
基于深度学习的行人属性识别及应用
2023-10-27 10:29:27武鑫森
现代信息科技 2023年17期

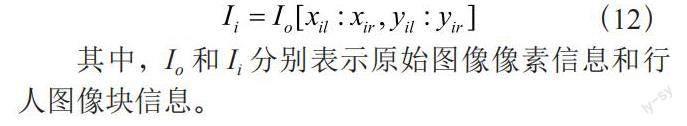
摘 要:为了提高行人属性识别的准确率,提出基于多尺度注意力网络的行人属性识别算法,并对其进行了改进。将行人属性分为上身、上身附属、下身、下身附属、脚部、朝向、性别、年龄、携带物9个类型。在进行初步的二分类属性预测后,实行进一步的属性筛选分类,避免互斥属性同时出现,从而提高属性识别结果的准确性和合理性。此外,为了有利于行人属性识别算法的应用,基于模块化的设计理念,按照原始图像和目标检测预测结果中的行人类型和位置信息获取行人图像块信息进行属性识别,提出目标检测与行人属性识别一体化的方法。
关键词:图像处理;深度学习;行人属性识别;目标检测
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)17-0061-06
Pedestrian Attribute Recognition and Application Based on Deep Learning
WU Xinsen
(CRSC Communication & Information Corporation, Beijing 100070, China)
Abstract: In order to improve the accuracy of pedestrian attribute recognition, a pedestrian attribute recognition algorithm based on multi-scale attention networks is proposed and improved. Divide pedestrian attributes into 9 types: upper body, upper body attachment, lower body, lower body attachment, feet, orientation, gender, age, and carrying items. After preliminary binary attribute prediction, further attribute screening and classification are implemented to avoid the simultaneous occurrence of mutually exclusive attributes, thereby improving the accuracy and rationality of attribute recognition results. In order to facilitate the application of pedestrian attribute recognition algorithms, and based on a modular design concept, pedestrian image block information is obtained from the original image and the pedestrian type and position information in the target detection prediction results for attribute recognition. An integrated method of target detection and pedestrian attribute recognition is proposed.
Keywords: image processing; deep learning; pedestrian attribute recognition; object detection
0 引 言
