
基于深度强化学习的存内计算部署优化算法
2023-10-18 16:25:43胡益笛夏银水
计算机应用研究 2023年9期
胡益笛 夏银水


摘 要:针对存内计算大规模神经网络部署导致的计算延迟、运行功耗较大等问题,提出了基于深度强化学习的神经网络部署优化算法。首先,建立了马尔可夫决策过程的任务模型,优化神经网络的延迟和功耗,完成片上计算核心的部署。其次,针对优化部署过程中,存在求解空间过大、探索能力不足等问题,提出了一种基于深度强化学习的智能部署优化算法,从而得到近似最优的神经网络部署策略。最后,针对强化学习探索能力不足的问题,提出了一种基于内在激励的奖励策略,鼓励探索未知解空间,提高部署质量,解决陷入局部最优等问题。实验结果表明,该算法与目前强化学习算法相比能进一步优化功耗和延迟。
关键词:存内计算; 深度强化学习; 神经网络部署; 近端策略优化; 内在激励
中图分类号:TP391.7
文献标志码:A
文章编号:1001-3695(2023)09-008-0000-00
doi:10.19734/j.issn.1001-3695.2023.02.0047
Processing in memory deployment optimization algorithm
based on deep reinforcement learning
Hu Yidi, Xia Yinshui
(College of Information Science & Technology, Ningbo University, Ningbo Zhejiang 315211, China)
Abstract:To address the issues of computational latency and high operational power consumption caused by the deployment of large-scale neural networks for in-memory computing, this paper proposed a deep reinforcement learning-based optimization algorithm for neural network deployment. Firstly, it established a task model for Markov decision processes, which optimized the latency and power consumption of the neural network and completed the deployment of the on-chip computing core. Secondly, to tackle the challenges of excessive solution space and insufficient exploration capability during the optimization process, it introduced a deployment optimization algorithm based on deep reinforcement learning to obtain a near-optimal neural network deployment strategy. Lastly, it proposed a reward strategy grounded in intrinsic motivation to address the lack of exploration ability in reinforcement learning, encouraging the exploration of unknown solution spaces, enhancing the quality of deployment, and resolving issues such as getting trapped in local optimality. Experimental results demonstrate that this proposed algorithm further optimizes power consumption and latency compared to current reinforcement learning algorithms.
