证据名、证实内容和卷宗号等实体边界。以上方法将部分领域知识特征应用于NER 任务中,而民间文学文本一词多义问题更加突出,要求模型具备更强的分类能力,常规模型难以满足需求。
为此,针对民间文学文本中存在的一词多义与实体分类问题,本文提出TBERT-BiLSTM-CRF 模型,修改传统BERT 模型的嵌入层结构,增加实体类别标签表征,从而使词向量包含实体类别信息,增强了字符对应向量的表达能力,亦加强了模型对于实体类别的划分能力。针对民间文学文本中存在较多领域专业名词的问题,利用未标记的民间文学专有领域语料增量预训练BERT 模型,在一般中文BERT 模型的基础上添加了民间文学文本语义特征,使得模型输出更符合民间文学文本的语境。该模型的创新之处在于通过添加类型嵌入层使传统BERT 模型具备表征实体标签的能力,通过民间文学语料增量预训练进一步优化了TBERT 模型的输出,结合BiLSTM-CRF 模型根据序列依赖特征与标签约束规则输出全局最优结果,改善了传统NER 方法对于民间文学文本NER 任务的局限性。
2 TBERT-BiLSTM-CRF 模型构建
民间文学文本的NER 问题可被视作一项序列标注任务。例如,给定一段民间文学文本序列S={w1,w2,…,wn},其中wi为序列中的第i个字符(i≥1),民间文学文本NER 任务旨在准确充分地预测出该字符序列对应的标签序列L={l1,l2,…,ln},以最终识别出其中所有实体的位置和类别。本文提出的TBERT-BiLSTM-CRF模型总体框架如图1 所示,主要包括TBERT、序列依赖学习与实体识别3 个部分:①TBERT。TBERT 模型学习实体类别特征,同时利用民间文学文本语料进行增量预训练进一步优化TBERT 模型的输出,从而将输入文本转化为含有字符类型信息与文本语义信息的字符表示;②序列依赖学习。BiLSTM 模型学习序列上下文依赖特征并对序列进行建模;③实体识别。CRF 模型对序列进行解码,根据标签依赖规则输出全局最优结果。

Fig.1 Main framework of TBERT-BiLSTM-CRF图1 TBERT-BiLSTM-CRF 模型总体框架
2.1 语料预训练
预训练模型能够挖掘文本中的深层语义知识并通过语言模型进行表达,针对民间文学领域的预训练模型,若采用通用的BERT 模型则难以恰当地表达出存在着较多领域专属名词的民间文学的语境。因此本文首先利用未经标记民间文学的文本语料对BERT 进行预训练,使最终模型中的字符表示包含民间文学领域相关深层特征知识。BERT 模型采用遮蔽策略(Masked Language Modeling,MLM)以[MASK]标记对输入的字符随机遮蔽,并根据其上下文语义预测被遮蔽的词。此外,模型还针对训练语句进行预测下一句任务(Next Sentence Prediction,NSP),若输入的两个句子为前后句关系,则使用[isNext]标记,反之则以[notNext]标记,通过这种方式能够捕获句子级别的上下文关系。
设Encoder 中的参数为θ,被遮蔽的单词集合为M,输出层中MLM 任务使用的参数分别为θ1,词典为V,则模型采用负对数似然函数计算其损失。表示为:
若NSP 任务的输出层参数为θ2,预测标签集合为N,则模型计算NSP 任务的损失函数表示为:
重新训练模型将花费巨大开销,因此本文采用增量训练方式,使用BERT 模型的初始权重,在保留通用领域知识的基础上对模型进行民间文学领域知识扩展,从而使其融合民间文学文本的语义特征。
2.2 TBERT模型
