
基于日负荷指标及改进分布式K-means聚类的用户用电规律研究
2023-10-19 00:51:12李柏新雷才嘉方兵华黄裕春贾巍马乙歌
电测与仪表 2023年10期
李柏新, 雷才嘉, 方兵华, 黄裕春, 贾巍, 马乙歌
(广东电网有限责任公司广州供电局, 广州 510620)
0 引 言
负荷聚类和用电规律研究是进行精细化负荷预测的前提,不仅可以依据不同的用电规律划分用户类型,还可以与实际用户匹配展开用电特性分析[1]。此外,直接处理海量负荷数据不仅耗费计算资源,还会由于原始数据中存在干扰和低价值数据,引发模型训练难以收敛、耗时延长、增大预测误差等问题,有必要针对负荷数据提出一种更高效的降维及聚类方法。
目前,主流的聚类算法包括K-means聚类[2]、层次聚类[3]、模糊聚类[4]、谱聚类[5]等。比如,文献[6]提出了一种针对电力大数据的三层过滤机制,在第二层过滤中通过并行计算的多初始聚类中心对原始K-means算法进行了改进,弥补了太过依赖初始聚类中心的缺点;文献[7]利用Spark的RDD编程模型的可扩展性和分布式功能来实现CURE算法的计算过程的并行化,从而提高了算法的数据处理速度,使算法能够适应数据规模的扩展,并通过算例表明:基于Spark的CURE聚类算法不仅保证了聚类的准确性,而且提高了算法的实时性;文献[8]根据数据结构的特点,合理地优化了谱聚类算法中特征向量的提取过程,避免了传统方法导致数据信息丢失的问题,并以每日负荷数据为例对现有融合研究结果进行比较,结果表明该算法具有较高的聚类质量和鲁棒性。以上方法均对原始聚类算法进行了改进,并取得了更好的聚类效果,但是对于日负荷数据而言,本身具有显著的变化特征,如果能结合负荷特征指标实现数据降维,会极大提升聚类算法的效率。
提出了一种基于“峰谷”时段日负荷指标的数据降维及改进分布式K-means聚类算法。首先根据样本负荷数据的核密度(KDE)分布划分“峰”、“谷”期,并利用8个典型日负荷指标实现原始负荷数据的降维;然后利用熵权法改进的分布式K-means算法进行聚类,与原始K-means算法比较后发现,具有更强的样本辨识能力,并通过算例证明了文中所提算法的有效性和时效性;最后根据聚类结果分析每种负荷类型的用电特性,并与实际的负荷类型相匹配,得到4类典型用电规律的数据集,为不同类型负荷的精细预测提供支持。
1 负荷数据来源及预处理方法
1.1 负荷数据的来源
电力数据具有多源异构[9]的特点,而且保密性要求高,开放程度低。因此,获取海量负荷数据首先需要与电力公司配合,并进行脱敏处理。此外,政府和第三方机构大多有专门的数据网站和开源数据库,通过搭建API接口可实现数据采集。同时,电力用户侧的数据比较分散,一般需要访问企业、楼宇的相关网站,通过对HTML爬虫后整理获得。
总的来说,电力数据比较割裂,且各个系统间互联性较低,需要结合用户ID、采集日期DATA等用户信息标识对获取的原始数据进行融合与处理。
1.2 负荷数据的预处理方法
在负荷数据采集的过程中,不可避免会由于通信中断、信号干扰、人工操作失误等,造成数据异常和数据缺失等,需要对原始数据进行预处理。若单日m个时间节点负荷数据表示为一个样本,则n条日负荷数据组成n×m阶的日负荷矩阵L。
(1)处理缺失值
单缺失值:根据负荷曲线平缓变化的特点,采取前后数据均值插补的方法,计算方法如下:
li,j=(li,j-1+li,j+1)/2
(1)
