
科研数据学术不端影响因素研究
2023-10-26 13:21白如江秦明艳张玉洁
科技进步与对策 2023年20期
白如江,秦明艳,张玉洁
(山东理工大学 信息管理研究院,山东 淄博 255000)
0 引言
科研数据(Science Research Data)指在科研活动中产生的有价值的、数字形式的数据集合,包括通过调查、观察、实验等科研活动直接获取的原始数据,经清洗、加工等优化后的预支撑论文数据,以及直接支撑论文结论的最终数据等[1]。科研数据通常以图表形式存在于论文中。目前,国内外对学术不端具体含义的界定尚未完全统一,但已在“学术不端是主观故意违反学术道德”方面达成共识。根据我国首个学术不端行为行业标准《学术出版规范——期刊学术不端行为界定(CY/T174—2019)》可知,学术不端行为包含剽窃、伪造、篡改、不当署名、一稿多投、重复发表6种类型[2]。本文结合科研数据概念、学术不端含义共识及我国学术不端行为行业标准,认为科研数据学术不端指科研人员主观故意剽窃、伪造、篡改论文中有价值的、数字形式的数据集合的行为。
自2002年以来,国际学术界科研数据学术不端丑闻层出不穷[3-4],且呈显著上升趋势[5-6]。科技伦理是开展科学研究、技术创新活动时应遵守的行为准则和价值理念,是推动科技事业积极发展的基础保障。当前科研数据学术不端事件时有发生,严重扰乱科研伦理秩序,长此以往将阻碍科技事业健康发展。
针对科研数据学术不端问题,相关机构尝试了各类防范举措。例如,美国科研诚信办公室、艾普蕾公司相继开发“Droplets”程序、“猫图鹰”系统,用于检测图片篡改、造假[7];联合国教科文组织期望科研数据能在一天之内公开到“Zika Open”平台[8];《Science》成立数据编委会专门负责论文科研数据审查[9];《Scientific Data》《humanities and social sciences communications》《数据分析与知识发现》等国内外众多期刊强烈建议甚至强制要求作者提交并共享科研数据[10-11]。国内外学者也就此展开热烈讨论,相关文献主要借助案例分析、文献计量、经验总结、调研实证、模型构建等方法,分析科研数据学术不端类型及其行为特征[12-13]、分布规律及造假风险[14]等,并在此基础上探讨期刊防范科研数据学术不端的方法[15]。李侗桐(2019)等通过分析科研数据伪造案例,将科研数据伪造划分为捏造科研数据、虚报样本量、篡改科研数据3类,并总结其主要表征;刘胜利[14]等首次提出基于信息约束量与科研数据形式间关联规则计量评估论文科研数据造假风险的方法,以及凭借期刊影响因子、撤稿指数计量评估科研人员科研数据造假可能性的方法;Steen[13]等借助撤稿论文计量分析科研数据伪造、篡改类学术不端论文分布特征;Sebastian[15]等展示了如何使用聚类分析法识别伪造的科研调查数据。
综上,相关机构为防范科研数据学术不端尝试了多种方法,相关学者也提出了一些完善的意见。但以下两个方面仍需进一步探讨:一是突破事后识别思路,更注重事前预防。当前探讨的科研数据学术不端防范措施主要适用于论文完成后、出版前期刊对科研数据学术不端辨识环节,但由于科研数据学术不端行为的难辨性[12],很难保证相关论文被成功拦截。即使成功避免了科研数据学术不端论文的出版、传播,但科技资源、期刊资源已被浪费。如何从源头上约束科研人员科研数据学术不端苗头,预防科研数据学术不端论文大量出现,是亟需努力的方向。二是深入研究科研数据学术不端影响因素。当前研究大多探讨科研数据学术不端类型及其行为特征,鲜少对科研数据学术不端影响因素进行研究,缺乏一套对科研数据学术不端影响因素进行系统分析的模型及方法。
