
基于图卷积神经网络和RoBERTa的物流订单分类
2023-10-21 02:36王建兵刘方方
计算机技术与发展 2023年10期
王建兵,杨 超,刘方方,黄 暕,项 勇
(安徽港口物流有限公司,安徽 铜陵 244000)
0 引 言
近年来,物流业运营模式逐渐从外包型向综合型转变,信息系统在物流企业的运营管理中扮演了关键角色。作为物流信息系统的中枢神经,订单子系统在提升企业运营效率、改善客户服务质量等方面发挥了积极作用[1]。个性化物流服务对订单操作流程提出了更高要求,物流企业亟需提高差异化订单的处理效率。通常而言,大型物流企业每天要受理成千上万个订单。对于每一个物流订单,客服人员需要根据不同的起运地、目的地、货物清单、服务要求等信息对订单进行拆解与分类,工作量巨大且容易出错[2]。依靠人工处理海量差异化订单,难以达到现代物流服务的效率标准。因此,研究智能化物流订单分类对于降低物流服务周期、提升客户满意度具有重要意义。物流供应链服务一般包括公路运输、水路运输、多式联运等业务类型,而多式联运业务又包括公水、铁水、公铁等类型[3]。客户通过物流平台提供的微信小程序以文本形式提交一站式委托订单,平台客服首先对订单文本进行分解,然后结合历史订单路线、最优路线完成物流订单分类,最后根据订单类型分拨到对应的业务系统以完成服务受理。为高效完成订单分类,平台客服不但需要对客户委托有深入的理解,还需要熟悉各种物流业务类型。然而,平台客服往往缺乏系统的业务培训,使得物流订单分类往往存在错误,造成了不必要的二次分拨。
支持向量机、决策树、朴素贝叶斯等机器学习方法能够完成工单分类,但特征的分析和选择使得特征工程较为复杂,可能会出现入模特征和指定任务不相关的情况[4]。RoBERTa预训练语言模型在文本特征的特征提取方面具有较好的优势,可以有效地提取文本的上下文信息,从而实现中文文本语义的向量化表示[5]。然而RoBERTa模型对于长文本处理能力较弱,而基于图结构的神经网络模型,如图卷积神经网络(Graph Convolutional Network,GCN),可以根据文本图有效提取文本的全局和局部图特征[6]。为了克服人工分类效率低下且容易出错的问题,该文提出了一种基于GCN和RoBERTa模型的物流订单分类方法。该方法使用抽象语义表示(Abstract Meaning Representation,AMR)解析订单文本的每个句子,获取输入文本多个AMR图以形成局部AMR图;根据输入文本的关键词以及AMR图的根节点构建全局AMR图,并使用GCN网络和堆叠GCN(stacked-GCN)网络来提取全局和局部AMR图的特征;通过RoBERTa模型提取订单文本语义特征,最终通过融合特征来完成物流订单分类。
1 相关研究
1.1 工单分类
文献[7]提出了一种基于ResNet-BiLSTM的电力客服工单分类模型,该模型利用残差网络学习句内的细节特征,再通过BiLSTM学习句间的上下文关联信息,最终得到工单的类别预测结果。文献[8]提出了一种基于事件提取的政务热线工单分类方法,该方法通过由CNN-BiGRU-Self-Attention定义的特征提取层获取工单文本的局部特征和全局特征完成工单分类。文献[9]提出一种基于矩阵分解和注意力的多任务学习方法,实现了运营商客服快速准确地对多层级的投诉工单文本进行分类。文献[10]使用word2vec模型对银行工单文本进行词嵌入化表示,使用深度学习下的TextCNN模型进行文本分类和工单判定。文献[11]利用TF-IDF方法对经过word2vec模型处理后的词嵌入向量进行加权,在TextCNN模型中进行训练后利用分类器自动完成银行工单类型判断。
1.2 图卷积神经网络
文献[12]针对在线知识社区中回答者用户之间的协作行为,通过构建基于图卷积神经网络的链接预测模型,对在线知识社区中回答者用户的协作行为进行预测。文献[13]根据交互历史构建读者-图书二部图,搭建图卷积神经网络,通过连续的卷积层捕获二部图的高阶连通性来得到读者的邻域偏好信息以实现图书推荐方法。文献[14]提出了一种基于图卷积网络的专利摘要自动生成方法,旨在通过专利的权利要求书及其结构信息来生成专利摘要。文献[15]提出了一种具有替代训练算法的自调优GCN方法,实现通过超参数优化来自动化训练GCN模型,从而可以通过自动选择参数的方式来缓解传统的GCN模型存在过拟合和过平滑的问题。文献[16]通过预训练语言模型生成全文句子之间的注意力矩阵,并将其作为文本全连通图的加权邻接矩阵,将GCN应用于文本图对每个节点进行分类,从而在文本中找出突出句子,最终生成文本摘要。
1.3 RoBERTa模型
文献[17]针对中文任务对RoBERTa模型进行了改进,使用了针对中文的Whole Word Masking(WWM)训练策略,在不改变其他训练策略的基础上,提升了RoBERTa模型在中文任务上的实验效果。文献[18]将多目标类别情感分析转换为多个子任务,使用RoBERTa模型从文本和目标短语中提取特征信息,并利用交叉注意力机制找出与给定目标类别最相关的特征。文献[19]提出一种民间文学文本预训练模型MythBERT,并与BERT、BERT-WWM和RoBERTa等主流中文预训练模型在情感分析、语义相似度、命名实体识别和问答四个自然语言处理任务上进行比较。文献[20]使用RoBERTa训练出荷兰语言模型RobBERT,实验结果表明在一系列荷兰语自然语言处理任务上RobBERT语言模型的性能要超越其他语言模型的性能,尤其在小数据集上表现地更为突出。文献[21]在情感识别方面比较了BERT、RoBERTa、XLNet等主流预训练语言模型,研究发现采用预训练语言模型学习到的词向量相比以往模型能够获得更多的上下文语义信息。
2 模型结构
该文提出的物流订单分类模型主要由基于全局AMR图的GCN特征提取层、基于局部AMR图的堆叠GCN特征提取层、基于RoBERTa语言模型的语义编码层和订单分类层构成,如图1所示。对于给定的物流订单文本,首先采用全局AMR算法构建全局AMR图,并使用GCN网络对全局AMR图的节点进行特征提取,获取文本的全局AMR图表示向量;其次,采用局部AMR算法构建多个AMR图,然后使用堆叠GCN网络提取多个AMR图的特征,并进行融合得到文本局部AMR图表示向量;再次,使用RoBERTa预训练语言模型提取订单文本的上下文语义特征,得到订单文本语义表示向量;最后,融合三种类型的文本表示向量,并使用全连接网络(Full Connection,FC)结合sigmoid函数完成订单分类。

