
基于改进PSO-SVM的生产线分拣机器人罐装食品识别方法
2023-10-24 02:38高海燕高晋阳王伟成
食品与机械 2023年9期
高海燕高晋阳王伟成
(1. 晋中职业技术学院,山西 晋中 030600; 2. 中北大学,山西 太原 030051;3. 山西农业大学,山西 太原 030031)
“中国制造2025”和“工业4.0”的提出,推动了智能制造不断向前发展,制造型企业对工业机器人的智能化要求也越来越高[1]。Delta机器人凭借速度快、精度高等优点在食品生产领域得到了广泛应用,而目标识别是机器人技术领域的热点研究问题。传统目标识别方法无法提取目标深度特征,识别准确率较低[2]。
近年来,机器人目标识别技术研究主要集中在支持向量机和卷积神经网络等方法上[3-6],在食品生产线中的应用较少。王成军等[7]对基于机器视觉技术的分拣机器人的研究进行了综述,指出现有的识别方法耗时长,难以实现准确、高效分拣目标。融合5G和深度学习的机器视觉将成为未来的发展方向。伍锡如等[8]提出了一种用于工业分拣机器人识别和定位的深度学习方法,其定位误差<0.8 mm,最快识别速度可达0.049 s/个,在试验环境中识别精度可保持在98%以上。王银明等[9]提出了一种能识别异物缺陷和折痕缺陷的分拣系统,识别率达95.00%,能准确有效地分拣出单片火腿,分拣成功率达98.00%,筛选效率为160包/min。王新龙等[10]将分类特征提取与深度学习相结合用于食品品质识别。所提模型识别精度相比于常规方法提高了14.00%左右,可提高食品品质识别精度。虽然上述方法可以实现食品的目标检测,但在实际应用中识别的准确性和效率还有待进一步提高。
研究拟提出将改进的粒子群(particle swarm optimization,PSO)算法与支持向量机(support vector machine,SVM)相结合用于食品分拣机器人的目标识别。通过改进PSO算法寻优SVM参数,对全局特征和局部特征分别进行分类器训练并结合,通过试验进行验证,以期为机器人技术在食品生产线中的应用提供一定参考。
1 系统结构
基于双目视觉的食品分拣机器人系统结构如图1所示,主要由视觉系统、计算机系统、Delta机器人本体等组成[11]。由视觉系统采集图像并发送到计算机进行处理,识别目标并计算目标位置,控制Delta机器人到达指定位置进行准确分拣。
2 识别方法
试验提出一种基于双目视觉的食品分拣系统识别方法,结合PSO算法和SVM模型,通过改进PSO算法寻优SVM参数,得到优化的SVM分类模型,对全局特征和局部特征分别进行训练,动态分配特征权重系数。识别方法流程如图2所示。基于双目视觉原理,根据相机标定数据完成三维重建,控制机器人到指定位置进行分拣。
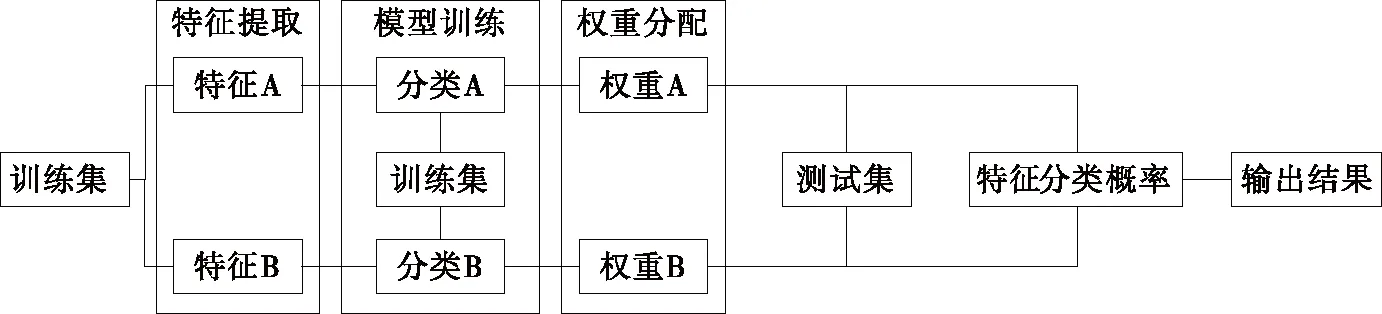
图2 识别方法流程
2.1 全局特征提取
