
基于Voting和Stacking集成算法的岩爆倾向性预测*
2023-10-24 03:43:42李子彬
化工矿物与加工 2023年10期
王 凯,李子彬
(1.中国有色金属工业昆明勘察设计研究院有限公司,云南 昆明 650000;2.昆明理工大学 国土资源工程学院,云南 昆明 650093)
0 引言
随着矿山开采向深部转移,工作面处于高地应力、高地温、高岩溶水压以及强扰动等环境中,岩爆灾害呈增加趋势[1-2]。岩爆是高地应力条件下地下洞室开挖过程中因围岩开挖卸荷而发生脆性破坏,储存于岩体中的弹性应变能突然释放且产生爆裂松脱、剥落、弹射甚至抛掷现象的一种动力失稳地质灾害[3]。岩爆具有很强的突发性、随机性和危害性,已成为威胁井下安全生产的重大灾害之一[4-5]。因此,提高岩爆预测准确性对于保障矿山安全生产至关重要。
机器学习作为人工智能的一个分支,国内外不少学者将其引入岩爆等级预测预警领域,获得了较好的效果。汤志立等[6]引入机器学习算法建立了9个考虑多因素的岩爆预测模型;谢学斌等[7]基于改进的CRITIC算法以及XGBoost对样本进行加权和计算训练,建立了CRITIC-XGB岩爆倾向性等级预测模型;乔木等[8-9]基于主客观组合赋权和物元可拓理论建立了岩爆倾向性预测模型;胡建华等[10]采用消除云雾化的综合权重法建立了多指标岩爆倾向性的改进有限云评价模型;吴顺川等[11]采用主成分分析法(PCA)对数据进行降维,结合概率神经网络(PNN)建立了岩爆烈度预测模型;刘晓悦等[12]引入AdaBoost集成学习算法对BAS-SVM弱学习器进行