
基于改进YOLOv5算法的安全帽佩戴实时检测模型
2023-10-23 02:58:38郭安文权冀川
计算机时代 2023年10期
郭安文,权冀川
(陆军工程大学指挥控制工程学院,江苏 南京 210007)
0 引言
施工人员佩戴安全帽是安全施工的必要措施。因此,需要对施工人员是否佩戴安全帽进行监测及管理。
本文探讨利用计算机视觉技术自动监测工人是否佩戴了安全帽。具体来说,是借助目标检测算法检测监控图像或视频中人员的头部,并利用分类算法判断头部是否佩戴了安全帽。常用的目标检测算法包括SSD、Faster R-CNN、YOLO 系列算法等,这些算法可以检测图像中的目标位置和类别信息。对于安全帽检测任务,需要在检测结果中提取出人员头部的位置和安全帽的位置,对这些位置信息进行比对,以判断是否佩戴安全帽。
但是施工环境通常比较恶劣,无法保证标准的机房条件,温湿度不稳定,同时还有灰尘、震动、噪声等不良因素,会对高性能设备的稳定性和计算性能产生很大的影响。而便携式、低性能的设备通常比较耐用,适应性强,能够在恶劣的环境下正常运行。因此,在施工环境中,适合选用低性能设备,以保证设备的稳定性和可靠性。
由于施工环境中适用的设备性能有限,因此需要选择合适的检测模型,即较少的参数量、较小的计算量和精度适中的检测模型,并且保证在一些简单的应用场景中能够使用。YOLOv5算法相较于其他目标检测模型更加方便配置。它的配置文件简单、支持多种数据集、使用的预训练模型简单、易于调试,这些特点使得用户可以快速地配置和训练模型,大幅提高工作效率。所以本文选择在YOLOv5 算法模型的基础上改进和优化,提出一种可以在低性能设备上实现高效安全帽佩戴检测的系统。
1 YOLOv5算法
根据主干网络的depth_multiple(深度)参数和width_multiple(宽度)参数的不同,YOLOv5 算法默认提供了五个模型,YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x,图1 是深度和宽度均为1 的YOLOv5模型结构图。随着模型的深度与宽度依次增加,模型的精度会不断提高,但训练、推理的速度也会显著下降。YOLOv5算法网络模型的结构总体上可以分为四个部分:输入端、Backbone网络、Neck特征融合网络以及Head输出端。

图1 宽度和深度均为1的YOLO结构图
1.1 输入端
⑴Mosaic 数据增强:Mosaic 数据增强是对四张图片进行随机色域变换,再通过随机缩放、随机裁减、随机排布的方式进行拼接形成训练数据。这种操作方式极大丰富了图片的背景数量,变相地实现了更大的batch size,同时经过随机缩放增加了很多小目标,提高了模型的泛化能力和鲁棒性。
⑵自适应图片缩放:常见目标检测模型对于输入图片的处理方式是将原始输入图片的尺寸统一调整为固定大小,再输入到检测网络中。但像这样仅仅使用resize 操作来调整图片的大小,很容易导致图片失真。而且在缩放填充后,如果填充过多,就会存在信息冗余,影响模型的推理速度。为了避免信息冗余,同时提高模型运算速度,YOLOv5 算法采用了自适应的缩放方法,在待检测图片的两端填充最少的黑边,然后将其输入网络模型中进行训练,保证在提高模型运算速度的同时,又不会引入过多的冗余信息。
