
基于流量特征的区域互联网攻击源IP地址检测
2023-10-28 10:25徐胜超毛明扬王宏杰
计算机测量与控制 2023年10期
杨 波,徐胜超,毛明扬,陈 刚,王宏杰
(广州华商学院 数据科学学院,广州 511300)
0 引言
随着经济发展的数字化转型和5G技术的发展,当前很多企业在云上部署业务,不仅业务更方便,同时大大减轻了企业的负担,这样就加快了经济的发展。利用“云”的方式来实现网络入侵检测、网络异常流量检测、负载均衡、物理主机资源充分利用、尽最大可能节省数据中心的能量消耗,符合国家节能减排的主要政策。
当数据上云后,能否很好地开展业务,云任务在复杂系统中的运行,在传输数据时是否会被窃取,延迟很高导致传输速度很慢等等问题,就是一直存在的。为了保证云网的安全稳定运行,减少入侵风险,如果我们将安全防护策略部署在云端,可以有效减低企业维护安全设备软硬件的人力物力资源,安全平台提供开放的接口标准,快速的实现零门槛的安全软件/硬件部署,实现企业网络安全防护。
为了实现满足云安全服务长期稳定可靠运行需求、监管合规、建设安全运营平台,实现云安全“可视”、“可控”。城域网区域互联网攻击源IP地址检测是云安全中的一个重要的研究方向[1]。目前,许多研究人员通过分析网络流量数据来检测互联网攻击源IP地址[2]。然而,传统的基于规则和特征的检测方法存在一定的局限性,比如需要事先定义规则或特征,并且对新型攻击的检测能力较弱。因此,基于机器学习和数据挖掘技术的检测方法逐渐成为研究热点[3]。
互联网攻击源检测在识别攻击和确保计算机网络安全方面发挥着重要作用。基于该问题,很多专家和学者依据各种算法提出了检测方法。例如文献[4]为了有效识别网络环境中大量网络流中未知的恶意攻击行为,提出了一种基于人工免疫网络与密度峰值(ADAID,artificial immune network and density peak)的检测方法,研究中引入了聚类标记算法和流异常检测算法,利用前者标记每个簇是否恶意,并将标记的簇视为检测器,利用后者识别攻击网络流量。文献[5]提出了一种基于人工神经网络的攻击检测方法,使用NS2网络模拟器收集网络流量并创建数据集,然后以此为输入,利用人工神经网络实现不同的DoS攻击检测。文献[6]提出了一种基于隐马尔可夫模型改进算法的攻击检测方法,研究中为了提高算法的学习能力和适应性,利用Baum-Welch算法改进隐马尔可夫模型,最后利用优化维特比算法检测攻击行为。