
基于嵌入式注意机制的目标语音提取算法
2023-10-28 10:47:20郭志楷杨明堃蒋国峰刘欢欢马红强
计算机测量与控制 2023年10期
郭志楷,杨明堃,蒋国峰,陶 祁,刘欢欢,马红强
(空军工程大学航空机务士官学校 航空电子工程系,河南 信阳 464099)
0 引言
单声道语音分离是将说话人语音信号从混合语音中分离出来,也被称为鸡尾酒会问题[1]。人类的听觉系统可以很容易的从混合语音中分离感兴趣的源信号,但是这对于计算机识别系统来讲并不容易,尤其是在单声道情况下,提取目标语音非常困难。因而关于语音信号处理的大多数研究都集中在单声道语音分离(SCSS,single channel speech separation)[2-4]。非负矩阵分解(NMF,nonnegative matrix factorization)[5]和计算听觉场景分析(CASA,computational auditory scene analysis)[6]都是SCSS的常用方法。在文献[5]中,NMF为每个源都训练一个非负基的集合,以此来进行语音分离。在文献[6]中,CASA由语音的客观质量评估(OQAS,objective quality assessment of speech)指导,解决了语音质量与分离过程相结合的问题。但是对于多个说话人混合的语音,NMF和CASA取得的分离效果有限。
近几年,深度学习技术在很多领域都得到了很好的应用。随着深度学习技术的发展,研究学者们已经提出了很多基于深度学习的语音分离方法[7-10],SCSS技术取得了很大的进步。基于深度神经网络(DNN,deep neural network)的语音分离通常在以下3种情况下应用:1)声音与乐器之间的分离;2)多个说话者的分离;3)嘈杂语音的分离。基于DNN的单声道语音大体可分为两种主要形式,第一种是将混合信号的特征直接通过DNN映射到源信号的特征[11],第二种是将混合信号映射到各种频谱掩蔽,以解释混合信号中每个源的贡献。众多研究表明,二进制掩蔽相比较比例掩蔽分离性能低,比例掩蔽表示混合信号中源信号所占的真实能量比[12]。大多数关于混合语音的分离研究,都是针对所有源信号的分离。然而在实际情况下,例如,单个扬声器向个人移动设备发出语音查询,或者自动语音识别设备对说话人的语音识别,在这些场景下更倾向于恢复单个目标扬声器,同时降低噪声和干扰扬声器的影响,这个问题被定义为目标说话人提取[13-14]。与语音分离相比,提取目标说话者可以有效解决置换不变训练(PIT,permutation invariant training)[15]、说话者数量未知的说话人跟踪等问题。当网络仅专注于目标说话者语音提取时,总体分离性能可能会更好。
