
基于小样本数据统计的双阶段舌位建模研究*
2023-10-24 06:25:26徐正丽肖素芳杨明浩
广西科学 2023年4期
徐正丽,肖素芳**,简 敏,杨明浩
(1.桂林电子科技大学,广西桂林 541004;2.中国科学院自动化研究所,北京 100190)
舌头是人类重要的发音器官,其形变是人类能够发音的关键,对舌头形状的分析及建模是语音生成领域中的一项重要工作[1-4]。舌头属软组织结构,发音过程中舌头会产生较大变形,从而产生复杂的声道结构。但舌头主要隐藏在口腔内,致使人们难以直接观察舌头发音形状(即舌位),因此对舌位轮廓分析及建模一直是语音分析中的难点之一。在传统的实验语音学领域,人们提出了多种舌位模型来研究舌运动导致的声道结构变化和语音之间的关系。20世纪70年代初,语言学家和言语病理学家从X光片中手动标记舌头轮廓,并使用主成分分析(Principal Component Analysis,PCA)方法获得舌头运动模式[5,6],发现在元音生成中前两个主要成分所占比重为90%以上,即元音对应的舌头变形可通过前两个维度参数进行描述。平行因子分析(PARAFAC)也是一种广泛应用的舌位轮廓分析工具[7-11]。通过分析10个英语元音的13个横截面平行因子,研究者发现发出10个英语元音时舌位变化可分解为两个主要运动因素:一是舌根向前运动的同时伴随着舌头前部的向上运动;二是整个舌体的向上和向后运动。然而,PARAFAC并不具备从低维数据分布中重建舌位轮廓的能力[11,12]。此外,与舌头运动建模相关的研究还包括基于元音的流形表示[13]、舌头轨迹的可视化[14-16]、基于语音驱动的舌面[2,17,18]和基于径向基函数(Radial Basis Function,RBF)的B样条拟合[19],基于机器学习的复杂三维有限元生物力学模型[20],基于集总元件模型的舌尖、舌外侧下侧和软腭前侧的平均感知方法[21]、舌苔瘀点的检测方法[22]等,这些方法侧重于从文本、语音记录、舌位受到刺激的反应以及舌噪声图像等方面对舌头运动轨迹和病理进行研究,但并未研究重建舌形以及建立舌位与语音之间的对应关系。
随着深度学习技术的兴起,研究人员将深度神经网络应用到舌位图像分析以及轮廓提取工作中,如Ruan等[23]提出了基于U-Net的舌头分割模型,从整个舌头图像中准确地分割出舌头主体;Ploumpis等[24]提出了生成3D舌面的新型生成对抗网络(Generative Adversarial Network,GAN),将舌位3D模型生成与面部细节重建进行关联;Mansour等[25]提出了基于深度神经网络的人类舌头图像疾病分类模型。虽然这些方法在舌头图像边缘提取、舌头表面纹理细节处理等方面取得了较好效果,但未能很好地对舌位轮廓进行压缩、重建和分析等[26-28]。