文献[7]提出基于XGBoost回归分类器的网络攻击行为检测方法,该方法首先对XGBoost回归分类器的工作原理进行说明,采集网络运行中的各项数据,将采集的数据输入到XGBoost回归分类器中,实现分布式拒绝服务、网络钓鱼、跨站点脚本攻击的检测。文献[8]提出基于半监督学习的无线网络攻击行为检测方法,通过无监督学习模型栈式稀疏自编码器提取网络流量的新特征值向量与原始特征权重向量,将提取的两类向量输入到深度神经网络中进行迭代训练。采用k-means聚类方法对训练输出结果进行聚类处理,完成网络攻击的识别。
以上5种研究方法在攻击检测中都发挥了一定的作用,但是随着网络攻击朝着隐蔽性、复杂性、多步骤等方向发展,如果不考虑网络流量特征,则会降低攻击源的检测精度。针对上述问题,本文提出一种基于流量特征的区域互联网攻击源IP地址检测方法。
1 区域互联网攻击源IP地址检测
当下攻击方式具有很强的随机非线性、欺骗性、伪装性,使得要想准确定位攻击源IP地址困难[7]。面对这种情况,为了抵御恶意攻击者的恶意攻击,研究一种基于流量特征的区域互联网攻击源IP地址检测方法,检测方法的主要内容包括IP网络流量采集、IP网络流量预处理、流量特征提取以及攻击源IP地址检测实现。下面针对上述步骤进行具体分析。
1.1 IP网络流量采集
攻击源检测需要依据一定的数据来确定某一用户存在攻击行为,然后针对这一行为进行追踪,定位攻击源IP地址,完成攻击溯源[8]。从上述整个过程中可以看出依据数据是基础,后续所有检测步骤都是围绕该数据进行挖掘和分析,最终得出结果。基于此,依据数据的获取至关重要。依据数据类型主要有两种:一是互联网日志,二是网络流量[9]。在本研究中,选择后者作为基础。采集方法为NetFlow技术,采集具体过程如图1所示。
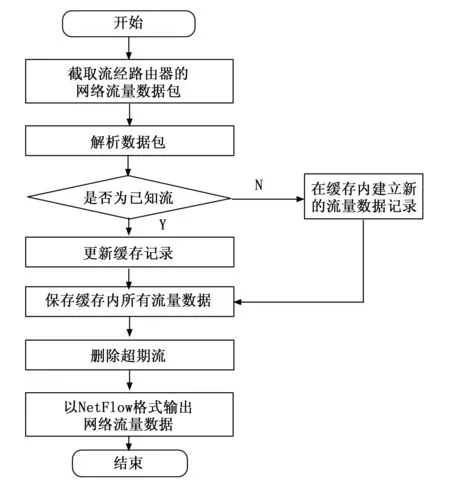
图1 IP网络流量采集流程
任何用户在进入互联网后,一切操作都会产生一定数据流量。数据流量会随着操作行为的不同而表现出差异性。基于此,只要把握住这种差异性就能反向观察用户行为,判断其是否存在攻击行为[10]。
1.2 IP网络流量突变预处理