故此,本文集成决策实验室分析法、解释结构模型法,构建我国科研数据学术不端影响因素多级递阶结构模型,识别我国科研数据学术不端关键影响因素,厘清因素间逻辑层次关系,并基于此为构建我国科研数据学术不端预防机制提供对策建议,以期从源头上预防科研数据学术不端论文,优化我国科研生态环境,促进科技事业健康发展。
1 研究方法与过程
本文共包含3个研究阶段:一是基于匿名反馈函询法,构建我国科研数据学术不端影响因素体系,抽取影响因素集;二是基于决策实验室分析法构建综合影响矩阵,识别关键影响因素;三是基于解释结构模型法,构建影响因素多级递阶结构模型,厘清因素间逻辑层次关系。具体研究思路如图1所示。
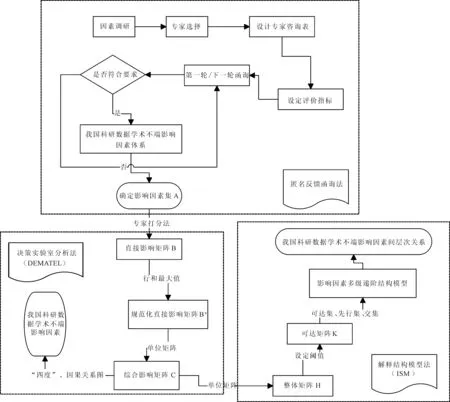
图1 我国科研数据学术不端影响因素研究思路Fig.1 Research ideas of influencing factors of academic misconduct in scientific research data in China
1.1 我国科研数据学术不端影响因素体系构建
匿名反馈函询法,亦称专家调查法,是一种基于函询方式调查专家建议、结构化匿名反馈调查结果、多轮修改直至协调认同的直观预测法[16]。该方法充分借助专家知识经验,集思广益,调查结果具备广泛代表性,准确性高。本文基于匿名反馈函询法构建影响因素体系,有利于科研管理部门全面了解我国科研数据学术不端影响因素,也为后期影响因素模型建立提供数据保障。
1.1.1 因素调研
在中国知网期刊数据库中,以“数据学术不端”“数据造假”“图表学术不端”“图表数据造假”为主题词,检索到66篇核心期刊研究论文,删除不相关文献,剩余37篇。逐一阅读文献,初步提取出160个影响因素。专家小组成员删除不相关和低频次因素,合并名称相似及含义相近因素,从个人、组织、期刊、社会4个维度归纳出12个影响因素,分别是科研数据素养、学术道德素养、学术能力、学术自尊、科研诚信教育、科研诚信环境、科研评价压力、监督惩治机制、数据公开、数据审查、数据学术不端检测技术、论文代写代发。
1.1.2 专家选择
为提高因素体系合理性,本文邀请该领域专家有组织地、反复多次修正影响因素,以形成认同度高、准确性强的因素体系。专家选择是匿名反馈函询法中影响研究结果准确性的重要环节。本文依据广泛性原则和代表性原则,选择来自多省份、多学科的代表性科研人员作为函询对象。专家的代表性和广泛性既能体现意见专业性,也利于多视角意见的提出。专家基本信息如表1所示。

表1 专家基本信息Tab.1 Basic information of experts
1.1.3 专家咨询表设计
在文献参考和小组讨论的基础上,反复修改专家咨询表结构和措辞,形成专家咨询表,包含4个部分:一是简介,主要包括研究背景、内容、目的等;二是填表说明,主要包括相关说明、注意事项等;三是专家信息,主要包括专家基本信息(性别、学历、所在学校/单位、所学专业)和专家自评(判断依据、熟悉程度);四是指标意见,主要包含因素重要程度意见和修改意见(添加、删除、合并指标或其内涵)。
咨询表中各变量评分标准和赋分含义如下:影响因素重要性测量采用李克特五级量表,即非常重要、比较重要、一般重要、不太重要、不重要,分别赋分5、4、3、2、1,代表影响因素的重要程度,如“5”代表某专家认为某影响因素对我国科研数据学术不端的影响程度非常大,即该影响因素非常重要;熟悉程度分为非常熟悉、较熟悉、一般熟悉、不太熟悉、不熟悉,分别赋分0.9、0.7、0.5、0.3、0.1,代表专家对该课题的熟悉程度,如“0.1”代表该专家对本课题不熟悉。本文参考何宇[17]在专家咨询表中描述的“判断依据”内容,将本文判断依据分为实践经验、理论分析、参考国内外数据、直觉感觉4种。判断依据测量量表采用三级评分,分为实践经验(大、中、小)、理论分析(大、中、小)、参考国内外数据(大、中、小)、直觉感觉(大、中、小),对应赋分为实践经验(0.5、0.4、0.3)、理论分析(0.3、0.2、0.1)、参考国内外数据(0.1、0.1、0.1)、直觉感觉(0.1、0.1、0.1)。其中,“大、中、小”代表专家在判定影响因素重要性时基于该依据的程度,比如实践经验“大”代表专家很大程度上基于实践经验对影响因素重要性作出判断。分值代表专家打出的影响因素重要性分值的可信度,如实践经验0.5代表专家给出的影响因素重要性分值的可信度最高。各变量评分标准如表2所示。