近年来,基于深度学习的自动编码器(Autoencoder)在数据降维和模式挖掘等方面表现良好[29],如面向图像的深度卷积网络自编码器能有效提取低维图像特征[30],降噪自编码器(Denoising Auto Encoder,DAE)在序列数据处理和模式发现等方面表现出良好性能[31-33]等。然而,目前还未见将基于深度学习的自动编码器用于舌位分析的研究,这主要是因为基于深度学习的自动编码器在训练中需大量数据,但由于舌头在口腔中的隐蔽性,真实舌位数据难以大量获得。一些学者通过添加噪声数据或使用Dropout技术来增加数据样本的方式提高小样本深度学习DAE的性能[29,31,32],这两种方法由于能生成更多有效的训练数据,因此能够提升网络从少量真实数据中提取特征的能力[31,34,35]。一般来说,舌头运动的前部较后部对发音过程的影响更大,因此基于平均随机理念的Dropout技术并不适用于舌位数据增强。
描述舌位运动的高性能模型既要维度低又要准确性高[26-28]。低维度表示有利于揭示舌头运动模式以及精准确定舌头运动模式与发音结构间的映射关系。为建立高性能且保持深度结构特征的舌位模型,本文提出一种双阶段自编码器舌位模型,其第一阶段首先利用符合生理特征的舌位变形数据构建大规模的形变舌位轮廓样本,再训练一个n层堆叠的舌位轮廓自编码器;第二阶段在舌位轮廓自编码器的基础上添加具有少量隐藏单元的第(n+1)层组成最终的自编码器。
1 研究方法
1.1 舌位轮廓标准化
本文采取传统方法对舌位轮廓进行标准化处理。图1(a)中有18条网格线(即图中序号为1-18的线条),主要舌形区域对应着网格4-17的横截面段,因此使用网格线4-17(共13条横截面)来描述声道结构。首先确定上齿和上腭的尖端,然后将从齿尖点沿腭到会厌的轮廓作为不同声道结构的参考截面,最后将舌头表面和腭之间的归一化横截面范围作为编码器网络的输入。这13条网格线从参考截面到舌片表面(与背景正交)的线段长度可用于舌位分析。
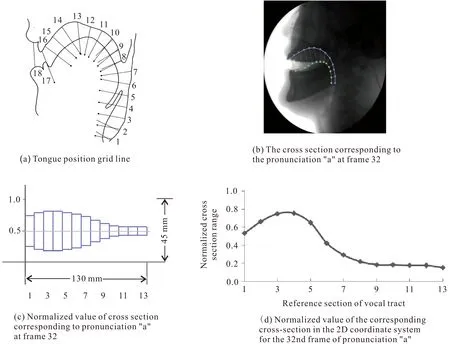
图1 舌位轮廓标准化
本文使用网格线长度的归一化值用于编码器网络训练。归一化函数如式(1)所示,
