
基于改进YOLOv5的铝型材瑕疵检测算法
2023-10-21 02:36杨国宇陈朝峰
计算机技术与发展 2023年10期
刘 柱,董 琴,杨国宇,陈朝峰
(盐城工学院 信息工程学院,江苏 盐城 224001)
0 引 言
伴随“中国制造2025”的提出,铝型材凭借其独特的质轻,柔韧性好等特点,在机械工业领域有着不可动摇的地位,其全行业的产量和消费量在世界范围内逐年递增[1]。在加工速度上涨的同时,由于环境等不可抗力因素,使得产品表面不可避免地产生瑕疵问题,这不仅仅是铝型材外观问题,它严重影响到了铝型材在应用时的可靠性和安全性。
通过调研发现,传统的检测方法成本高、操作复杂度高且对环境要求苛刻,无法实现可视化过程检测。伴随工业化的发展,机器视觉检测凭借精确、无接触测量等优点被广泛应用于瑕疵表面检测[2]。早期利用机器视觉进行表面瑕疵检测,主要是通过对缺陷照片进行图像处理提取瑕疵特征,这类方法能对特定瑕疵较准确地进行检测[3]。但对于铝型材瑕疵种类较多、尺度不一的情况,存在泛性较差、特征提取复杂、检测精确度不高等问题,因此在实际生产中局限性太大,难以满足生产需求。
近些年,基于深度学习的瑕疵检测算法因具有稳定高效、鲁棒性强的特点,在很多场景中得到了广泛的应用,取得了瞩目的成绩,并逐渐取代传统表面瑕疵检测方法。YOLO(You Only Look Once)算法的检测性能更为突出,在YOLO的基础上涌现出了YOLOv3[4]、YOLOv4[5]等众多改进算法。例如,刘浩等人在机床刀具的检测过程中采用了改进的YOLOv3算法,取代了传统的人工目测[6]。孙永鹏等人采用改进YOLOv4的检测方法提升冲压件的检测效率和检测精度并取得了良好的效果[7]。乔欢欢等人使用YOLOv5算法进行交通标志检测,取得了良好的检测效果[8]。
上述研究结果表明,YOLO算法在瑕疵检测方面具有良好的鲁棒性。因此,针对准确快速的检测需求,提出一种基于改进YOLOv5(You Only Look Once Version-5)的铝型材瑕疵检测算法。首先,在heard部分通过K-means++算法设计新的检测端,提升小尺度瑕疵的检测效果。其次,改进原Backbone网络结构,加入新的卷积层,并插入改进注意力机制E-CBAM,增强整个模型网络特征提取能力,减少原始信息丢失。最后,使用EIoU Loss(Efficient IoU Loss)作为整个网络结构的损失函数,加快收敛效率,从而解决难易样本不平衡的问题。通过评估不同改进策略对检测模型的影响,及真实产线下数据集实验数据对比不同检测算法,确保改进YOLOv5算法在满足工厂实际需求的同时,兼顾检测精度和检测效率。