1.1.4 评价指标设定
(1)专家积极程度(Y)。专家积极程度指专家对研究问题的关心程度。Y值越大,表示专家对该研究的关心程度越高。一般来讲,Y≥0.70时,认为专家积极程度高。m表示回收问卷数,q表示发出问卷数,计算公式如下:
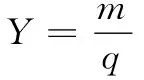
(1)
(2)专家权威系数(CR)。专家权威系数指专家在该研究方向的权威程度,CR值越大说明专家权威性越高,评价结果可靠性越高。一般来讲,CR≥0.70时,认为专家权威程度高。CR由专家自评时得到的指标判断依据Ca和熟悉程度Cb决定,计算公式如下:
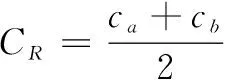
(2)
(3)专家集中程度。专家集中程度反映指标重要性分值的集中趋势,该值越大,表示该指标越重要。常用的专家集中程度计量指标有均值、满分频率,其中,均值是所有专家打分总数与打分专家人数之比,计算公式如下:

(3)
式中,Mi指第i个指标的重要性得分均值,mi指评价第i个指标的专家人数,Bij指第i个指标的第j个专家打出的重要性评分。一般而言,重要性均值大于3才满足要求。
满分频率是指标满分数与专家人数之比,计算公式如下:
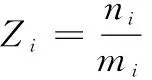
(4)
式中,Zi指第i个指标的满分频率,mi指评价第i个指标的专家人数,ni指第i个指标的满分数。Zi值越大,表明该指标越重要。
(4)专家协调程度。专家协调程度指专家对同一指标重要性意见的波动程度,通常由变异系数CV表示。变异系数是消除量纲影响后,客观比较测量值变异程度的统计量,计算公式如下:
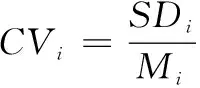
(5)
式中,CVi指第i个指标的变异系数,SDi指第i个指标的标准偏差,Mi指第i个指标的均数,该值越大,表明专家对同一指标重要性认知差距越大。一般而言,CV≤0.25时满足要求,否则应重新调研直到满足需求。
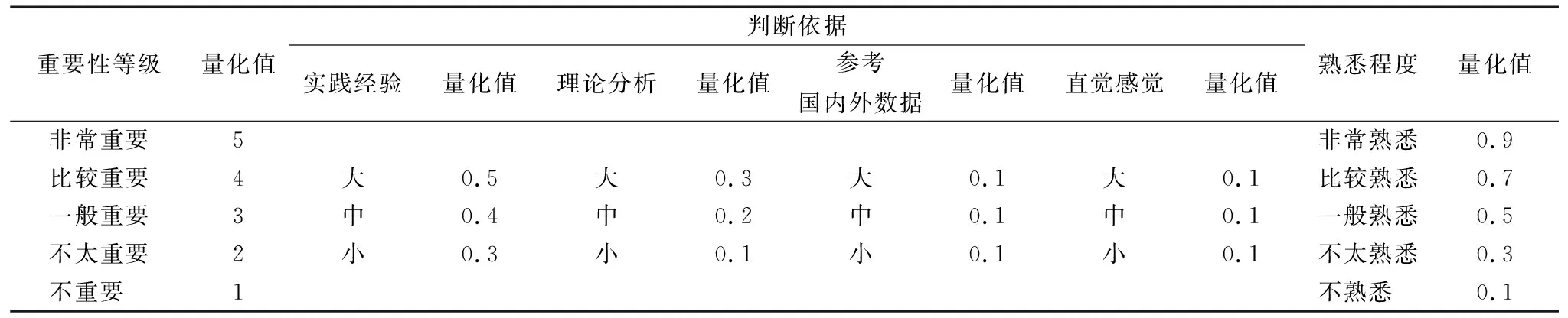
表2 影响因素重要性、判断依据与熟悉程度评分标准Tab.2 Importance of influencing factors, judgment basis and scoring criteria of familiarity
1.1.5 函询结果分析
(1)第一轮匿名反馈函询结果分析。在第一轮专家咨询中,以函询方式邀请25位专家对12个因素的重要性进行打分,收回22份问卷,专家积极系数为0.88(>0.70),说明专家对该研究关心程度高,符合要求;22位专家中有3位专家权威系数小于0.7,说明这3位专家对我国科研数据学术不端影响因素熟悉度较低、判断依据的主观性更强,填写数据的可信度、准确性受到影响,因而将这3份问卷视为无效问卷。在剩余19份有效问卷中,专家权威系数均≥0.7,均值为0.77;因素重要性均值除学术自尊外均符合大于3的要求,总体均值为4.20,其中,学术道德素养均数值最高,说明学术道德素养最重要;变异系数均值为0.21,其中,学术自尊、科研诚信教育、科研诚信环境、监督惩罚机制、论文代写代发5个因素变异系数大于0.25,说明专家认同度不够,其中,学术自尊既不符合均数要求也未满足变异系数标准,因而将其删除,其余4个指标在下一轮专家咨询中再次寻求专家建议。第一轮匿名反馈函询结果如表3所示。