(1)
式中,Γifj=(Gifj/Vifj)η,i∈{1,2,…,13}表示第i个舌位轮廓线;f和j是舌位轮廓数据集中第j个音素发音阶段的第f帧;V是中矢状面上声道的最宽横截面距离(根据前人研究,本研究将V设置为45 mm),ζifj和Γifj分别表示归一化和非归一化网格线长度,η是从舌尖到舌根的实际舌长。通常成年男性的舌长约175 mm,女性约140 mm。Gifj和Vifj是以像素为单位的网格线长度和舌位长度,可直接从X射线图片中获取[36]。
以元音“a”为例,图1(b)显示了其发音第32帧对应的13个横截面长度分布;图1(c)则以管状模型形式显示了从舌尖到舌根的形状,即舌头运动时对应的声道侧面结构;图1(d)给出了从舌尖到舌根的13条网格线ζi,32,a,i∈{1,…,13}所对应的归一化长度值。
1.2 舌位轮廓形变
由于舌头的隐蔽性,舌位数据通常难以大量获取,其真实数据的样本量较小,但本文算法模型需采集大规模舌位轮廓数据才能进行有效训练。为此,本文通过添加噪声到原始的小规模真实舌形数据集来构建大规模的舌位轮廓数据集。考虑到人类发音的舌位不能随机改变,本文采取主动形状模式(Active Shape Mode,ASM)[37,38]来产生可能存在于用来训练第一阶段舌位轮廓自编码器的舌位轮廓数据的生理变形,如式(2)所示。
(2)
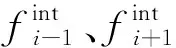
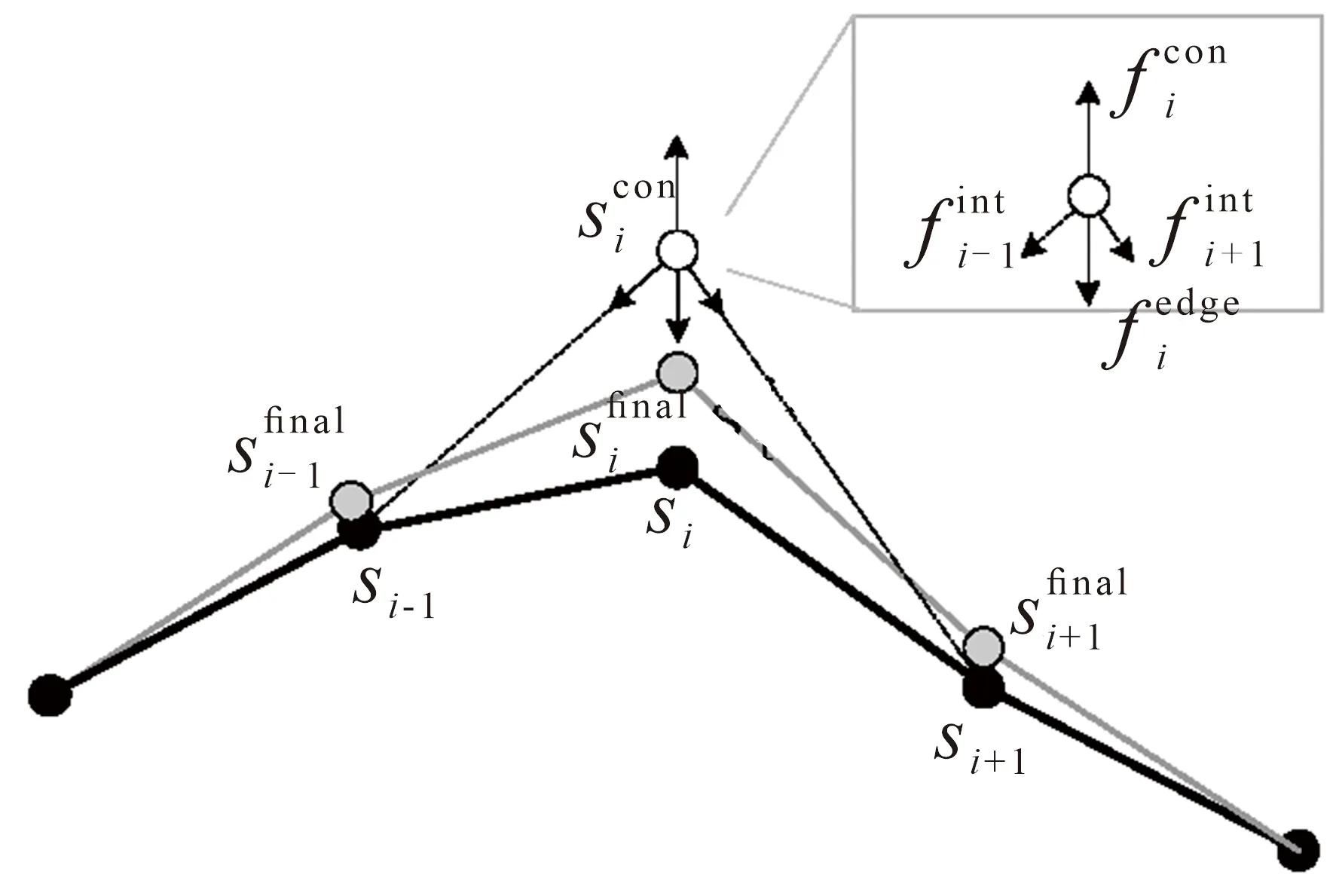
图2 舌位控制点形变示例
1.3 本文算法模型
本文将第一阶段网络结构定义为舌位轮廓自编码器(Tongue Shapes Denoising Auto Encoder,TS-DAE) [图3(a)],第二阶段定义为舌位轮廓降维编码器(Tongue Shape Dimensionality Reduction AutoEncoder,TSDR-AE) [图3(b)]。为提升TS-DAE所需的样本数量,本文采用符合生理特征的舌头形变数据构造大量的舌位轮廓数据,从而扩充第一阶段n层网络结构所需的样本,然后再使用真实舌位运动轮廓数据微调TSDR-AE网络的第(n+1)层。
1.4 舌位轮廓自编码器(TS-DAE)