⑶自适应锚定框计算:YOLOv5算法除了使用默认的锚定框外,还可以在模型训练前对数据集的标注信息进行统计,计算出数据集默认锚定框的最佳召回率。如果最佳召回率大于或等于某一设定阈值(一般取为0.98),则不会更新锚定框;如果最佳召回率小于该阈值,则自动重新计算更符合此数据集特征的锚定框。更新锚定框采用k-means算法和遗传算法对数据集进行解析,并预先设置固定的Anchor;网络训练时,算法基于初始锚定框输出预测框,并与真实值进行比较,计算这两者的误差;最后采用反向更新的方法迭代网络参数,降低损失函数的值。如果计算得到的锚定框的效果不好,也可以在代码中关闭自动计算锚定框的功能。
1.2 Backbone网络
⑴CBS 结构:CBS 是由卷积(Conv)、批量归一化(BN)和SiLU 激活函数(Silu)组成的结构。卷积层用于提取图像的不同特征,批量归一化层对特征数据进行归一化处理以减少训练过程中可能产生的梯度消失现象,而SiLU激活函数则是对输入数据进行非线性变换,使其具有更平滑的梯度,保证模型更加灵活和具有更强的表达能力。CBS 结构可以有效提高模型的准确率。
⑵ C3 结构:在YOLOv5-6.0 版本中,使用了C3模块替代早期的BottleneckCSP[3]模块。C3 结构与CSP 结构基本相同,如图2,都使用了分支结构来处理网络的不同特征,但在修正单元的选择上略有不同。C3结构由三个连续的卷积层组成,第一个卷积层的输出通道数为输入通道数的一半,第二个卷积层的输出通道数等于第一个卷积层的输出通道数,第三个卷积层的输出通道数等于输入通道数。这种设计可以有效地减少模型的参数量和计算量,同时也能提高模型的学习能力和精度。C3 模块的使用使得YOLOv5-6.0版本的模型更加轻量化和高效,可以更快地执行目标检测任务,实用性更好。

图2 C3模块结构与CSP模块结构
⑶SPPF 结构:SPP[4(]空间金字塔池化)能够将任意大小的特征图转换成固定大小的特征向量,可以增强特征图的表达能力。在YOLOv5-6.0 中,SPP 结构被SPPF(SPP-Fast)结构所取代。如图3,SPPF 只用了一种卷积核,串行以后等效SPP 的计算结果,速度比SPP更快。
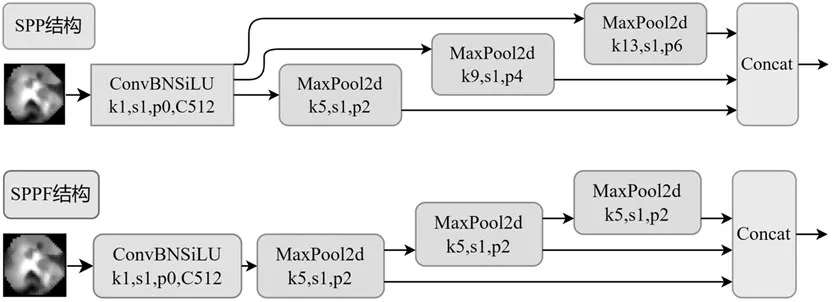
图3 SPP模块结构与SPPF模块结构
1.3 Neck特征融合网络
YOLOv5 算法模型的Neck 特征融合网络部分首先使用FPN 结构构建特征金字塔,然后通过PAN 结构进行特征融合。FPN 结构采用自顶向下的侧边连接构建多种尺度的高级语义特征图。PAN 结构则通过自底向上的路线加强低级语义特征图的定位信息,并将不同尺度的特征图进行融合。两种结构融合后,能够充分利用多尺度的特征图信息,兼具自顶向下和自底向上特征融合策略的优势,实现更加准确和鲁棒的物体检测。
1.4 Head输出端