(2)第二轮匿名反馈函询结果分析。在向各位专家反馈第一轮函询结果并更新咨询表内容的基础上形成第二轮专家咨询表,发送给原19位专家,回收19份问卷,回收率100%;无效问卷1份,剩余18份有效问卷的专家权威系数均大于0.7,均值约为0.86,符合要求且较上一轮提升0.09;指标均数全部大于3,总体均数为4.65,高出第一轮0.45;变异系数均值为0.11,协同程度较上一轮提升0.10。第二轮匿名反馈函询结果如表4所示。
鉴于第二轮匿名反馈函询结果中各因素评价指标均符合要求且较上一轮函询结果均有所提高,故不再进行第三轮函询。
1.1.6 我国科研数据学术不端影响因素体系构建
本文采用科隆巴赫信度系数法(Cronbach's α),检验内在一致性信度。如表5所示,Cronbach's α=0.701(>0.7),说明量表整体的可靠性较高,信度较高。同时,采用内容效度指数S-CVI/Ave评价量表内容效度,一般而言,平均效度指数大于0.9,说明量表内容效度满足要求[18]。编制“我国科研数据学术不端影响因素问卷内容效度分析”问卷,并在第二轮函询专家中抽选8位专家对问卷内容效度进行打分,选项采用四等级评分,即不相关、弱相关、较强相关、非常相关,分别赋分1、2、3、4。效度检验结果如表6所示,评分总次数为88,得分均为3或4。依据式(6)可知,S-CVI/Ave=1(>0.9),符合要求。
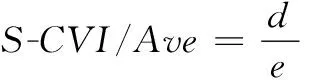
(6)
式中,d代表评分为3或4的总次数,e代表评分总次数。
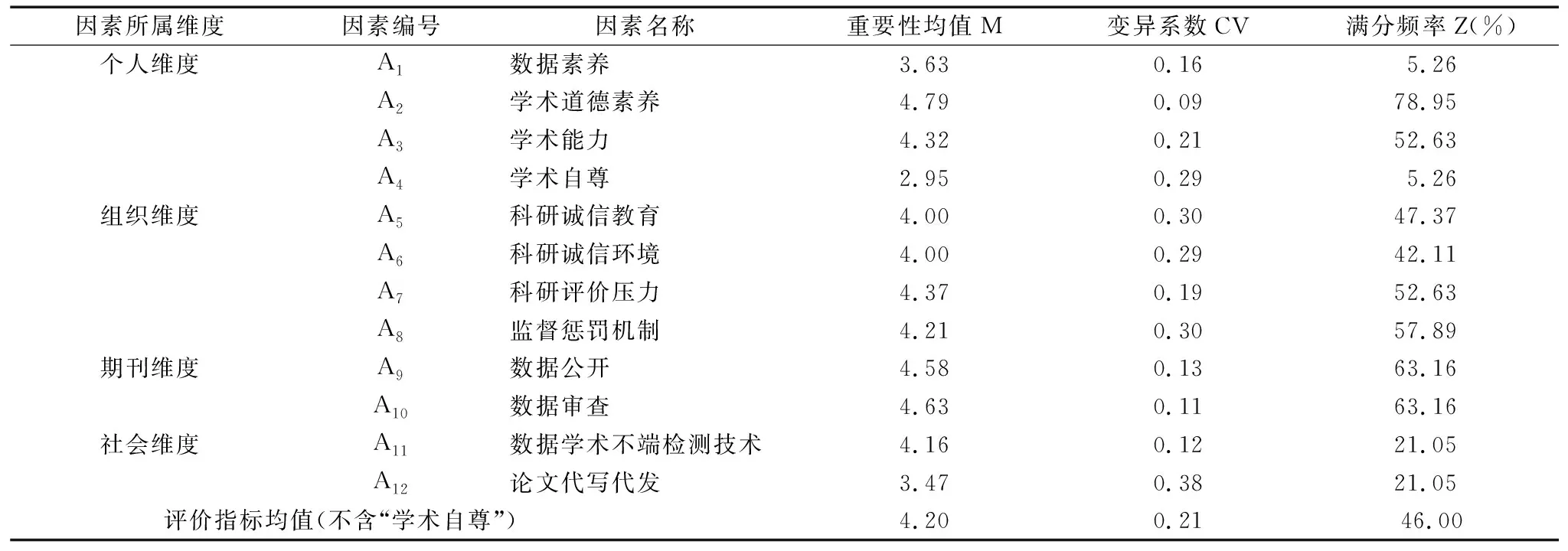
表3 第一轮匿名反馈函询结果Tab.3 Rresults of the first round of anonymous feedback correspondence
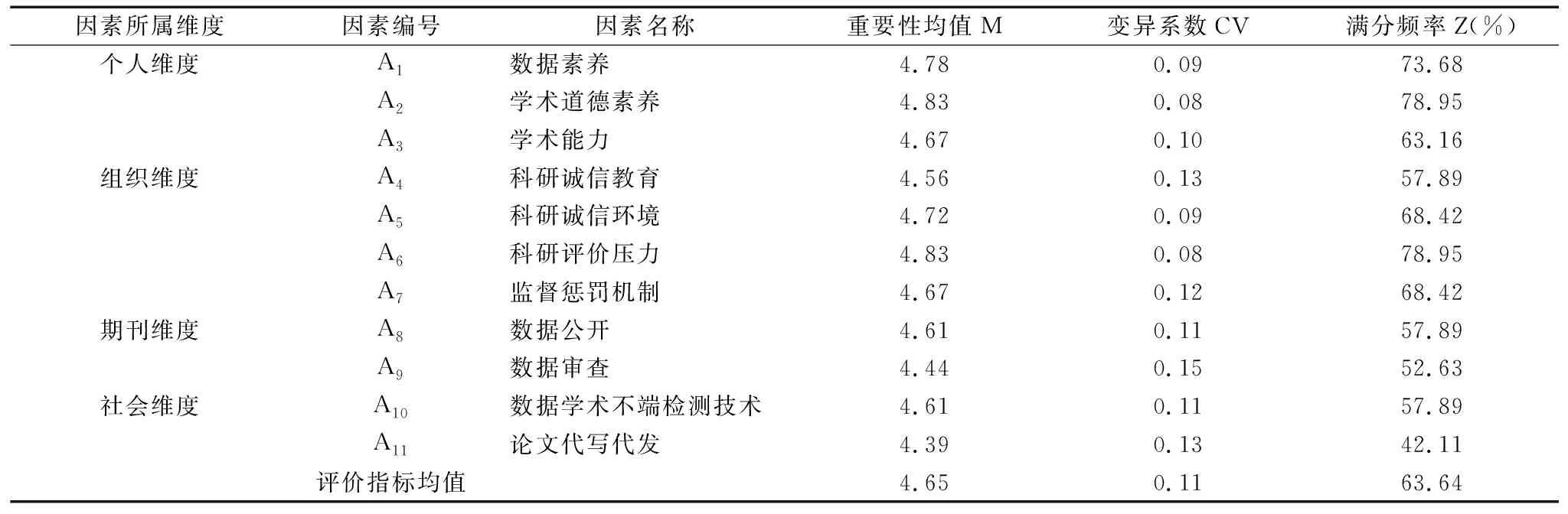
表4 第二轮匿名反馈函询结果Tab.4 Results of the second round of anonymous feedback correspondence

表5 信度检验结果Tab.5 Reliability test results
鉴于第二轮匿名反馈函询结果和问卷信效度检验结果均符合要求,故据此形成我国科研数据学术不端影响因素体系,如表7所示。

表6 效度检验结果Tab.6 Validity test results

表7 我国科研数据学术不端影响因素体系Tab.7 Influencing factor system of scientific research data academic misconduct in China
1.2 我国科研数据学术不端影响因素综合影响矩阵构建
决策实验室分析法(Decision-making Trial and Evaluation Laboratory,DEMATEL)是一种借助矩阵论和图论原理分析复杂系统因素间影响关系的方法。本文借助DEMATEL法,构建我国科研数据学术不端影响因素综合影响矩阵,定量计算、比较分析各因素的原因度、中心度、被影响度、影响度,识别我国科研数据学术不端关键影响因素。
1.2.1 数据收集
首先,根据表7中的科研数据学术不端影响因素体系,抽取影响因素集Ai={A1,A2,…,A11}。其次,编制“我国科研数据学术不端影响因素间直接影响关系调查问卷”,将影响程度划分为5个等级,即无影响、较弱影响、一般影响、较强影响、强影响,分别赋值1、2、3、4、5。最后,邀请对问卷效度打分的原8位专家,对我国科研数据学术不端影响因素间直接影响关系进行打分,得到8份有效问卷。