基于ASM对舌头轮廓的变形能够产生大规模且保持一定生理特征的舌位轮廓数据。如图3(a)所示,其最底部为真实舌位发音轮廓,在其上方矩形框中的轮廓为ASM所产生的变形舌位轮廓。基于这些变形舌位轮廓,TS-DAE可对舌位轮廓进行有效的自动编码。首先,增强的舌位轮廓通过TS-DAE编码器[图3(a)中的浅橙色框A]可以获得指定维度的特征表示。然后,将TS-DAE编码器连接与之完全对称的TS-DAE解码器[图3(a)中的虚线框A′],对输入的舌位进行重建。TS-DAE的舌位轮廓重建性能由生成的舌位重建轮廓[图3(a)顶部的虚线轮廓]与原始舌位轮廓[图3(a)下方实线轮廓]的差异值来评估,差异值越小说明TS-DAE的舌位轮廓重建性能越好。
1.5 舌位轮廓降维编码器(TSDR-AE)
由于TS-DAE输出数据维度较高,为实现舌位轮廓压缩,本文将具有少量隐藏单元的网络层堆叠到TS-DAE顶部,进而形成总共有(n+1)层的TSDR-AE。TSDR-AE对舌位轮廓的编码和解码过程如图3(b)所示。同TS-DAE一样,TSDR-AE也由结构对称的编码器和解码器构成。TSDR-AE的编码器[图3(b)中的浅蓝色实线框B]包含了TS-DAE的编码器,其解码器[图3(b)中的虚线框B′]也包含了TS-DAE的解码器。TSDR-AE的最上层添加了维度较小的节点[图3(b)中灰色部分],并用TSDR-AE解码器解码舌位轮廓低维度的特征表示,最终获得重建的舌位轮廓数据。TSDR-AE的舌位轮廓重建性能由所生成的舌位重建轮廓[图3(b)上方虚线轮廓]与原始舌位轮廓[图3(b)下方实线轮廓]之间的差异来评估,差异值越小,TSDR-AE的舌位轮廓重建性能越好。
2 实验与结果分析
2.1 数据准备
X光片发音数据在发音观测上具有较好的时间分辨率[37,38],目前被广泛用于语音生成领域。本研究的舌头形状取自中国女性发音X光片视频所获得的舌位轮廓视频,包含20个音素(包括普通话元音)和181个音节。X射线图像分辨率为640×480。发音者舌头形状用公式(1)进行归一化处理。每个元音持续35-50帧,每帧时长约30 ms。本研究以5个典型元音(“a”、“i”、“u”、“e”、“o”)为对象,选取了对应的240个真实舌形及6 000个生成的形变轮廓作为训练和测试数据来验证所提出的双阶段自动编码器方法的性能。
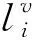
由于发音过程中前舌较舌头后部会发生更大形变,本研究的舌位形变单元更多产生在上述13个节段的前6个。本文通过120个真实舌头形状构建了6 000个变形轮廓,其中5 000个用于第一阶段TS-DAE神经网络训练,1 000个用于第一阶段TS-DAE网络性能评估。在舌位轮廓降维编码阶段,从240个真实的舌位轮廓中随机抽取120个舌形用于微调TSDR-AE,其余的120个舌形则用于TSDR-AE网络性能评估。