网络流量数据具有一定的突变性特征,该特征主要是用户设备和互联网连接异常造成的,这种流量数据的存在很容易与攻击用户所产生的流量数据混淆,二者十分相似,因此会干扰检测结果准确性[11]。面对这种现象,需要找出其中的突变网络流量数据,提高IP网络流量数据质量。具体过程如下:
步骤1:输入IP网络流量数据;
步骤2:通过互补聚合经验模态分解(CEEMDAN,complete EEMD with adaptive noise)方法对IP网络流量数据分解,得到k个子序列IP网络流量,记为S={si|i=1,2,...,k}。
步骤3:计算S中每个子序列的分散熵,记为bi;
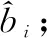
步骤6:将ci与设定的均值变化率阈值T进行对比。当ci≥T时,将第i个子序列归入去突变模态集合;否则将第i个子序列归入保留模态集合。
步骤7:参照根据CEEMDAN的分解规律,将去突变模态集合中的子序列IP网络流量划分为高、中、低频三类。
步骤8:对其中的高频部分进行舍弃,对其中相对中频子模态利用小波阈值方法去除突变网络流量数据,低频部分则保持不变,不进行任何处理[12]。
步骤9:将低频部分与去除突变后的低频部分进行重构,完成IP网络流量突变预处理。
经过上述流程,完成IP网络流量突变预处理,避免了突变流量数据带来的干扰[13]。
IP网络流量突变预处理流程如图2所示。
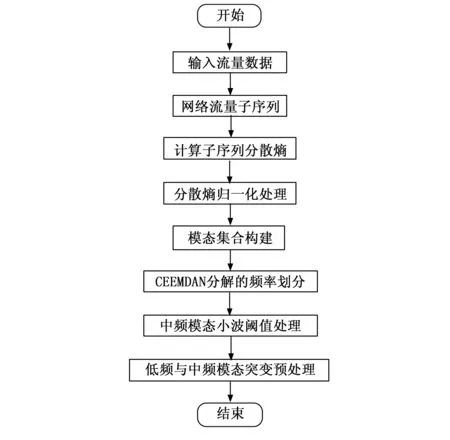
图2 IP网络流量突变预处理
1.3 流量特征提取
根据1.2节中的处理结果,本节正式进入数据分析环节。IP网络流量中包含了很多特征参数,如表1所示。
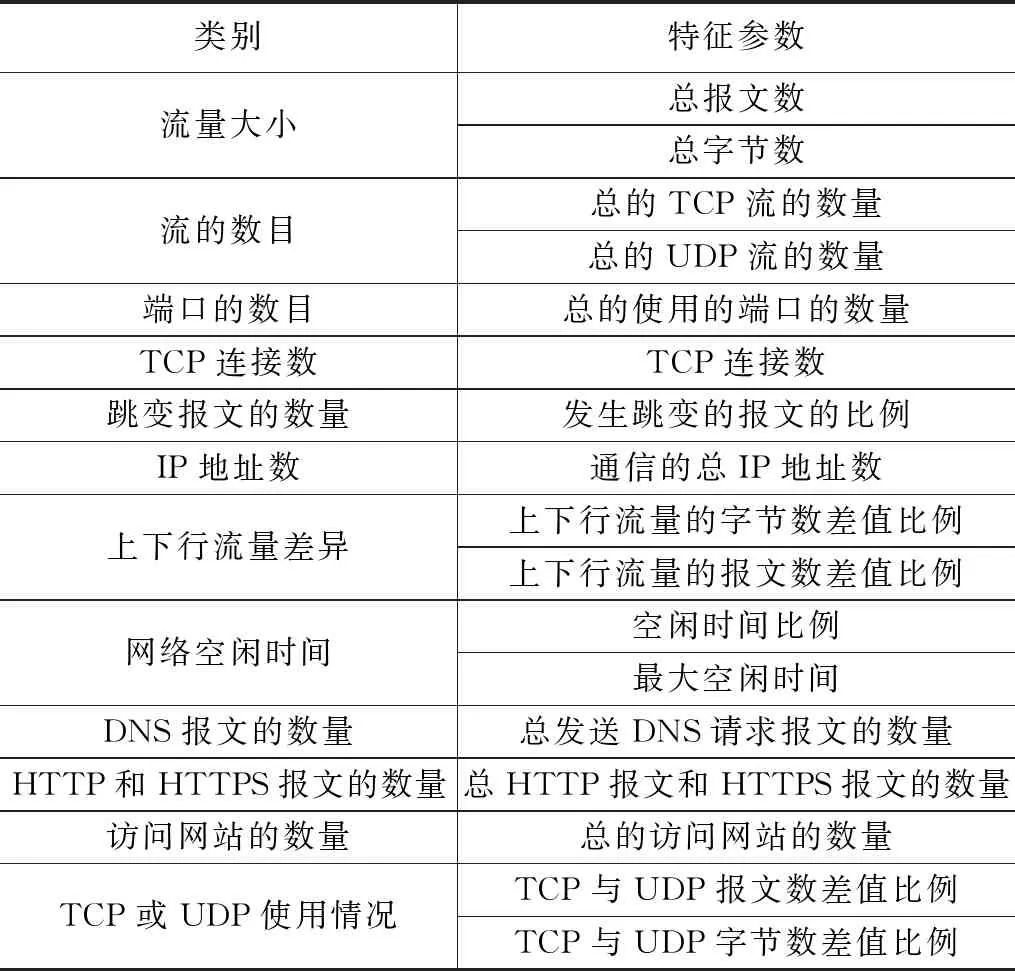
表1 IP网络流量数据特征参数表
从表1中可以看出,IP网络流量中特征参数有很多,虽然都可以用于最后的攻击源检测,但是过多的特征参数不仅会大大增加后期检测工作的计算量,而且对提高检测精度并没有太大的帮助[14]。针对这种情况,只要从上述表1中选出N个最优特征参数就可以。在这里N取值4[15]。通过计算最小冗余最大相关性,选取排名前4的特征参数,具体选取流程如下:
步骤1:计算第i个特征参数pi与类别Q之间,特征参数pi和pj之间的互信息值,记为R(pi,Q)、W(pi,pj)。
步骤2:计算R(pi,Q)、W(pi,pj)的平均值,公式如下:
(1)
式中,P代表特征数量。
步骤3:计算最小冗余最大相关性。计算公式如下:
(2)
式中,Gi代表第i个特征参数的最小冗余最大相关性。
步骤4:按照从大到小的顺序排列Gi。
步骤5:选取Gi值排前4的特征参数作为选取结果。
计算4个流量特征的信息熵值,统一参数值[16]。熵值计算公式如下:
(3)
式中,Hi代表第i个网络流量特征的熵值;g(Gi)代表Gi出现的概率。
经过上述过程,完成了流量特征的选择工作,为攻击源IP地址的精准检测奠定基础。
1.4 攻击源IP地址检测实现
攻击源IP地址检测是本研究的最后一部分,该部分的工作主要分为两步:攻击流量检测和攻击源IP地址定位[17]。下面将对这两个步骤进行具体分析与研究。
1.4.1 攻击流量检测
攻击流量检测是指基于网络流量数据特征判断是否存在攻击流量[18]。结合极限学习机与k均值算法来构建攻击流量监测模型,攻击流量监测模型的结构如图3所示。
为了进一步攻击流量检测的精度,基于极限学习机和k均值算法进行攻击流量检测。首先利用k均值算法对原始数据进行聚类分析,将数据划分为不同的簇;然后,将每个簇的数据作为输入,利用极限学习机算法进行分类预测。通过不断迭代优化,可以得到一个精度较高的分类模型,用于对未知数据进行分类识别。其具体流程如下:
步骤1:设定攻击流量检测模型的相关参数。
步骤2:构建极限学习机。
步骤3:确定K-Mean算法中的近邻数。
步骤4:输入训练样本到极限学习机当中,经过三层处理,在映射函数的帮助下,将网络流量特征训练样本(信息熵)映射到L维特征空间中[19]。
步骤5:执行k均值算法检测流程。具体如下:
1)从L维特征空间中选取初始聚类中心,选取数量为M。
2)计算其余所有特征矢量与M个初始聚类中心之间的加权距离D,计算公式如下:
(4)
式中,Oj表示第j个聚类中心;N表示特征数,这里取值4;wi表示特征对应的权值,取值一般在0~1之间,由于本研究有4个特征参数,这4个特征参数合计需要等于1。
3)根据D将特征矢量分配到某一类。在这里主要是指两类,一类为正常,一类为攻击。
4)更新聚类中心。
5)中心是否发生变化?若发生,回到步骤2);否则,停止并输出检测结果[20-23]。
1.4.2 攻击源IP地址定位
在完成攻击流量检测之后,进行攻击源IP地址定位。具体过程如下:
步骤1:通过水印添加器在检测出来的攻击流量中嵌入水印。水印添加器可以直接在攻击流量中嵌入目标水印,不需要额外进行操作,可以在确保水印嵌入可靠性的基础上,提高水印嵌入的效率[24-27]。水印添加器添加水印的流程如图4所示。
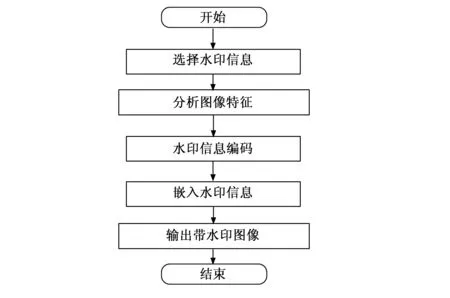
图4 水印添加器添加水印的流程图
步骤2:依据嵌入的水印得到一条从发送端到终点站的流量传输路径。
步骤3:对路径进行追踪并实时提交提交本机(IP,检测时间戳,水印参数名)。
步骤4:通过定位到的用户服务器的IP地址,可以实施防御策略,以击退攻击并保护网络安全。
2 实验与性能分析
为保证本文检测方法的实际应用效果,在设置的算例下,进行攻击源IP地址检测测试。为进一步凸显该方法性能,与基于ADAID、人工神经网络、改进隐马尔可夫模型的检测方法应用结果进行对比。
2.1 实验环境
实验采用某个区域互联网作为模拟测试环境,通过极限学习进行预测建模,再采用均值算法对数据进行挖掘,并最终通过水印添加器对其进行数字版权和内容安全保护。在该环境中,共有1153个网络用户,其中321个用户为网络攻击用户,其余用户为合法上网用户。
2.1.1 实验参数设置
K-mean算法的参数设置如表2所示。
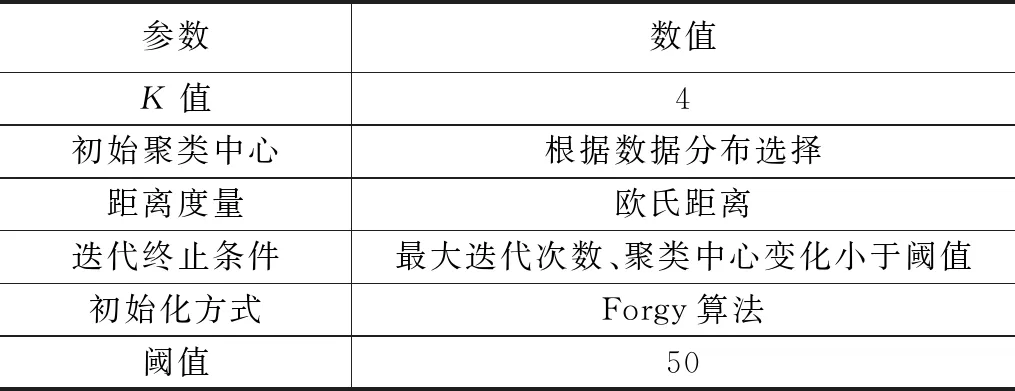
表2 K-mean算法的参数设置
极限学习机方法的参数设置如表3所示。

表3 极限学习机方法的参数设置
2.1.2 实验软件与硬件设置
1)软件设置:
(1)操作系统:选择Windows10的操作系统。
(2)网络安全软件:安装防火墙、入侵检测系统(IDS)网络安全软件来保护实验环境。
(3)流量分析工具:使用Wireshark工具对流量进行抓取和分析。
(4)信息采集:在网络用户的终端设备内安装NetFlow软件,采集这些用户为期30天的网络流量数据。
2)硬件设置:
(1)网络设备:交换机、路由器等用于构建实验网络环境,并保证流量传输的稳定。
(2)流量生成工具:使用流量生成器模拟的攻击流量,用于实验测试。
实验共计3 000多条记录,每条记录包含3个特征和1个类别标签。以其中1条流量数据为例,数据样本如图5所示。

图5 网络流量示例