Key words:processing in memory; deep reinforce learning; neural network deployment; proximal policy optimization; intrinsic reward
0 引言
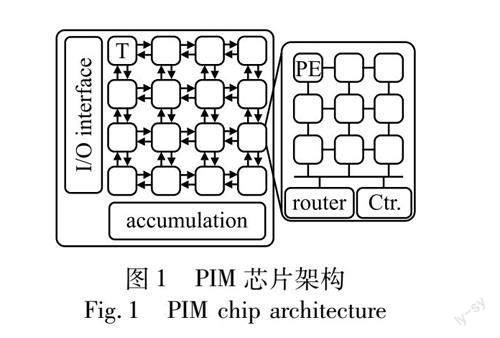
近年來,从人工智能领域兴起的神经网络算法在如计算机视觉[1]、语音识别[2]、自动化[3]等诸多应用领域都取得了显著的成果。通过堆叠网络层数的深度神经网络算法具有层数深、参数多等特点,需要更适合的计算架构。在众多计算架构中,存内计算(processing in memory,PIM)以其高集成性、高并行性和低功耗的优势而备受关注。PIM架构中通常使用阻变式存储器(resistive random access memory,ReRAM)[4,5]进行存储和计算,结合纳米线阵列构成的RRAM阵列结构为PIM架构中的核心计算单元(计算核),如图1所示,T(Tile)为计算核,包括9个处理器(processing engine,PE),其中PE内集成了行列为64或128的RRAM阵列。
在神经网络部署任务中,神经网络参数被平均分布在计算核上,通过路由器实现PIM的片上通信。基于上述PIM架构,工业界和学术界已经提出了诸如IBM的TrueNorth[6]、英特尔的Loihi[7]、BrainChip的Akida和NeuRRAM[8]等PIM芯片。
如图2所示,在PIM芯片上部署神经网络算法通常需要两个步骤:逻辑映射和物理部署。在逻辑映射阶段,神经网络按照计算核容量被划分为计算节点,由有向无环图(directed acyclic graph,DAG)表示,称为逻辑图。在物理部署阶段,将逻辑图的节点依据图拓扑结构、芯片的路由策略和计算核排列方式,部署到片上计算核中。不同的部署结果会对芯片延迟、功耗等性能有较大影响,因此探索一种从逻辑图至多核芯片的低延时低功耗的部署策略至关重要。
目前,已有大量工作面向延迟功耗优化的神经网络的物理部署问题。Ostler等人[9]提出了基于整数线性规划(integer linear programming,ILP)的方法,实现逻辑图至4×4的多计算核系统部署,优化了计算功耗。然而,在大规模部署任务中该方法存在计算时间长的问题。Joseph等人[10]提出负载平衡的方法,使用蛇型部署的方式获得一个良好的物理部署,并使用启发式算法进一步降低延迟。Wu等人[11]使用二维矩阵表示当前部署结果,通过深度确定性策略梯度(deep deterministic policy gradient,DDPG)训练部署策略,与模拟退火算法相比降低了18.6%的延迟,但它在训练过程中,没有考虑逻辑图的拓扑关系,其训练效果比较有限。Myung等人[12]创新性地使用图神经网络提取逻辑图的拓扑关系,并以此指导部署策略的学习,在包含8×8和16×16个计算核的PIM芯片内,相比模拟退火算法在延迟和功耗上分别降低了19.4%和10.9%。但在此过程中已提取的信息不会随着部署的进行而变化,导致策略更新缓慢,难以进一步优化部署。
研究发现,相比于传统的启发式算法,融合深度神经网络(deep neuro network,DNN)和强化学习(reinforce learning,RL)的深度强化学习(deep reinforce learning,DRL)更善于求解各种组合优化问题,在计算机视觉、机器人控制、电子设计自动化[13,14]等领域中,取得较好的优化效果。
神经网络至多核系统的物理部署优化是组合优化问题之一。DRL通过状态变化进行组合优化的策略选择,以使长期累积的奖励和最大,具有较大优势。
在PIM芯片的物理部署研究中,DRL算法学习选择逻辑图节点至PIM芯片上的计算核的部署策略。在此过程中,完整逻辑图的部署称为单轮部署。通过多次的单轮部署,DRL学习到有效的部署策略。但是现有基于DRL的神经网络多核部署研究中,缺乏单轮部署中间状态的观测和奖励的反馈[11,12],难以引导DRL算法的更新方向,存在稀疏奖励问题。
针对部署优化问题,本文从单轮部署出发,丰富中间状态表示,构建内在激励,优化物理部署结果。因此部署过程中需要提取中间状态信息,并基于中间状态的差异构建内在激励,将稀疏奖励转变为稠密奖励。首先,将物理部署问题建立为马尔可夫决策过程(Markov decision process,MDP)模型,定义了状态表示和决策方式。其次使用图神经网络和卷积神经网络提取当前部署状态的信息。依据状态信息的变化定义内在激励,DRL在目标函数与内在激励共同作用下通过近端策略优化[15](proximal policy optimization,PPO)更新部署策略。本文的主要贡献为