大多数针对提取目标说话人的研究,都是在目标说话人语音基础上只训练一个神经网络,以此建立专门用来提取说话人的模型[16-18]。在这些提取模型的训练过程中,目标说话者和干扰者的语音都被使用,而训练的目的只是为了估计目标说话人的掩蔽,单一的网络难以充分考虑语音样本的深度特征。
Zhao等人[19]发现频谱映射在去混响中比时频掩蔽更有效,而掩蔽在去噪和分离方面比频谱映射更好。因此构造了两个阶段的DNN,其中第一阶段执行掩蔽去噪,第二阶段执行频谱映射去混响。受此启发,利用这两种方法的优点,可以开发一个包含频谱特征映射分离和掩蔽提取功能的框架,可在目标说话人提取过程中同时融入这两种方法的优势[20]。与单一网络相比,联合网络识别目标语音的精度更高[21]。
本文着重进行了目标说话人语音提取研究,提出了一个包含语音分离和提取相结合的注意机制模型,基于语音数据的迭代训练过程,仿真了模型训练的收敛性,利用训练好的网络模型进行了目标说话人语音提取实验,并给出部分实验的处理结果。
1 语音提取问题描述
对于单声道语音提取问题,可理解为从线性混合的单声道语音y(t)中提取目标说话人语音s0(t)的过程。混合信号为:
(1)
式中,si(t)为任何数量的干扰者语音或者是噪声(在实验中考虑了干扰者);i=1,2,…,I为干扰说话人或者是噪声的索引。
通过短时傅里叶变换(STFT,short time fourier transform)将混合信号y(t)转化为Y(t,f):
(2)
式中,t和f分别为时间和频率索引;Y(t,f)、S0(t,f)和Si(t,f)分别为y(t)、s0(t)和si(t)在时频域的表示。
在语音增强[22-23]和语音分离[24-25]的研究中表明,对 DNN训练时,采用信号幅度谱近似(SA,signal approximation)损失收敛方法比理想比例掩蔽(IRM,ideal ratio mask)和估计的幅值谱掩蔽(SMM,spectral magnitude mask)之间的近似损失收敛方法性能更好。
(3)
(4)

2 目标值
在基于DNN的监督语音分离系统中,语音的分离工作通常分两阶段进行,首先是模型的训练阶段,其次是测试分离阶段。我们要讲的是在训练阶段中目标的获取,目标的选取一般都是基于干净的目标语音和背景干扰得到的,合适有效的目标对于模型的学习能力和系统的分离性能起着重要的作用。目前使用的目标主要分为两类:基于时频掩蔽的目标和基于语音幅度谱估计的目标。这里简单介绍下主要的四种分离目标。