对于网络流量中的每条正常流量数据和攻击流量数据,根据已知的攻击类型对数据包进行匹配和标记。每条流量数据将被标记为攻击包或非攻击包。为了消除数据偏差,在要输入数据来训练检测模型时,将所有攻击数据包与随机数目的合法数据包混合,然后重新采样以获得训练模型的输入数据。
2.2 相关性测试结果
为了从较多的流量特征参数中,选取出与攻击源IP地址检测最为相关的特征,并减少后续的计算量,通过最小冗余最大相关性Gi来进行流量特征参数的选择。最小冗余最大相关性Gi的计算结果如表4所示。
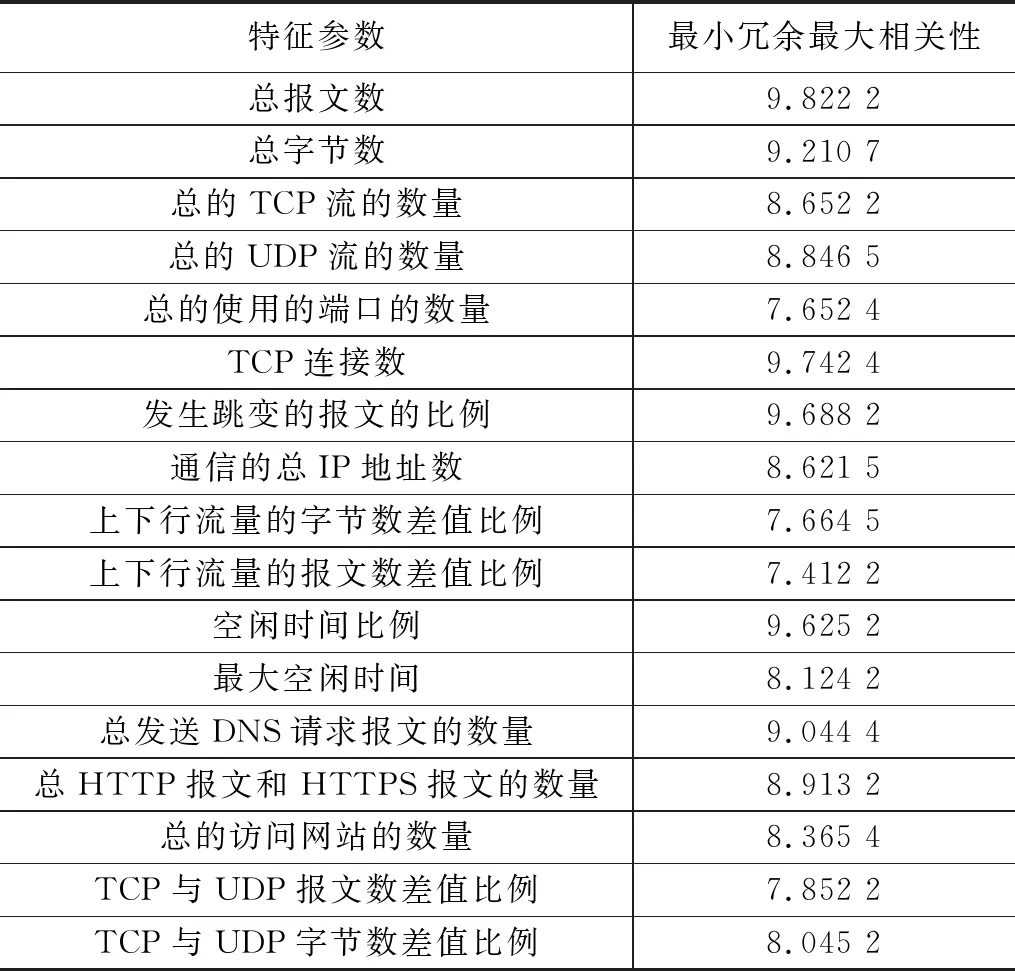
表4 网络流量数据特征参数的最小冗余最大相关性表
从表4中可以看出,结合本文方法的优点,可以对选出的4个流量特征进行丰富。以下是一个具体的描述:根据最小冗余最大相关性的排序结果,本文选择了总报文数、TCP连接数、发生跳变的报文的比例以及空闲时间比例作为关键的流量特征。这四个特征的选择是基于本文方法的优点来进行的。首先,总报文数作为一个基本的统计特征,可以提供关于流量负载的整体信息。它能够反映网络中数据包的总体流量情况;其次,TCP连接数是一个重要的指标,用于衡量潜在的攻击行为。攻击者通常会引发大量的非正常或恶意的TCP连接,因此监测和分析TCP连接数可以有效检测和识别攻击行为;第三,发生跳变的报文比例是一个针对网络流量异常变化的特征。异常的报文跳变可能表示网络中出现了异常事件或攻击行为。通过监测和分析该比例,可以快速发现网络中的可疑活动;最后,空闲时间比例是一个与网络利用率和活动程度相关的特征。攻击者可能会利用网络的空闲时间来进行攻击,因此监测和分析空闲时间比例可以帮助识别潜在的攻击行为。通过选取这四个流量特征,可以充分利用最小冗余最大相关性的方法,在保持簇间相关性最小且簇内相关性最大的同时,捕获到网络流量数据中的关键信息,从而提高攻击源IP地址检测的准确性和效果。
2.3 特征信息熵的测试结果
针对选出四个最优网络流量特征,计算每条网络流量数据的信息熵。随机选取10条作为示例,其信息熵统计结果如表5所示。
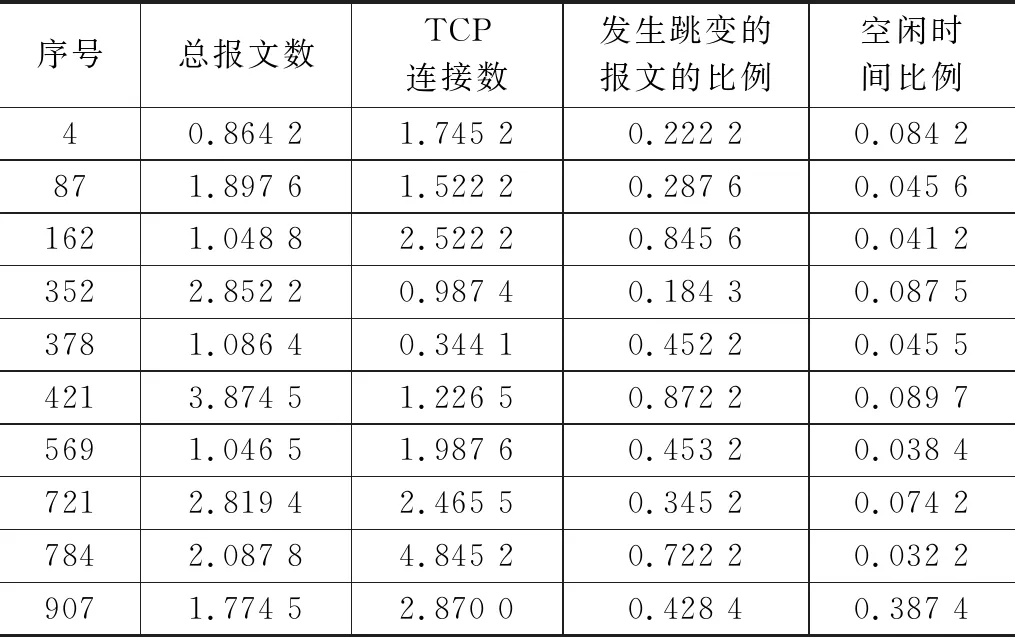
表5 特征信息熵示例表