a)对优化部署问题,通过建立丰富中间状态的MDP模型,联合优化部署后的通信开销和延迟,并使用DRL算法对该问题进行求解。
b)采用图神经网络和卷积神经网络结合的信息提取算法,丰富了部署过程中的信息表达,更精准决策。在部署的过程中,提取当前部署状态和逻辑图的信息,作为每一次部署决策的依据。
c)使用内在激励算法,在8×8和16×16等多计算核系统的物理部署阶段解决稀疏奖励问题。单轮部署中,根据当前状态为DRL构建不同的内在激励。通过内在激励促进DRL对新状态的探索,进而学习到更高质量的部署策略。
1 研究基础和术语
1.1 物理部署
物理部署是将神经网络的逻辑图部署到计算核上的过程,如图3所示,根据计算核的容量限制,将神经网络转变为逻辑图。逻辑图由节点和加权边组成,被部署在一个网格(Mesh)结构的PIM芯片上。为方便后续讨论,将逻辑图和片上的多计算核拓扑图给出有关定义如下。
逻辑图使用一个有向无环图表示,定义為G=(A,E),其中ai∈A表示神经网络计算节点,ei,j∈E表示计算节点ai与aj之间有向加权边。其中权重表示为两个节点之间的通信量comni,j。
计算核的拓扑图表示为一个有向图T(N,P),其中每个顶点ni∈N表示计算核,每个路径pi,j∈P表示顶点ni与nj之间在路由策略下的最短通信路径。
应用任务图G(A,E)到拓扑图T(N,P)的映射函数定义如下:
map:G→T s.t. map(ai)=ni
ai∈A,ni∈NA≤N(1)
片上的多个计算核通过片上网络(network on chip,NoC)传输信息,因此部署结果通常由NoC模拟器进行评估,如BookSim[16]、Noxim[17]等。
随着PIM芯片集成核数的增加,部署策略的探索空间呈指数性上升。启发式算法主要处理具有数十个核的系统,且设计空间探索能力有限,其计算复杂度随着系统规模的增大而急剧增加。在大规模探索空间求解问题中,使用DRL算法可较好求解该问题[18]。
1.2 强化学习
DRL是一种基于马尔可夫决策过程的通过与环境ε交互进行学习的试探性算法。如图4所示,在单个时间步长中,智能体从环境中获取当前状态st,并根据策略π从动作空间A中选择一个动作at,从环境中接收到下一个状态st+1和奖励rt作为回报。相较于RL,DRL使用神经网络作为智能体,学习能力更强。
时间步长t后的累计奖励Rt表示为
Rt=∑∞k=0γkrt+k(2)
其中γ∈(0,1],为折现因子。状态—动作价值定义为
Qπ(s,a)=Eπ[Rt|st=s,at=a](3)
Qπ(s,a)是依据策略π在状态s时选择动作a后的预期回报。状态价值Vπ(s)定义为
Vπ(s)=E[Rt|st=s](4)
状态价值是根据策略π从状态s开始的期望回报。智能体的目标是使每个状态的期望收益最大化。
PPO是一種基于策略的DRL算法,其计算复杂度明显低于其他策略梯度方法。PPO在策略更新规模的约束下最大化奖励期望:
maximizeθ Etπθ(at|st)πθold(at|st)t(5)
其中:πθ(at|st)是当前的策略;θ是该策略的参数;πθold(at|st)表示更新前的策略;Et[]表示一定步数内可获得的奖励期望。式(2)(6)中t为t时刻动作at相比其他动作的优势,定义为预期回报与状态价值的差值。
t=Qπ(s,a)-Vπ(s)(6)
在此过程中,PPO限定参数的更新范围,防止参数过度更新。令pt(θ)表示参数更新前后的策略偏差程度:
pt(θ)=πθ(at|st)πθold(at|st)(7)
PPO通过clip()限制策略偏差范围
clip(pt(θ))=pt(θ) if 1-ε≤pt(θ)≤1+ε
1-εif 1-ε>pt(θ)
1+εif pt(θ)>1+ε(8)
其中:ε是用于度量新策略与老策略之间偏差程度的超参数。
智能体学习到的部署策略的质量取决于中间状态所能表示的信息准确度[15]。缺乏中间状态会导致智能体难以精确预测选择动作所能得到的预期奖励,进而导致无法对策略网络有效更新。
1.3 内在激励
神经网络至PIM芯片的部署任务中,只有完成所有节点的部署后才可以计算部署结果的质量。在文献[11,12]的算法中,神经网络的逻辑图中间部署阶段没有奖励,只有在完成部署后根据部署结果给予奖励。这导致了面对大规模部署任务时训练容易陷入停滞,难以探索更优部署策略等问题,这一现象称为稀疏奖励问题[19]。