1 改进YOLOv5算法模型
1.1 改进YOLOv5网络模型
YOLOv5是一阶段的目标检测算法,主要模型结构可分为Input(输入端)、Backbone(骨干网络)、Neck(颈部网络)及Head(输出网络)。
Input主要用于对输入数据进行规范化调整、数据增强、自适应锚框计算。当数据进入网络进行训练时,输入端会起到保持图片的大小一致作用,当输入数据量不够时,会自动对图像进行裁剪、反转扩充数据量,在训练阶段在初始锚点框的基础上输出对应的预测框。Backbone主要用于输入数据的特征提取,YOLOv5使用CSPDarknet作为骨干网络,在不同图像细粒度上聚合并形成图像特征的卷积神经网络。Neck网络借鉴CSPnet[9]研发出CSP2结构实现不同深度的特征图信息融合,增强神经网络对特征信息的表达能力,有效提高网络的特征融合性能。Head以CIOU Loss作为bounding box损失函数,使用三个不同尺度的Detect检测端在特征图上进行瑕疵位置确定及种类分别的预测。
为使得网络模型达到检测更精确、检测尺度更广、速度更快的瑕疵检测效果,针对铝型材瑕疵检测模型结构的改进将通过改进原有Backbone网络结构、加入优化注意力机制(E-CBAM)增强特征信息提取、添加新的检测端扩大识别尺度且锚框使用K-means++算法聚类生成、采用EIOU边界损失函数加快网络收敛的方法实现[10],改进后的网络结构模型如图1所示。
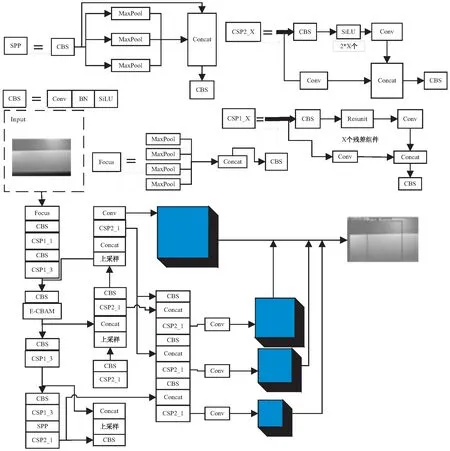
图1 改进后的YOLOv5网络框图
1.2 改进检测尺度及锚框优化
1.2.1 检测尺度优化
原有的YOLOv5模型结构采用三个检测端,以本实验为例,若输入的图片数据为640×640,通过卷积池化等操作步骤最终得到的检测尺度为80×80、40×40、20×20,这对于一般的检测任务是较为合理的,但对于铝型材表面瑕疵尺度多样化,且存在尺度差较大的瑕疵类别,为提升检测精度,在Neck网络结构中再一次进行上采样及张量拼接,将浅层特征与深层特征融合增大检测特征尺度10×10,同时在Backbone网络结构中增添一组CSP及CBS模块。
相比原有检测结构,新的检测端进一步加强了对特征信息的提取,并将浅层特征进一步融合得到更加丰富、高效的语义信息,拓宽感受野得到更多有用的特征信息,从而有效提升模型检测精度。
1.2.2 检测锚框优化
每个检测端的检测锚框采用K-means++算法聚类生成[11],原始算法的自适应锚框只适用于常规尺寸的数据集,而本次实验所用的铝型材瑕疵数据集瑕疵复杂程度较大,尺度大小差距较大,采用K-means++算法减小真实框与预设框的差距,避免发生错检、漏检现象,提升检测精度。