行人属性识别是近年来发展迅速的一种算法,作为深度学习算法的一个分支,行人属性识别算法可以有效挖掘出监控场景中行人可被观察到的一些语义信息,如行人性别、年龄、朝向、发型、帽子、上衣、下衣、鞋子,以及行人是否佩戴眼镜、口罩、背包等附属物等,为此该算法在智慧城市、刑事侦查等领域得到广泛的应用。虽然这些信息可通过人工观察的方式获得,但这会十分耗时费力。行人属性识别无须人工操作,只是将这些信息转换成可以用于检索的高级语义信息即可进行计算。如进行行人检索时可基于属性快速检索感兴趣的目标[1]。在真实场景中,有些监控摄像头捕获的行人图像分辨率较低,而行人属性凭借其对比度和光照不变性而具有较高的应用价值[2]。
在行人属性识别中,不同类别属性所属的粒度不同,如发型、帽子、眼镜、口罩等信息是图像中行人的局部区域低层信息,而年龄、性别、朝向等信息则为全局的高层语义信息。针对细粒度的属性(如眼镜、装饰),采用直接提取整幅图像特征的方法无法有效识别这些属性。因行人的属性各不相同,识别时对网络浅层或深层特征,局部或全局特征的需求也各不相同[3]。此外,在视角、光线等信息变化时,采样到的图像变化可能很大,但对这些属性信息的判别结果不应该因受上述环境因素的影响而发生改变。从一张输入图像中提取不同尺度的特征完成对应属性的判别及提升属性判别的鲁棒性,是行人属性识别的难点所在。在很多的现实场景中,行人往往比较密集,摄像机角度和分辨率等都存有较大的差别。
在研究层面,目前行人属性识别的研究大都是以单独完整的行人图片作为输入,但是真实场景中的应用往往需要以原始图片作为输入,需要实现目标检测和行人属性识别算法的有机结合。此外,行人属性总是表现出语义或视觉空间上的相关性或互斥性,但若是基于多标签二分类属性的輸出,因训练数据集属性不均衡等原因,有可能会导致不符合常识互斥属性的出现,比如识别结果为同一个人既穿短裤又穿长裤。所以应采取有效措施避免不符合常识互斥属性的出现,这将有助于提高检测结果的准确性和合理性。
在国内外的研究中,随着深度学习的发展,Li等[4]提出了多标签属性学习卷积神经网络模型(DeepMar),通过卷积神经网络(CNN)获得更丰富的特征以代替手工特征,进而从一个网络模型中同时识别出行人的多个属性。Sudowe等[5]提出了属性卷积网络(ACN),将整个行人图像作为模型输入,联合学习所有属性的预测。这些方法都是利用网络中的最后一个特征图来完成属性识别任务,不能提高属性识别的准确率,原因是不同网络层的特征反映了属性不同的语义信息。如CNN模型需要从前几层网络中提取颜色或纹理等底层特征,这些特征对于衣服颜色和条纹的属性非常重要,但对于性别、年龄这样的语义属性,高层网络的特征比底层特征更有效[6,7]。为了应对多层次的属性识别,通过CNN提取行人图像的特征,构建特征金字塔网络(FPN)。Li等针对行人属性识别任务的特点设计了多尺度注意力网络,采用基础的残差网络ResNet50框架构建特征金字塔网络(FPN),以融合底层特征和高层特征,并利用通道注意力机制提升特征通道之间的关联性,以增强网络的属性识别能力。
在深度学习领域,目标检测的实现通常是基于主流的卷积神经网络构建用于提取特征的基础网络,而后在基础网络中预先选定的特征提取层后部,通过额外附加的卷积层进一步增加卷积图的语义深度并调整其维度,使之匹配后面连接的检测器的输入要求,最终由检测器实现对目标的分类和定位等功能。YOLO系列是当下非常流行的单阶段实时目标检测算法,其将目标检测问题转化为回归问题,采用一个单独的卷积神经网络实现端到端的目标检测,具有速度快、准确率高、适用性广、可扩展性强等特点。Wang等[8]推出的YOLOv7模型针对模型结构重参化和动态标签分配问题进行了优化,使模型的参数量和计算量大幅度减少,进一步提升了目标检测性能。
1 算法介绍
1.1 行人属性识别算法