目前针对稀疏奖励问题已展开多种研究。逆强化学习通过大量专家决策数据在马尔可夫决策过程中逆向求解环境奖励函数,寻找多个奖励函数来描述专家决策行为。经验回放机制对经验池中的样本设置优先级,使样本被抽取的概率与优先级成正比,在一定程度上解决了稀疏奖励问题。内在激励的目的是构造虚拟奖励,用于和真实奖励函数共同学习。由于真实的奖励是稀疏的,使用虚拟奖励可以加快学习的进程。
在逻辑图部署中,任意节点的摆放均会产生不同的部署结果,存在大量中间状态,充分利用该中间状态构建内在激励是解决稀疏奖励问题的方法之一。本文利用在训练过程中构建的环境模型来评估状态的新颖程度,并通过随机固定神经网络和受训练的预测神经网络之间的差异[20]来计算新颖度,表示智能体对当前状态的熟悉程度,并以此给予奖励。
2 基于深度强化学习的部署策略
PPO算法在组合优化问题中具有稳定性强、效率高等优势。本文提出了一种基于改进PPO的PIM芯片部署算法。在部署过程中实时提取单轮部署的中间状态信息,依据该信息选取合适的部署结果,并比较部署过程中不同步骤的中间状态差异,构建内在激励将稀疏奖励转变为稠密奖励,探索更优部署策略。图5展示了该算法的全部流程,智能体通过多轮部署学习部署策略。获得不同的奖励后,智能体使用PPO算法优化网络参数,学习并找出最优策略。
2.1 环境与动作
DRL中状态的表示至关重要。合适的状态表示可以正确地表示当前的部署状态,使智能体的决策更合理。
在DRL的部署优化算法中,使用一个二维矩阵表示将要部署的PIM芯片的状态,其中未部署的计算核表示为零,已部署的计算核则用序列号表示。动作为选择一个位置进行部署。
在单轮部署开始前,对当前的环境进行初始化,该二维矩阵中的序列号全部置零。当智能体完成一个节点的部署时,置零的计算核更新为当前部署的序列号。逻辑图的所有节点部署完成后,根据部署结果计算该轮部署的结算奖励。随即初始化,开始下一轮的部署。执行完固定步长的部署轮次后,对智能体进行更新。
在先前工作中,使用全局部署来得到当前节点将要部署的坐标,即对于每一个节点都可以选择多核系统上的任意位置进行部署但过大的动作空间也会导致训练困难。相邻层的节点具有明显的相关性,将其部署至临近的节点可以降低延迟。因此限制动作空间可以在不降低部署结果质量的前提下降低训练难度。局部部署策略主张限制部署范围。首先对逻辑图的节点进行拓扑排序,并根据排序部署。部署当前节点时,寻找到与此节点通信量最大的已部署节点的位置,将部署范围限制在该位置的一定范围内。
2.2 中间状态表示
智能体依靠当前状态作出决策。合适的状态表示是获得高质量决策的关键。如图6所示,状态信息提取算法分别使用图神经网络和卷积神经网络提取逻辑图和当前部署情况两个方面的信息。
图神经网络通过逻辑图的连接关系聚合并输出节点上的信息,通过全连接层将这些信息编码。每当一个节点完成部署后,更新其节点特征中的坐标信息。
中间状态的表示中,部署的结果由二维矩阵表示,卷积神经网络可以从输入图像中提取重要特征,因此使用卷积神经网络对当前部署状态的信息进行提取。二维矩阵中的数字表示为节点的序列号,并且都进行归一化处理。在经过多层卷积层后通过全连接层转换为状态向量。
在训练过程中这两个作为信息提取器的网络不进行更新。智能体的网络权重根据PPO算法进行更新。
2.3 混合奖励
在相关工作中[11,12],仅根据部署结果反馈奖励,且没有足够的中间状态表示,导致采样效率低,部署结果优化有限。本文基于2.2节的中间状态表示方法,提出混合奖励方法,包括结果奖励和虚拟奖励。该算法使智能体在熟悉的部署和新部署结果的边界中进行更集中的探索,学习到更丰富的部署策略,并利用结果奖励保留高质量的策略。
r=rresult+rvirtual(9)
结果奖励rresult在所有节点完成部署后对部署结果进行评估,并以此反馈奖励。
rresult=-α×(C-Cbaseline)(10)
其中:α是比例系数。由于使用模拟器精确评估消耗时间过长,导致算法求解速度慢,所以使用简化的公式来近似估计当前的部署结果。因计算过程的功耗和延迟与数据传输路径即通信开销高度相关[12],因此使用通信开销C计算奖励,根据以下公式计算得到:
C=∑vi,vjcomni,j×Pi,j(11)
通过模拟退火算法得到部署结果的通信开销Cbaseline作为基准,增加训练的稳定性[11]。在部署任务中,通信开销越低意味着部署结果越好,获得的奖励越高。所以通过比例系数α将奖励转换为通信开销的负值,并限制在一定范围以内,防止在训练过程中出现梯度消失的问题。