2.2 自编码器舌位模型网络结构
为实现TS-DAE和TSDR-AE两阶段在结构及性能等方面的均衡分布,本文还对网络结构进行了优化。通常,隐藏层在获得足够单元输入的前提下,自动编码器能够拟合任意数据分布。在实践中,隐藏单元数为输入单元数的10倍左右时,自编码器即能产生较好结果。由于输入矢量包含了13个单元节段,且TSDR-AE输出层要求节点数较少,因此,TS-DAE可被构建为“13-15”、“13-150-15”、“13-150-30-15”以及“13-150-60-24-15”等层级网络结构。实验使用原始舌形与模型重建的舌形间的皮尔逊相关系数(Pearson Correlation Coefficient,PCC)和均方误差(Root Mean Square Error,RMSE)来评估模型的性能(图4),其中PCC的值越大越好,RMSE的值越小越好。从图4可见,“13-150-15”网络结构相对于其他3个网络结构能获得较理想的PCC和RMSE,尤其是RMSE明显更优。因此,本文将进一步使用该网络构建(n+1)层的TSDR-AE网络结构。
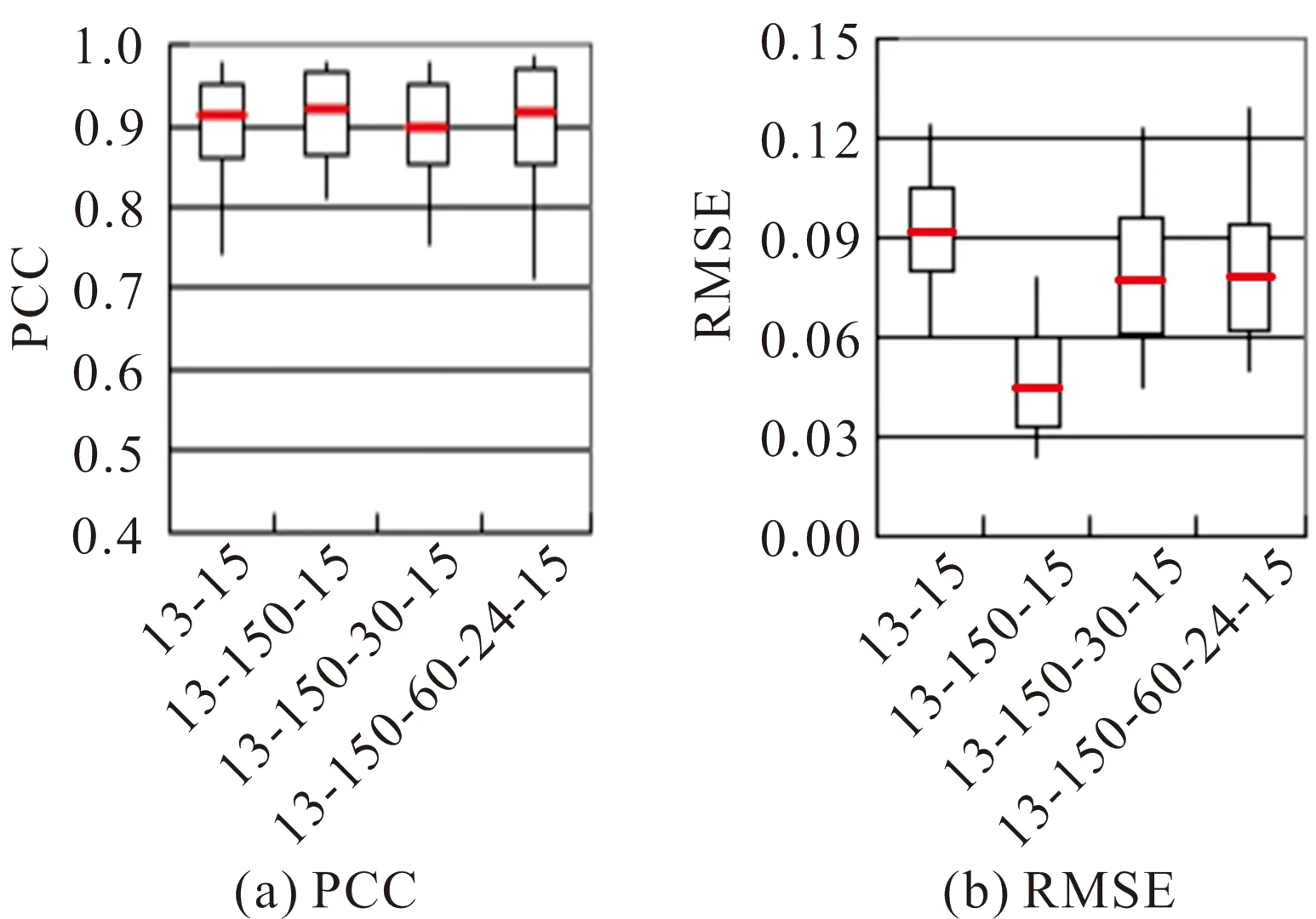
图4 4种网络结构的PCC和RMSE的平均值、最大值、最小值和方差范围比较结果
实验将舌位轮廓压缩在2个因子内(即TSDR-AE的输出层单元为2)进行分析和比较。因此,本文在第一阶段TS-DAE的顶部附加了“15-2”自动编码器,构建了“13-150-15-2”堆叠的TSDR-AE。为验证本文模型[13-150-15-2 (the proposed)]性能,将其与标准的2层“13-2”自编码器模型(13-2 AE)、采用Dropout技术进行数据增强的“13-150-15-2”DAE模型[13-150-15-2 DAE (DRPT)]、使用形变进行舌位增强数据训练的“13-150-15-2”DAE模型[13-150-15-2 (DFRM)]进行实验比较。其中,将13-2 AE模型和13-150-15-2 DAE (DRPT)模型在120个真实舌位轮廓上进行Dropout训练;对13-150-15-2 DAE (DFRM)模型使用了5 000个变形舌位轮廓进行训练。本文所提出的TSDR-AE模型训练过程与上述13-150-15-2 DAE (DFRM)类似,但额外随机抽取了120个真实舌形数据对其进行训练及微调。
