
基于改进谱减法的工地语音增强方法
2023-10-24 07:35:26李含雁李勇滔梁明孔罗梅桂周海琳宋仁发
装备制造技术 2023年8期
白 帆,李含雁,李勇滔,梁明孔,罗梅桂,周海琳,江 柏,宋仁发
(1.广西科技大学a.自动化学院;b.机械与汽车工程学院,广西 柳州 545616;2.柳州柳工挖掘机有限公司,广西 柳州 545007)
0 引言
语音信号增强算法[1]的主要研究内容是有效地降低失真和噪声对语音信号的影响,并尽可能提取出纯净的语音信号。在实际应用中,音频信号往往受到环境噪声、回声、失真等干扰,尤其是在工地施工环境下,各种非稳态噪声会大大降低语音质量和可理解性。因此,通过减少噪声的干扰并增强有用的语音成分,改善语音信号的质量和提升识别成功率变得尤为重要。
语音增强常用的算法主要有两种:一种以发声模型为基础的算法,即通过建立声音产生模型来对语音信号进行语音增强处理;另一种是以估算语音幅度谱为基础的算法,即通过估计语音信号的幅度谱对带噪语音进行降噪处理,这两种算法在语音增强技术中起着重要的作用[2]。在以估算语音幅度谱为基础的算法中,谱减法[3]可控性强,适用范围最广,得到了众多学者的深入研究。传统的谱减法将无语音段噪声的平均功率谱作为整个语音信号噪声估计的功率谱,用带噪语音谱中减去估计的噪声谱[4],从而得到干净的语音谱。但是,在面对非平稳噪声尤其是工地噪声时,由于噪声的功率谱是随机波动的,会出现估计的噪声功率谱太大,波形相减使得不能为负的幅度谱出现负值的情况。如果直接将负值置为零,则会过度减少信号的能量,导致信号的部分信息丢失或失真,出现波形中断的情况。为解决这一问题,Mossa E 等[5]通过调节参数法在提升信噪比的同时,尽量降低语音信号失真程度;申浩等[6]分别采用掩蔽效应、小波包分解和维纳滤波相结合、与麦克风波束形成方法相结合三种方法对谱减法中产生的音乐噪声进行抑制;张国峰等[7]将语音识别系统估计的噪声参数用于谱减法语音增强,在语音持续期间及时更新噪声的均值。
分析传统的谱减法算法原理普遍存在的问题,通过设置谱值下限因子,在不出现波形中断的情况下解决幅度谱为负值的问题,并进一步引入平滑机制来避免谱值下限因子可能导致的波形不连续现象的发生。最后,通过与传统谱减法语音增强结果进行对比实验,验证了改进算法的增强效果。
1 传统谱减法原理
谱减法是语音增强算法中最早被提出的算法,它假设噪声是加性的,将无语音段噪声的平均功率谱作为整个语音信号噪声估计的功率谱,用带噪语音谱中减去估计的噪声谱,即可得到干净的语音谱估计。算法相对简单,容易实现与理解,能够有效地降低噪声的干扰,提升信号强度,并且适用性强,在多种场景中均有不错的效果。谱减法的算法原理如下:
记z(i)为带噪语音信号,s(i)为无噪声的纯净语音信号,n(i)为噪声信号,故语音信号可以用以下公式来表示:
由于谱减法是基于短时谱的估计算法[8],故需要先对信号z(i)、s(i)和n(i)进行预加重[9]、分帧、加窗处理,得到:
对式(2)左右两边同时作傅里叶变换,得:
对式(3)左右两边进行平方,得:
故式(4)可得:
式(7)中,θYw(ω)表示带噪语音信号的相位。最后,对Sw(ω)进行傅里叶逆变换,得到增强处理后纯净语音信号的时域估计表达式为:
谱减法原理图如下所示:

图1 谱减法原理图
2 谱减法的改进
在谱减法算法中,如果带噪语音的功率谱与估计出来的噪声谱相减出现负值,说明对估计的噪声功率谱太大,最简单的处理方法就是将负值置零,以保证幅度谱非负。但是,这种处理方式会导致信号帧频谱出现波形中断的情况,使信号的部分信息丢失。
2.1 谱值下限因子
为了在不出现波形中断的情况下解决幅度谱为负值的问题,需要在噪声估计的过程中找到一个平衡点,既能降低噪声的影响,又能保留语音信号的重要信息。针对传统谱减法进行优化,当语音能量谱大于噪声的时候,谱减法正常运行,可以增强语音质量;当语音能量谱小于噪声的时候,增加谱值下限因子,保留谱值下限,对二者之差取值,既保证幅度谱不为负值,也不直接置零,避免出现波形中断的情况。具体原理如下:
式中,β为谱值下限因子,取值范围为0 ~1 之间。如果β取值过小,会对低频信号进行更强的抑制,导致音频信号的低频部分失真;如果β取值过大,会对低频信号进行较弱的抑制,仍有低频噪声的残留。因此,具体取值需要根据具体的音频信号和噪声特征进行调整,以达到更好的语音增强效果。
2.2 平滑机制
增加谱值下限因子虽然能够在不出现波形中断的情况下解决幅度谱为负值的问题,但如果遇到信噪比较低的待增强语音时,输出的增强语音会出现波形不连续的情况,因此需要在该方法基础上引入平滑机制来进行再次改善。具体过程如下:
首先在噪声估计阶段,计算出谱减法噪声估计时所产生的最大误差。将带噪语音前T帧的真实幅度谱与前T帧噪声的平均功率谱进行按帧相减,并取其中最大值,即为前T帧的最大噪声估计误差。其中,T为谱减法噪声估计时所选取的无语音段噪声帧数值。
如式(10)所示:
如果改进谱减法处理完毕后,仍有某时频点的幅度值小于噪声估计时所产·生的最大误差,则将其替换为相邻帧的最小幅度值。如式(11)所示。
3 实验结果及分析
通过实验对纯净语音、添加噪声后的语音、传统谱减法处理过的语音以及改进谱减法处理过的语音分别进行时域波形模拟,验证增加谱值下限因子并引入平滑机制的改进谱减法的有效性。实验中,纯净语音在安静环境下录制,噪声则采用工地施工现场录制的噪声,以44000 Hz 的采样标准和16bit 量化对纯净语音信号和噪声信号进行采样,按照一定比例,将纯净语音信号和噪声信号线性相加,分别形成五种不同信噪比的情况,分别为:-10 dB、-5 dB、0 dB、5 dB、10 dB。