采用基于弱监督多尺度注意力网络的行人属性识别算法,能够融合网络中不同层次的特征并自适应分配网络权重,可以以端到端简单易行的方式进行训练,并可有效识别行人的各类属性[2,9]。其以从ImageNet训练的BN-Inception网络作为基础网络,沿着自底向上的路径以多个尺度从低层特征图中提取细节信息,并沿着自顶向下的路径从高层特征图中提取语义信息,然后在网络中添加横向连接,使得高层的语义特征能够与底层的细节特征进行融合构建特征金字塔,并通过通道注意力机制自主融合不同通道的特征,提升特征通道之间的关联性。最后,采用属性定位模块将属性与图像中的具体区域进行关联,将属性标签与图像中相应的位置进行匹配和定位,以提供属性的局部化信息。在对行人的各个属性进行判断和预测时,采用sigmoid函数将网络的输出映射到0到1之间,表示属性存在的概率。
但行人属性识别本身是个多标签分类问题,若只是对属性采用sigmoid函数以二分类的形式进行预测,有时会产生一些互斥属性同时出现的现象,比如识别结果为同时出现短裤和长裤。为了避免互斥属性的同时出现,将行人属性分为上身、上身附属、下身、下身附属、脚部、朝向、性别、年龄、携带物9个类型,并将属性归类到9个类型中,如表1所示。通过对行人属性进行sigmoid二分类,获取每个属性存在概率的分值Kij,如式(1)所示,并只保留分值Kij大于阈值αij的属性。对于携带物这个类型中的属性,允许多项属性同时存在。而其余8个类型中的属性,通过softmax函数对其余8个类型中的属性重新获得分值gij,如式(2)所示。最后通过argmax函数获取每个类型存在概率最大值属性的索引sij,并将该索引对应的属性xij作为该类型唯一显示的属性,如式(3)所示。
其中,xij表示第i个類型的第j个属性,kij表示属性xij通过sigmoid获得的分值,ni表示类型i中的属性个数,kim表示类型i中每个属性通过sigmoid获得的分值,gij表示属性xij在类型i中通过softmax获得的分值,sij表示类型i中通过argmax筛选出来的属性索引。
1.2 算法结合
在研究层面,通常是目标检测和行人属性识别等算法分开单独研究;而在工程应用层面,需要将目标检测和行人属性识别算法有机结合。完整的流程是以原始图像作为输入,通过目标检测算法识别行人类型并获取其位置坐标,然后将获取的行人图像信息传入改进后的行人属性识别算法,获取行人的有效属性并进行输出,如图1所示。
在YOLO系列中,预测的物体边界框坐标(中心坐标和宽高)通常是相对于输入图像的归一化坐标,取值范围在[0,1]之间。为了实现进一步的处理,需要将这些归一化坐标转换为图像像素坐标,如式(4)~(7)所示:
其中,xi和yi表示检测目标i在图像中归一化的中心坐标,wi和hi表示归一化的宽度和高度。wo和ho表示原始图像的宽度和高度。xip和yip表示检测目标的中心像素坐标,wip和hip表示检测目标的宽度和高度。
为了便于获取图像中的行人图像块信息,将目标在图像中的中心坐标和宽高转换为目标左上角和右下角的坐标,如式(8)~(11)所示:
其中,xil和yil表示检测目标i在图像中左上角的像素坐标,xir和yir表示检测目标i在图像中右下角的像素坐标。
在原图中获取行人图像块信息的方法如式(12)所示。将行人图像块信息传入行人属性识别算法,以进行下一步的属性识别。
其中,Io和Ii分别表示原始图像像素信息和行人图像块信息。
2 实验结果
2.1 实验测试
服务器使用的是64位Centos 7系统,GPU为NVIDIA RTX 2080 Ti,内存为32 GB。编程语言为Python 3.8,模型训练使用的深度学习框架为PyTorch。实验采用的行人属性数据集为PA-100K,包含由598个室外监控摄像头采集到的100 000张行人图像,每张图像有26个属性标注,图像分辨率从50×100到758×454 [9,10]。随机选择80 000张图像用于训练,10 000张图像用于验证,10 000张图像用于测试。
在行人属性识别模型中,根据行人图像的特点将输入图像的分辨率统一缩放至256×128,同时使用随机水平镜像和数据洗牌等数据增强方法进行行人属性识别,网络采用自适应运动估计算法(Adam)进行训练。总共训练了60个Epoch,batch-size为32,初始学习率为0.000 1,且每10个Epoch衰减0.1。参数衰减值(weight-decay)为0.000 5,动量因子(momentum)为0.9,模型参数量为1.4×107。