2.1 理想二值掩蔽
理想二值掩蔽(IBM,ideal binary mask)经常作为深度神经网络模型学习的目标,该目标是一个二值函数(0或1),该二值掩蔽的取值是根据语音信号时频谱的每个时频单元中语音能量和噪声能量的大小关系决定。首先设定一个阈值,如果一个时频单元中局部信噪比大于阈值,则对应的单元掩蔽值设为1,反之为0。IBM表示为:
(5)
其中:SNR(t,f)表示语音信号时频单元的局部信噪比,IBM(t,f)表示理想二值掩蔽,LC是设置的阈值。
2.2 理想比例掩蔽
Wang等人首先提出了理想比例掩蔽(IRM,ideal ratio mask),IRM是一种软函数类型的目标[12]。该目标计算公式如下:
(6)
其中:IRM(t,f)是在时间t和频率为f的时频单元掩蔽值,S2(t,f)和N2(t,f)分别表示语音能量和噪声能量,β是一个可调节参数,而Wang等人已经通过实验证明,β为0.5时,模型的训练结果是最好的。IRM的值在[0,1]之间是连续的,这样在分离语音的时候可以提高目标语音能量谱完整性。
2.3 幅度谱掩蔽
幅度谱掩蔽(SMM,spectral magnitude mask)由目标语音和带噪语音的STFT谱计算得到,表示如下:
(7)
|S(t,f)|和|M(t,f)|分别表示目标语音和带噪语音幅度谱,利用两者的比值得到SMM目标。由于SMM目标用来估计目标语音的幅度谱,所以在信号的重构时需要结合带噪语音信号或目标语音信号的相位,经过STFT得到重构的目标语音的时域信号。
2.4 信号近似估计
信号近似估计(SA,signal approximation)的思想就是最小化目标语音和估计输出的语音幅度之间的误差,当误差逐渐收敛时,默认为此时的模型参数最优,损失函数如下:
SA(t,f)=(RM(t,f)|Y(t,f)|-|S(t,f)|)2
(8)
其中:RM(t,f)是网络模型的输出,可直接认为是估计的掩蔽,也可以通过用SMM目标估计RM(t,f)来训练模型参数,然后通过上述目标函数最小化对模型参数进行微调得到最优解。
3 频谱映射分离网络
3.1 神经网络结构
DNN是模仿人类神经系统而设计的信息分析处理结构,由神经元作为基本单元组成。一组输入经过加权进入神经单元,然后对加权后的输入进行激活计算,最后产生某种输出。其结构如图1所示。

图1 神经单元结构