式中li,j为第i天第j个时间节点的负荷;li,j-1和li,j+1分别为该节点前、后时刻的负荷数据;若单个缺失值恰为单日的首、尾节点位置,则取临近节点的值填充。
多个连续缺失值:由于样本连续缺失值数量直接影响插值结果的偏差,因此文中取较小的阈值(连续缺失值占比6%)来确保插值结果的准确度。超过阈值时认为该日样本无效;否则,采用平滑修正法根据前后数据插值,计算公式如下:
(2)
式中 Δt1和T1分别为前向采集开始和截止的节点数目;Δt2和T2分别为后向采集开始和截止的节点数目。
(2)处理异常值
先计算n条同时刻样本的均值和方差,从而设置阈值加以判断,然后根据前后节点数据进行插值修正,均值和方差计算公式如下:
(3)
(4)

li,j=α·(li,j-1+li,j+1)/2+β·li,j+1
(5)
式中α和β分别为该节点前、后时刻的负荷数据权重,且满足α+β=1。
(3)数据标准化
常用的数据标准化方法有三种:Min-Max归一化方法、Z-score规范化方法和Max最大值归一化。其中,Max方法将原始数据缩放,可以保留“峰谷”差值信息,其标准化处理方法如下:
(6)
2 基于日负荷指标的负荷数据降维
2.1 原始降维方法及指标的局限
主成分分析(PCA)[10]、奇异值分解(SVD)[11]、线性判别分析(LDA)[12]等降维方法虽然能从数据自身规律提炼出更少的特征,为后续学习器训练降低难度,并提高了效率,但是降维过程本身也会由于高维矩阵消耗大量的计算资源。对日负荷而言,如果能通过负荷变化特征,用低维日负荷指标代替高维原始负荷数据,会极大地缩短模型运行时间,提升负荷聚类的效率。
日负荷特征降维需要构造出能体现负荷基本特性和变化规律的特征指标。现阶段,国内外日负荷指标还没有统一的标准,大概有以下7种:日最大负荷Pmax、日最小负荷Pmin、日平均负荷Pav、日峰谷差ΔP、日峰谷差率α、日最大负荷利用小时数T、日负荷率β。以上指标虽然能反映日负荷的基本特征,但总体比较粗糙,还需要结合负荷“峰谷”变化规律构建更加显著的日负荷特征指标。
2.2 基于KDE模型的显著日负荷指标构建方法
文献[13-14]在划分“峰谷”时具有极大的主观性,因此如何根据海量负荷样本确定典型的“峰谷”时段是建立不同时段负荷特征指标的前提。由于核密度估计(Kernel Density Estimation,KDE)方法不使用有关数据分布的先验知识,并且不对数据分布附加任何假设,所以是一种从样本自身研究数据分布概率的方法,适用于从众多负荷数据中挖掘典型的日负荷曲线,划分“峰谷”时段。
假设某时刻有n个负荷样本,x1、x2,…,xn为对应的负荷值,则负荷的KDE模型如下:
(7)
式中fh为负荷的概率密度函数;h为带宽;K为核函数。其中,带宽h反映了整个KDE曲线的平坦度:h越大,样本数据点在曲线形状中的比例越小,使得KDE模型更注重整体变化规律,曲线越平坦;反之,KDE模型更注重细节,曲线就越波折。
为了确保负荷概率密度函数fh的连续性,核函数K(x)一般为单峰平滑,且关于y轴对称的非线性函数,满足以下特性:
(8)
比较常用的核函数有Uniform函数、Epanechikov函数、Gaussian函数和Quartic函数。选用Gaussian函数作为核函数,公式如下:
(9)
比如,当h选用0.5时,负荷概率密度函数fh可以表示为:
(10)