分析表5可知,信息熵越高表示流量数据中的不确定性和复杂性越大。通过计算信息熵,可以量化每条流量数据的信息量大小,从而更好地理解其在整体数据集中的重要程度。根据实验结果,观察到不同流量数据的信息熵有所差异。这意味着某些网络流量数据可能包含更多的信息,对于识别攻击源IP地址具有更高的潜力。通过进一步分析和挖掘这些高信息熵的流量数据,可以更好地理解网络中的异常行为,并提高对潜在攻击的检测能力。通过计算选定网络流量特征的信息熵,可以更深入地了解流量数据的信息量,并为后续的攻击源IP地址检测工作提供有价值的参考
2.4 检测质量实验对比分析
应用本文方法、基于ADAID的检测方法、基于人工神经网络的检测方法、基于改进隐马尔可夫模型的检测方法进行互联网攻击源IP地址检测。根据计算结果,计算检测质量指数,公式如下:
(5)
式中,Y代表正确检测出来的攻击源IP地址数;J代表检测质量指数;U代表用户IP地址总数;X、Z代表方法检测出来和实际攻击源IP地址数目。当J越大,认为检测准确性越高。结果如图6所示。

图6 检测质量指数对比图
从图6中可以看出,基于ADAID的检测方法的质量指数为0.83,基于人工神经网络的检测方法的质量指数为0.65,基于改进隐马尔可夫模型的检测方法的矢量指数为0.68,均低于本文方法。本文方法的检测质量指数为0.97,说明本文方法的检测准确性更高。本文方法具有较高的检测质量指数的原因在于采用了NetFlow技术对区域互联网中的IP数据流进行采集,并在最小冗余最大相关性的约束下提取了流量特征。将流量特征的信息熵输入到极限学习机中,通过k均值算法确定互联网攻击源的IP地址。
3 结束语
为了能够有效阻止攻击,保护数据安全,进行基于流量特征的区域互联网攻击源IP地址检测研究。该研究以访问用户的流量数据为基础,通过提取流量特征,利用检测模型实现攻击流量检测,确定攻击地址,为防御策略提供了重要的参考。在未来的工作中将尝试在具有真实网络流量的网络环境中实施此方法,进一步验证方法的有效性。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
微型电脑应用(2021年3期)2021-03-31
铁道通信信号(2020年11期)2020-02-07
网络安全和信息化(2018年3期)2018-03-03
制造技术与机床(2017年11期)2017-12-18
北京航空航天大学学报(2017年7期)2017-11-24
黑龙江电力(2017年1期)2017-05-17
科学中国人(2017年14期)2017-01-28