YOLOv5 算法模型的Head 部分用来输出目标检测的结果,其主体是三个检测器,分别处理不同尺度的特征图。当输入图片分辨率为640×640时,三个尺度上的特征图分别为80×80、40×40、20×20,基于网格的anchor 会在这些提取出的特征图上进行目标检测,以捕捉不同尺度的目标信息,提高模型的准确性和鲁棒性。每个检测器部分都采用了非极大值抑制NMS 机制以筛选出目标框,可以有效去除冗余框,提高算法的效率和速度,并采用了CIOU_Loss 作为损失函数,进一步提升了算法的检测精度。
2 YOLOv5算法的改进
2.1 替换主干网络
YOLOv5 算法模型的主干特征提取网络采用C3结构,在精度方面表现优异,但具有较大的参数量,面临模型过于庞大、内存要求高、检测速度慢等问题。在低性能设备上,如此大而复杂的模型很难有用武之地。由于模型过于庞大,经常面临内存不足的问题。而工地场景中的检测设备性能有限,需要小巧、适用度高的模型,而且还可能缺少高性能的GPU 支撑。MobileNet v3 是一种轻量级网络,采用了深度可分离卷积等轻量化技术,具有较小的模型参数量和计算复杂度,适合在计算能力较弱的设备上运行。还可以通过减少卷积核的数量以缩减通道数,从而降低计算量和存储空间要求。这些优化策略可以进一步提高MobileNet v3的计算速度。本文提出将主干特征提取网络替换为更轻量的MobileNet v3 网络(图4),以实现网络模型的轻量化,平衡速度和精度的要求。
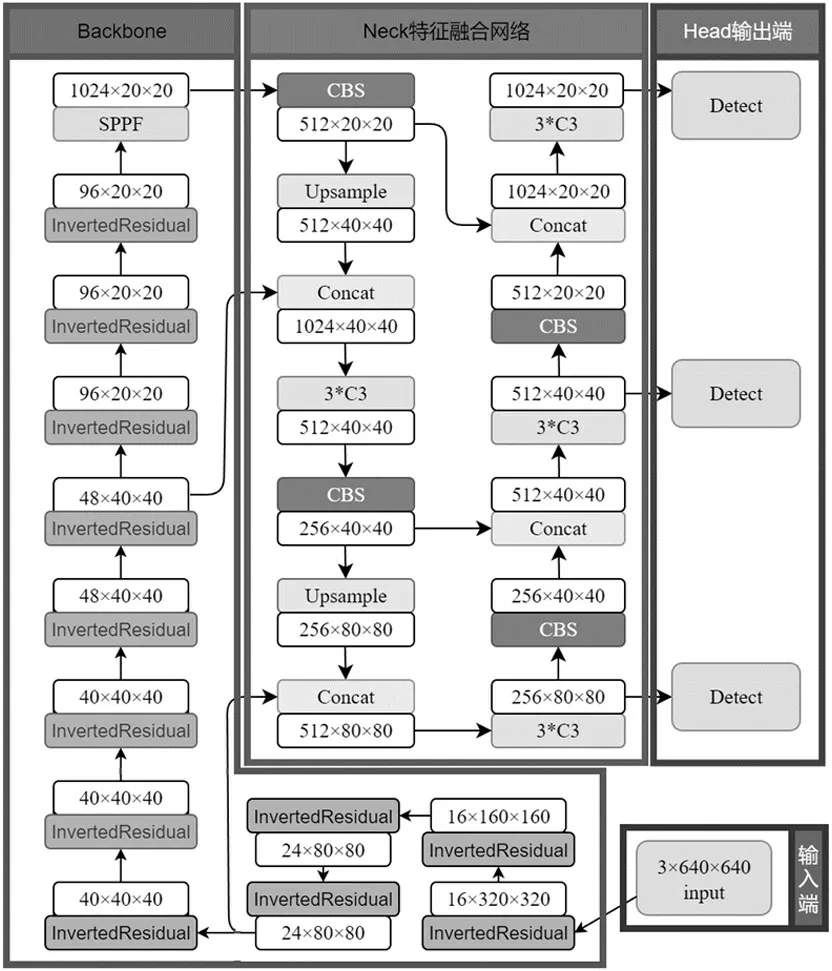
图4 替换为MobileNet主干网络后的结构图
2.2 加入CA注意力机制
将YOLOv5 的主干网络替换为MobileNet v3 是一种有效的轻量化方法,可以大幅减少模型的参数量和计算复杂度。但是,替换后模型的检测精度下降,为了提高模型的性能同时又不过度增加模型的参数量与计算量,就需要引入注意力机制。
目前的轻量级网络中,使用SE[5]模块作为注意力机制的例子比较常见,然而,SE 模块仅仅考虑了通道间的信息,忽略了位置信息。BAM[6]和CBAM[7]等注意力机制通过卷积来提取位置注意力信息,但卷积只能提取局部关系,缺乏长距离关系提取的能力。因此采用能够将横向和纵向的位置信息编码到注意力通道中的coordinate attention,如图5,使网络能够关注大范围的位置信息又不会带来过多的计算量开销,可以在模型轻量化的同时提高目标检测性能。

图5 在SPPF结构后加入CA注意力机制的结构图
3 实验数据集与实验环境
实验环境采用的操作系统为Ubuntu20.04.06 LTS,使用的CPU 为Intel(R) Core(TM) i9-9920X,主频 为3.50GHz,GPU 为3 块NVIDIA GeForce RTX 2080 Ti显卡,配置12GB显存,使用Pytorch 1.10.1框架。
实验采用的数据集为公开的Kaggle 数据集YOLO helmet/head[8]。YOLO helmet/head 数据集共包含22789 张图片,按照7:2:1 的比例划分训练集、验证集和测试集,数据集标注采用YOLO 格式,标签为head 与helmet。实验中使用的Batch size 大小为50,epoch为100。