基本神经单元中含有多个输入、一组权重、一个加法器、一个激活函数和一个输出,其计算原理为:
(9)
其中:xi表示输入数据,wi表示权重和偏置(i=0),F表示激活函数,yk表示第k层神经单元的输出。
激活函数F有多种表达式,常用的激活函数有:线性函数、双曲正切函数(Tanh)、Sigmoid函数、线性整流函数(ReLU,rectified linear units)。
1)线性函数:
F(x)=x
(10)
2)Tanh函数:
(11)
3)Sigmoid函数:
(12)
4)ReLU函数:
F(x)=max(0,x)
(13)
除了上述四种激活函数外,还有阈值函数等。激活函数是影响神经网络功能的重要因素之一,不同的激活函数实现的功能是不一样的,例如Tanh函数在特征相差明显时效果会更好,ReLU函数的稀疏性可解决网络训练时的梯度消失现象。连续平滑的Sigmoid函数和具有稀疏性的ReLU函数常用于语音分离任务中。
深度神经网络又包含三种属性层,即输入层、隐藏层、输出层,深度的大小取决于神经网络的隐藏层个数。图2展示了一个三层的神经网络。

图2 三层神经网络结构
3.2 附加掩蔽层的频谱映射网络
频谱映射分离网络主要由单个DNN体系结构组成,其中每个扬声器对应一个输出层,而利用谱映射分离后的两个语音幅度谱之和不等于混合语音的幅度谱,表明直接映射分离语音幅度谱是有缺陷的。因此,一个掩蔽层被添加到网络输出端,很好地解决了这个问题,其网络结构如图3所示。

图3 附加掩蔽层的频谱映射分离网络


(14)
(15)
频谱映射分离网络将说话人选择机制包括在其分离框架中,在输出层之后进行说话人语音的选择,然而目前还不清楚这是否会提供最佳的说话人语音。因此本文将基于频谱映射的分离解释为内部分离机制的频谱映射,如图4所示。
由此,可以认为分离机制存在于两个模块中,其中一个分离模块生成了对应每个源信号的内部嵌入向量Zi,另一个掩蔽估计模块生成来自内部嵌入向量的时频掩蔽Mi,如式(16)、 (17)函数所示:
(16)
Mi= MaskEstimator (Zi) (i= 1,...I)
(17)
其中:Separator(·)为内部嵌入向量分离器;i为Separator(·)源信号对应的嵌入向量的索引;MaskEstimator(·)为基于嵌入向量的掩蔽估计器。假设I个源共用MaskEstimator(·),并且其中shared表示参数和网络层激活函数共享,linear是DNN中的线性运算。
4 多任务学习的嵌入式注意机制模型