了强化训练,建立了AdaBoost-BAS-SVM岩爆等级预测模型;刘剑等[13]基于修正散点图矩阵与随机森林进行了岩爆倾向性等级预测;刘德军等[14]融合8个机器学习算法,提出了3组考虑多个岩爆预测指标的Stacking集成算法。
从现有研究成果来看,机器学习应用于岩爆预测是可行的。然而各种机器学习算法都有其优越性和鲁棒性,仅将一种或几种算法简单融合得到的模型预测效果并不理想或泛化性不强。因此,本文基于Voting和Stacking集成算法,融合现阶段准确率较高的几种机器学习算法,建立集成分类器预测岩爆倾向性。此外,选用精确率、准确率、召回率及F1分数作为评价指标,综合评估几种基础分类器和集成分类器的性能,择优选择最佳分类器,并将其应用于秦岭隧道进行岩爆预测,以检验模型的可靠性。
1 数据来源及分析
1.1 数据来源
根据烈度将岩爆划分为无岩爆(Ⅰ级)、轻微岩爆(Ⅱ级)、中等岩爆(Ⅲ级)、强烈岩爆(Ⅳ级)。从岩爆的影响因素出发,考虑了应力条件、脆性条件及能量因素,选取最大切向应力SMT、应力集中系数FSC、脆性系数B1、弹性能量指数Wet等作为指标。本文一共选择231组岩爆数据,均来自国内外公开发表的文献[15-16],其中,无岩爆(Ⅰ级)37例,轻微岩爆(Ⅱ级)72例,中等岩爆(Ⅲ级)79例,强烈岩爆(Ⅳ级)43例。岩爆数据及等级分布见图 1。
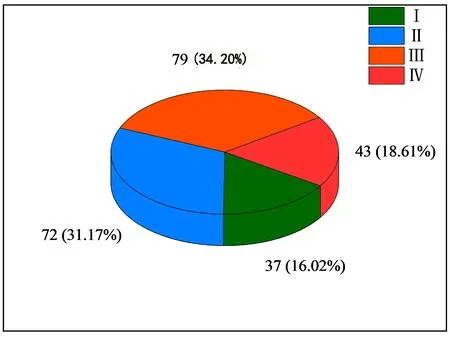
图 1 岩爆数据及等级分布
1.2 数据分析
为分析数据异常情况,以各指标数据按不同岩爆等级绘制箱型图(见图 2)。