Hu几何不变矩是一种高度浓缩的图像特征,具有平移、灰度、尺度和旋转不变性[12]。试验利用Hu几何不变矩提取双目视觉采集图像的全局特征。
hi=-sgn(hi)log10(|hi|),i=1,2,…,7,
(1)
式中:
hi——第i个特征值。
2.2 局部特征提取
使用方向梯度直方图HOG提取双目视觉采集图像的局部特征,HOG特征提取步骤为:
(1) 步骤1:图像预处理,通过灰度变换、Gamma校正等对采集图像进行预处理。
(3) 步骤3:计算cell单元梯度方向直方图,有利于后续的特征提取。
(4) 步骤4:组合block特征向量,并对直方图进行归一化。
(5) 步骤5:将所有block进行串联,得到HOG特征。
2.3 改进PSO算法
PSO算法基本原理:用X={X1,X2,…,Xn}描述粒子在D维搜索空间构成的种群,且粒子数量为n,用Xi描述每个粒子的位置,Xi可以根据目标函数计算相应的适应值。在不断更新的情况下,可以使用个体极值pbest与全局极值gbest更新粒子的速度和位置,如式(2)、式(3)所示[14]。
Vid(t+1)=ωviVid(t)+c1r1(pbestid(t)-Xid(t))+c2r2(gbest-Xid(t)),
(2)
Xid(t+1)=Xid(t)+vid(t+1),
(3)
式中:
ω——惯性权重;
c1、c2——学习因子;
Xid(t)、Vid(t)——d维空间中粒子i在迭代t次后的位置和速度;
r1、r2——[0,2]随机数。
(1) 优化ω:ω值越高,全局搜索能力越强,反之局部搜索能力越强。因此,引入动态ω,初期加强全局搜索,后期加强局部搜索,如式(4)所示[15]。
(4)
式中:
λ——系数,取0.01。
(2) 优化c1和c2:c1越大,全局搜索能力越强,c2越大,本地搜索能力越强。文中对c1采用线性递减,对c2采用线性递增,初期加强全局搜索,后期加强局部搜索,如式(5)、式(6)所示[16]。
(5)
(6)
式中:
t、tm——当前和最大迭代次数;
c1max、c2max——最大学习因子;
c1min、c2min——最小学习因子。
2.4 改进SVM
支持向量机是Vapnik等为解决小样本、非线性问题而提出的一种机器学习方法,被广泛应用于目标识别、状态评估等[17]。
设置可分样本X={xi,yi},i=1,2,…,l,其中xi∈Rn,n为样本空间维数。yi∈{-l,+l}为样本类别标记。如果存在最优超平面,则可以最大间隔地分割两个采样。最优超平面为
ω·x+b=0,
(7)
式中:
ω——权重向量;
b——偏差值。
根据式(8)所示的约束条件求解[18]。
(8)
对于线性不可分样本,最优超平面由式(9)中的约束来求解。
(9)
式中:
C——控制误差的惩罚程度;
ξi——松弛变量。
引入拉格朗日乘子,式(9)转化为对偶问题:
(10)
由KKT条件求解式(10)得到最优解[19]:
(11)
式中:

如式(12)所示,获得最优分类函数。
(12)
通过定义核函数K(xi,xj),在映射空间中找到最优超平面,并区分样本。对应的最优分类函数为
(13)
文中主要将RBF核函数用于SVM。RBF核函数[20]为
K(xi,xj)=exp(-g‖xi-xj‖)2,
(14)
式中:
g——核参数。
SVM模型的性能取决于惩罚参数C和核函数参数g的选择,参数的质量对算法的精度有显著影响。因此,选择改进PSO算法寻优SVM参数,以确保算法选择的参数是模型的最优参数。利用改进PSO算法的全局搜索能力,可以快速准确地搜索SVM的最优参数。使用pbest和gbest分别描述PSO优化SVM惩罚参数C和核函数的参数g。
优化过程为:
(1) 步骤1:初始化,对粒子群算法进行初始化,并给出SVM参数范围。
(2) 步骤2:计算各粒子的适应度值,适应度函数取均方误差MSE。
(3) 步骤3:根据适应度值更新pbest与gbest,再更新粒子速度和位置。
(4) 步骤4:是否满足停止条件(迭代和误差),满足执行下一步,不满足转到步骤2。
(5) 步骤5:通过训练样本对优化的SVM模型进行训练。
(6) 步骤6:通过测试样品验证改进的PSO-SVM,并输出测试结果。
基于改进PSO-SVM的优化流程图如图3所示。
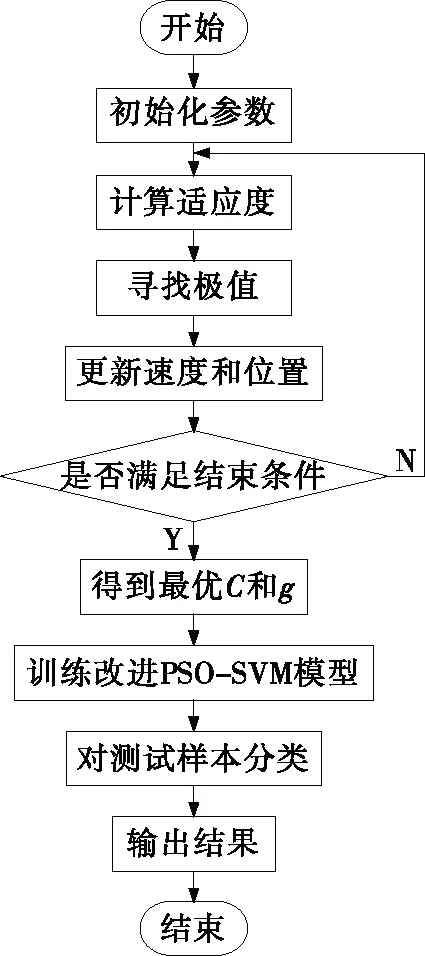
图3 优化流程
3 试验结果与分析
3.1 试验参数
为了验证所提方法的有效性,对不同输入特征的识别结果进行分析。粒子群算法参数:种群50、权重系数[0.4,0.9]、学习因子[1,2]、迭代次数100、惩罚因子和参数g的取值范围为[2-10,210],适应度函数为均方误差MSE。文中以罐装食品为例进行说明,共采集罐装食品图像1 000张,其中100 g罐装食品图像500张,210 g罐装食品图像500张,按4∶1分为训练集和试验集。为了确保准确度,在多次测试中取平均值。测试装置为华为PC,操作系统为Windows 11 64位旗舰,英特尔i513400CPU,2.5 GHz主频,16 GB内存。采用MER-125-30GM-PS相机,光源采用白色LED带状光源,伺服电机采用松下MSME202SGM。试验参数见表1。
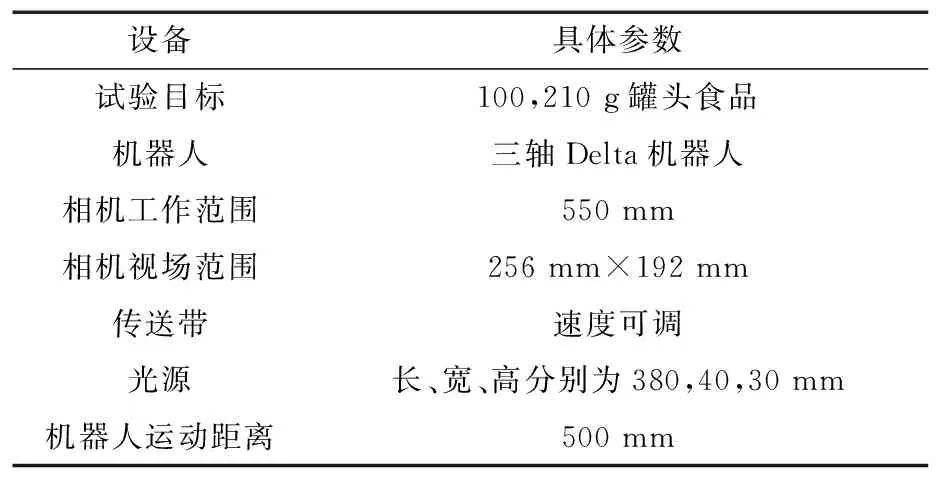
表1 试验参数
3.2 试验分析
为了验证多特征融合的优越性,根据前面提出的改进PSO-SVM特征组合算法,对Hu不变矩和HOG特征分别进行训练,并进行单特征和组合特征对比试验,将210 g罐头定义为1,100 g罐头定义为2。Hu几何不变矩特征分类器测试集识别结果如图4所示,HOG特征分类器测试集识别结果如图5所示,融合分类器测试集识别结果如图6所示。不同特征测试集的识别准确率见表2。

表2 不同特征测试集识别结果

图5 HOG特征识别结果