对于人耳听力来讲,在一个多人说话的环境中只关注自己感兴趣的语音是很容易的。然而这对于人机交互的语音识别设备来说是很困难的,因此为了更好地识别感兴趣的说话人,就需要提取目标说话人的语音信息而忽略其他人声音。为了解决这个问题,本文提出的基于注意机制的多任务学习语音提取算法,它成功地提取出了目标说话人信息,同时辅助信息的利用更好地提高了说话人语音质量。
4.1 分离和提取相结合的嵌入式注意机制
本文提出的分离系统可以扩展到更多源信号混合的分离工作,为了简化说明,只考虑两个源信号混合的分离提取工作(目标语音s1,干扰语音s2)。
基于分离和提取相结合的嵌入式注意机制模型如图5所示,意在实现一个分离和提取双重标准下的语音处理系统。该模型由分离器、注意机制模块和掩膜估计器三部分串联而成,分离器分离出不同说话人的嵌入向量{Zi}Ii=1,在注意机制模块中与说话人辅助语音谱特征相结合运算,提取出目标说话人的嵌入向量Ztar,进而在掩蔽估计器中得出目标说话人对应的时频掩蔽Mtar。
该模型通过在分离器和掩蔽估计器之间添加说话人注意机制模块,该模块可以有针对性的选择对应目标说话人的嵌入向量,从而集成了说话人感知提取功能。下列功能函数可表示基于嵌入式注意机制的分离和提取进程:
(18)
(19)
Mtar=MaskEstimator(Ztar)
(20)

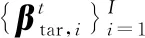
(21)
(22)

在嵌入注意机制中多层感知器的输出端使用了双曲正切函数,该函数在特征相差明显时效果会很好,循环过程中不断扩大特征效果。其计算如下:
(23)
(24)
式中,w,WΓ,WAUX为网络可训练的权重;b为网络模型偏置参数;γ为设置的超参数。
4.2 多任务学习进程
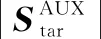
LMTL=αLSEPA+(1-α)LEXTR
(25)
(26)
(27)
5 实验及结果分析
为了验证目标语音提取算法的有效性和优越性,设计了两组实验。第一组实验证明了本算法的有效性,同时探讨了说话人性别对目标语音提取的影响。第二组实验分别使用不同的训练目标作为目标语音提取的对比试验,验证了算法的优越性。
5.1 实验数据
实验所用语音数据由TIMIT[27]数据库提供,分别从TIMIT数据库中选取两个不同性别的说话人语音片段,针对每个说话人截取了40秒时长的语音,前8秒作为测试样本,中间16秒作为训练样本,最后16秒作为辅助语音样本。然而为了研究说话人性别和语种影响,采集了两段相同时长的母语为汉语的说话人语音数据。根据采集得到的数据,利用Matlab软件对信号进行处理分析,将两说话人语音进行混合,混合的信噪比(SNR,signal-to-noise ratio)从0~5 dB均匀分布。采样频率为16 000 Hz。