相比于传统的K-means[12]算法,K-means++算法使用IOU(Intersection Over Union)也就是预测框与真实框的交并比来计算样本与聚类中心的距离,从而控制不同大小边框的误差,公式如下:
DiStance(box,cluster)=1-IOU(box,cluster)
(1)
式中,box表示真实框集合,cluster表示聚类中心集合,IOU(box,cluster)表示真实框与聚类中心交集与并集的比例。
IOU值越高表示真实框与聚类中心越接近,相关度也就越高。初始化簇中心的方法为逐个选取k个簇中心,且离其它簇中心越远的样本点越有可能被选为下一个簇中心。计算公式如下:
(2)
其中,α表示数据集,D(X)表示每个样本与当前已有聚类中心之间的最短距离,P(X)表示下一个聚类中心的概率大小。
最终利用聚类分析得到最优的12个不同比例大小的锚框参数避免收敛速度慢的现象,其聚类结果和分配策略如表1所示。
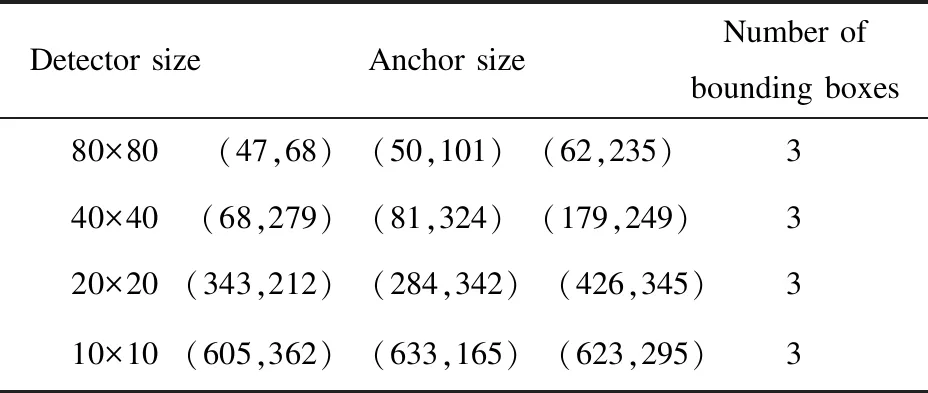
表1 聚类结果及分配策略
1.3 改进注意力机制E-CBAM
注意力机制(Attention Mechanism)能够根据需求选择最合适的输入,能够对齐两个序列之间的token关系,从而实现更好的效果。为了提升YOLOv5的网络表达能力,在Backbone网络中对CBAM[13]注意力机制进行改进,并命名为E-CBAM(Efficient Convolutional Block Attention Module)。
如图2所示,为选出针对当前数据集最合适的注意力机制,在Backbone网络结构中分别加CA[14]、ECA[15]、SE[16]及E-CBAM注意力机制后,通过pytorch与GradCAM[17]实现热力图可视化。通过比较特征图层的热力图可以明显看出,E-CBAM注意力机制针对当前数据集类别检测在精度和准确度要优于其他注意力机制。

图2 不同注意力机制热力图效果
通道注意力模块CAM(Channel Attention Module)[18]和经过优化后的空间注意力模块E-SAM(Efficient Spatial Attention Module)两个子模块共同组成E-CBAM(Efficient Convolutional Block Attention Module),结构如图3所示。

图3 E-CBAM结构
从图中可知,输入信息先通过一个通道注意力模块得到加权结果之后,再经过一个空间注意力模块,最终进行加权得到结果。
