
几种机器学习算法的锂电池SOC估计研究
2023-10-13 09:18张志冬李云伍李杨柳梁新成
重庆理工大学学报(自然科学) 2023年9期
张志冬,李云伍,李杨柳,梁新成
(1.西南大学 工程技术学院, 重庆 400715;2.西南大学 计算机信息与科学学院软件学院, 重庆 400715)
0 引言
电动汽车是目前使用清洁能源的主要交通工具。锂电池具备性能稳定、寿命长、能量密度高的良好特性,因此成为了电动汽车动力电池的首选[1]。荷电状态(state of charge,SOC)作为电动汽车电池管理系统(battery management system,BMS)的核心参数,对其精确估计可以避免电动汽车动力电池过充或亏电,从而延长使用寿命。因此,SOC的准确估计对电动汽车技术的进一步发展至关重要[2]。
刘湘东等[3]采用安时积分法和开路电压法融合估计锂电池SOC,该方法可以解决电池长时间静置的问题,但难以消除累计误差;雷肖等[4]提出一种径向基函数神经网络方法估计SOC,可以解决SOC不能非线性估计的问题,但所用模型结构过多且复杂;刘鹏等[5]提出遗忘递推最小二乘法与自适应无迹卡尔曼滤波估计锂电池SOC,但不能保证估计的准确性。不同于上述方法,基于数据驱动的锂电池SOC估算方法只需要通过机器学习或深度学习就能得到SOC与放电数据的关系,具有较强的非线性处理能力,能有效避免出现累计误差,提高估计精度。目前,基于数据驱动的锂电池SOC估计方法大多是单个分类器,其存在泛化能力较弱、分类精度低等缺点。骆秀江等[6]采用支持向量机方法(support vector machine,SVM)对锂电池的SOC进行估计,但建模过程中参数选取难度高,不利于实际应用。王爽等[7]将遗传算法(genetic algorithms,GA)和BP神经网络(back propagation,BP)结合作为融合算法估计锂电池的SOC,但该方法训练模型建立难度大。Wang等[8]建立AFSA-BP神经网络模型,实现了锂电池SOC的准确估计,但训练时间长、网络收敛速度慢。
为了提高锂电池SOC估计的实时性和精确度,基于一种新型的LightGBM算法,并与随机森林、支持向量机、线性回归、神经网络等4种常用的算法在估计SOC的速度及精度方面进行比较[9]。该算法具有2个特性:① 拥有传统算法的计算速度快、泛化能力好等优点;② 防止过拟合并支持数据采样和列抽样。此外,LightGBM算法可以降低时间复杂度并且提高估计精度。笔者首先介绍了LightGBM算法,然后应用随机森林、支持向量机、线性回归、神经网络4种算法对4个数据集(数据集a、b、c、d)分别进行训练,最后通过对比4种训练结果得出LightGBM算法在估计锂电池SOC方面的优越性。