图1 模型结构
2.1 基于全局AMR图的GCN特征提取层
从物流订单文本中提取特征信息的一个关键环节是捕捉句内和句间的特征。对于句子之间的相关特征,该文采用全局AMR算法处理物流订单文本生成该文本的全局AMR图,然后使用GCN网络来编码全局AMR图,以此得到订单文本句子之间的相关特征和订单文本的主题特征。
2.1.1 全局AMR图构建
AMR是一种全新的领域无关的句子语义表示方法,它将一个句子的语义抽象为一个单根有向无环图[22]。图2给出了一个句子“订单发货地点是铜陵市港口物流公司”的AMR图表示的示例,一个自然的句子可以通过AMR解析器被解析成一个AMR图G=(V,E)。V表示句子中的实词抽象的概念节点,而边代表一个特定的实词之间的关系(抽象为带有语义关系标签的有向边,且忽略虚词和形态变化体现较虚的语义)。因此,AMR侧重于语义关系而不是语法的, 这种表示方式更有利于理解物流订单,且这种结构更接近订单的“触发词和角色参数(trigger-arguments)”结构。

图2 AMR图示例
由于物流订单文本存在长短不一问题,且订单文本中的一些句子与订单主题并不相关。因此,该文提取订单文本的关键字以及AMR的根节点作为全局AMR图的串联节点,构建全局关系图,这样可以提取订单的主题信息和订单文本句子之间的关联关系。句间文本图的构建过程如下:
Step1 对订单文本进行分句处理得到n个句子,使用哈工大NLP工具包中关键词提取算法提取订单文本每个句子的关键词,得到n个句子的关键词集合{Ki};
Step2 对订单文本的n个句子进行分词处理,使用AMR算法将订单文本的每个句子抽象成n个AMR图;
Step3 对n个句子的AMR根节点进行对比,同样语义的根节点进行融合;
Step4 对n个句子的关键词集合{Ki}进行分析处理,不同句子之间存在相同语义的关键词进行融合;
Step5 根据n个句子的融合结果构建AMR全局图。
2.1.2 GCN特征提取
在GCN特征提取前,需要对构建的物流订单文本关系图进行节点编码。对于给定的物流订单文本T,节点编码首先需要对其进行分词,获取订单文本的分词序列Tq,然后使用词嵌入的方式对序列Tq进行编码,获取编码序列Eq:


em=λ1ξm+λ2pm
(1)

(2)

(3)

(4)
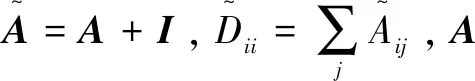
(5)
其中,W(0)是输入层到隐藏层的权重矩阵,W(1)是隐藏层到输出层的权重矩阵。
2.2 基于局部AMR图的堆叠GCN特征提取层
如图3所示,对于句子内部的相关特征,该文采用局部AMR算法处理物流订单文本生成局部AMR图,然后使用多层堆叠GCN网络来编码局部AMR图,并对编码结果进行融合,以得到订单文本句子内部的相关特征的融合结果。