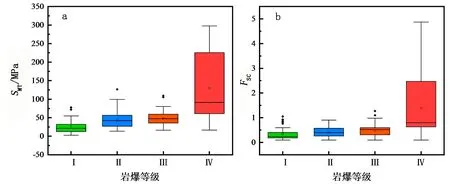
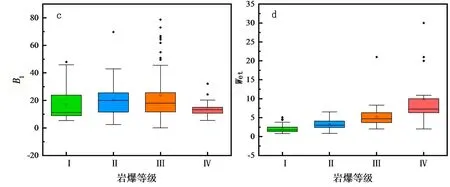
图 2 各指标数据箱型图
由图2可知,各指标均存在异常数据,考虑到工程实际情况,本文并未删除这些异常值,保留异常离群值的全部样本作为数据集,建立岩爆预测算法。
1.3 数据预处理
建立模型之前,首先对所有数据作标准化处理(特征缩放),其原理是针对每个特征维度去均值和归一化,而不是针对样本,使得处理后的数据符合标准正态分布,以解决数据不均衡的问题。其转换函数为
(1)
式中,μ为所有样本的均值,σ为所有样本的标准差。
2 集成算法构建
2.1 Voting集成算法原理
Voting是一种集成学习,结合多个机器学习模型预测结果而产生最终结果(见图 3)。在整个数据集上训练多个基础模型来进行预测,每个模型预测结果被认为是一个“投票”,得到多数选票的预测结果将被选为最终预测结果。投票方法分为硬投票和软投票两种(见图 4),硬投票将N个基础模型预测结果按数量票选出最终结果,软投票将N个基础模型预测的概率平均值作为最终结果。
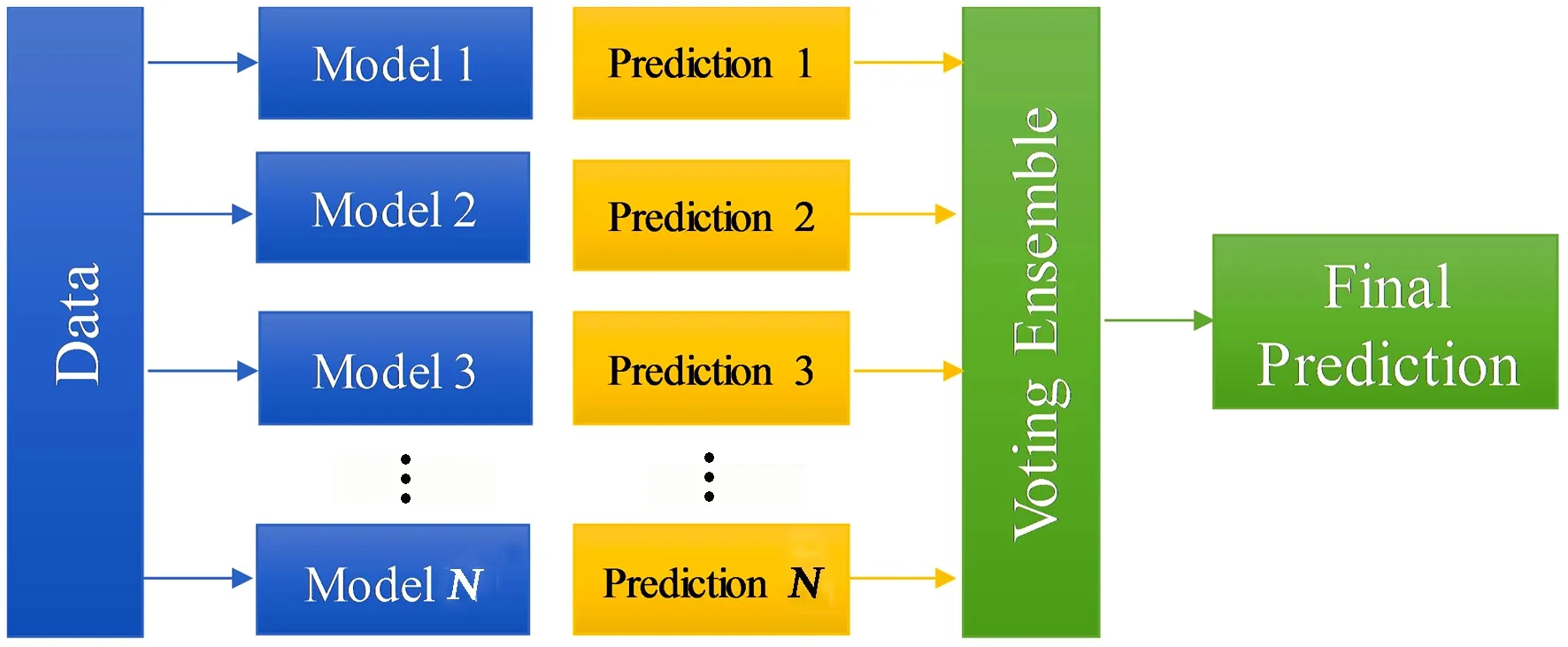
图 3 Voting集成算法原理
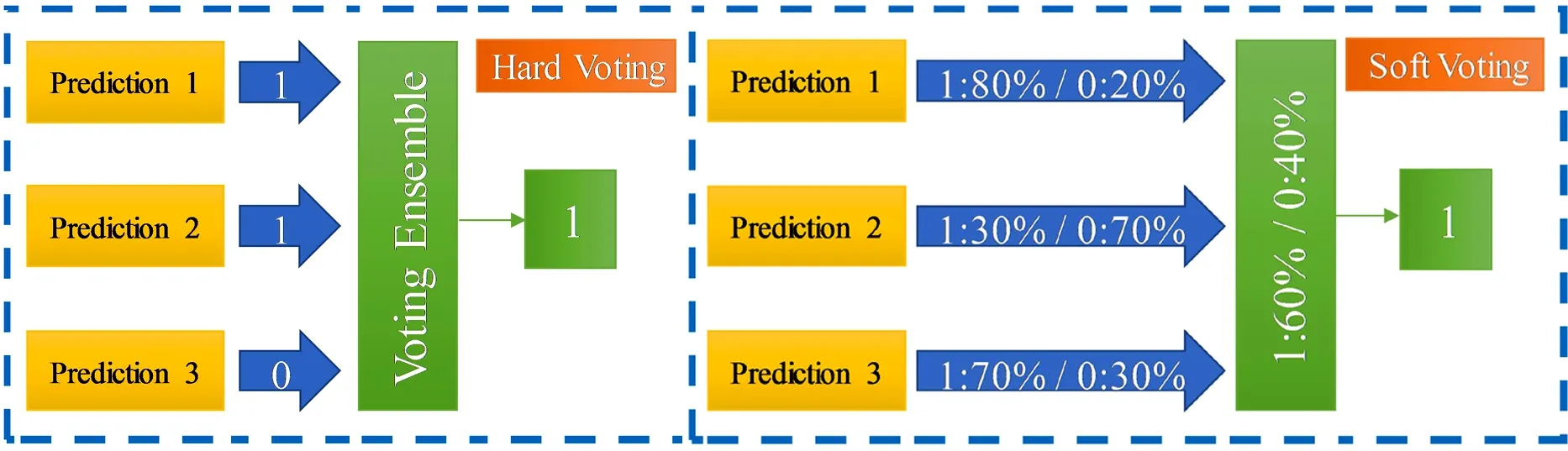
图4 硬投票和软投票
2.2 Stacking集成算法原理