5.2 实验设置
本实验分离和提取的统一网络采用五层结构的DNN,一个输入层,三个隐藏层和一个输出层,其每层网络的单元数为[513 1024 1024 1024 513]。
预训练:掩蔽估计网络采用玻尔兹曼机(RBM,restricted boltzmann machine)进行预训练,训练迭代次数为20,语音数据最小批次大小为256(帧数),学习率为0.003。通过RBM预训练,得到网络的初始权重和偏置。
实验使用RBM预训练方法初始化网络参数,将前一层的输出作为下一层的输入以这种数据传递方式训练RBM模型,其模型如图6所示。

图6 玻尔兹曼机模型
RBM是一种无方向的两层神经网络,严格意义上并不算深层网络。在图6中,下面一层神经元组成了可见层(输入层),用v表示可见层的神经单元值,上面一层神经元组成了隐藏层(输出层),用h表示隐藏层的神经单元值。可见层和隐藏层是全连接的,两层之间的权重由w表示。RBM工作时,首先获取一个训练样本v,计算隐藏层节点概率,然后在这基础上获取隐藏层激活的样本h,计算v和h的外积作为“正梯度”。反过来从h中获取重构的可见层激活向量样本v′,然后从v′再次获得隐藏层激活向量h′,计算v′和h′的外积作为“负梯度”。利用正负梯度差乘上学习率更新权重w。
精调:预训练得到初始化网络参数,在此基础上利用反向传播算法有监督的训练神经网络,使用随机梯度下降法更新权重,并且在训练过程中引入了可变动量项,训练的前十次动量项为0.5,后续的迭代过程中动量项为0.9的可变化学习率,其值在区间[0.08,0.004]中均匀减小,自适应学习率改善了固定学习率在学习权重时精确性差的问题。精调阶段的训练次数为180,隐藏层和输出层的激活函数分别是ReLU函数和Sigmoid函数。
ReLU(x)=max(0,x)
(28)
(29)
Sigmoid函数的连续光滑性质,使网络输出在一定范围内,数据在传递过程中不易发散,ReLU函数的稀疏性可解决网络训练时的梯度消失现象。
掩蔽估计网络的目标函数为LMTL,参数α设为0.5,多次试验表明γ=2时分离性能最优,其收敛曲线如图7所示,曲线逐渐趋于收敛,这表示网络的训练是有效的。

图7 多任务学习的损失曲线