有别于先前工作中缺乏单轮训练过程中的奖励,本节提出在单轮部署中获取中间状态的虚拟奖励,将训练过程中只有单轮部署结束时才获得的稀疏奖励转换为每执行一个动作就可获得的稠密奖励。rvirtual计算方式为
rvirtual(st,at,st+1)=max[n(st+1)-β·n(st),0](12)
其中:β是一个超参数,根据给定的PIM芯片和逻辑图来衡量内在激励的重要性。当智能体探索新的部署结果时给予其内在激励rvirtual,从而鼓励智能体在原先的部署结果上探索新的部署。n(st)表示当前状态的新颖度,通过两个神经网络计算的差异得到。
n(st)=‖φ(st)-φ′ω(st)‖2(13)
其中:φ表示固定网络;φ′ω表示预测网络;ω是预测网络的参数。内在激励分为两个网络:随机固定神经网络和受训练的预测神经网络。随机固定网络不参与参数更新,将观察到的状态进行编码。完成新颖度的计算后通过梯度下降法(stochastic gradient descent,SGD) 对预测网络进行更新,使预测网络的期望均方误差(mean-square error,MSE)最小,表示对当前的狀态进一步熟悉。
在训练的初始阶段每一次部署的差异度均较大,因此都获得较高的内在激励。随着训练的进行,预测网络对部署状态的预测逐渐逼近固定网络的结果。智能体若尝试不同的部署,则获得内在激励随之变化。结果奖励的提升在总体奖励中占比更大,因此智能体更倾向于在优秀部署结果的基础上探索新的部署。在训练后期,新颖度逐渐降低为零,智能体学习到了高质量的、稳定的部署策略,因此内在激励算法得以收敛。
3 实验结果
3.1 实验设置
在硬件上,使用Tianjic芯片[21]的架构模拟,每一个计算核内有9个行列为128的RRAM阵列,并且计算核上设计了包括池化,累加器等功能电路。如表1所示,对不同规模的神经网络进行测试比较,分别为小规模神经网络Alexnet、VGG11、DenseNet121、ResNet34以及大规模神经网络VGG16、DenseNet201和ResNet101。其中ResNet101拥有超过四千万个参数,DenseNet201拥有192层卷积网络层数。表1中的计算核表示部署部署神经网络所需的计算核数量,规模表示神经网络模型部署在不同规模的存内计算芯片内。8×8和16×16分别表示芯片上共有64个和256个计算核,后者是目前所设计的大规模存内计算芯片。本文仅考虑神经网络中的卷积层。其中Alexnet和VGG11运行在包含8×8计算核的PIM芯片上,DenseNet121、VGG16、ResNet34、DenseNet201和ResNet101运行在包含16×16计算核的PIM芯片上。ResNet101所需参数量较多,将该网络划分为两个部分,部署至两个存内计算芯片中。将结果与模拟退火算法(simulated annealing,SA)[10],DDPG算法[11]和PPO算法[12]相比较。
在本文的方法中,使用图神经网络将逻辑图转换为大小为64的特征向量,使用卷积神经网络将当前状态转换为大小为192的特征向量。部署算法中Actor和Critic网络均使用3层全连接层,每一层的参数量为256。根据经验,部署算法中的超参数设置如下:学习率设置为0.000 2,其中PPO_epoch为10,PPO_clip为0.2,折扣因子为0.98。内在激励的缩放因子为0.75,内在奖励稀疏为2。结算的奖励裁剪到[-100,100]。文献[11,12]中DRL算法的超参数根据其论文中设置。
所有的部署结果使用基于C++的周期精确的NoC模拟器进行评估。这个模拟器模拟在设备的每个循环中运行的所有数据包的状态。为不失通用性,在所有情况中使用二维网格拓扑和维序路由。在NoC中的平均延迟表示为
Latency=1|N|∑|N|i=11Ni∑|Ni|j=1Latencyi,j(14)
其中:N表示计算核的数量;Ni表示经过i次预热后单个计算核收到的数据包数;Latencyi,j表示数据包j的延迟。
平均功耗表示为
Power=C×E|h|t(15)
其中:E|h|为单跳距离下发送数据包的能量;t为所需要的时间。
帶宽需求为计算过程中,同一时刻在同一信道上传输的最大数据包数量。
模拟退火算法在较大的搜索空间中近似全局最优。随机初始化部署位置,通过交换两个节点的位置实现进化,并使用与DRL相同的代价函数。针对每一个神经网络,为模拟退火算法设置不同的超参数,包括不同的温度上限、不同的衰减率、不同的迭代次数。选取延迟最小的结果作为基准。
3.2 结果分析
最终结果如表2所示。综合表1的结果,基于DRL的部署优化算法在所有数据集中均有提升。在功耗开销方面提升较大,分别达到了67.49%,20.06%,33.39%。在延迟方面,分别提升了30.60%,17.02%,11.55%,并且在最大带宽需求上也有不同程度的提升。