民间文学文本中的同一个字符可能表示不同类型的实体。目前通用BERT 模型采用词嵌入ew、句子嵌入es与位置嵌入ep相加的方式生成文本的向量表示,其中词嵌入生成字符本身的向量,反映了其语义;句子嵌入表示当前句子的归属,使模型具备一定的文本分类能力;位置嵌入记录字符的位置信息以保证文本输入的时序性。对于民间文学文本NER 任务而言,实体类别信息作为最终的预测目标直接影响NER 结果的好坏,能否高效准确地表达字符的类别信息是NER 任务的关键所在,而通用BERT 模型无法表征实体类别信息。因此,本文提出Type based Bidirectional Encoder Representation from Transformers(TBERT)模型,利用嵌入层生成实体类别标签向量,并与文本字符向量相结合对实体类别特征进行捕获,使模型能够到学习实体类别信息,以更好地完成序列标注任务。
将文本字符与其对应的实体类别标签作为TBERT 模型的输入,利用模型原始的3 层嵌入对文本字符进行表征以生成字符向量(ew,es,ep)。该模型额外增加了一层类型嵌入,由于实体标签间不存在明显的上下文语义联系,采用One-Hot 技术对各实体及非实体类型进行统一编码并对齐BERT 模型向量,然后将实体类别向量与字符向量相加得到最终向量表示eb。公式为:
TBERT 模型堆叠使用全连接Transformer 编码器(Encoder)结构,具体如图2 所示,主要包括多头注意力机制(Multi-head Attention)、前馈神经网络(Feedforward Network)与归一化操作(Add and Norm)。

Fig.2 Framework of Transformer encoder图2 Transformer编码器结构
Attention 机制的通用表达式如式(5)所示,其中V表示输入,Q与K表示计算注意力的权重,三者由eb经过线性变换得到;dk表示Q与V的维度。通过Softmax 函数对Q与K的点积运算结果作归一化处理并乘以V获得输出向量。
多头注意力机制利用多个Attention 层计算文本语句权重以获取字符关系信息,将各Attention 层的结果整合输出。为了避免Attention 机制对于上述操作的拟合程度不够,Encoder 结构使用前馈神经网络对结果修饰,并再次归一化处理获得最终输出eb’,如公式(6)所示,其中n表示Attention 的头数,W表示权重矩阵,b表示偏置。
在BERT 预训练的基础上,利用TBERT 再次对标记字符类型数据进行微调更新,使得模型增加字符的类型信息。TBERT 结合了文本字符信息与对应实体类别标签信息的词向量,可更轻易地区分一词多义类实体。例如:“千瓣莲花”在语句1 中表示角色,在语句2 中表示物品。原始BERT 模型能够在考虑当前语境的情况下将语句1 中的“千瓣莲花”以向量v=(v0,v1,…,vn)表示,语句2 中的“千瓣莲花”以向量v'=(v'0,v'1,…,v'n)表示,但由于其未采用实体类别信息,导致两者在数值上近似而令模型难以区分。而TBERT 模型能够将实体类别标签转化为向量并叠加至原有字符向量中,扩大了v与v'的数值差距,从而有效增强了模型对于实体的分类能力。
2.3 序列依赖学习
民间文学文本NER 作为一项序列标注任务旨在输出文本序列对应的标签序列,因此利用BiLSTM 模型对TBERT 产生的词嵌入进行编码以学习序列上下文依赖特征。BiLSTM 模型由前向LSTM 层与后向LSTM 层组成,解决了循环神经网络的梯度消失问题[21],从而更适用于民间文学中长文本的编码工作。