Stacking也被称为叠加泛化,目的是通过使用不同的泛化器来减少错误,其结合策略是使用另一个机器学习算法来将个体学习器的结果结合在一起。在Stacking算法中,个体学习器又称为初级学习器,用于结合的学习器称作元学习器(Meta-model)。将初级学习器的预测结果作为新的特征输入元学习器,得到最终预测结果(见图5)。
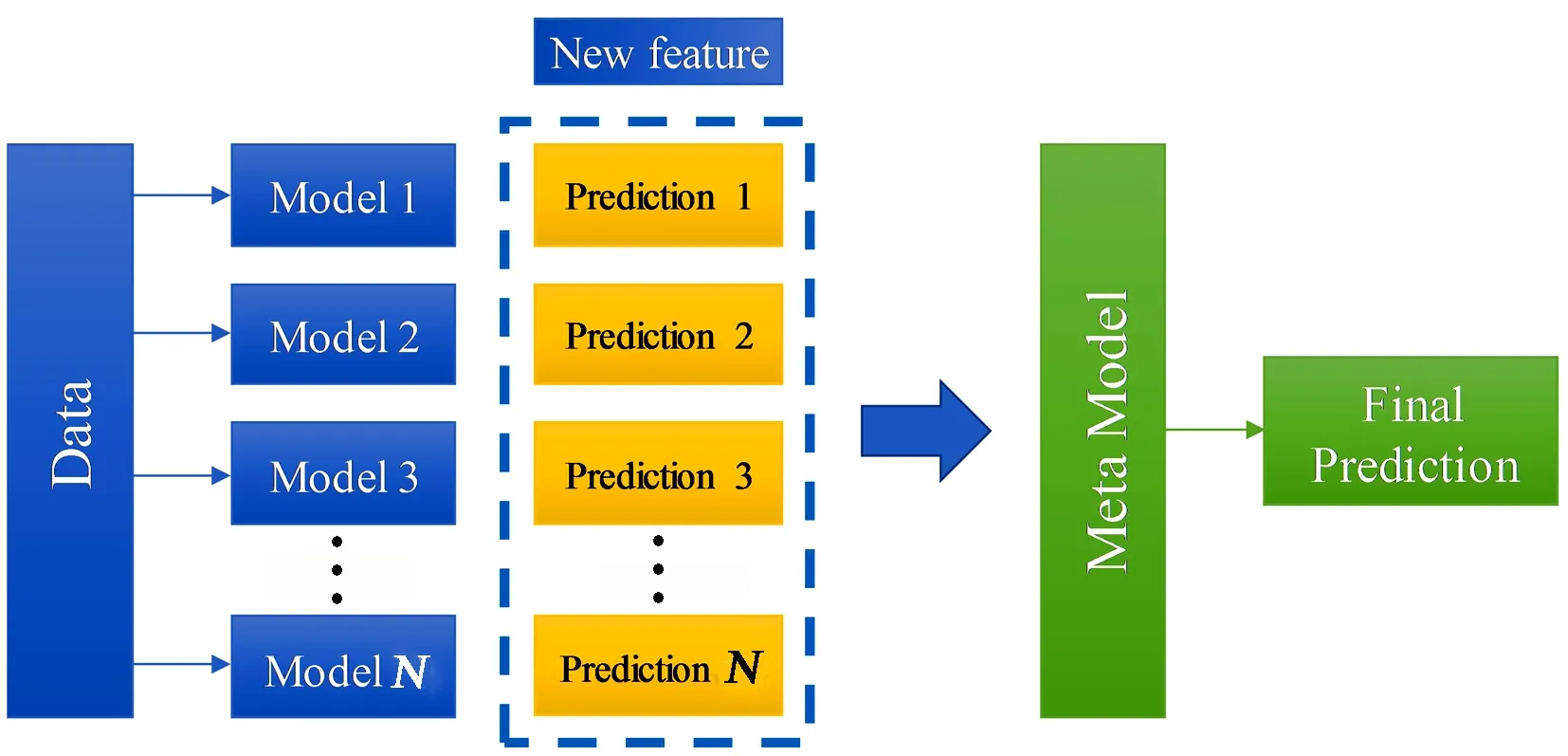
图 5 Stacking集成算法原理
2.3 集成算法构建及优化
2.3.1 集成算法构建
本文基于Scikit-learn基础算法包对数据集进行学习,考虑到各算法的原理、优缺点及精确率,选择逻辑回归(LR)、随机森林(RF)、支持向量机(SVM)、决策树(DT)、K近邻(KNN)、高斯朴素贝叶斯(GNB)等6种基础机器学习方法,其精确率分别为0.70、0.93、0.94、0.92、0.90、0.92。先将数据集输入6种机器学习算法模型中得到初始预测结果,根据Voting集成算法分别进行硬投票和软投票,得到Voting集成分类器1(V1)和Voting集成分类器2(V2);Stacking集成算法的初级学习器也由6个基本算法构成,并分别从中选择准确率最高的两种(RF、SVM)作为元模型,由此得到Stacking集成分类器1(S1)和Stacking集成分类器2(S2)。
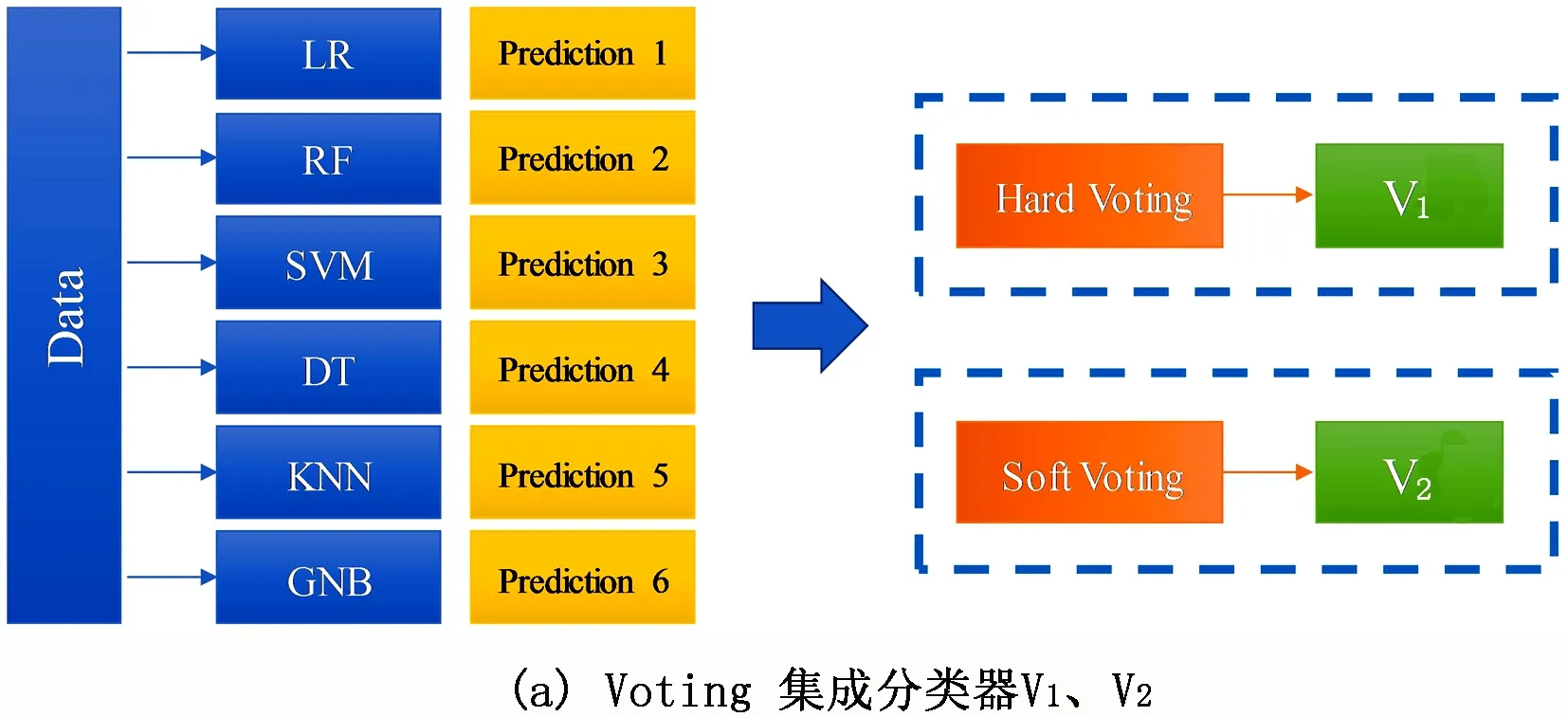
图6 构建集成分类器V1、V2、S1和S2
2.3.2 交叉验证及超参数调优
为使建立的分类器具有更好的泛化性,本文引入K折交叉验证(K-fold cross-validation)[17],K值取10,其原理见图 7。将原始数据集分割为相等的K部分,依次将每个部分作为测试集,其余部分作为训练集,训练分类器,将K次准确率的平均值作为最终的准确率。