在KDE曲线上,概率密度最大值对应的负荷值即为该时刻负荷样本的典型值。针对样本其它时刻分别进行KDE处理后,便可整合得到典型日负荷曲线,从而进行“峰谷”划分。
结合全天、峰期、谷期3个时段,对原始7个简单日负荷指标进行组合变换后,得到表1中的8个显著特征指标。

表1 日负荷特征指标和计算方法
表1中,Pup-av为峰期的负荷平均值,Pdown-av为谷期的负荷平均值。通过以上8个日负荷指标来表征原始日负荷数据,便可结合负荷自身变化特征实现多维负荷数据的降维。
3 基于熵权法的改进分布式K-means聚类算法
3.1 K-means算法的缺陷
K-means算法是基于划分的经典聚类算法之一,通常欧式距离用作衡量样本间相似度的指标,在计算效率上具有其它方法无法比拟的优势。数据点越近,欧式距离越小,相似度就越大;由此将相似性较高的数据对象归为同一类,而相似性较低的数据对象则为不同的类。但是在实际操作过程中,两类具有不同变化规律的负荷,如果满足“互补性”要求,则很容易被错误划分为一类,如图1所示。
图1中,Type1和Type2两种负荷虽然具有截然相反的“互补性”变化规律,但由于二者到聚类中心的欧式距离相等,两个样本自然被错误划分为同一类簇。不难判断,如果这两类负荷到该聚类中心的距离均小于Type1和Type2与其它聚类中心的距离,则两类负荷始终被划分为一个类簇。因此,基于欧式距离的K-means聚类方法存在局限性。
3.2 改进分布式K-means聚类算法
熵权法是一种客观赋权法,通过比较各个评价指标自身的信息有序地来判定其权重。某项特征的样本差异越大,表示状态越混乱,该特征在所有特征中所占的权重也越大,样本间的差异被放大。
假如有n个日负荷数据样本,经过负荷指标降维后,每个样本有m个特征,则组成一个n×m维度的日负荷样本集Pn×m,则其熵值的计算方法如下:
(11)
(12)
式中j=1、2…m;pij为日负荷样本集的第i行,第j列数据;根据熵值Ej计算结果,得包含m个日负荷特征的信息熵集合为{E|E1,E2,…,En}。当样本数据差异较小时,Ej的值趋近于1。根据熵权法计算对应特征的权值wj,即:
(13)
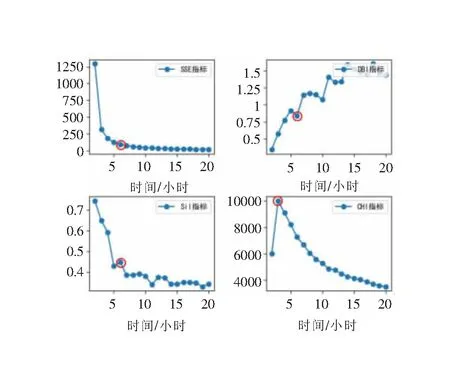
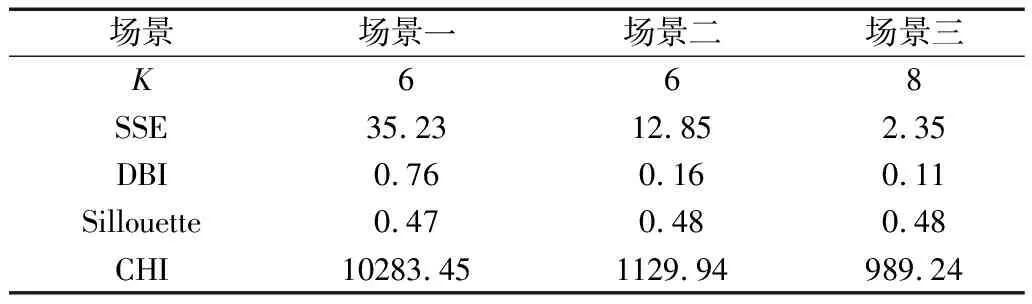
由此得到特征指标的权重值矩阵[w1,w2,…,wn],且满足0 结合如图2的分布式聚类算法,得到熵权法改进的K-means算法流程如下: 图2 分布式K-means聚类算法的流程图 (1)在日负荷特征矩阵Pn×m中参照层次聚类结果选取聚类中心,并将其作为n个输入,复制m份后分发给m台计算机。第i个聚类中心为Ci(i=1、2…k),记为Ci=[ci1,ci2,ci3,…cim]; (2)记Pj=[pj1,pj2,pj3,…,pjm],对Pn×m中所有样本Pj(j=1、2…n),派发给各个计算机节点,依次计算到第i个聚类中心Ci的加权欧氏距离: (14) (3)每个节点单独运算一次,将n个输入派发给c个内核,找出每个Pj对应最小的dist(Pj,Ci),将其划分到聚类中心Ci所在的类簇; (4)对每个簇,更新聚类中心Ci;记类簇Ci中样本数目为NCi,则其计算公式为: (15) (5)重复(3)和(4)的操作,直至新的聚类中心趋于稳定,或者该算法的损失函数式趋于收敛。 (16) (1)聚类有效性检验 聚类有效性指标用于度量聚类的效果,主要希望同一簇的样本彼此之间尽量相似,不同簇之间的样本尽可能不同。常用的聚类算法的评价指标有:离差平方和(SSE)、卡林斯基-哈拉巴兹指数(CHI)、轮廓系数(SIL)、戴维斯-布尔丁指数(DBI)等。记K为聚类数,则各个聚类效果评价指标的计算方法如下: SSE指标的计算公式为: (17) 式中Xi为第i类簇中的样本数据;Ci为对应第i类簇的聚类中心。SSE指标值越小,说明聚类效果越好。 CHI指标的计算公式为: (18) 式中i为当前的类簇;trB(i)为类簇间离差矩阵的迹;trW(i)表示类簇内离差矩阵的迹。CHI指标越大,说明聚类效果越好。 Silhouette指标的计算公式为: (19) (20) 式(19)、式(20)中,M为样本数;a(n)为样本n到类内其它样本的平均距离;b(n)为样本n到类间其它样本平均距离的最小值。Silhouette指标越大,聚类效果越好。 DBI指标计算公式为: (21) (22) 式中d(Xi)为类簇内的平均距离;d(Ck,Cj)为两个聚类中心的欧氏距离。DBI指标越小,说明聚类效果越好。 (2)聚类时效性检验 传统聚类评价指标只考虑有效性,但是对大数据而言,时效性同样重要,主要涉及到三个部分:基于日负荷指标降维方法的耗时、熵权法指标赋权计算的耗时、K-means聚类算法的耗时。为了验证本章所提算法在时效上的优越性,在控制处理相同负荷数据条件下,时效性指标可以表示为: Ktn=t2n/t2n-1 (23) 式中n=1,2,…,10表示10个数据样本;t2n为指标降维及改进K-means算法的耗时,t2n-1为原始K-means算法的耗时;当0 选取某市区供电网格2015年历史负荷数据,采集间隔为15 min,共计260 922个日负荷样本。算例编译环境为Anconda,编译语言为python,分布式计算采用ODPS架构。 根据全样本的KDE分布特征,提取对应96节点的典型负荷数据,得到日负荷曲线来划分“峰谷”时段,结果如图3所示。 全样本的“峰”、“谷”期的划分结果为:(1)峰期:08:00~11:30,15:00~23:00;(2)谷期:23:00~08:00、11:30~15:00。 根据表1的负荷指标计算方法,提取出每个样本的8个显著日负荷特征,与原96节点数据比较,数据量减少了91.67%,由此实现原始数据的降维。 结合熵权法对降维后的特征进行加权,计算结果如表2所示。 表2 日负荷特征指标的权值表 日负荷特征指标的权重计算结果,将用于改进K-means算法的中欧式距离的加权计算过程,增加算法对不同类型负荷的辨别能力,挖掘新的负荷类型。 (1)聚类有效性分析 算例中聚类数K取值为2~20,构造以下3个场景,并对每个场景下4个指标(SSE、DBI、Sillouette、CHI)对应的最佳聚类用“ ”进行标记,结果如下: 场景一:预处理前的K-means聚类效果。 图4中根据“肘部”法则,场景一的SSE指标曲线“拐点”对应的最佳聚类数6;DBI和Silluoette指标呈现单一变化趋势,原则上无法挑选出最佳K值,考虑到畸变数据影响,以区间极小值对应的6为最佳聚类数;CHI指标对应的最佳聚类数为3。 图4 场景一的负荷聚类效果 综合分析,聚类数取值为K=6,并根据分类结果得到日负荷样本的聚类曲线,如图5所示。 