本文采取上述4种模型来验证120个原始舌形与重建舌形间的PCC和RMSE,图5是对比结果的箱线图。由图5(a)可知,13-150-15-2 (the proposed)模型的PCC值高于其他3种模型。同时,由图5(b)可知,13-150-15-2 (the proposed)的RMSE比其他3种模型更小,说明其误差更小。以上结果充分表明13-150-15-2 (the proposed)模型所重建的舌位轮廓与真实舌位轮廓更为接近,说明该模型具有更好的舌位轮廓重建性能。
2.3 与PCA的重建性能比较
PCA是语音学领域用于舌位轮廓压缩和重建的常见降维工具[5,37,38]。这里进一步比较13-150-15-2 (TSDR-AE)网络结构和PCA对真实舌位轮廓的重建性能。根据多名学者利用PCA模型在舌位轮廓上的分析结果[5,37,38],PCA舌位模型的前2-4个主成分通常占所有成分的95%以上。图6为120个测试舌形上PCA和13-150-15-2 (TSDR-AE)模型的PCC和RMSE的结果,其中PCA_iD项中的i表示采用前i个分量的PCA重建结果。
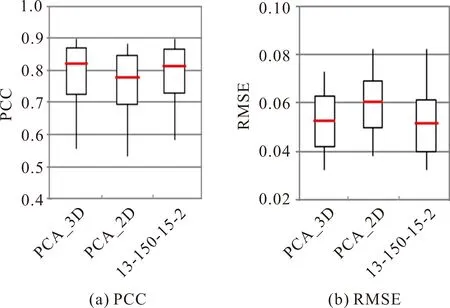
图6 PCA (2D,3D)模型和13-150-15-2 (TSDR-AE)模型在120个测试舌位轮廓上重建与原始舌位的PCC和RMSE的平均值、最大值、最小值和方差范围比较结果
从图6(a)可以看到,13-150-15-2 (TSDR-AE)模型重建的舌位轮廓与原舌位轮廓的PCC平均值为0.83。相对于PCA_2D的0.77以及PCA_3D的0.81,13-150-15-2 (TSDR-AE)模型的PCC值比PCA_2D和PCA_3D的更高。这说明与PCA相比,该文模型把舌位轮廓压缩到二维后重建的舌位轮廓与原舌位轮廓更相似。
由图6(b)可知,13-150-15-2 (TSDR-AE)模型重建的舌位轮廓与原舌位轮廓的RMSE平均值为0.05。相对于PCA_2D的0.06以及PCA_3D的0.05,该模型并不逊色,这说明该模型在把舌位轮廓压缩到二维然后重建的舌位轮廓与原舌位轮廓的误差更小。综上,13-150-15-2 (TS-DAE)模型将舌位轮廓压缩到二维后重建的舌位轮廓比PCA压缩舌位轮廓到二维和三维后重建的舌位轮廓更好。
2.4 元音二维发音图谱分布性能比较