1.2.2 直接影响矩阵B
将问卷数据按平均法处理,得到直接影响矩阵B=[Bij]n×n,如表8所示。其中,n表示因素个数,n=11。Bij表示因素Ai对因素Aj的直接影响程度,当i=j时,Bij=0。
1.2.3 直接影响矩阵B*规范化
为统一量纲,采用“行和最大值法”对原始矩阵进行归一化处理。将原始矩阵中各因素Bij除以该矩阵中的行和最大值,得到规范化影响矩阵B*。
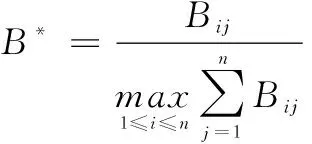
(7)
式中,max代表原始矩阵B中因素行和最大值。
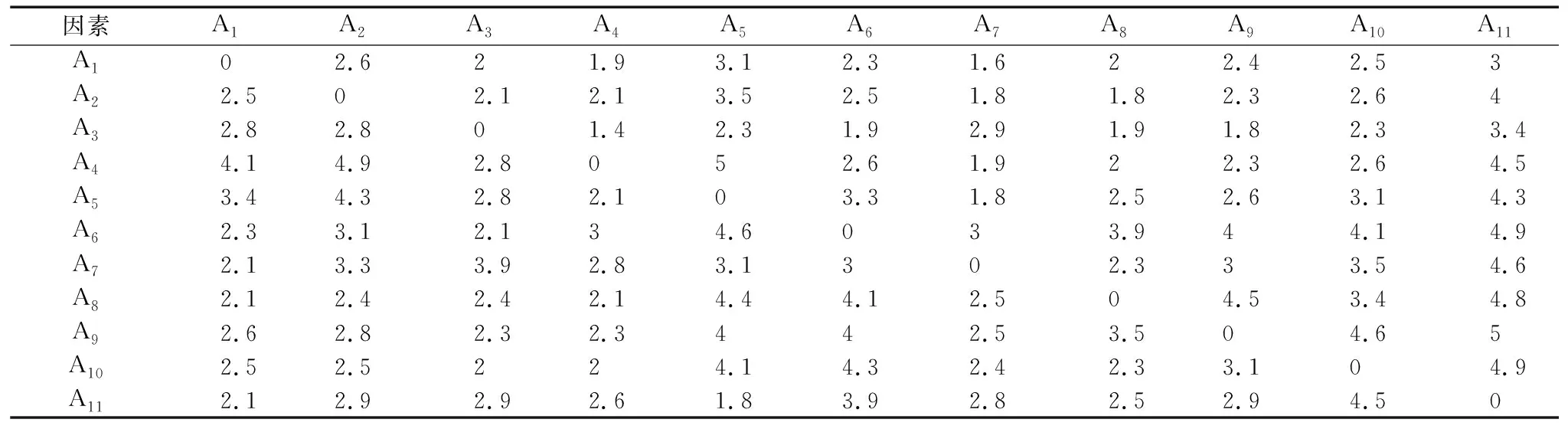
表8 直接影响矩阵B Tab.8 Matrix B of direct impact
1.2.4 综合影响矩阵C
复杂系统不仅受到众多因素影响,而且因素之间也因受到反馈性和非线性影响而存在包含直接影响关系和间接影响关系的复杂关系[19]。故此,在规范化直接影响矩阵B*的基础上,根据公式(8),得到同时反映系统要素间直接和间接影响关系的综合影响矩阵C,如表9所示。
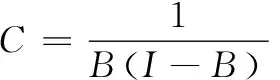
(8)
式中,I为单位矩阵。
1.2.5 “四度”计算
以综合影响矩阵C为基础,计算“四度”,明晰因素因果属性和重要程度,为识别我国科研数据学术不端关键影响因素奠定基础。
影响度D值是因素行之和,指该因素对其它因素的综合影响程度,计算公式见式(9)。被影响度E值是因素列之和,指其它因素对该因素的综合影响程度,计算公式见式(10)。中心度F值是影响度与被影响度之和,指该因素在系统中的重要程度,该值越大,说明该因素在系统中越重要,计算公式见式(11)。原因度G值是影响度与被影响度之差,指该因素对其它要素的影响情况,原因度值大于0说明该因素对其它因素综合影响更大,原因度小于0说明该因素受其它因素的综合影响更大,计算公式见式(12)。计算结果如表10所示。
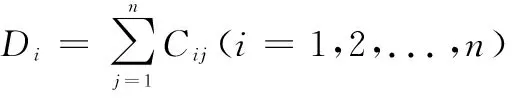
(9)
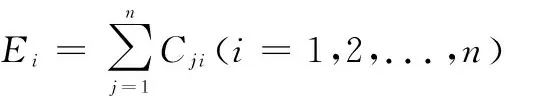
(10)
Fi=Di+Ei(i=1,2,...,n)
(11)
Gi=Di-Ei(i=1,2,...,n)
(12)

表9 综合影响矩阵C Tab.9 Matrix C of comprehensive influence

表10 影响度、被影响度、中心度与原因度计算结果Tab.10 Calculation results of influence degree, affected degree, centrality degree and cause degree
1.2.6 因素关系图、因果关系图绘制
我国科研数据学术不端影响因素关系图,如图2所示。以表9数据为基础,将中心度F作为x轴,将原因度G作为y轴,绘制我国科研数据学术不端影响因素因果关系图,如图3所示。
1.3 我国科研数据学术不端影响因素多级递阶结构模型构建
解释结构模型法(Interpretative Structural Modeling Method,ISM)是一种在保证系统整体功能完整的前提下,以最简有向拓扑图形式展示系统结构的研究方法。本文借助ISM模型优势,划分我国科研数据学术不端影响因素间逻辑关系,并借助层级图使影响因素间逻辑层次、关系结构一目了然。
1.3.1 整体影响矩阵H计算
鉴于综合影响矩阵C未考虑因素对自身的影响,故引入单位矩阵I,形成整体影响矩阵H[20]。计算公式如式(13)。
H=C+I
(13)
1.3.2 可达矩阵K计算
