
基于结构重参数化技术的轻量化目标检测算法
2023-10-21 02:36杨世恩陈春梅
计算机技术与发展 2023年10期
朱 郝,杨世恩,陈春梅
(1.西南科技大学 计算机科学与技术学院,四川 绵阳 621010;2.西南科技大学 信息工程学院,四川 绵阳 621010)
0 引 言
目标检测是计算机视觉领域的热门研究方向,经过数十年的发展,在生活中得到了广泛的运用,例如监控安全、人脸检测、自动驾驶等。目前,现有的主流图像目标检测算法可以分为两类:一类是二阶段的检测算法,先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类,检测精度较高,检测速度较慢,如RCNN、Fast R-CNN、Faster R-CNN等;另一类是一阶段的检测算法[1],只需一次提取特征即可实现目标检测,其速度相比二阶段的算法快,但检测精度会有所下降,如SSD、YOLO系列等;其中基于一阶段的YOLO系列目标检测算法最具有代表性,因其较好的综合性能,逐渐成为大多数实际应用的首选框架。
由于基于卷积神经网络的图像处理算法相较于传统的算法[2],具有更好的鲁棒性,于是越来越来多的研究者提出了更具有表征能力的深层网络,使得模型变得越来越复杂。尽管复杂的模型能够提供更高的精度,但也产生了一些问题:模型复杂度高,占用大量计算资源,不利于算法的落地应用。于是相关工作[3-5]利用骨干网络替换、深度可分离卷积、网络剪枝等方法减少模型的参数量(Parameter Count)和浮点运算量(FLOPs),达到网络轻量化的目的。但上述两种度量指标并没有考虑内存的访问成本和并行度,可能会对模型的推理速度产生较大的影响。为了进一步提高模型的推理速度,于是有了结构重参数化(structural re-parameterization technique)相关工作,如RepVGG[6-8]等。RepVGG将训练时的多分支结构和推理时的普通线性结构进行解耦,使用多分支拓扑结构进行训练,而后通过结构重参数化技术将多分支拓扑结构转为普通线性结构进行推理,这样既能保持多分支结构相当的鲁棒性,又能提高模型的推理速度。
为了进一步改善上述目标检测算法所存在的问题,该文基于结构重参数化技术设计了一个高效的轻量化目标检测框架。在维持较高的检测精度的同时,尽可能降低模型的规模大小。为了实现这一目标,结合YOLO系列算法的研究成果,该文设计了一个新的轻量化目标检测框架Rep-YOLO,其通过结构重参数化技术来解耦训练过程和推理过程,从而优化延时。
主要贡献如下:
(1)提出了Rep-YOLO,一种轻量化目标检测架构,与其他精度相当的算法相比,规模更小,检测速度更快。
(2)引入MobileOne[9]Style结构,并基于结构重参数化技术重新设计了Backbone和Neck。
(3)设计了一个轻量化解耦检测头(Decoupled Head)。
1 相关工作
1.1 YOLO
You Only Look Once(YOLO)是一种基于图像全局信息进行预测的一阶段的目标检测算法。自2015年Joseph Redmon[10]等人提出初代模型以来,领域内的研究者们已经对YOLO进行多次更新迭代,使得模型性能越来越强大。从YOLOv1到YOLOv7已经是一个庞大的家族。
主流的YOLO系列主要由四个部分构成[11],分别为Input层、Backbone层、Neck层、Head层。Input层先对图像进行预处理,Backbone层可以是VGG、MobileNet、RepVGG、EfficientRep和E-ELAN等骨干网络,以及附加模块SPP、SimSPPF[12]、ASPP等。Neck层由几个自下而上的路径和几个自上而下的路径组成,如FPN、PAN、BiFPN等。对于Head层,包含YOLOv3-v5[11-13]中采用的耦合检测头(Coupled Head)、YOLOX[14]使用的解耦检测头(Decoupled Head)和YOLOv6中的高效检测头(Efficient Decoupled Head),YOLOv7[15]在Coupled Head的基础上增加了辅助训练头(auxiliary Head)。
1.2 轻量化骨干网络MobileOne
MobileOne[9]是苹果公司研究人员于2022年提出的一种高效的移动设备骨干网络。在主流的高效网络中,在ImageNet上达到了SOTA的精度。与之前关于结构重参数化的工作一样,MobileOne在训练时采用分支拓扑结构,在推理时采用重参数化后的线性结构,便可减少内存访问成本,提高模型推理速度。MobileOne的结构如图1所示。MobileOne模块有两种不同的结构用于训练和推理。图1的左边是基于深度卷积的训练结构,上面是深度卷积,下面是点卷积。图1的右边展示了经过结构重参数化后的推理结构。
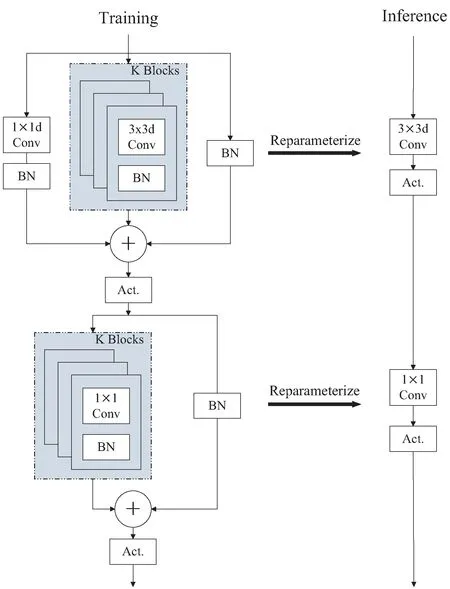
图1 MobileOne block结构
2 文中算法
在本节中,分析了轻量化模型设计中的FLOPs和Parameter Count这两个度量指标与推理延时的相关性。其次,在主流的YOLO系列的总体框架基础上,分别从以下三个方面对Rep-YOLO的架构进行描述:Backbone、Neck和Head;并对主要的训练策略进行介绍。
2.1 指标相关性
通常,网络的轻量化设计一般是通过降低Parameter Count和FLOPs这两个指标参数进行的,笔者也进行了相关的实验。以目前改进最多的YOLOv4为例,使用轻量化的骨干网络替换YOLOv4的Backbone,并将Neck和Head中的标准3×3卷积替换为深度可分离卷积。相关实验结果如表1,通过降低Parameter Count和FLOPs改进而来的YOLOv4,其推理延时明显减少。但总体上来看,改进的YOLOv4与参数量更大的YOLOv6s/v7相比在推理速度上并没有更快,可以看出推理延时和以上两个指标的相关性并不是特别强。其次,由于MobileNetv1-YOLOv4中不含残差结构,所以拥有更低的延时。因此,仅仅考虑减少参数量和浮点运算量这两个因素是不够的,还要考虑内存访问成本和并行度等因素,从而设计出一个高效推理结构。