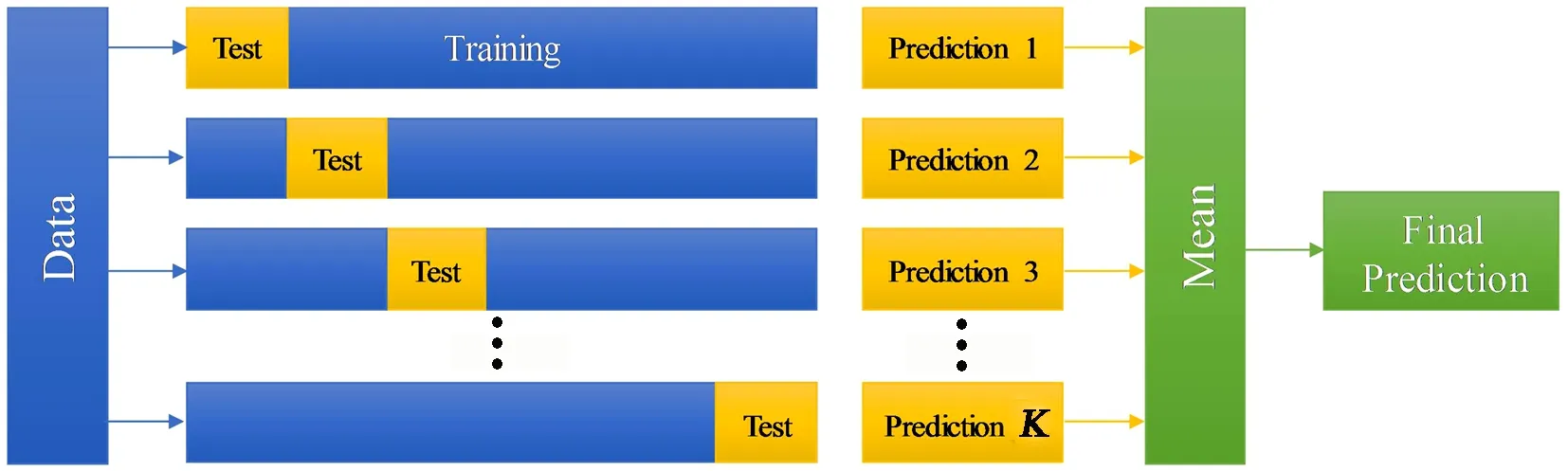
图7 K折交叉验证
逻辑回归分类器(LR)中C值为正则化惩罚参数,其值越小惩罚力度越大,取0.01;随机森林分类器(RF)中基评估器数量(estimators)为100,随机因子(random state)取10;支持向量机分类器中C值惩罚因子为1.0,核函数为径向基函数RBF,决策函数类型选择一对一;决策树分类器中最大深度为2;K近邻分类器中用于查询邻居的数量为2。
3 分类器性能评估
准确率(Precision)和召回率(Recall)是广泛应用于信息检索和统计学分类领域的两个度量值,分别衡量分类器的查准率和查全率。图 8列举了所有分类器各个等级的预测结果,计算了各等级的准确率、召回率及全部结果的精确率(Accuracy),并组成了混淆矩阵。
由图8可知:预测为Ⅰ级样本中准确率最高的是集成分类器S1、SVM,准确率为1,其次为集成分类器V1、RF,准确率为0.949;所有Ⅰ级样本中预测最全的是集成分类器S1、V1、RF,召回率为1。预测为Ⅱ级样本中准确率最高的是集成分类器S1,准确率为1;其次是SVM,准确率为0.986。所有Ⅱ级样本中预测最全的是集成分类器S1、SVM,召回率为0.986。预测为Ⅲ级样本中准确率最高的是集成分类器S2,准确率为0.949,其次是集成分类器S1,准确率为0.948。所有Ⅲ级样本中预测最全的是LR,召回率为0.975;其次是KNN,召回率为0.962。