为更直观地验证所提模型性能,实验分别使用PCA_2D模型和本文模型将240个舌位轮廓压缩为二维变量并投影到2D坐标系,相应投影点分布如图7(a)、图7(b)所示。其中的不同元音投影点分别采用不同颜色符号进行标识,元音“i”用绿色方块标识、元音“e”用红色加号标识、元音“u”用深蓝色五角星符号标识、元音“o”用紫色圆形符号标识、元音“a”用浅蓝色三角形符号标识。
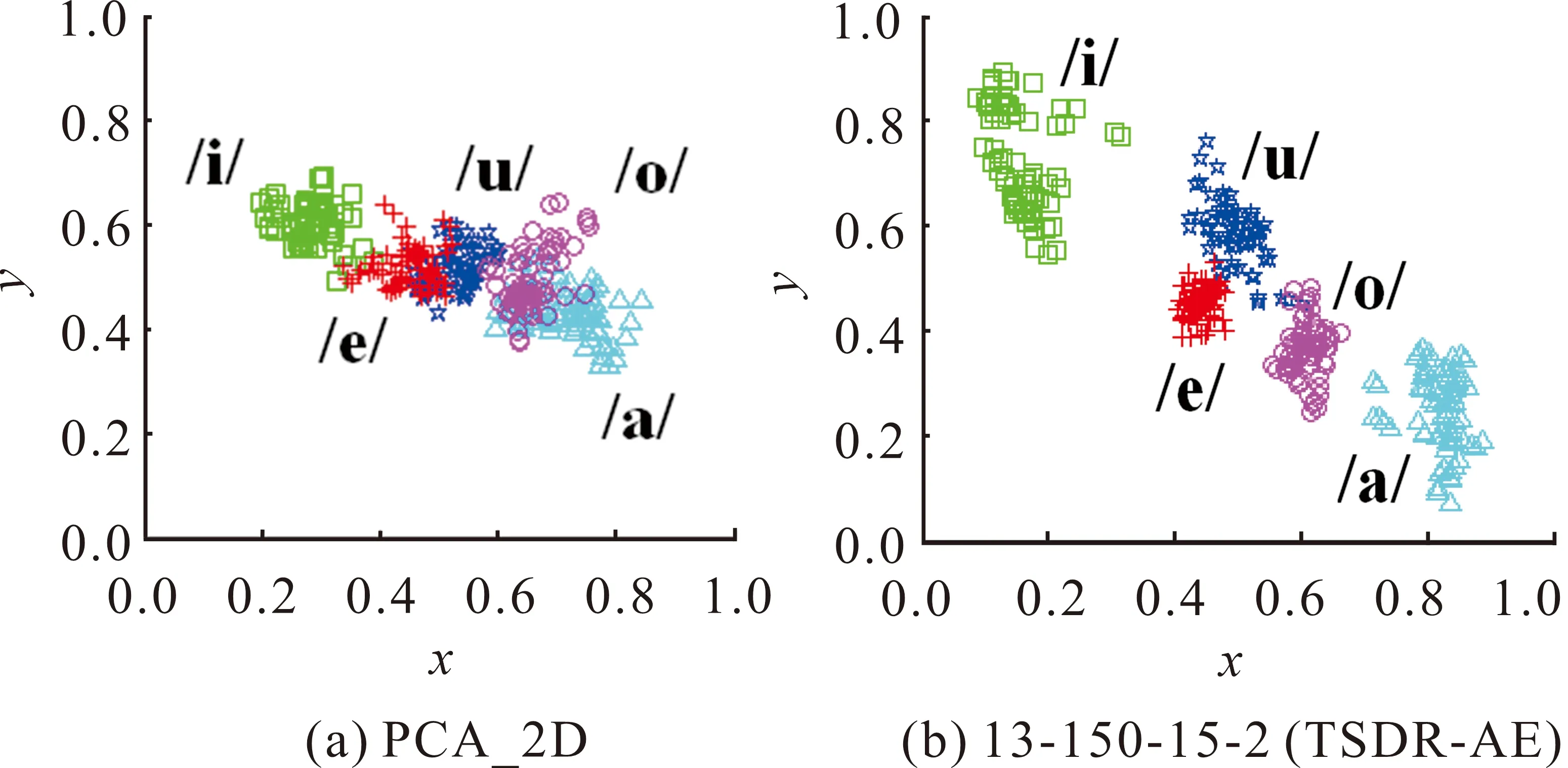
图7 汉语元音发音舌位轮廓降维到二维的可视化结果
由图7(a)可知,不同元音间的二维投影点存在较多重叠,“u”(蓝色区域)和“e”(红色区域)重叠较多,“a”(浅蓝色区域)与“o”(紫色区域)重叠也非常明显,这意味着PCA_2D模型所获得的不同元音舌形并不利于区分。
由图7(b)可知,5个元音的发音被13-150-15-2 (TSDR-AE)划分为5个簇,其中“i”与“a”的簇间距离比图7(a)中的“i”与“a”更远,仅有“u”与“e”、“o”存在少量的边界点相邻。因此,13-150-15-2 (TSDR-AE)模型和PCA_2D将汉语元音的舌位发音轮廓同时压缩到二维,并将结果在2D坐标系进行可视化,前者比后者能获得更好的舌位区分结果,这说明所提出模型相对于被广泛使用的PCA方法在二维压缩维度上能更好获得元音的发音分布特征。
3 讨论
将基于舌位形变的13-150-15-2 (DFRM)模型与标准的两层13-2 AE模型、采用Dropout技术进行数据增强的13-150-15-2 DAE (DRPT)模型进行比较可以得知,13-150-15-2 (DFRM)模型相对于其他2个模型,其PCC值分别提高了0.09和0.05,同时RMSE值分别降低了0.007和0.013。这表明基于ASM的形变技术能生成更多符合一定发音规律的舌位轮廓数据,使得模型的第一阶段TS-DAE (舌位轮廓自编码器)受输入数据影响较小,具有更强的鲁棒性,进而有效提高了模型的性能。
模型的第二阶段TSDR-AE通过引入带有少量隐藏单元的附加网络层进行微调。该附加网络层能进一步提高对真实舌位轮廓的拟合度,使得本文模型比13-150-15-2 (DFRM)模型具有更好的舌位重建性能。从图5可见,本文模型较13-150-15-2 (DFRM)模型的PCC值提高0.07,同时其RMSE值降低0.01,表明该模型所提出的第二阶段TSDR-AE能进一步改进舌位轮廓自编码器整体性能。