鉴于决策实验室法采用1~5五级赋分法划分因素间影响程度,而解释结构模型采用二级法,用1和0代表因素间有无关系[21],故引入阈值λ筛除整体影响矩阵H因素间弱影响关系,简化关系层次。本文在遵循数据内在规律的基础上,借助统计分布的均值和标准差确定阈值λ。根据综合影响矩阵C,计算得出α=0.511 5,β=0.118 0。
λ=α+β
(14)
式中,λ∈[0,1], α和β分别代表综合影响矩阵C中所有因素的均值、标准差。根据公式(14)计算得出,λ=0.629 5。
根据公式(15),得到可达矩阵K,如表11所示。
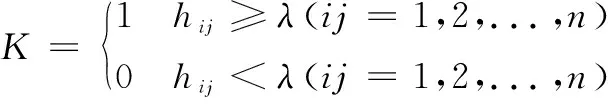
(15)

图2 我国科研数据学术不端影响因素间关系Fig.2 Relationship between influencing factors of academic misconduct in scientific research data in China
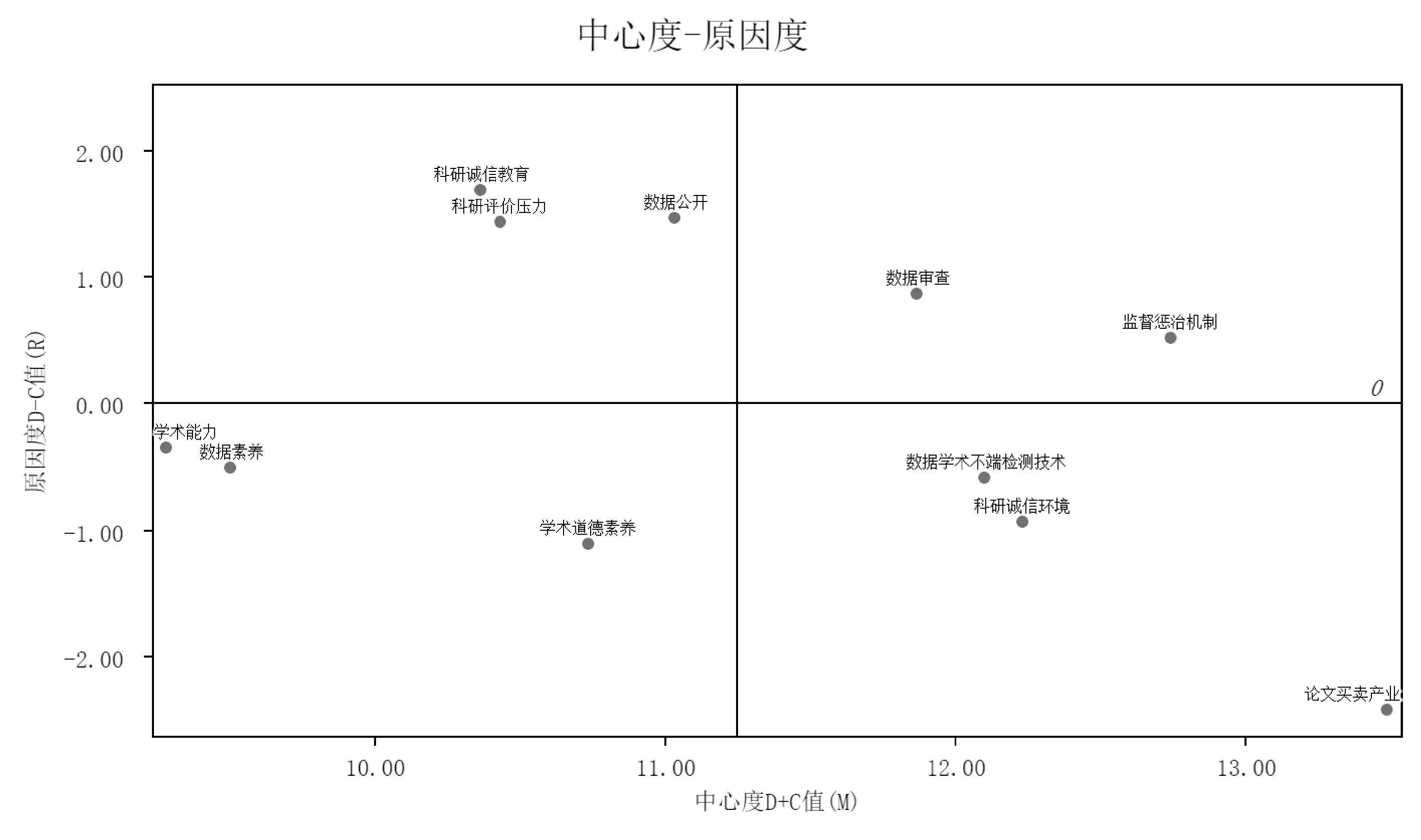
图3 我国科研数据学术不端影响因素间因果关系Fig.3 Causal relationship of influencing factors of academic misconduct in scientific research data in China

表11 可达矩阵K Tab.11 Reachable matrix K
1.3.3 多级递阶结构模型构建
以可达矩阵K为基础,根据公式(16)、(17)、(18),依次形成可达集L、先行集M及其交集R。
L(ai)={aj|aj∈A,Kij=1}(i=1,2,...,n)
(16)
M(ai)={aj|aj∈A,Kji=1}(i=1,2,...,n)
(17)
R(ai)=L(ai)∩M(ai)(i=1,2,...,n)
(18)
可达集L是可达矩阵中要素ai所在行中值为1的列要素集合,集合中所有因素ai都能到达;先行集M是可达矩阵中要素ai所在列中值为1的行要素的集合,集合中所有因素ai都能到达;交集R表示可达集合L和先行集合M的交集,结果如表12所示。
当因素ai满足L(ai)=R(ai)时,代表可达集L中的因素ai都能在先行集M中找到前因。故此,因素ai被划分到最顶层O1。从可达集和交集中删除之前满足条件的因素,再重复以上步骤迭代划分,直到所有因素都被确定层级。依据层级划分结果,构建我国科研数据学术不端影响因素多级递阶结构模型,如图4所示。

表12 可达集L、先行集M、交集R Tab.12 Reachable set L, antecedent set M and intersection R
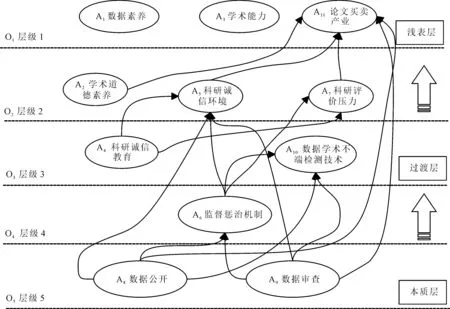
图4 我国科研数据学术不端影响因素多级递阶结构模型Fig.4 Multi-level hierarchical structure model of the factors affecting the academic misconduct of scientific research data in China
2 研究结果分析
2.1 我国科研数据学术不端影响因素体系分析
本文基于匿名反馈函询法,识别出我国科研数据学术不端影响因素11个。其中,个人维度包含3个因素,分别是数据素养(A1)、学术道德素养(A2)、学术能力(A3);组织维度包含4个因素,分别是科研诚信教育(A4)、科研诚信环境(A5)、监督惩治机制(A6)、科研评价压力(A7);期刊维度包含2个因素,分别是数据公开(A8)、数据审查(A9);社会维度包含2个因素,分别是数据学术不端检测技术(A10)、论文代写代发(A11)。
2.2 我国科研数据学术不端关键影响因素分析