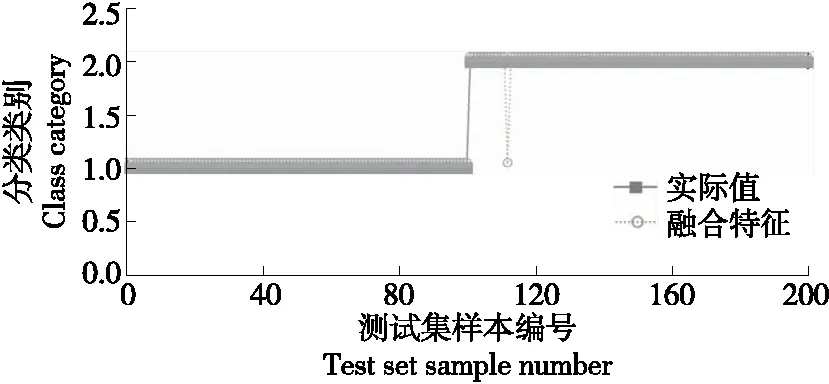
图6 融合分类器识别结果
由图4~图8和表2可知,Hu几何矩不变特征分类器在210 g罐装食品识别中出错7次,在100 g罐装食品识别中出错8次,识别准确率为92.50%,HOG特征分类器在210 g罐装食品识别中出错8次,在100 g罐头识别中出错5次,识别准确率为93.50%。文中融合特征分类器在210 g罐装食品识别中出错0次,在100 g罐装食品识别中出错1次,识别准确率达99.50%。结果表明,与单个Hu不变矩特征和HOG特征识别相比,文中提出的融合特征分类和识别方法有效提高了分类识别准确率,分别提高了7.57%和6.42%。此外,文中的融合特征分类识别的准确性波动较小,分类的鲁棒性更高。这是因为文中方法对特征的训练更加具体,而不会相互干扰,最大限度地提高了特征利用率,提高了识别准确率。
为了进一步验证文中方法的优越性,将文中改进PSO-SVM模型与SVM模型和文献[21]中的卷积神经网络模型进行对比分析,识别结果见表3。
由表3可知,未优化前的SVM模型参数c和g是系统设置的默认值,该模型对测试集的分类结果有19个错误,分类准确率为90.50%,识别效果较差,平均识别时间为0.121 s。文献[21]中的模型对测试集的分类结果有3个错误,分类精度为98.50%,识别时间为1.233 s,识别准确率较优,但识别时间不能满足分拣要求。另一方面,文中模型具有优异的识别准确率和识别效率,识别精度为99.50%,平均识别时间为0.048 s,与SVM模型和文献[21]模型相比,文中方法的识别准确率提高了9.94%和1.12%,平均识别时间降低了60.33%和96.12%。综上,文中模型能够比较有效地识别食品目标,具有较优的识别准确率和识别效率。
4 结论
提出了一种将改进的粒子群算法与支持向量机相结合用于食品分拣系统的目标识别,通过改进粒子群算法求出支持向量机参数,再通过全局和局部特征分别进行训练。结果表明,在食品识别中所提方法具有较高的识别准确率和效率,准确率为99.50%,效率为0.048 s。与支持向量机模型和文献[21]相比,文中方法识别精度提高了9.94%和1.12%,平均识别时间降低了60.33%和96.12%,具有一定优势。但仍需进一步优化和完善,如数据集自制,仅对生产线分拣系统的目标识别方法进行研究,未对目标定位和分拣机器人控制方法进行研究。
猜你喜欢
初中生学习指导·提升版(2022年10期)2022-05-30
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
知识就是力量(2019年1期)2019-01-10
中国交通信息化(2018年5期)2018-08-21
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