将所提方法与PCA方法在舌位压缩重建后的效果进行比较,通过对120个真实测试舌形压缩和重建的实验结果表明,采用13-150-15-2 (TSDR-AE) 将舌位轮廓压缩到二维,其重建的舌位轮廓明显优于采用PCA压缩舌位轮廓到二维重建的舌位轮廓,甚至更优于通过PCA压缩到三维所获得的重建结果。
将舌位轮廓压缩为二维变量并投影到2D坐标系中。由图7可知,本文模型在二维坐标系中的元音舌形压缩和可视化方面均优于传统的PCA_2D模型,其所获得的二维点分布呈现出更好的分类效果,即拥有更好的元音舌位识别能力。究其原因,主要是因为TSDR-AE具有较高的重建性能和良好的降维能力,确保了TSDR-AE模型较传统PCA方法能更直观建立舌关节结构和低维参数之间的双向映射关系。
综上,虽然舌位因其隐蔽性等生理特征而无法产生大量真实样本数据,但本文基于ASM产生的舌位形变数据所提出的两阶段自动编码器舌位模型比PCA舌位模型具有更强的舌位轮廓压缩能力、降维能力以及元音舌位区分能力。
4 结论
针对传统深度学习自动编码器难以直接用于舌位轮廓分析的问题,本文提出了一种基于小样本真实舌位数据统计分析的双阶段自动编码器方法。第一阶段通过引入具有生理特征的大规模变形方法,构建通用轮廓重建模型;第二阶段在前阶段的基础上添加隐藏单元,构建与降维目标维度相等的附加网络层对舌位数据进行压缩。实验在人类真实的小规模元音舌形数据上进行验证,并与传统PCA方法比较了降维、重建性能。实验结果表明,本文所提舌位轮廓重建模型比PCA方法的重建性能更优,所生成的元音舌位图谱在二维平面上也呈现出更好的区分度。
猜你喜欢
今日农业(2021年20期)2022-01-12 06:10:38
考试与评价·七年级版(2021年1期)2021-08-14 04:25:30
考试与评价·七年级版(2020年1期)2020-10-23 09:10:18
小天使·一年级语数英综合(2019年8期)2019-08-27 02:23:00
小学生学习指导(爆笑校园)(2018年10期)2018-10-20 06:00:54
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
小学生作文(低年级适用)(2017年6期)2017-07-07 14:56:51
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
小学生时代·大嘴英语(2014年6期)2014-11-04 00:35:50