AlexNet和VGG11所需的计算核数量较少,属于小规模的神经网络。对此类神经网络的部署,本文方法与PPO相比功耗开销的降低更多,在延迟方面两个方法提升效果相似。对于大规模的神经网络如VGG16,Resnet34,这两个网络被部署至16×16个计算核的多核系统中,随着规模的增大其探索空间呈指数级上升。同时,大规模神经网络的节点数量众多,缺乏中间结果表示使得PPO算法难以探索更优部署结果。混合奖励方法通过逐步部署并精确表示中间状态的方式,使得延迟和功耗开销有较为明显的提升。更大参数量的ResNet101的探索空间更大,使用混合奖励可以获得更好的效果,在延迟和功耗上相比ResNet34的优化程度更大。但是对于扇入扇出数较多的DenseNet121和DenseNet201而言,延迟和功耗开销的提升都较小。因为采取局部部署的方法,对扇入扇出数较多的节点选择空间有限,所以对此类网络优化有限。
如图7所示,比较了ResNet34是否使用内在激励的训练情况。纵坐标reward表示训练得到的奖励,横坐标step表示训练的步长。使用了内在激励使得DRL算法的收敛速度和部署的结果得到提升。在初始阶段,由于智能体对环境较为陌生,所以表现和没有好奇心奖励基本相同。当智能体熟悉边界后,虚拟奖励驱动智能体探索未知空间,增加了寻找优化部署方法的概率。
4 结束语
本文针对PIM的神经网络部署问题,提出了一种基于DRL的优化算法。该算法使用图神经网络提取逻辑图的信息,使用卷积神经网络提取中间状态的信息,并且使用内在激励鼓励探索新的部署决策。相比较SA和DRL算法获得了更优的延迟和功耗开销,但在一些复杂任务如节点扇出数过多时存在难以训练的问题,这是后续的工作方向。
参考文献:
[1]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al.Delving deep into rectifiers:surpassing human-level performance on ImageNet classification[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2015:1026-1034.
[2]Zhang Ying,Pezeshki M,Brakel P,et al.Towards end-to-end speech recognition with deep convolutional neural networks[EB/OL].(2017-01-10).https://arxiv.org/abs/1701.02720.
[3]Kiran B R,Sobh I,Talpaert V,et al.Deep reinforcement learning for autonomous driving:a survey[J].IEEE Trans on Intelligent Transportation Systems,2022,23(6):4909-4926.
[4]Ankit A,Hajj I E,Chalamalasetti F,et al.PUMA:a programmable ultra-efficient memristor-based accelerator for machine learning inference[C]//Proc of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems.New York:ACM Press,2019:715-731.
[5]Yao Peng,Wu Huaqiang,Gao Bin,et al.Fully hardware-implemented memristor convolutional neural network[J].Nature,2020,577 (7792):641-646.
[6]Akopyan F,Sawada J,Cassidy A,et al.TrueNorth:design and tool flow of a 65 mW 1 million neuron programmable neurosynaptic chip[J].IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems,2015,34 (10):1537-1557.