预测为Ⅳ级样本中准确率最高的是集成分类器V1,准确率为0.944;其次是KNN,准确率为0.938。所有Ⅳ级样本中预测最全的是RF,召回率为0.953;其次是集成分类器S1、S2、DT,召回率为0.930。
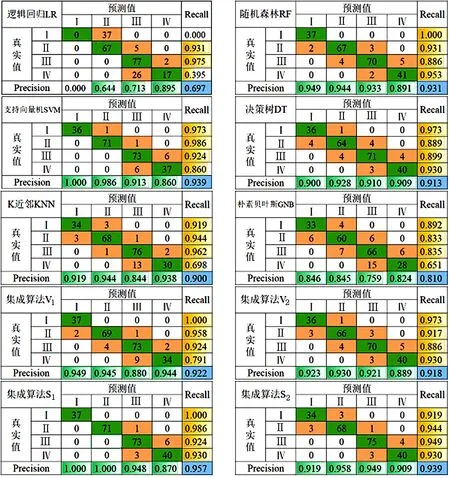
图8 各算法混淆矩阵
对于Ⅰ级、Ⅱ级样本,6个基础分类器中SVM、RF预测效果更好,4个集成分类器中S1、V1预测效果更好。对于Ⅲ级、Ⅳ级样本,6个基础分类器中KNN预测效果更好,4个集成分类器中S1、S2预测效果更好。从整体精确率来看,6个基础分类器中SVM、RF预测效果更好,4个集成分类器中S1、S2预测效果更好。
根据混淆矩阵计算各算法的精确率、准确率、召回率及F1分数(见表 1)。由表1可知,6个基础分类器中预测效果最好的是RF和SVM,精确率分别为0.93、0.94,准确率、召回率及F1分数也优于其他基础分类器;LR由于对Ⅰ级、Ⅳ级样本不敏感,导致整体预测效果欠佳。
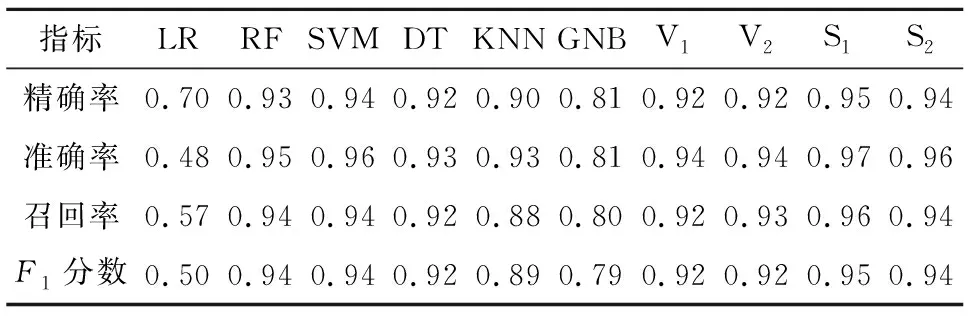
表1 各算法精确率、准确率、召回率及F1分数
集成分类器相对于基础分类器均有不同程度的提升,为了更直观地对比集成分类器的优化效果,图 9列举了4个集成分类器相对于基础分类器中RF、SVM的性能提升情况。由图9可知:相对于RF,S1、S2性能提升较明显;V1、V2基于投票原理,受基础分类器中较差的LR、GNB影响,预测效果稍差;相对于SVM,S1性能提升较明显,S2预测性能与其持平;V1、V2均因投票机制所限性能稍有降低。整体来看,4个集成分类器中S1较基础分类器性能提升最显著,预测效果最佳,精确率、准确率、召回率、F1分数分别为0.95、0.97、0.96、0.95。