经过60个Epoch训练,模型训练结果如表2所示。在第60个Epoch时,当前批次的处理时长(time)为0.721 s,整个训练过程的平均处理时长为0.769 s;当前批次的损失值(Loss)为0.015 6,整个训练过程的平均损失值为0.021 4;当前批次的准确率(Accuracy)为1.000,整个训练过程的平均准确率为1.000。损失值和准确率这两个指标通常用于监控模型在训练过程中的性能表现。损失值越低,准确率越高,代表模型的训练效果越好。
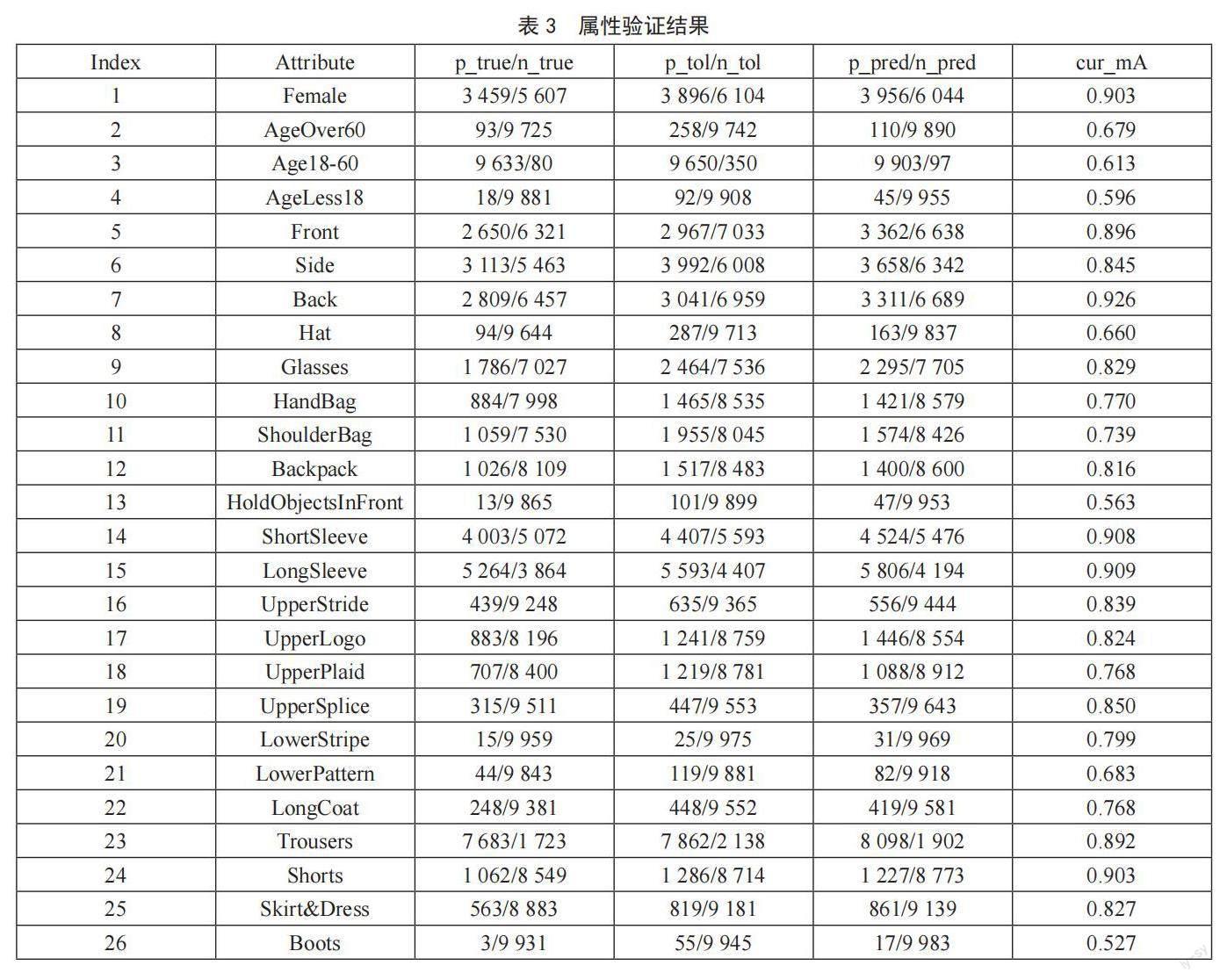
为了避免模型过度拟合训练数据,在每个Epoch中对模型进行验证。在第60个Epoch的验证集中,26个属性的验证结果如表3所示。其中,p_true/n_true表示属性在验证集中为“真”的正样本数/总正样本数,p_tol/n_tol表示属性在验证集中为“真”或误差容忍度范围内的正样本数/总正样本数,p_pred/n_pred表示模型對属性的预测结果中为“真”的正样本数/总正样本数,cur_mA表示当前的平均精度。
衡量行人属性识别能力的指标通常为基于标签的评价指标和基于实例的评价指标,前者主要是平均精度均值(mA),后者主要是准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1_Score[11,12]。其中,在评价属性识别模型的性能时,主要看mA和F1。经过60个Epoch训练,行人属性识别算法的mA为0.782,F1为0.865,取得了较好的效果,如表4所示。
在第60个Epoch的测试集中,模型的准确率为0.939。对PA-100K测试集中行人属性的预测效果进行可视化展示,如图2所示。
而对于目标检测,通常采用平均精度(AP)来评价。YOLOv7模型采用经过MS COCO数据集训练的模型参数进行各种常见场景的类型检测,其各项指标APtest/APval为51.4%/51.2%,AP50test为69.7%,AP100test为55.9%[8]。
2.2 实例测试
真实场景中的行人行为更为复杂多变,以铁路车站场景的图片为例进行实例测试,在视频截图中可以看到远近有多名不同性别的行人,其穿戴、朝向、携带物等均有差异,如图3所示。
若仅让该图经过YOLOv7目标检测算法的运算,可以有效识别出行人、火车、背包等各种类别,并可获取其位置坐标,如图4所示。
通过目标检测算法在原图中筛选出行人类型及其归一化位置坐标,并将归一化位置坐标转换为像素位置坐标。若把每个检测到的行人裁剪出来,可视化效果如图5所示。
将每个行人的图像块信息传入改进的行人属性识别算法进行识别,能够有效识别出行人的各项属性(如性别、年龄、朝向、上衣、下衣、穿戴物以及携带物等),且没有互斥属性出现,如图6所示。
在实际应用中,已经把目标检测算法和改进的行人属性识别算法进行了有机结合,所以输入原图可以直接获得行人属性识别的效果图及其属性识别信息,以便做进一步的处理和分析。
3 结 论
采用端到端多尺度特征融合的行人属性识别算法,基于多层提取特征和自适应分配特征权重的框架,以端到端简便易行的训练方式,可以完全由属性识别的总体标定结果驱动算法进行端到端的位置回归和类别打分训练迭代,从而自动获得属性识别结果。在此基础上,将行人属性分为9个类型进行筛选,实现对行人性别、年龄、朝向、帽子、上衣、下衣、鞋子,及其是否带有眼镜、背包等附属物的自动检测识别,并避免互斥属性的同时出现,提高了属性识别结果的准确性和合理性。
在行人属性与目标检测算法结合方面,采用模块化的设计理念,通过目标检测对图像中不同尺度、位置的行人进行检测。通过目标检测获取行人类型和位置信息,进而获取行人图像块信息传入改进的行人属性识别模型,以获得准确的属性识别结果,可为行人在岗检测等其他算法的研发应用提供基础参考。
参考文献:
[1] SU C,YANG F,ZHANG S L,et al. Multi-task learningwith low rank attribute embedding for multi-cameraperson re-identification [J].IEEE Transactions onPattern Analysis and Machine Intelligence,2018,40(5):1167-1181.