由图5知,未剔除畸变数据的负荷样本总体上实现了负荷的分类,但在每类负荷中明显存在“毛刺”现象;且在type2、type4负荷中,红色聚类中心线没能体现出10:00~15:00之间存在的“峰”期。 场景二:除畸变后K-means的聚类效果。 如图6所示,通过式(1)、式(2)缺失值处理,以及式(3)~式(5)异常数据处理后,场景二的SSE指标“拐点”对应的K仍为6;DBI指标曲线明显存在极小值,且对应的K为6;Silluoette和CHI指标也明显存在极大值,对应的K均为8。以上说明数据预处理对提升聚类效果有一定影响,但仍旧未能统一最佳聚类数。 图6 场景二的负荷聚类效果 当K=6时,得到日负荷样本的聚类曲线如图7所示。 图7 场景二条件下的负荷聚类结果 由图7知,与场景一比较,每类负荷中没有“毛刺”现象,且每一类样本的变化规律较为一致,说明通过缺失值弥补和异常值替换后消除了畸变数据影响,使得聚类效果有了质的提升。但是,仔细观察发现,如“→”标记,type1、type2负荷中存在很窄的“间隙”,说明类中样本仍旧存在细微的差异。 场景三:除畸变后改进K-means的聚类效果。 如图8所示,场景三的SSE、DBI、Silluoette和CHI指标统一了K值,即最佳聚类数均为8。说明基于日负荷指标降维和熵权改进的K-means算法显著提升了聚类效果,能从现有聚类结果中发现新的类簇。 取K=8得到日负荷样本的聚类曲线如图9所示。 图9 场景三条件下的负荷聚类结果 由图9知,与场景二比较,场景三多出了两个聚类簇。其中,type2、type6原属场景二中同类,区别在于05:00~18:00时间段最低负荷值,前者在0.1左右,后者基本为0;type3、type8也由场景二中同类分裂而来,两类负荷在12:00左右的谷值负荷差距明显,前者为0.8,后者为0.9。因此,场景三的基于日负荷指标降维和改进K-means算法能够挖掘出负荷样本间更加细微的差别,从而实行更精细的聚类结果。 对以上三个场景的最佳聚类数K和聚类效果有效性指标进行统计,结果如表3所示。 表3 不同场景下的聚类效果 由表3分析知,场景三聚类数最多,能够将细小差别的类簇进一步划分,具有更高的类簇辨识能力;从场景一到场景三,SSE和DBI指标的数值依次减少,说明剔除畸变数据、日负荷指标降维及改进K-means聚类方法能够一定程度上提高聚类效果;Sillouette指标基本不变化,说明该指标在最佳聚类场景下具有很强的稳定性;从场景一到场景二,CHI指标显著减小,说明该指标对畸变数据比较敏感。 (2)聚类时效性分析 构造10个不同数据量的样本集,然后记录各部分的时间。作出时效性指标Ktn随样本占比M的变化曲线,探究算法的时效性与数据量的关系,如图10所示。 图10 时效性指标随数据量变化 由图10知,Ktn基本分布在[0,1]范围,且呈现出“1/Mn”型变化规律,说明基于日负荷指标降维及熵权法改进分布式K-means算法在应对大量负荷数据时,可以显著提升工作效率。 通过聚类得到的典型负荷,各自具有不同的时序性变化规律,能够直接反映出用户的用电特征,甚至可以对每种典型曲线包含的负荷类型进行初步匹配。8类典型负荷曲线之间既存在差异,又有一定的相似性,大致归属以下4种规律类型,如表4所示。 对每种规律类型包含的负荷进行以下分析: (1)第1种规律类型 全天负荷具有“高低双峰”的特点,其中白天09:00~14:00为低峰负荷段,晚间20:00~22:00为高峰阶段,而凌晨和早间的负荷水平较低。