改进后的空间注意力模块结构如图4所示。空间注意力模块的主要工作包括:将Channel attention模块输出的特征图信息作为输入数据;将特征信息进行基于channel的global max pooling和global average pooling的处理,然后将这2个结果基于channel做concat操作;经过3个卷积核大小为3*3的卷积,降维为1个channel;再经过sigmoid生成spatial attention feature;最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
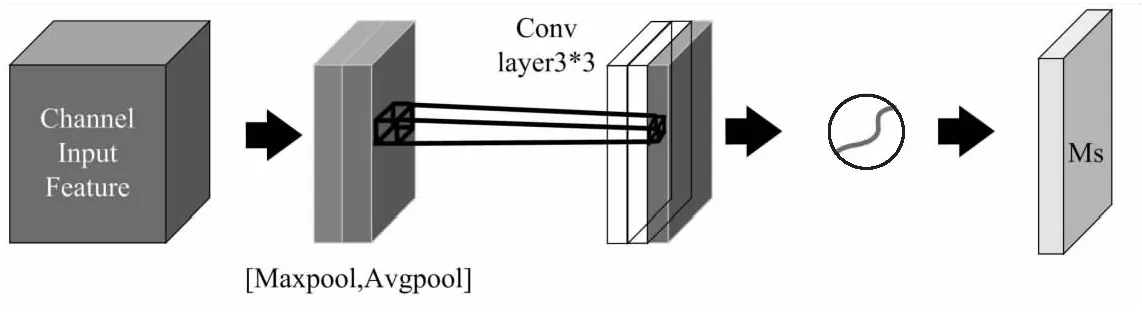
图4 改进空间注意力模块结构
整体表达公式如下:
Fs=Ms(Fc)⊗Fc
(3)
MS(F)=σ((f3×3([AugPool(F);
MaxPool(F)]))3)=
(4)
式中,Ms分别表示通道及空间注意力模块,Fs表示通道注意力特征图及空间注意力特征图。通过改进空间注意力的卷积结构,使用连续3*3大小的卷积核在原算法的基础上降低了模型的计算量。
1.4 损失函数EIoU(Efficient IoU Loss)
铝型材瑕疵种类较多,像素数量不均衡,因而容易忽略个别瑕疵的重要性,原始的损失函数纵横比差异不是宽高分别与其置信度的真实差异,因此在很大程度上会降低模型优化相似性。EIoU Loss[19]在CIOU[10]的基础上将纵横比拆开计算,使目标与锚盒的宽度和高度之差最小,从而加快收敛效率。针对BBox回归过程中样本数据问题,利用梯度下降方法,EIoU Loss基于Focal Loss把高质量的锚框和低质量的锚框分开,通过分类加权的方法提高回归精度,因此采用EIoU Loss作为整个网络结构的损失函数。该函数的惩罚公式如下:
LIOU=1-IOU
(5)
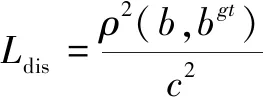
(6)

(7)
LEIOU=LIOU+Ldis+Lasp
(8)
LF-EIOU=IOUγLEIOU
(9)
式中,CW和Ch分别表示最小的宽度和高度,LIOU表示IOU损失函数,Ldis表示距离损失函数,Lasp表示宽高损失函数,Υ为控制异常值抑制程度的参数。b和bgt表示预测框和真实框的中心点,ρ表示计算两个中心点间的欧氏距离,c表示能够同时包含预测框和真实框的最小闭包区域的对角线距离。
2 实验结果与分析
2.1 实验环境及参数设定