图3 基于局部AMR图的堆叠GCN特征提取
2.2.1 局部AMR图构建
由于订单文本中的各句子对订单分类结果的重要程度不一样,且存在某些句子与订单类型的关联性不强(如收货联系人信息),因此,该文使用AMR算法对订单文本的每个句子进行处理,得到多个句子的AMR图。具体步骤如下:
Step1 对订单文本进行分句处理,得到n个句子;
Step2对n个句子分别使用AMR算法进行处理得到n个AMR图;
Step3将n个AMR图构成的集合形成订单文本的局部AMR图。
2.2.2 堆叠GCN融合网络

(6)
(7)
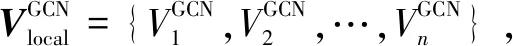
(8)

2.3 基于RoBERTa模型的语义编码层
RoBERTa模型是基于BERT的改进模型,相较于BERT,它拥有更大的模型参数、更大的batch size、更大规模的训练数据,同时删除了下一个句子预测(NSP)任务。这使得RoBERTa语言模型能够比BERT更好地应用到下游任务,取得更好的模型效果。


图4 RoBERTa特征提取
2.4 订单类别预测
(9)
其中,ω1,ω2,ω3是融合参数,满足ω1+ω2+ω3=1。将Vconcat输入分类器中完成订单的多标签分类:
p=sigmoid(WVconcat+b)
(10)
其中,W和b是可学习参数,p是各类别的分类预测概率。使用多标签分类的交叉熵作为训练损失函数:
(11)
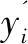
3 实验结果与分析
3.1 实验环境
该文使用基于CUDA 11.0的深度学习框架pytorch 1.7.1构建网络模型,实验平台为内存64G,显存24G的Ubuntu 18.04 LTS系统。
3.2 模型训练过程
该文提出的物流订单分类模型训练流程如图5所示。

图5 模型训练过程
首先,通过对历史物流订单文本进行分词、分句处理、去除停用词以及提取关键词后,结合历史物流订单的处理结果构建物流订单数据集。然后,将数据集按一定比例划分为训练集、验证集和测试集,其中训练集用于模型训练,验证集通过不断迭代更新模型性能,测试集用来评估模型性能。最后,使用训练好的模型进行物流订单类型预测。
3.3 数据集
从2017年1月1日-2021年12月31日期间安徽港口物流有限公司历史物流订单中挑选了30 000条订单构建了实验数据集,如表1所示。数据集包含订单文本数据和对应的订单类型,其中订单文本是客户物流委托内容,订单类型是由客服根据订单文本标注所得。同时,对30 000条订单文本进行了统计分析,这些物流订单文本长度均值为276个字。

表1 数据集描述
3.4 超参数设置
在整体网络训练过程中,文中模型的超参数如表2所示。

表2 超参数设置
3.5 基线对比实验
该文采用精确率(Precision)、召回率(Recall)、F1值、准确率(Accuracy)以及汉明损失(HammingLoss)作为物流订单分类性能的评价指标。为了验证文中物流订单分类方法的性能,与多种基线方法进行了对比。
· TextCNN[24]:使用预训练词向量来编码输入文本,然后采用卷积神经网络提取订单文本的嵌入向量来获取输入文本的特征,最终采用全连接网络结合sigmoid函数完成订单分类。
· HAN[25]:使用基于词级别的BiGRU+Attention和句子级别的BiGRU+Attention模型来提取订单文本多层次语义特征,然后采用sigmoid函数完成订单分类。
· TextGCN[26]:首先基于词共现和文档词关系构建语料库的文本图,然后使用one-hot编码对构建的文本图进行编码,最终采用GCN网络提取编码后的文本图完成订单分类。
· XLNet[27]:使用哈工大讯飞联合实验室训练的中文XLNet预训练语言模型(chinese-xlnet-base)提取订单文本特征,进行fine-tuning后应用订单分类任务。
· RoBERTa[17]:使用哈工大讯飞联合实验室训练的中文RoBERTa预训练语言模型(chinese-roberta-wwm-ext)提取输入文本特征,进行fine-tuning后应用到订单分类任务。
· BERT-GCN[28]:基于词节点与文档节点构建异质图,采用BERT预训练模型初始化文档节点,联合训练BERT模块和GCN模块完成订单分类。
基线对比实验结果如表3所示。从表中可以看出,该文提出的物流订单分类方法在各项指标上均优于其他基线模型。值得注意的是,TextCNN使用传统的CNN网络提取文本特征并进行分类,效果不佳,这是因为CNN网络仅仅能提取文本的局部特征,从而无法获取文本上下文信息。HAN由于是用双向GRU并结合Attention机制提取上下文语义信息,但是缺乏对文本局部特征的提取同时对于长句的特征提取能力也较差,因此仅取得了比TextCNN好的效果。对于XLNet和RoBERTa模型,可以有效提取订单文本的特征信息,因此取得了较好的效果。TextGCN使用GCN对文本图进行编码,可以有效地获取文本的句法结构信息,更好地解决文本长度问题,然而它对文本上下文信息的提取能力较差。而BERT-GCN由于加入了BERT模块,从而达到了更优的效果。由于RoBERTa模型在预训练阶段充分利用大规模无标注数据,可以更好地掌握通用语言能力,在绝大多数任务上都能表现出超越传统模型对文本上下文语义的提取效果,并且对于长短不一的文本可以使用GCN网络来提取文本的主题特征,因此该文提出的基于多种层次的图结构的订单分类方法拥有更好的性能。