据此特点分析,type1负荷大致为商场、店铺等典型商业负荷,负荷大小与其人流量、营业及休息时间相适应。 (2)第2种规律类型 该类具有晚间“单高峰”的特点,在8:00~16:00保持较为平缓的中等负荷水平,在晚间20:00左右达到高峰,至凌晨负荷达到最低水平。据此分析,type4极有可能为上班族的家庭负荷,白天离家后,冰箱、空气净化器等电器继续保持工作,直至晚间回家后,做饭、照明、娱乐等活动导致用电增加,在20:00点左右达到用电高峰,23:00休息后负荷又恢复至低水平状态。 (3)第3种规律类型 全天负荷具有极为典型的“U”型变化特征,在白天5:00~17:00之间负荷水平很低,而在晚间及凌晨负荷水平保持较高,且负荷波动较小。据此知,该大类很可能是公园路灯、公路照明等室外负荷,或者公共场所的室内照明,以及利用分时电价将生产任务更多地转移到晚间进行的工业负荷。对照明负荷而言,根据type2和type6白天负荷最低值是否为0,可以判断前者主要为室内,后者为室外。 (4)第4种规律类型 该类型具有显著的“三峰”特征,09:00~11:00、14:00~17:00、18:00~21:00为三个峰期阶段,且峰期负荷差别较小;中午12:00和晚间16:00左右有两个短时的“谷期”,与吃饭和午休时间基本重合。由此推测,type3、type5、type7、type8为普通上班负荷,该大类应该包含普通工厂、车间、写字楼、科研教学等场所的商业、科教,或者工业负荷等。 通过以上分析,将供电区域的日负荷数据进行聚类后,可以根据负荷规律对其属性进行标记,比如商业、居住、工业及科教等,构造同类负荷的数据集合,为精细化负荷预测提供高质量数据。 基于日负荷指标将原始负荷数据进行降维,利用熵权法对分布式K-means算法的距离计算实施加权,提升了聚类算法对高相似度样本的辨识能力,且具有较高的时效性;通过算例验证了所提算法的可行性,并对典型负荷的用电特性展开分析。同时,存在以下不足: (1)畸变数据的处理,其假设条件是各节点负荷值在均值附近随机正态分布,从而过滤偏离度较大的数值,实际上并非完全符合正态分布规律,在过滤过程中会损失很多有效样本; (2)基于熵权法改进的K-means聚类算法虽然能够提升辨识能力,划分更多的类簇,但同时说明其鲁棒性较差,容易受小样本数据的影响。

3.3 聚类效果的检验指标
4 算例分析
4.1 基于KDE的负荷数据分布及峰谷时段划分
4.2 日负荷指标的降维及权值计算

4.3 聚类效果分析




4.5 典型日负荷曲线与用户特征分析
5 结束语
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12海峡姐妹(2019年12期)2020-01-14 03:24:40电子测试(2017年15期)2017-12-18 07:19:27东北电力技术(2016年2期)2016-05-17 04:32:46中国化肥信息(2016年35期)2016-05-17 04:25:50智能系统学报(2015年4期)2015-12-27 09:38:39核科学与工程(2015年2期)2015-09-26 11:56:59电子设计工程(2015年6期)2015-02-27 12:04:53电测与仪表(2014年14期)2014-04-04 11:53:40计算物理(2014年1期)2014-03-11 17:00:18