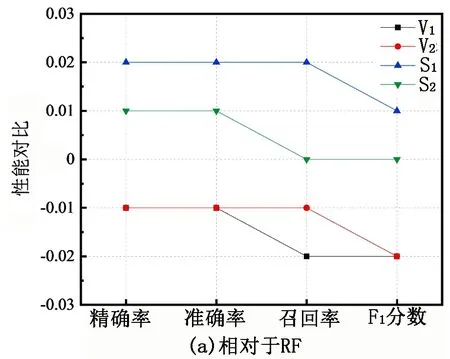
图9 集成分类器相对于RF、SVM的性能对比
4 工程实例
秦岭隧道为西安-安康铁路线上的重大控制工程,位于陕西省长安县与柞水县交界处,长18 km,近南北向穿越近东西向展布的秦岭山脉,最大埋深达1 600 m。隧道穿越的岩体主要为混合片麻岩和混合花岗岩,其中混合片麻岩的单轴抗压强度为95~130 MPa,最大主应力为20~40 MPa。岩爆主要发生在洞身拱部,电镜扫描岩爆破裂面发现主要是张拉破坏,局部为剪切破坏[17]。
根据秦岭隧道施工过程中实际发生岩爆的4处记录,桩号分别为1+731、1+640、3+390、3+000,岩爆等级为Ⅱ级、Ⅲ级。将本文构建的集成分类器S1应用于秦岭隧道的岩爆倾向性分析,结果见表 2。由表2可知,S1预测结果与秦岭隧道实际情况一致,验证了该分类器在实际应用中的可靠性及准确性。
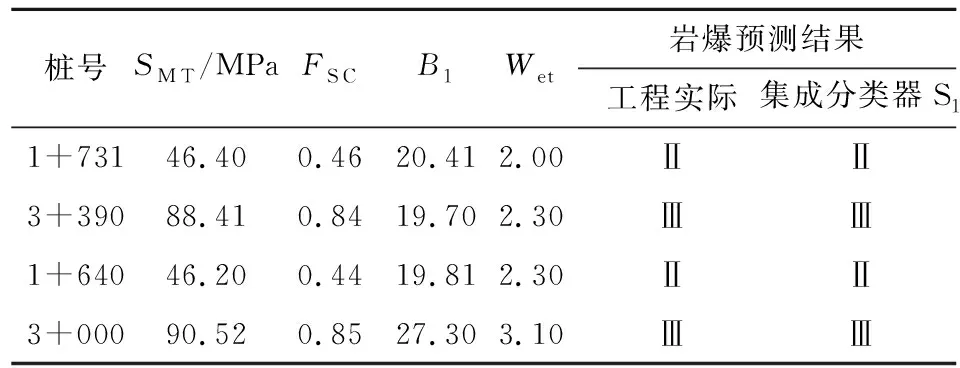
表2 秦岭隧道岩爆数据及预测结果
5 结论
为合理预测岩爆灾害的烈度,本文考虑了岩爆发生的主要因素,采用Voting和Stacking集成算法,结合6种机器学习算法建立了4个集成分类器V1、V2、S1、S2,对其预测效果进行了对比分析,得到以下主要结论:
a.基础分类器各有优劣,对不同等级的样本敏感程度也不尽相同,其中,SVM、RF对Ⅰ级、Ⅱ级样本较敏感,KNN对Ⅲ级、Ⅳ级样本更敏感。整体来看,LR由于对Ⅰ级、Ⅳ级样本不敏感,导致预测效果欠佳;预测效果最好的是RF和SVM,精确率分别为0.93、0.94。
b.Voting和Stacking集成算法均能有效融合各基础机器学习算法结果,充分发挥各算法优势,集成分类器相对于基础分类器性能均有不同程度的提升。根据投票机制,基于Voting集成算法的分类器易受性能较差的基础分类器影响,整体性能弱于Stacking集成算法。
c.4个集成分类器中S1、V1对Ⅰ级、Ⅱ级样本较敏感,S1、S2对Ⅲ级、Ⅳ级样本更敏感。整体来看,S1较基础分类器性能提升最显著,预测效果最佳,精确率、准确率、召回率、F1分数分别为0.95、0.97、0.96、0.95。
d.将基于Stacking算法构建的集成分类器S1应用于秦岭隧道岩爆预测,预测结果与工程现场实际一致,验证了其可靠性。
猜你喜欢
中国水运(2023年8期)2023-09-08 01:45:02
金属矿山(2022年1期)2022-02-23 11:16:36
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子测试(2018年1期)2018-04-18 11:52:35
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:34
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