以形成的信噪比为5 dB 的含噪语音为例,纯净语音时域波形图见图2,添加噪声后语音时域波形图见图3,传统谱减法输出语音时域波形图见图4,改进谱减法输出语音时域波形图见图5。

图2 纯净语音时域波形图
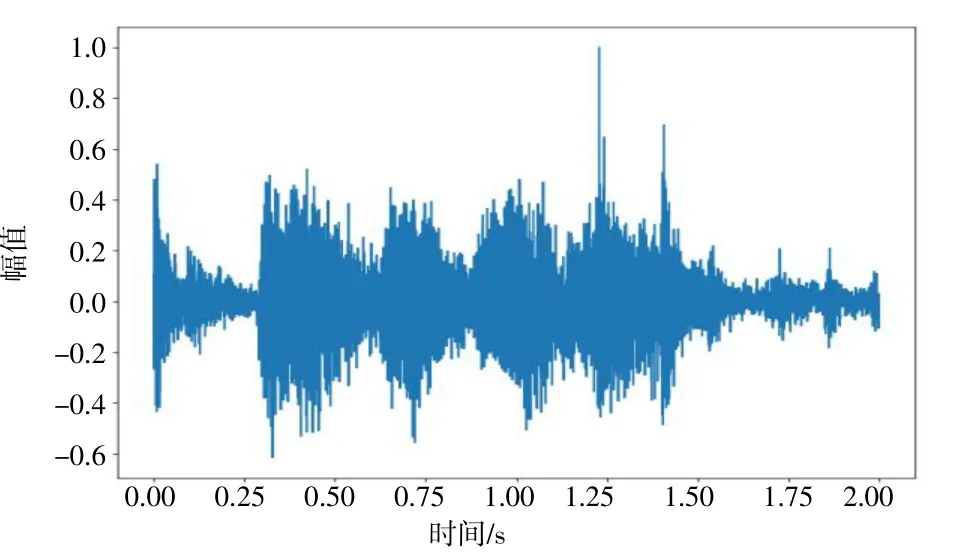
图3 添加噪声后语音时域波形图
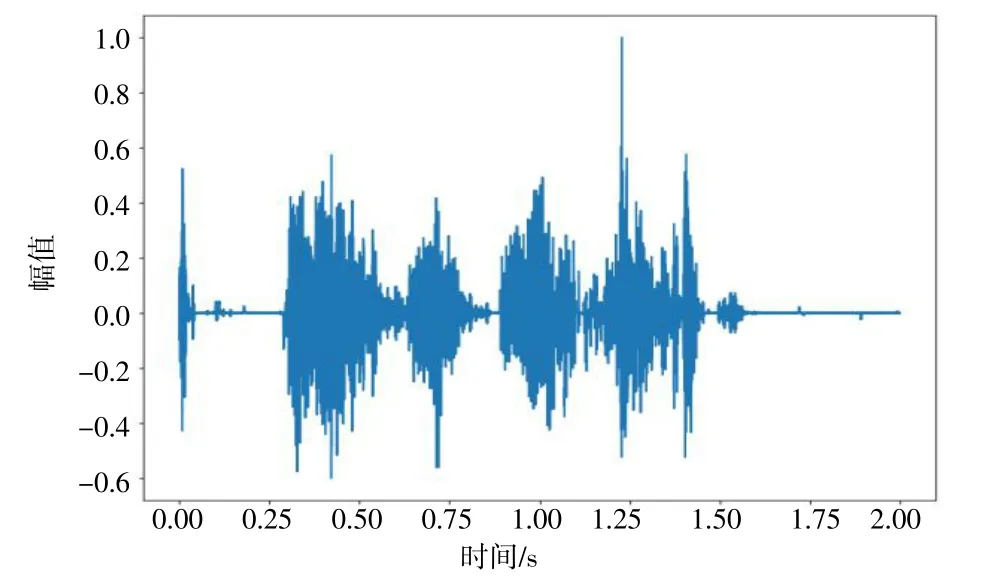
图4 传统谱减法输出语音时域波形图

图5 改进谱减法输出语音时域波形图
由图2、图3 对比可知,加入工地施工现场录制的噪声后,纯净语音受到了很大的干扰,一些频率成分被压制或淹没在噪声中,从而导致整体幅值降低;经过传统谱减法处理后,由图3、图4 对比可知,传统谱减法在保留语音波形的基础上,消除了大部分的工地噪声所带来的波形影响,但由于将波形相减所产生的负值直接置为零导致波形中断的情况十分明显;由图4、图5 对比可知,改进谱减法在保留传统谱减法去噪的基础上,增添的谱值下限因子和平滑机制效果显著,解决了波形不连续的情况。
对实验结果进行信噪比评测,结果见表1。
从表1 结果可以看出,传统谱减法在五种信噪比的情况下,输出语音信噪比平均增强了6.28 dB,而改进谱减法比平均增强了8.43 dB,比传统谱减法平均增强了2.15 dB。与传统谱减法相比,改进后的谱减法不仅在波形连续的情况下解决了负值问题,而且降噪能力更强,使得信噪比提升更大,尤其在低信噪比情况下,增强效果更加明显。

表1 实验结果信噪比统计
4 结语
经过传统的谱减法处理后的语音信号可以获得一定程度的增强效果,但由于将波形相减所产生的负值直接置为零,导致出现波形中断的情况。通过增加谱值下限因子并引入平滑机制,对传统谱减法进行了改进,在不出现波形中断的情况下解决了幅度谱为负值的问题,进一步对语音信号进行了增强。实验结果说明,改进谱减法在五种信噪比的情况下,输出语音信噪比平均增强了8.43 dB,比传统谱减法平均增强了2.15 dB,并且当信噪比处于较低水平时,有更加明显的增强效果。
猜你喜欢
电器与能效管理技术(2024年12期)2024-01-02 00:00:00
中学生数理化·八年级物理人教版(2021年9期)2021-11-20 06:00:28
攀枝花学院学报(2021年5期)2021-10-19 02:52:58
大学物理(2021年2期)2021-01-25 03:26:18
英语文摘(2020年7期)2020-09-21 03:40:56
意林·少年版(2019年20期)2019-11-13 15:57:04
测控技术(2018年11期)2018-12-07 05:49:02
系统工程与电子技术(2016年7期)2016-08-21 13:59:14
西北工业大学学报(2015年4期)2016-01-19 03:31:55
电测与仪表(2015年2期)2015-04-09 11:28:50