如式(7)、式(8)、式(9)、式(10)所示,LSTM 网络使用细胞状态记录当前最重要的信息,同时利用遗忘门ft与输入门it控制中信息的更新,通过Sigmoid 函数σ将输出值控制在0~1之间,其中0表示完全舍弃,1表示完全保留。
式中:W表示权重矩阵,b表示偏置量,t表示时刻,ht-1表示t-1 时刻的隐藏状态,xt表示t时刻的输入,ot表示输出门。
根据细胞状态,利用tanh 函数确定最终的输出值ht。计算公式为:
最后将双向LSTM 层的结果进行拼接作为CRF 层的输入进行解码操作。
2.4 实体识别
BIO(Begin-Inside-Outside)标注规则中,“I-X”标签只可能存在于实体的中间位置,不可能出现在实体的开头或单独出现。若仅使用一个线性层选取BiLSTM 输出中概率最高的标签作为最终结果,则很可能产生不合理的序列,如“B-CHA O O I-CHA”。因此,本文利用CRF 模型对BiLSTM 层的输出进行修正并计算出全局最优序列[22]。
对于给定的输入h=(h0,h1,…,hn),其对应的预测输出标签L={l0,l1,…,ln}的得分计算公式为:
PR(L|h)为h的预测结果为L的概率,计算公式为:
式中:L'为真实标签,Lh为所有可能存在标签组合。
在最终预测阶段,根据式(15)输出最优结果:
2.5 算法描述
本文提出的TBERT-BiLSTM-CRF 模型在BERT 模型利用未经标记的民间文学文本语料进行增量预训练的基础上,通过字符类型嵌入并再次优化产生含有字符类型信息与文本语义信息的字符表示,然后由BiLSTM 模型进行序列依赖学习,经CRF 模型预测输出最优结果。该模型算法具体步骤为:
输入:原始未标记民间文学文本语料,BERT 模型,带类型标记数据
S={w1,w2,…,wn'}:句子
输出:L*:句子对应标签序列
3 实验方法与结果分析
3.1 数据集
本文使用的民间文学文本语料包括《千瓣莲花》、《傣族文本》、《娥并与桑洛》与《云南少数民族古典史诗全集》,字数信息如表1所示。

Table 1 Word count for the corpus of folk literature texts表1 民间文学文本语料字数信息
由于民间文学文本语料规模庞大且需要人工标注,且以上4 则文本在内容与形式上具有相似性,挑选其中1 824句能够反映民间文学文本一词多义等特点的语句,利用BIO 标注的方式产生数据集,共计5 921 个标签。人名(PER)、地点(LOC)与组织(ORG)是3 种广泛应用于NER任务的标签,其同样适用于民间文学的NER 工作。考虑到民间文学中不仅会出现人名,还会有许多拟人化的动植物角色,因此将PER 替换为角色(CHA)。此外,民间文学中描述了一些对于剧情发展具有推动作用的“宝物”,本文对该类实体也进行了标注,并用物品标签(OBJ)表示。表2为序列标签集。数据集以8∶2 的比例随机划分为训练集与测试集,其中语句和各类实体的分布情况如表3所示。
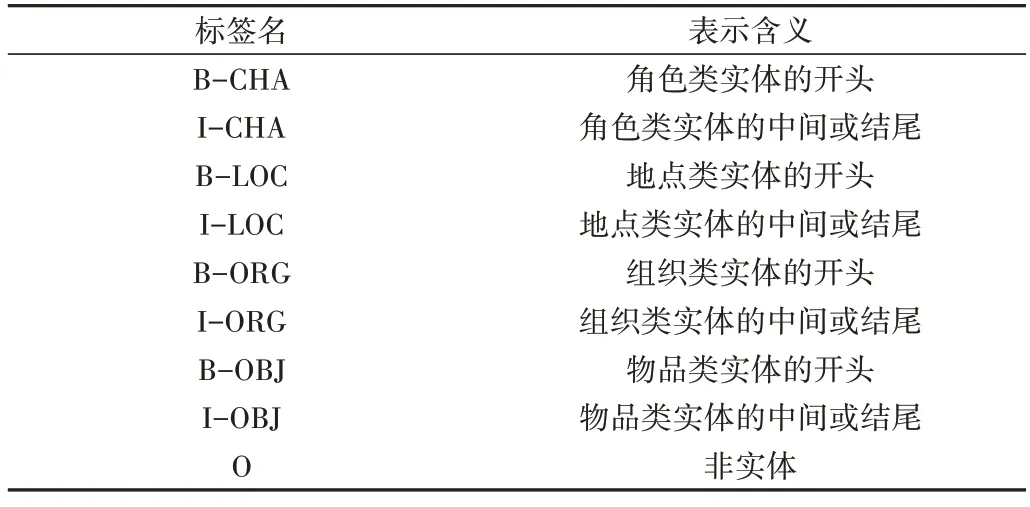
Table 2 The sequence labels表2 序列标签集

Table 3 Statistics of the datasets表3 数据集统计信息
3.2 评价指标
NER 任务旨在识别出文本中的预定义语义类别,能否准确全面地进行识别在NER 模型性能评价中占据重要地位,因此本文使用准确率P、召回率R与F1 值评价实验结果。计算公式分别为:
式中:Np表示模型识别的正确实体数量,NA表示测试集中的实体数量,NF表示模型识别的实体数量。P、R和F1取值范围均为0~1,其值越大越好。
3.3 实验平台与参数设置
实验平台为Intel(R)Xeon(R)CPU E5-2650 v3 @2.30GHz 处理器,RTX 2080Ti GPU,256 GB 内存,Ubuntu20.04.1 操作系统,Python 3.6 语言,Tensorflow-gpu 1.11.0框架。
预训练在chinese_L-12_H-768_A-12模型的基础上进行,民间文学文本数据经处理后生成tf.record 文件。同时设置最大句子长度为128,batch_size 为32,学习率为2e-5进行训练。模型参数设置见表4。

Table 4 Model parameter settings表4 模型参数设置
3.4 实验结果与分析
3.4.1 不同模型比较
在民间文学数据集上对本文模型(TBERT-BiLSTMCRF)与目前广泛应用于NER 任务的BERT-BiLSTMCRF[17]、BiLSTM-CRF[18]、BiLSTM[21]、CRF[22]模型的表现进行比较,结果见表5。可以看出,将CRF 与BiLSTM 结合后,3 项评价指标相较单独结构均有明显提高;在此基础上添加一般中文语料BERT 预训练模型后,3 项指标比BiLSTM-CRF 模型分别提高了1.15%、2.24%、1.75%;将一般中文语料BERT 预训练模型更换为本文方法生成的TBERT模型后,相比BERT-BiLSTM-CRF 3 项指标分别提高了3.61%、2.14%、2.89%。说明同时利用民间文学的语义特征与实体类别特征可使模型理解民间文学的领域知识并加强对实体的划分,从而在识别出更多实体的同时确保分类的准确率。

Table 5 Experimental result comparison of each model表5 各模型实验结果比较
比较TBERT-BiLSTM-CRF、BiLSTM-CRF、BERT-BiLSTM-CRF 3 种模型对民间文学数据集中4 种不同类型实体的准确率、召回率与F1值,结果见表6、表7、表8。

Table 6 Precision comparison of each model for different entity categories表6 各模型对不同类型实体识别准确率比较 (%)
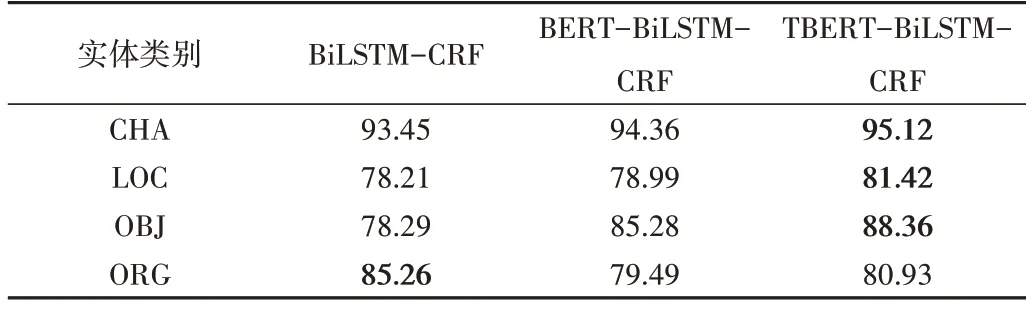
Table 7 Recall comparison of each model for different entity categories表7 各模型对不同类型实体召回率比较 (%)
由表6 可知,TBERT-BiLSTM-CRF 模型对各类实体识别的准确率均优于其他模型约2%,说明利用标签信息能使模型更好地区分一词多义类实体,使识别更加准确。
由表7 可知,TBERT-BiLSTM-CRF 模型对3 类实体的召回率超出其他模型0.7%~3%,表现优异。
由表8 可知,TBERT-BiLSTM-CRF 模型对各类实体识别的F1 值均超过其他模型1%~5%。由于F1 值的计算综合考虑了模型识别准确率与召回率,说明TBERT-BiLSTM-CRF 模型较目前广泛使用的NER 模型能够更准确完整地识别出民间文学文本中存在的实体。
3.4.2 案例分析