为了评估说话人语音的提取性能,实验采用了BSS_EVAL工具箱中的三个评估指标:源信号失真比(SDR,source to distortion ratio)、源信号伪影比(SAR,source to artifacts ratio)、源信号干扰比(SIR,source to interference ratio)。SDR反映了综合分离效果,SAR反映算法对产生噪声的抑制能力,SIR 反映算法对干扰信号的抑制能力。三者数值越大就说明分离提取性能越高。
5.3 实验结果
首先对算法的有效性进行了实验评估,实验结果以波形图和语谱图的形式展示,如图8和图9所示。
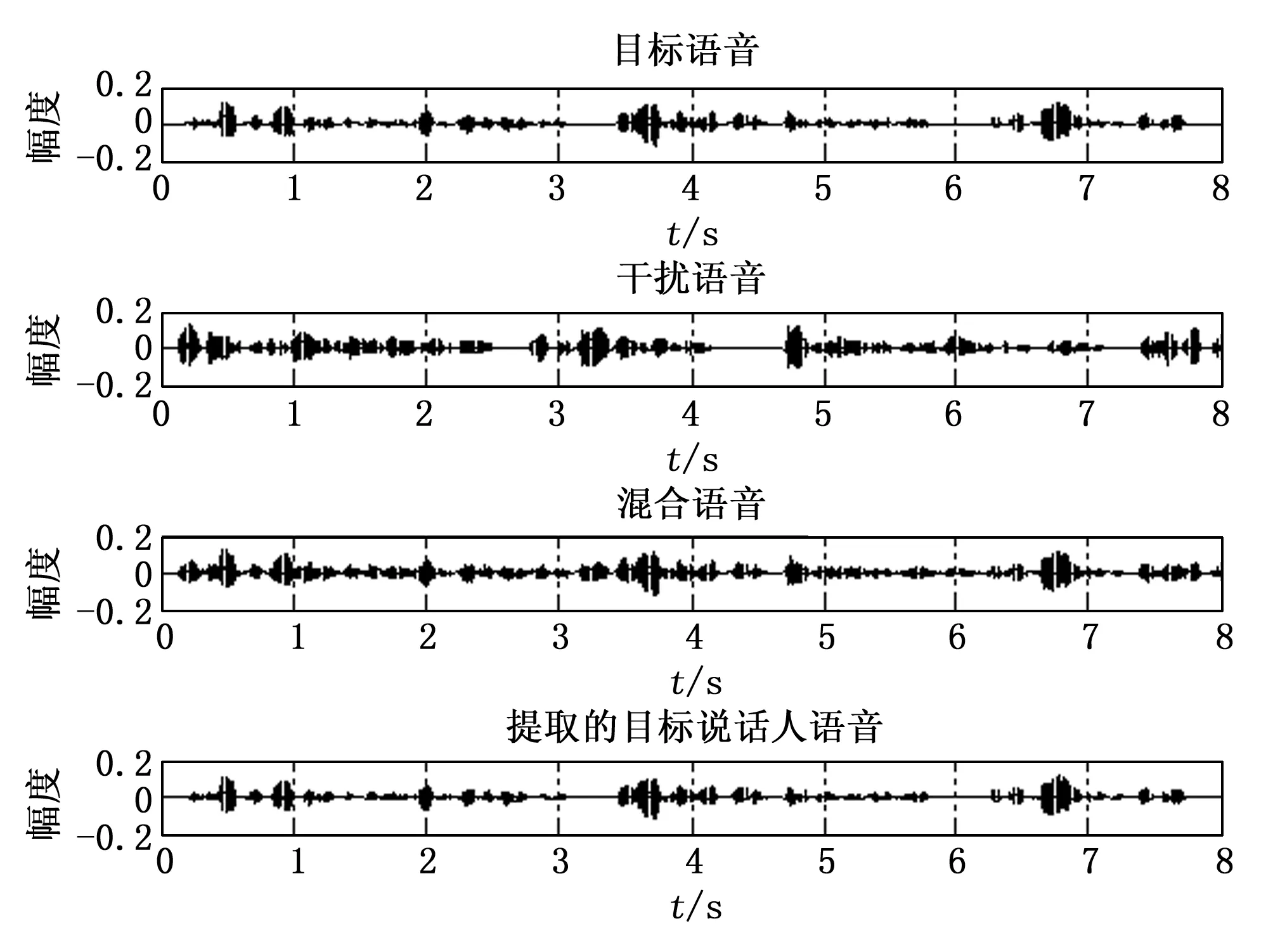
图8 语音时域信号波形图

图9 目标说话人的估计掩
图8分别展示目标语音、干扰语音、混合语音和算法提取的目标说话人语音的波形图。波形图的横轴表示时间,纵轴表示波形的幅值大小。通过对比提取的目标说话人波形和混合语音的波形,可以看出算法具有提取目标人语音的功能,提取的目标说话人波形与目标源语音波形的相似程度体现了算法模型对目标说话人语音提取性能的优劣。
图9和图10分别表示目标说话人的估计掩蔽插图和语谱图。掩蔽插图横坐标为时间帧,纵坐标为网络输出通道数。该掩蔽插图由掩蔽值归一化后描绘而成,其图上的白色部分是有值的,在0~1之间取值。黑色背景代表很小的值,接近于0。注意下列图右上角的矩形框区域,在掩蔽插图和目标语音语谱图框内黑色占主导,说明此区域的谱值绝大多数很小或为0,而对应的干扰语音和混合语音矩形框内具有不同颜色值,说明此区域的谱值大于0,最终提取的目标说话人语音语谱图在相应位置也是黑色占主导,这在时频域里体现了掩蔽提取目标说话人的本质。
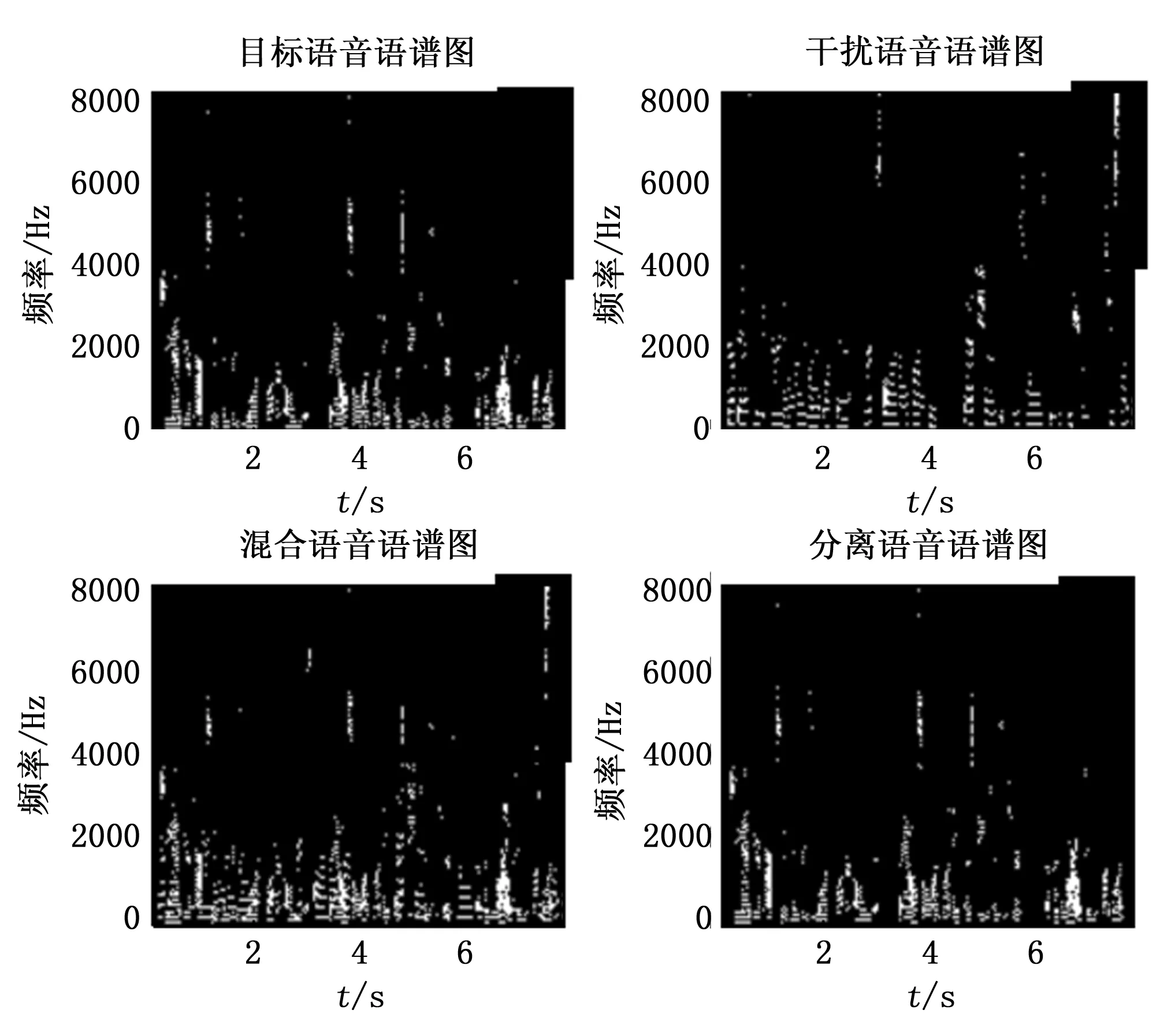
图10 语音频域信号语谱
除了验证所提算法的有效性,同时也在相同信噪比混合情况下,探讨了说话人的性别对提取算法的影响,实验结果如表1所示。

表1 混合信噪比为0 dB下的男1目标语音提取性能 dB
利用这4个人的语音分别得到了以上5种组合方式,其中男1和女1为不同性别的目标说话人,选自是TIMIT数据集中的说话人语音。男2和女2是干扰说话人,为课题组录制的说话人语音。通过分析表1和表2指标,可以发现,相比较同性别混合语音,不同性别混合语音中的提取效果更好。在同性别混合语音中,女声的提取效果由于男声的提取效果,这可能与说话人的音质和音色有一定的关系。除了说话人性别对语音的提取有影响以外,干扰说话人语音的说话内容和语种对目标语音提取性能也有关系。同语种的混合的说话人提取效果要比不同语种混合的说话人提取效果好。这表明由同语种混合语音训练的网络模型,对本语种语音信号的提取更有效。而对于不同语种的语音来讲,特征可能相差较大,无法在同一特征水平上进行很好的分离提取。