[7]Davies M,Srinivasa N,Lin Tsunghan,et al.Loihi:a neuromorphic manycore processor with on-chip learning[J].IEEE Micro,2018,38 (1):82-99.
[8]Wan Weier,Kubendran R,Schaefer C,et al.A compute-in-memory chip based on resistive random-access memory[J].Nature,2022,608 (7923):504-512.
[9]Ostler C,Chatha N.An ILP formulation for system-level application mapping on network processor architectures[C]//Proc of Design,Automation & Test in Europe Conference & Exhibition.Piscataway,NJ:IEEE Press,2007:1-6.
[10]Joseph J M,Baloglu M S,Pan Yue,et al.NEWROMAP:mapping CNNs to NoC-interconnected self-contained data-flow accelerators for edge-AI[C]//Proc of the 15th IEEE/ACM International Symposium on Networks-on-Chip.New York:ACM Press,2021:15-20.
[11]Wu Nan,Deng Lei,Li Guoqi,et al.Core placement optimization for multi-chip many-core neural network systems with reinforcement learning[J].ACM Trans on Design Automation of Electronic Systems,2020,26 (2):1-27.
[12]Myung W,Lee D,Song Chenhang,et al.Policy gradient-based core placement optimization for multichip many-core systems[J/OL].IEEE Trans on Neural Networks and Learning Systems.(2021-10-13).https://doi.org/ 10.1109/TNNLS.2021.3117878.
[13]Mirhoseini A,Goldie A,Yazgan M,et al.A graph placement methodology for fast chip design[J].Nature,2021,594 (7862):207-212.
[14]Cheng Ruoyu,Yan Junchi.On joint learning for solving placement and routing in chip design[C]//Advances in Neural Information Processing Systems.[S.l.]:Curran Associates Inc.,2021:16508-16519.
[15]Schulman J,Wolski F,Dhariwal P,et al.Proximal policy optimization algorithms[EB/OL].(2017-08-28).https://arxiv.org/abs/1707.06347.
[16]Jiang Nan,Becker D U,Michelogiannakis G,et al.A detailed and flexible cycle-accurate Network-on-Chip simulator[C]//Proc of IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) .Piscataway,NJ:IEEE Press,2013:86-96.
[17]Catania V,Mineo A,Monteleone S,et al.Noxim:An open,extensible and cycle-accurate network on chip simulator[C]//Proc of the 26th IEEE International Conference on Application-specific Systems,Architectures and Processors.Piscataway,NJ:IEEE Press,2015:162-163.
[18]Li Zhaoying,Wu Dan,Wijerathne D,et al.LISA:graph neural network based portable mapping on spatial accelerators[C]//Proc of IEEE International Symposium on High-Performance Computer Architecture .Piscataway,NJ:IEEE Press,2022:444-459.
[19]楊惟轶,白辰甲,蔡超,等 深度强化学习中稀疏奖励问题研究综述[J].计算机科学,2020,47 (3):182-191.(Yang Huaiyi,Bai Chenjia,Cai Chao,et al.A review of research on the sparse reward problem in deep reinforcement learning[J].Computer Science,2020,47 (3):182-191.)
[20]Zhang Tianjun,Xu Huazhe,Wang Xiaolong,et al.NovelD:a simple yet effective exploration criterion[C]//Proc of the 35th Conference on Neural Information Processing Systems.2021:1-14.
[21]Pei Jing,Deng Lei,Song Sen,et al.Towards artificial general intelligence with hybrid Tianjic chip architecture[J].Nature,2019,572 (7767):106-111.
收稿日期:2023-02-07;
修回日期:2023-04-04
基金项目:国家自然科学基金资助项目(62131010,U22A2013);浙江省创新群体资助项目(LDT23F4021F04);宁波高新区重大技术创新体资助项目(2022BCX050001)
作者简介:胡益笛(1996-),男,浙江台州人,硕士研究生,主要研究方向为电子设计自动化;夏银水(1963-),男(通信作者),浙江宁波人,教授,博导,博士,主要研究方向为低功耗电路设计及其自动化(xiayinshui@nbu.edu.cn).