表1 指标相关性实验
2.2 Backbone
YOLOv5/YOLOX/YOLOv7的Backbone和Neck都是基于CSPNet[17]搭建,采用的是多分支结构或者残差结构。对于GPU等硬件来说,这种结构一定程度上会增加延时,同时减小内存带宽利用率。YOLOv7中的ELAN模块是一个输入和输出相等的多分支结构,优点是可以提出更多的特征信息,拥有更好的鲁棒性。尽管如此,多分支结构在一定程度上会导致内存访问成本的增加,导致更多延时。因此,该文综合考虑内存访问成本和并行度等因素(如2.1所述),构建了MOne Backbone和DRep-PAN,其主要内容如下:
(1)引入了MobileOne block style结构。
(2)基于结构重参数化技术重新设计了Backbone和Neck。
MobileOne block style结构是一种在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个3×3深度卷积和一个1×1逐点卷积的可重参数化的结构(参考图1)。
MOne Backbone:在Backbone设计方面,基于以上的MobileOne block style结构设计了一个高效的backbone。相比于YOLOv5、YOLOX、YOLOv7等基于CSPNet的结构,MobileOne block style结构能够通过融合成的3×3卷积结构(单路结构),有效利用计算密集型硬件计算能力(比如GPU),同时也可获得GPU/CPU上已经高度优化的NVIDIA cuDNN和Intel MKL编译框架的帮助[13]。
MOne Backbone的结构如图2所示,原始的MobileOne是进行图像分类的网络,去掉最后的平均池化层和线性层,将剩下的部分作为文中算法的Backbone,并且保留了MobileOne所采用的缩放策略,引入了6种不同规格的Backbone(如表2所示)。在Backbone最后的附加模块中,采用的是YOLOv6所提到的SimSPPF,与YOLOv5中的SPPF不同的是SimSPPF的三个池化核大小都为5,其作用是能够有效避免对图像区域裁剪、缩放操作导致的图像失真等问题。