以下列举了BiLSTM-CRF、BERT-BiLSTM-CRF 模型与TBERT-BiLSTM-CRF 模型对于民间文学文本具体句子案例的识别结果,其中加粗部分表示模型识别的实体,括号内记录其对应的类型。
(1)BiLSTM-CRF 模型。国王(CHA)的第七个姑娘她说的每一句话会变成一朵千瓣莲花(OBJ)漂在天上,喷发出馥郁的清香,世上千万个美丽的姑娘我一个也不看在心上,我单单爱上千瓣莲花(OBJ)姑娘,我真有福气能来到与莫板森林(LOC)遇见美丽的莲花(OBJ)姑娘。
(2)BERT-BiLSTM-CRF 模型。国王(CHA)的第七个姑娘她说的每一句话会变成一朵千瓣莲花(OBJ)漂在天上,喷发出馥郁的清香,世上千万个美丽的姑娘我一个也不看在心上,我单单爱上千瓣莲花(OBJ)姑娘,我真有福气能来到与莫板森林(LOC)遇见美丽的莲花(CHA)姑娘。
(3)TBERT-BiLSTM-CRF 模型。国王(CHA)的第七个姑娘她说的每一句话会变成一朵千瓣莲花(OBJ)漂在天上,喷发出馥郁的清香,世上千万个美丽的姑娘我一个也不看在心上,我单单爱上千瓣莲花(CHA)姑娘,我真有福气能来到与莫板森林(LOC)遇见美丽的莲花(CHA)姑娘。
可以看出,BiLSTM-CRF 模型利用Word2Vec 技术生成的词向量较为单一,导致涉及“莲花”的实体皆判断为物品,且其因缺少民间文学领域知识而未将实体“莫板森林”完整地识别出来。这个问题同样出现在BERT-BiLSTMCRF 模型的识别结果中,该模型虽然能够根据上下文将“莲花姑娘”中的“莲花”正确判断为角色,但对于文字表述上完全相同的两个“千瓣莲花”并没有进行区分而均判断为物品。TBERT-BiLSTM-CRF 模型因融合了民间文学的语义特征与实体类别特征,在实体识别的准确度方面表现良好。
嵌套类实体会对TBERT-BiLSTM-CRF 模型造成干扰,如表9 中的案例1 与案例2 所示,其分别为地名嵌套角色名实体与组织名嵌套角色名实体。对于前后文关系紧密的民间文学文本,若前后文割裂输入进模型,则模型难以根据前后文判断出实体的正确类别,如表9 中的案例3所示。

Table 9 Error analysis表9 错误分析
4 结语
本文针对民间文学文本领域名词众多和一词多义的特点提出TBERT-BiLSTM-CRF 模型,将民间文学的语义特征与实体类别特征融入一般中文BERT 模型,使其具备识别具有领域特色实体与多重词义实体的能力;同时结合BiLSTM 模型与CRF 模型,根据上下文信息与序列间存在的强依赖关系使模型获得全局最优结果。与经典模型CRF、BiLSTM、BiLSTM-CRF 与BERT-BiLSTM-CRF 相比,本文模型在民间文学文本数据集上获得了最高的准确率、召回率与F1 值。然而,本文仍存在一定不足:一方面是并未构建较为完备的民间文学文本数据集,另一方面是模型效果未在其他领域数据集中得到验证。未来将进一步探索完备数据集上的领域知识NER 工作。
猜你喜欢
苏州教育学院学报(2022年2期)2022-06-27 07:40:34
电脑爱好者(2022年15期)2022-05-30 01:29:23
苏州教育学院学报(2022年1期)2022-05-06 04:30:16
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
活力(2019年22期)2019-03-16 12:48:04
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
阅江学刊(2015年5期)2015-06-22 11:05:13