为了降低模型参数量和计算量,本文选择将YOLOv5模型的主干网络替换为MobileNet v3 Small(即MobileNet v3_1)的主干网络,通过修改MobileNet v3 Small 主干网络中隐藏层的数量,生成了四种不同大小的MobileNet v3_X 主干网络,分别与不同宽度、深度的YOLO Neck 特征融合网络相结合。基于这些网络模型测试安全帽佩戴情况检测的性能。
此外,本文在修改后的模型上加入了CA 注意力模块,以进一步提升模型的性能,同时不会影响模型的参数量与计算量。
4 实验结果分析(需拆分)
模型训练过程在100轮后停止。训练过程中的指标变化如图6所示。
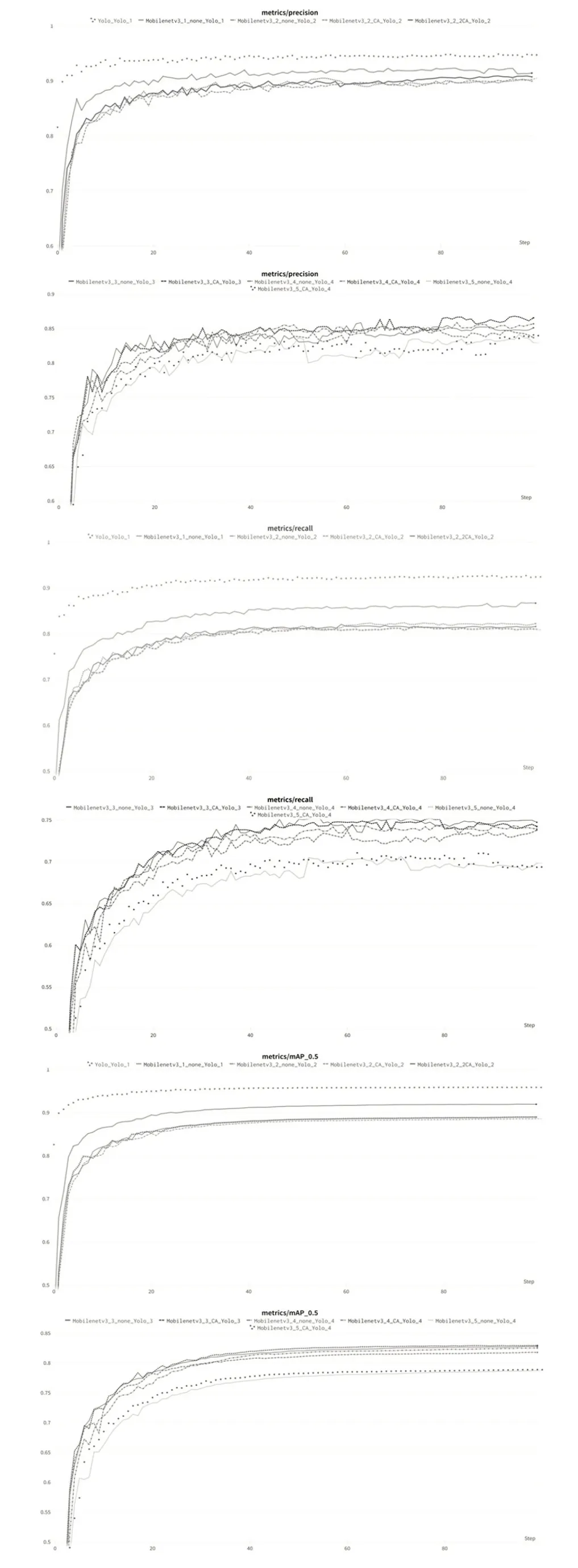
图6 100轮训练指标变化
为了更直观地验证改进后的YOLOv5 模型的检测效果,使用模型对测试集中的图像进行安全帽佩戴情况检测,并获得检测结果,如图7 所示。实验结果表明,改进后的轻量化模型能够满足任务要求。

图7 安全帽佩戴情况检测结果
表1 给出了实验结果的对比数据。将YOLOv5模型的主干网络替换为MobileNet v3 Small 网络后,模型的参数量和计算量都有显著的下降,但mAP 值也下降了3.95%。尽管如此,替换后的模型仍然需要较高的运行环境条件。因此,本文进一步修改了MobileNet v3 Small 的隐藏层和YOLOv5 模型的Neck 层宽度及深度,以获得更好的模型性能。这样组合而成的模型不仅在参数量和计算量上都有大幅度的下降,而且经过训练后的mAP 值也能满足任务要求。实验数据的对比表明,加入注意力模块的模型不仅能够提升性能,而且对参数量和计算量几乎没有实质性的影响。可见,加入注意力机制是一种有效的提高模型性能的方法,特别是在参数量和计算量都有限制的情况下。因此,建议实际应用中要根据具体情况选择是否加入注意力机制,以达到最佳的检测性能。上述实验结果可以为后续的目标检测研究提供参考和借鉴。

表1 实验结果对比
5 结束语
大规模深度学习模型在数据集上往往能达到比较高的性能。但在实际的生产应用中,为了适应特定的任务和环境,需要选择更加适合的模型,以降低成本或提高效率。本文研究了YOLOv5 算法模型的改进方法。在满足任务要求的模型性能条件下,将其主干网络替换为MobileNet v3 Small 网络,同时调整了各层的参数,使得模型的参数量和计算量大幅降低,以满足特定任务的环境条件要求;最后,通过引入CA注意力模块提高模型的性能,而不会增加模型的参数量和计算量,以满足任务的性能要求。
猜你喜欢
军事文摘(2024年2期)2024-01-10 01:58:34
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
广东教育·高中(2022年1期)2022-03-16 23:19:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
心肺血管病杂志(2020年3期)2021-01-14 00:42:12
心肺血管病杂志(2019年6期)2019-07-12 09:04:30
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电视技术(2014年19期)2014-03-11 15:38:20