在实验过程中选用Windows 10 x64的操作系统,处理器为Intel(R) Xeon(R) Gold 6258R CPU @2.70 GHz,显卡型号是NVIDIA Tesla V100S-PCIE-32 GB,采用Py-Torch1.12框架及CUDA11.3图形加速,运行内存为32 G,显存是256 G,采用SGD优化器,编译语言为Python3.7。
2.2 数据集处理
数据集采用广东某铝型材厂家提供的竞赛专用数据集,和实际生产中的情况直接相关,具有公开性、实用性。采用该数据集可以使得训练后的模型更具实用性,实验所用数据集中包含不导电、角位漏底、桔皮、漏底、杂色、起坑、漆泡共计7种常见表面瑕疵,如图5所示。

图5 数据集样本类别
通过对数据集进行离线增强,如旋转、亮度变化、裁剪等处理方式,将每种类型的瑕疵数据控制在700张,共计4 900张,并按照8∶2的策略划分训练集和检测集,由于原始数据集的标签格式为json,因此需通过脚本文件对数据集标签进行格式转换,调整为YOLO使用的txt格式数据标签。
2.3 评价指标
实验采用计算机视觉领域通用检测评价标准,AP(average precision)、mAP(mean average precision)以及FPS(Frames Per Second)作为模型性能评价指标,AP表示检测精度,mAP表示平均检测精度,FPS表示检测速度,其计算公式如下:

(10)

(11)

(12)
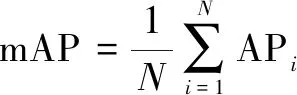
(13)
式中,TP(True Positive)表示检测正确数量,FN(False Negative)表示漏检数量,FP(False Positive)表示错检数量,P(Precision)为查准率,R(Recall)为查全率,N为目标检测任务的类别数量。AP的值越大,代表这个种类在该网络模型上检测效果越好,mAP值则反映该网络模型对目标检测的效果优劣。
2.4 实验对比
为验证改进算法检测性能的优越性,将改进后的YOLOv5模型与YOLOv3、YOLO v4、SSD[20]等主流算法进行对比,并以Precision、Recall、mAP、FPS作为评估指标,实验结果如表2所示。
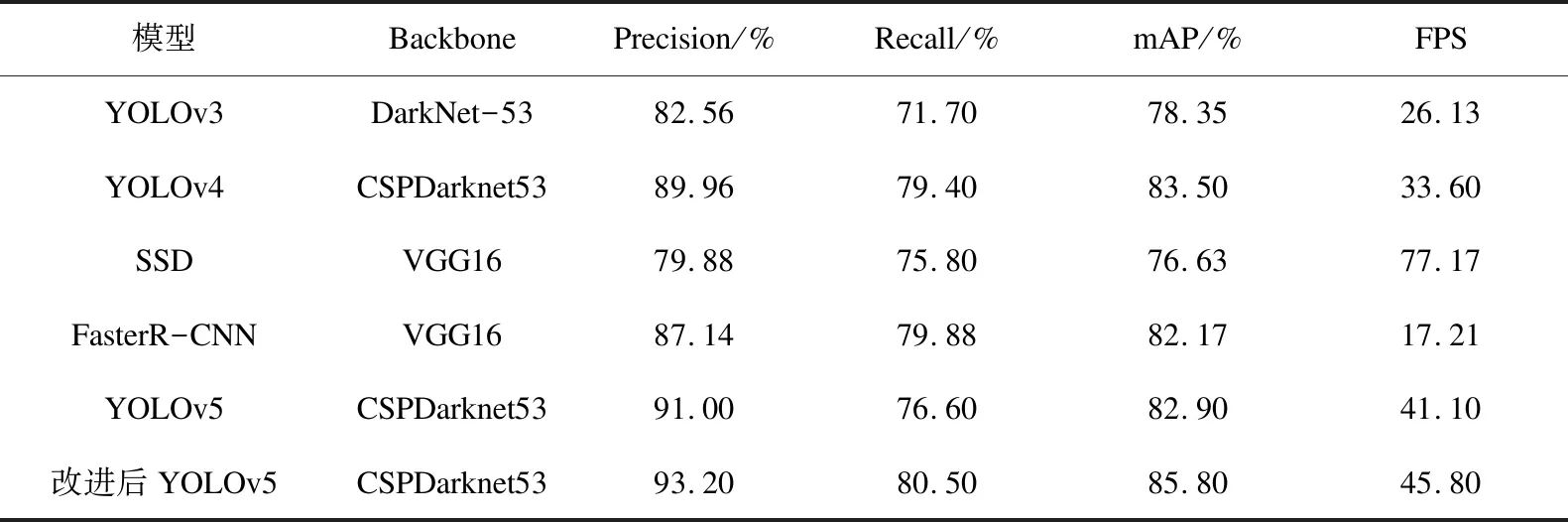
表2 不同网络结构性能对比
通过表2可知,改进后的YOLOv5在mAP达到了85.8%,相较于YOLOv3精度提升10.64百分点,召回率提升8.8百分点,mAP提升7.45百分点,各项指标均有提升,相较于原始算法,精度提升2.2百分点,召回率提升3.9百分点,mAP提升2.9百分点,FPS提升4.7百分点,同其他算法相比,检测性能及检测速度均具有优势。