[2] 李娜,武阳阳,刘颖,等.基于多尺度注意力网络的行人属性识别算法 [J].激光与光电子学进展,2021,58(4):290-296.
[3] 马腾飞.自适应特征匹配的行人识别技术研究及实现 [D].北京:中国科学院大学(中国科学院人工智能学院),2021.
[4] LI D W,CHEN X T,HUANG K Q. Multi-attributelearning for pedestrian attribute recognition in surveillance scenarios [C]//2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR). Kuala Lumpur:IEEE,2015:111-115.
[5] SUDOWE P,SPITZER H,LEIBE B. Person attribute recognition with a jointly-trained holistic CNN model [C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops. Santiago:IEEE,2015:87-95.
[6] 袁配配,张良.基于深度学习的行人属性识别 [J].激光与光电子学进展,2020,57(6):61-67.
[7]林笑.基于人体子部件分割的行人多属性识别模型研究 [D].北京:北京工业大学,2021.
[8] WANG C Y,BOCHKOVSKIY A,LIAO H M,et al. YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [J/OL].arXiv:2207.02696v1 [cs.CV].[2023-04-20].https://arxiv.org/abs/2207.02696.
[9] TANG C,SHENG L,ZHANG Z X,et al. Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul:IEEE,2019:4996-5005.
[10] SARFRAZ M S,SCHUMANN A,WANG Y,et al. Deep view-sensitive pedestrian attribute inference in an end-to-end model [J/OL].arXiv:1707.06089v1 [cs.CV].[2023-04-13].https://arxiv.org/abs/1707.06089v1.
[11] DENG Y B,LUO P,LOY C C,et al. Learning torecognize pedestrian attribute [J/OL].arXiv:1501.00901v2 [cs.CV].[2023-04-19].https://arxiv.org/pdf/1501.00901.pdf.
[12] ZHAO X,SANG L F,DING G G,et al. Groupingattribute recognition for pedestrian with jointrecurrent learning [C]//Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence.California:AAAI Press,2018:3177-3183.
作者簡介:武鑫森(1990—),男,汉族,河北沧州人,工程师,博士,研究方向:计算机视觉。
猜你喜欢
电子制作(2018年18期)2018-11-14 01:48:20
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学与财富(2016年28期)2016-10-14 23:45:18