表3 基线对比结果
3.6 消融实验
为了说明物流订单分类模型各模块的有效性,进行了消融实验:
①移除基于全局AMR图的GCN特征提取层,仅使用剩余两个模块的特征表示向量,其他部分保持不变。
②移除基于局部AMR图的堆叠GCN特征提取层,仅使用剩余两个模块的特征表示向量,其他部分保持不变。
③移除基于RoBERTa模型的语义编码层,仅使用剩余两个模块的特征表示向量,其他部分保持不变。
物流订单分类模型各模块的消融实验结果如表4所示。可以看出,该文提出的分类模型各项评价指标均优于①、②和③(文中模型>②>①>③)。③效果最差,说明了RoBERTa模型在订单文本特征提取方面有较大贡献,因而可以取得较好的效果。由②>①可知,基于全局AMR图的GCN特征提取层比基于局部AMR图的堆叠GCN特征提取层对订单文本特征提取的效果更好。由此可见,文中模型的各个模块均可以有效提高物流订单分类的性能。
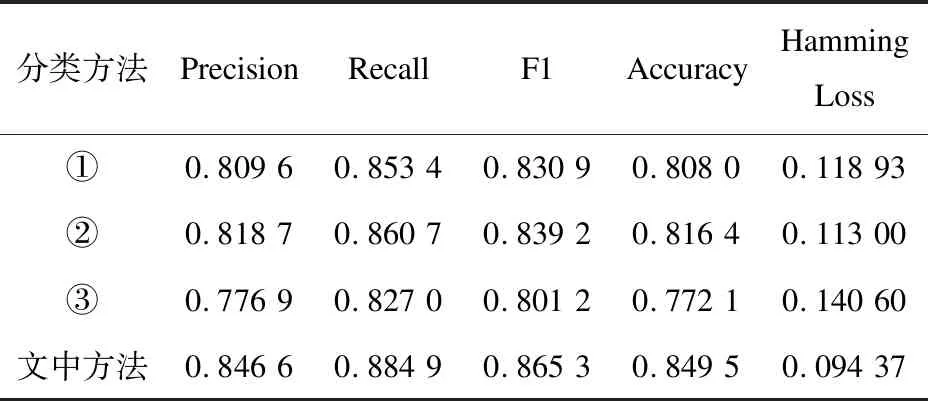
表4 消融实验结果
4 结束语
该文提出了一种基于图卷积神经网络和RoBERTa语言模型的物流订单分类方法。该方法通过提取订单文本的全局图、局部图以及文本语义的融合特征来实现物流订单分类。首先,基于全局AMR算法结合文本关键词构建全局AMR图,并使用GCN对提取全局AMR图的结构特征,获取订单文本的全局AMR图表示向量。其次,基于局部AMR算法处理订单文本分句,以生成局部AMR图集合,使用stacked-GCN处理局部AMR图集合,获取的局部AMR图表示向量集,并将向量集进行融合得到订单文本的局部AMR图表示向量。再次,使用RoBERTa模型提取订单文本的上下文语义特征,得到订单文本的语义表示向量。最后,融合三种类型的订单文本表示向量,并使用全连接网络结合sigmoid函数完成订单分类。由于采用了RoBERTa模型作为物流订单文本的上下文语义特征提取模型,对于长文本会进行截断,从而丢失语义信息,可能会导致错误的订单分类。未来,将进一步研究如何降低RoBERTa模型对物流订单文本截断所带来的性能影响。
猜你喜欢
今日农业(2022年4期)2022-11-16
中国石油石化(2021年9期)2021-03-30
开放教育研究(2020年2期)2020-03-31
电子制作(2018年19期)2018-11-14
当代陕西(2018年9期)2018-08-29
自动化学报(2017年11期)2017-04-04
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
创业家(2015年6期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