2.5 消融实验
为进一步验证改进策略的有效性,在原有YOLOv5的网络结构接触上设计消融实验,主要改进策略包括:anchor、检测层、注意力机制E-CBAM、EIOU,在实验过程中为确保实验数据的可靠性,保证超参数、数据集等条件一致。消融实验结果如表3所示。
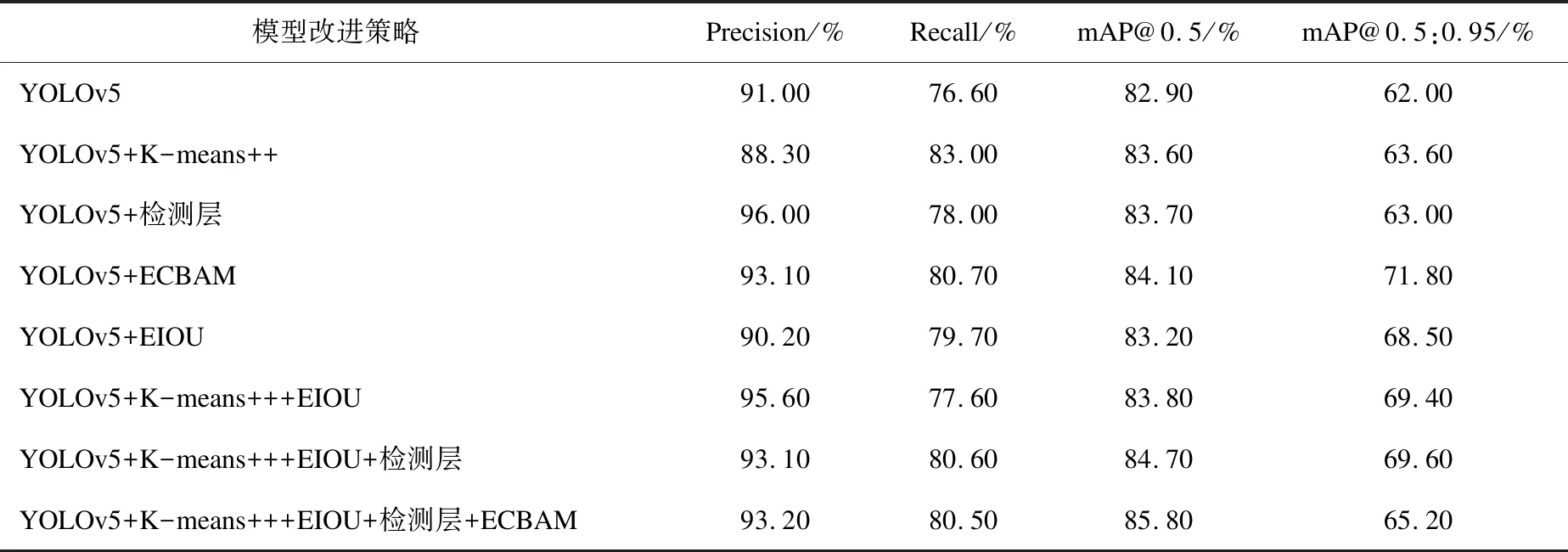
表3 YOLOv5消融实验
通过表3可知,在原始算法的基础上,使用K-means++锚框生成方式后,算法的召回率提升了6.4百分点,增加检测层后,将浅层特征进一步融合得到更加丰富,高效的语义信息,从而精确度提升了5百分点且召回率略有提升,在原有的YOLOv5基础上加入改进后的注意力模块E-CBAM发现,其精确度、召回率皆有提升,其中mAP@0.5:0.95更是提升了9.8百分点,提升了边框回归效果,对于IOU效果要求较高的任务是一项有效的改进措施。
通过表2、表3及图6数据展示可知,最终改进算法相比于原始YOLOv5算法,在各项精确度指标皆有提升,证明了算法改进的有效性,同时数据集数量满足了工业生产要求,模型的性能满足了企业需求。
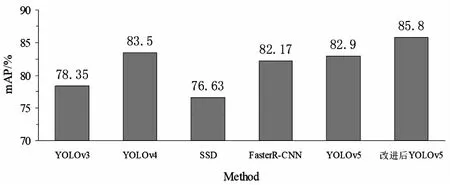
图6 不同检测模型的mAP比较
3 结束语
针对铝型材的不同瑕疵类别,提出了一种基于改进YOLOv5的铝型材瑕疵检测算法。通过融入改进后的E-CBAM注意力模块,减少冗余计算,弱化背景因素影响,加强铝型材瑕疵的特征提取能力;丰富检测尺度的同时,加入新的卷积核,提升算法对不同尺度目标的检测能力,加强对铝型材表面瑕疵的区域特征学习;采用K-means++锚框生成方式与EIOU损失函数相结合,使得算法回归更加专注于高质量锚框,提升了收敛效率,以及模型的精度和鲁棒性。
目前,铝型材相关厂家现场配备的摄像头像素较低,无法对相关瑕疵进行精确捕捉,针对该问题,可通过后期人工标注,及对采集的数据进行高分辨率重建,提升数据精度。因此后续研究方向可从瑕疵的尺度、分布及算法的边框回归函数进一步考虑改进。
猜你喜欢
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
法律方法(2021年4期)2021-03-16
扬子江诗刊(2019年3期)2019-11-12
扬子江(2019年3期)2019-05-24
制造技术与机床(2018年8期)2018-10-09
制造技术与机床(2017年2期)2017-05-04
制造技术与机床(2017年12期)2017-02-02