在11个因素中因素A6的影响度最高,说明监督惩治机制对其它因素的综合影响程度最高。按影响度排序为:A6>A9>A8>A4>A7>A10>A5>A11>A2>A1>A3。因素A11、A5、A10、A6、A2、A9的被影响度排名较高,说明它们更易受其它因素影响。从综合影响度和被影响度来看,因素A6、A9、A10排名较高,说明完善监督惩治机制、加强数据审查、改进数据学术不端检测技术有助于防范我国科研数据学术不端。
由图3可知,11个影响因素共坐落于4个象限。其中,位于第一象限的A6、A9原因度大于0且中心度大于平均数,说明监督惩治机制、数据审查不仅对其它因素的综合影响程度大于受其它因素的综合影响程度,而且在系统中发挥关键作用,属于“原因型关键因素”。第二象限的A4、A7、A8原因度大于0但中心度低于平均水平,说明科研诚信教育、科研评价压力、数据公开虽更易影响其它因素但发挥的作用有限,属于“影响型因素”。第三象限因素原因度小于0且中心度小于平均值,说明数据素养、学术道德素养、学术能力更易受其它因素影响且在系统中重要程度较低,属于“结果型因素”。位于第四象限的A5、A10、A11原因度小于0但中心度高于平均水平,说明科研诚信环境、数据学术不端检测技术、论文代写代发更易受其它因素影响但在系统中发挥关键作用,属于“结果型关键因素”。
综上,我国科研数据学术不端关键影响因素有5个,按中心度排序依次为:数据审查>数据学术不端检测技术>科研诚信环境>监督惩治机制>论文代写代发。
2.3 我国科研数据学术不端影响因素间层次关系分析
我国科研数据学术不端影响因素分为浅表层、过渡层、本质层,3个层次从上到下代表影响因素对我国科研数据学术不端的影响程度逐渐加深,3个层次从下到上代表我国科研数据学术不端影响因素间因果逻辑关系,其中,层级1(O1)属于浅表层,是影响我国科研数据学术不端的直接因素,包含数据素养(A1)、学术能力(A3)、论文代写代发(A11)3个因素;层级2(O2)、层级3(O3)、层级4(O4)属于过渡层,是影响我国科研数据学术不端的间接因素,包含学术道德素养(A2)、科研诚信环境(A5)、科研评价压力(A7)、科研诚信教育(A4)、数据学术不端检测技术(A10)、监督惩治机制(A6)6个因素。层级5(O5)属于本质层,是影响我国科研数据学术不端的根源因素,包含数据公开(A8)、数据审查(A9)两个因素。
同时,本文发现各因素不是独立作用于我国科研数据学术不端,而是在作用过程中交互影响,形成有向链条结构。这种交互作用主要体现在跨级因素间,比如本质层的数据公开因素跨级影响过渡层的监督惩治机制、浅表层的论文代写代发。再比如,层级4的监督惩治机制跨级影响层级3的数据学术不端检测技术、层级2的科研诚信环境。
3 结论与建议
3.1 主要研究结论
先前研究侧重在论文完成后、出版前环节探讨防范科研数据学术不端的方法,而本文力求探寻科研数据学术不端的关键影响因素和因素间逻辑层次关系,基于此构建预防机制,可以从源头上遏制科研数据学术不端苗头,减少科研数据学术不端现象,对预防我国科研数据学术不端,减少科研资源浪费,优化学术生态环境具有一定指导意义。
(1)采用匿名反馈函询法构建我国科研数据学术不端影响因素体系,抽取影响因素集,发现我国科研数据学术不端受多元因素综合影响,包含个人、组织、期刊、社会4个维度11个因素。
(2)利用DEMATEL法生成综合影响矩阵,计算并分析影响因素“四度”,明晰因素因果属性及其重要程度,识别出科研诚信环境、监督惩治机制、数据审查、数据学术不端检测技术、论文代写代发属于我国科研数据学术不端关键影响因素。
(3)基于ISM模型构建我国科研数据学术不端影响因素多级递阶结构模型,形成最简层次化有向拓扑图,深入分析因素间逻辑层次关系,将因素划分为5个层级、3个层次(浅表层、过渡层、本质层)。
3.2 对策建议