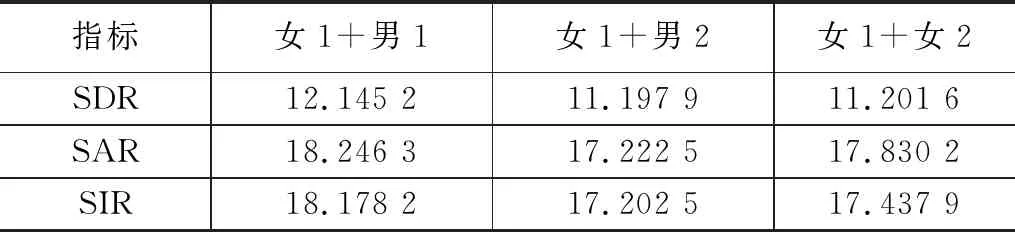
表2 混合信噪比为0 dB下的女1目标语音提取性能 dB
为了探究混合信噪比对提取性能的影响,因此在不同混合语音信噪比下进行了语音提取性能测试,由表3分析可知,随着干扰混合信噪比的增大,语音提取性能也不断提高。这表明在目标语音信号功率越大时,提取性能越高。
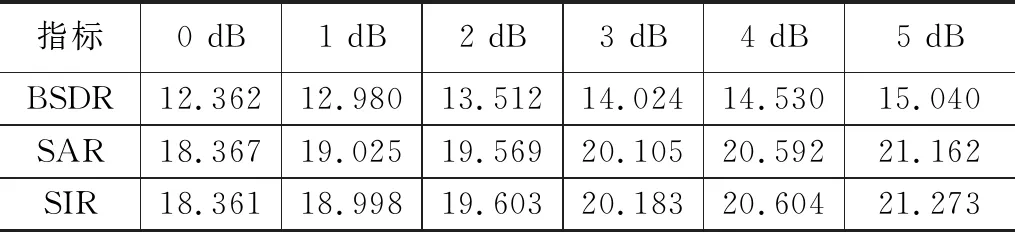
表3 不同信噪比下的语音提取性能 dB
为了验证所提算法的优越性,分别使用幅度谱掩蔽(SMM,spectral magnitude mask)和信号近似估计(SA,signal approximation)目标方法进行了对比实验,结果如表4所示。
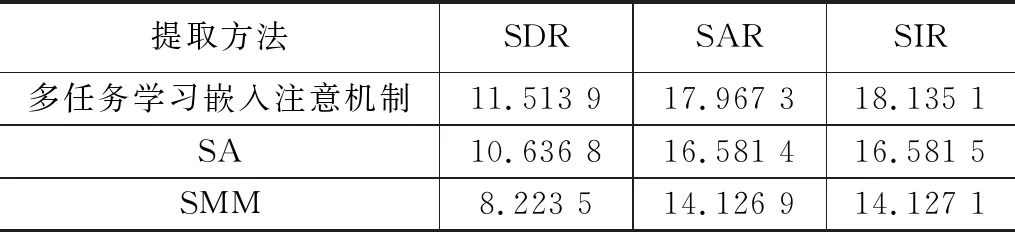
表4 混合信噪比为0 dB下不同方法的目标语音提取性能 dB
根据表4的实验结果表明,相比较SA和SMM这两种方法,本文提出的基于多任务学习的嵌入式注意机制语音提取算法在SDR分别取得了0.877 1 dB和3.290 4 dB的提高。对于SAR和SIR指标,本文算法也均优于其它两种方法。
6 结束语
在这篇文章中,针对目标说话人语音的提取,我们提出了一种基于分离和提取多任务学习的嵌入式注意机制目标语音提取算法。本文的算法模型主要分为分离模块、嵌入式注意机制模开、语音提取模块三部分,在分离和提取的多任务优化标准下,充分利用了说话人辅助信息,更加集中地对目标说话人语音进行提取。实验结果表明,本文提出的算法利用较少的训练数据集,可实现相对较高的提取性能。
本文的不足之处在于使用的数据集单一,下一步努力方向是扩大数据集总类,保证语音信号质量的前提下,提高模型的普适性。同时可探究在其他各种噪声环境下目标说话人语音的提取性能。
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:47:36
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
数学小灵通(1-2年级)(2020年4期)2020-06-24 05:47:08
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