表2 MOne Backbone网络规格配置

图2 文中算法模型结构
2.3 Neck
DRep-PAN基于PAN[18]拓扑方式(如图2的Neck所示)。与YOLOv6的Neck结构相似,进行多尺度特征融合。与YOLOv6不同的之处在于,使用深度可分离卷积替换了标准的3×3卷积来降低3×3卷积的参数量,用MobileOne block替换了YOLOv6中的RepBlock,同时对整体Neck中的其他算子进行了调整,目的是在硬件上达到高效推理的同时,保持较好的多尺度特征融合能力。
2.4 Head
YOLOv6的Efficient Decouple Head结构是YOLOX检测头结构的精简版。YOLOv6将YOLOX检测头中的两个3×3卷积层,改为一个3×3卷积层并采用混合通道策略来减少网络延迟。在YOLOv6检测头的基础上,去掉了第一个用于维度调整的1×1卷积层;用1个基础MobileOne block模块代替标准的3×3卷积层,构建了一个轻量化的解耦检测头(如图3所示)。与YOLOv6检测头相比,参数数量减少了约40%。
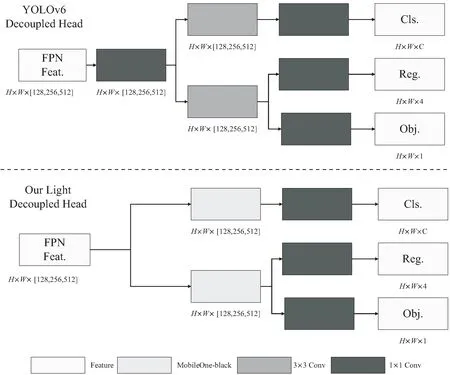
图3 轻量化解耦检测头结构
2.5 训练策略
2.5.1 SIoU边界框回归损失
边界框回归损失经过数年的发展,从L1/L2 Loss到IoU、GIoU、CIoU[19]Loss等。这些损失函数一步步将预测框与目标框之前的重叠程度、重叠的位置、中心点距离、纵横比等因素考虑边界框回归任务中。通过这些因素来衡量预测框与目标框之间的差距,从而指导网络最小化损失以提升回归精度。
以上这些方法都没有考虑到预测框与目标框之间方向的匹配性。因此,文中模型采用了SIoU[20]边界框回归损失,SIoU损失函数通过引入所需回归之间的向量角度,重新定义了距离损失,有效降低了回归的自由度,进一步提升了回归精度[20]。为了更加直观了解不同的损失函数对精度的影响,在Rep-YOLO-s0和Rep-YOLO-s1上进行对比实验,实验结果如表3所示,可以看出,使用SIoU损失函数训练的模型精度最高。

表3 损失函数对比
2.5.2 激活函数
为了分析激活函数对延时的影响,以Rep-YOLO-s0为基准,在RTX 3060上使用不同的激活函数进行了消融实验(如表4所示)。表4中的所有模型,除了激活函数之外,都有相同的结构,但它们的延时却是不同的。从实验可以看出,使用ReLU激活函数的模型的延迟最小。ReLU是目前设计神经网络时使用最为广泛的激活函数,如果输入值为负数,ReLU函数会转换为0,神经元不会被激活。这意味着在一段时间内只有少量的神经元被激活,这种稀疏性使得它的计算效率更高,使整个过程的计算量大大降低,从而减少延时。

表4 激活函数延时对比
3 实 验
3.1 实验准备
实验环境:11th Gen Intel(R) Core(TM) i7-11700 @ 2.50 GHz 16 GB内存,Nvidia GeForce GTX3060显卡,显存为12 GB。IDE平台为PyCharm,编程语言为Python3.6。Cuda版本为11.3,Cudann版本为8.2.0,使用Pytorch框架搭建网络模型,进行训练与验证。
数据集:使用PASCAL VOC(07+12)数据集,该数据集中包含20个类别,共21 503张图片。其中训练数据包含16 551张图片,共40 058个目标;验证数据包含4 952张图片,共12 032个目标。
3.2 训 练
所有的模型都是在PASCAL VOC数据集上从头开始训练的,输入图像大小为416×416,训练轮次(epoch)为300次,批次大小设置为16。训练过程中,对训练数据使用mosaic数据增强和mixup数据增强数据预处理技术进行处理,使得在训练过程中有70%的epochs,开启了mosaic数据增强,其中每个step有50%的图片使用了mosaic数据增强,并且对mosaic增强后的图片中50%图片进行 mixup[21]数据增强。使用SGD优化器,动量设置为0.937,标签平滑(label smoothing)因子设置为0.01。初始学习率为1e-2,学习率下降方式为余弦学习率衰减,使用L2权重衰减,权重值为5e-4。
3.3 关键技术——结构重参数化
结构重参数化技术是Rep-YOLO减少推理延时的关键(减少内存访问成本)。为了更好地理解使用结构重参数化技术带来的改进,进行了对比实验,除了是否使用结构重参数化技术进行训练结构与推理结构之间的切换之外,保持所有模型的结构和训练条件不变。比较结构重参数化前后的推理延时,实验结果如表5所示。结果显示,模型经过重参数化后,推理速度可以提高29%~40%。
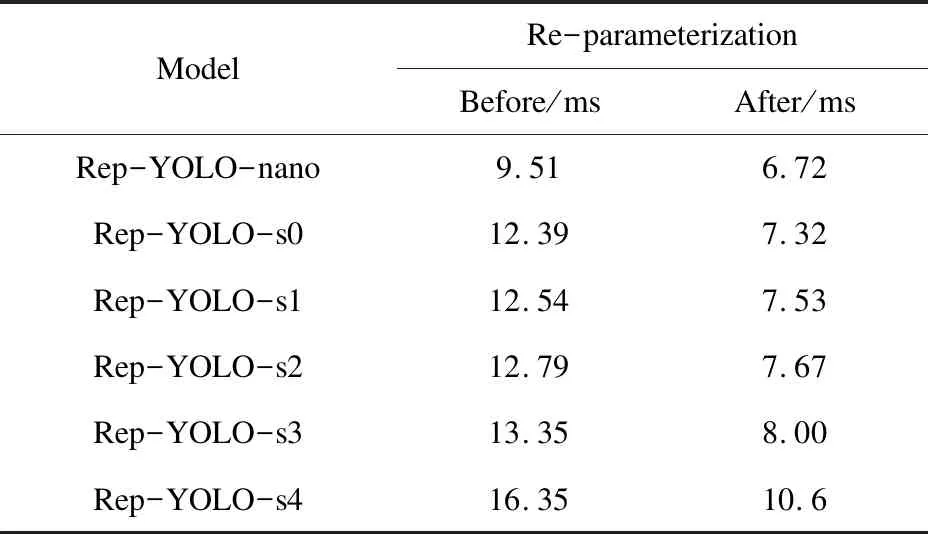
表5 结构重参数化前后对推理延时的影响
3.4 与其他先进算法对比
Rep-YOLO与其他先进的轻量化YOLO版本对比如表6、图4所示。可以看出,在类似规模的模型中,Rep-YOLO实现了速度与精度的良好平衡。比较如下:

表6 与其他先进算法对比

图4 算法对比
(1)Rep-YOLO-s4精度达到84.7%AP,推理延时为10.06 ms。Rep-YOLO-s4与YOLOv7进行比较,虽然模型在精度上低于YOLOv7,但Rep-YOLO-s4的参数量下降了51.7%,Rep-YOLO-s4的onnx模型大小是YOLOv7的48.1%。此外,Rep-YOLO-s3和Rep-YOLO-s2在检测精度和速度上也优于YOLOXs和YOLOv6s。
(2)Rep-YOLO-s1与YOLOxs对比,文中模型的推理延时减少了3.38 ms,检测精度提升了3.2百分点。另外,在参数量使用方面,Rep-YOLO-s1较YOLOv6s的参数量减少了9.43M,浮点运算量降低了10.17G,但是精度提升了2.4百分点。
(3)Rep-YOLO-s0与其他的tiny版本模型相比,其精度最高。较YOLOv7-tiny,精度提升了2.6百分点。较YOLOv6-tiny,在参数量和计算量更小的情况下,精度提升了0.7百分点。与YOLOv6s相比,在精度相当的情况下,Rep-YOLO-s0的推理速度提升了10.7%。
(4)推理延时为6.70 ms的Rep-YOLO-nano与推理延时为10.9 ms的YOLOX-nano相比,Rep-YOLO-nano的精度提升了7.8百分点。Rep-YOLO-nano与规模相当的YOLOv6-nano相比,精度提升了0.3百分点,推理延时减少了0.31 ms。Rep-YOLO-nano与YOLOv7-tiny相比,参数量下降了47.4%,精度提升了0.5百分点。
(5)图4直观展示了Rep-YOLO与其他规模类似的算法在精度、 检测速度和参数量大小方面的对比情况,越处于左上角的线表示算法的综合性能越好。从图7可以看出,文中算法Rep-YOLO位于较上方的位置,具有一定的优势。
4 结束语
介绍了在轻量化网络设计方面的经验,在骨干网络、多尺度特征融合和检测头等方面的设计优化进行了研究。为了进一步改善目标检测算法消耗大量计算资源的问题,基于结构重参数化技术提出了一个轻量化的目标检测网络模型。
在研究过程中,分析了轻量化网络设计的关键因素,通过结构重参数化技术将训练过程与推理过程解耦。在模型Rep-YOLO中引入了MobileOne style的结构,并设计了DRep-PAN Neck和轻量化的解耦检测头。实验结果表明,Rep-YOLO与其他类似规模的模型相比,在保持精度相当的情况下,拥有更小的体积和更少的延时。
未来会进一步对模型进行优化,持续提升检测性能,并在多种的硬件平台上进行实际场景应用。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
自动化仪表(2020年10期)2020-11-13
电子制作(2019年11期)2019-07-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
北京航空航天大学学报(2018年1期)2018-04-20
专用汽车(2016年1期)2016-03-01
船舶力学(2015年6期)2015-12-12
专用汽车(2015年4期)2015-03-01