根据以上研究结论,对我国科研数据学术不端预防机制构建提出以下思路。
3.2.1 综合多元因素,协调多方配合
由我国科研数据学术不端影响因素体系可知,我国科研数据学术不端受到多元因素、多个主体交互作用。因此,建议采用反馈控制理论方法进行动态闭环管理,即在监测科研数据学术不端动态的基础上,根据阶段性变化特征,动员多方主体,综合多元因素,系统性地调动影响因素,预防科研数据学术不端行为。具体而言,我国科研人员应提高自身数据素养、学术道德素养、学术能力,坚守学术道德底线;科研人员所在组织单位应加强科研诚信教育、改善科研诚信环境、完善监督惩治机制、优化科研评价体制,打造良好的科研诚信氛围和动力机制;期刊应完善数据公开、审查制度,对科研人员数据学术不端行为产生震慑;社会层面应注重改进科研数据学术不端检测技术,遏止论文代写代发发展。
3.2.2 把握关键制控点,强化推动作用
把握关键制控点,发挥重要推动作用,重点关注科研诚信环境、监督惩治机制、数据审查、数据学术不端检测技术、论文代写代发5个关键因素。科研诚信环境,会潜移默化地影响科研人员的学术道德素养和学术价值观。完善匿名举报制度,切实保障举报人信息安全,有效改善我国科研人员诚信环境;监督惩治机制是约束我国科研人员数据学术不端行为的有力手段,需要科研单位、科研诚信主管部门、基金项目负责部门、期刊出版机构和数据库机构等多方主体联合执行,通过提高科研数据学术不端成本,达到减少科研数据学术不端事件的目的;期刊应规范论文数据审查流程,增设数据审查环节,提高编辑数据审查能力;算法研究人员、软件开发者和数据库机构应协同研发检测精度更优、检测效率更高、学科适用性更强的科研数据学术不端检测技术,提高防范数据学术不端的能力;论文代写代发产业依托互联网技术、网络交易平台,利用行政制裁短板、民事制裁漏洞,形成灰色产业链,应采用高额罚款方式惩治论文卖家,采用行政罚款和名誉惩治方式惩治买家,使得买卖双方有所忌惮,对买卖论文望而却步。
3.2.3 立足层次关系,开展阶梯管理
基于我国科研数据学术不端影响因素多样化、结构层次化、作用差异化特征,建议立足层级关系,遵循因素自身作用规律,采用阶梯式向下深入和分类管理方式。具体而言,依据浅表层影响因素对我国科研数据学术不端的直接作用,采用全面铺开、逐个引导的方式,即相关机构全面关注数据素养、学术能力、论文代写代发3个因素,不能顾此失彼,且鉴于因素间独立性,需逐个引导单个因素往积极方向发挥作用,达到快速生效的目标;鉴于过渡层影响因素的间接作用,采用集中火力、重点落实的方式,即在适度引导学术道德素养、科研诚信教育、科研评价压力、科研数据学术不端检测技术等因素的同时,有针对性地重点控制与多因素存在因果关联的科研诚信环境和监督惩治机制,实现高效解决的目标;鉴于本质层影响因素的根源性作用,采用追本溯源的高质量分析方式,即完善数据公开、数据审查制度,从源头遏止,达到长期稳固的治标目标。这种阶梯式分类管理方式可以解决以往忽视因素间作用差异性的问题,将3种层次的管理方式融合为一个有机整体,共同构建我国科研数据学术不端预防机制。并且,不同管理方式相互配合,既有引导又有惩治,协同发挥作用,形成良性循环。
猜你喜欢
计算机应用(2022年2期)2022-03-01
工程建设与设计(2021年11期)2021-07-28
共产党员(辽宁)(2019年3期)2019-11-18
军事运筹与系统工程(2019年2期)2019-11-16
共产党员·上(2019年2期)2019-03-29
支部建设(2017年30期)2017-11-24
宠物世界·猫迷(2016年3期)2016-04-23
党的生活(2016年2期)2016-03-12
少儿科学周刊·少年版(2015年3期)2015-07-07
肝胆胰外科杂志(2015年4期)2015-02-27