传统的SOC估计方法包括安时积分法、开路电压法、电导法、卡尔曼滤波法等[10]。安时积分法通过实时监测电池工作状态的充放电量从而准确得到电池的剩余电量,但是需要获得精确的SOC初值[11]。开路电压法根据电池的开路电压估计SOC值,将放电过后的电池静置后,端电压与容量存在相对固定的函数关系,但是电池静置时间较长不能满足估计的实效性[12]。电导法通过对锂电池电导或电阻的大量测试数据分析出锂电池电导与SOC的关系,从而实现对锂电池SOC的估计。卡尔曼滤波法在等效电路模型的基础上在线估计锂电池SOC,可实时获得被估计状态量的最优估计值,但是估计的准确性依赖于电路模型建立的准确性[13]。相比于传统估计方法,新型估计方法有着估计精度高、估计方法简单的优点。
新型估计方法主要有支持向量回归法、多元线性回归法、多种深度学习网络模型融合算法、滑模观测器方法(sliding mode observer,SMO)等多种方法,可以有效解决传统SOC估计方法的不足[14]。
神经网络法通过对大量的样本数据进行多次训练,只需依靠输入和输出间的映射关系即可建立估计模型,无需考虑系统内部的实际反应情况。Li等[15]建立了一种基于外部输入全并行非线性自回归神经网络的锂电池SOC估计方法,将实时测得的电池电流、电压和温度作为网络的输入,而SOC作为输出。姚芳等[16]使用了3层BP神经网络模型对电池SOC进行了数据识别。支持向量机是一种针对二分类任务设计的数据驱动模型,但是估计SOC数据量过大时模型精度会下降,速度会降低。融合算法可实现对现有算法的优化,提高数据的综合能力和非线性拟合能力。大数据及数据挖掘技术的发展使SOC数据驱动估计方法逐渐成为主流估计方法。
各种SOC估计方法优缺点如表1所示。
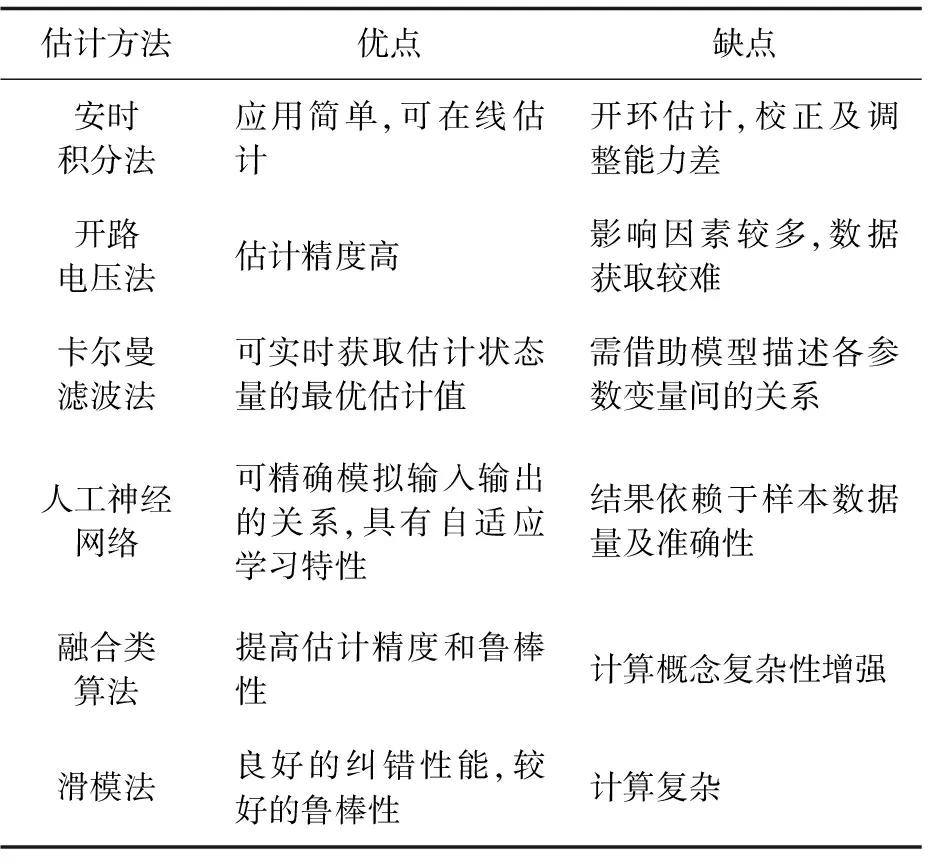
表1 各种SOC估计方法优缺点对比
1 LightGBM算法
LightGBM是一种快速、分布式和高性能的梯度提升框架,基于决策树算法实现。相较于其他方法,它具有更高的训练效率、更低的内存占用和更高的准确率,同时支持高效的并行化学习。
在LightGBM算法提出之前,XGBoost算法是主要的GBDT工具。XGBoost算法相比LightGBM算法的缺点是计算量大、内存占用大、易产生过拟合,由于迭代方式为Level-wise,故采用排序的方式会消耗大量空间。LightGBM算法框架的提出高效地解决了GBDT在处理较大数据集时的不足,有利于GBDT更好更快地应用于工业实践。此外,XGBoost算法需要保存数据的特征值和对应的排序结果,故需要消耗数据集2倍的内存,效率比较低。XGBoost的目标函数如下:

(1)
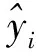
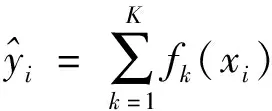
(2)
式(2)表示有k个样本,在XGBoost里每棵树是逐次往里加的,以下各式为XGBoost集成的核心:
(3)
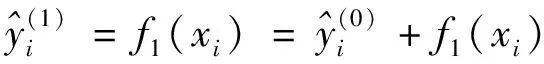
(4)
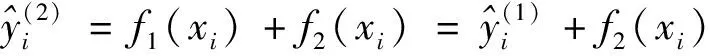
(5)

(6)
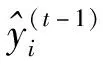
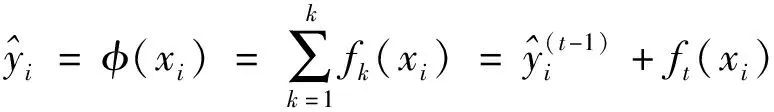
(7)

LightGBM算法支持3种并行方式:特征并行、数据并行和基于投票的数据并行。特征并行的主要思想是在不同的机器和不同的特征集上分别寻找最优的分割点,然后在机器之间同步最优的分割点。数据并行的主要思想是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上寻找最优分割点。而基于投票的数据并行能够解决数据并行在直方图合并时通信代价大的缺点。LightGBM估计速度是XGBoost的1/10,而内存占用率只为XGBoost的1/6。LightGBM与随机森林、支持向量机、线性回归、神经网络(3层)的时间复杂度见表2所示。n为训练实例数,k为决策树数量,d为数据维数。
LightGBM优化了对类别特征的支持,可以直接输入类别特征而不需要额外展开,并在决策树算法上增加了类别特征的决策规则。LightGBM采用histogram算法通信代价小,通过使用集合通信算法实现并行计算的线性加速。
2 实验结果及分析
2.1 数据集处理
在应用LightGBM训练模型之前,需要对初始数据集进行预处理以达到更好的估计效果。采用Panasonic-18650PF-Data公开锂电池数据集[17]。该数据集已实现全气候动力电池的全寿命高效管理,电池实验状态为室温状态25 ℃。首先,构建输入数据集对应的标签和特征,该数据集的特征包含电压、电流、电池温度、放电时间,标签为电池SOC,数据集预处理方式见图1。

图1 数据集预处理框图
将该数据集划分为4个子数据集分别进行4次训练,以减小训练误差从而获得更好的SOC估计效果。处理数据集时删除一些噪声影响以及其他影响的数据点,然后选择精确点。将数据集95%划分为训练集,5%为测试集,通过训练集确定拟合参数的曲线,测试集测试已经训练好的模型的误差,并对机器学习模型的泛化误差进行评估。最后,将数据可视化,以显示参数之间的任何明显趋势,调优统计模型以确定所需的变量,绘制特征之间的关系图。图2为子数据集SOC的变化曲线。
2.2 LightGBM模型训练结果
选择最优参数的方法为交叉验证法,即通过多次循环来寻找最优估计数,首先将各子数据集划分为100个大小相等的样本子数据集,依次遍历每个子数据集,每次把当前子数据集作为验证集,其余所有样本作为训练集进行模型训练和评估,该方法可以充分利用数据集。图3分别为4个子数据集带有LightGBM循环的最优估计数,4个子数据集最优估计数分别为298、298、298、299。
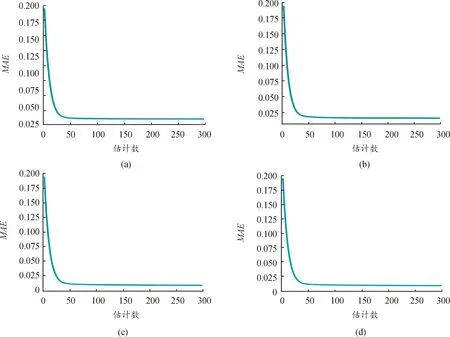
图3 带有LightGBM循环的最优估计数
选择平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)、R2-score作为预测模型的评价准则。

(8)
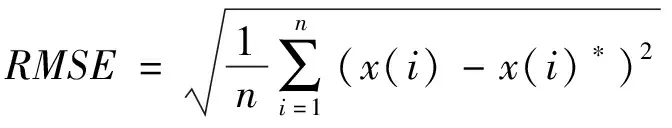
(9)
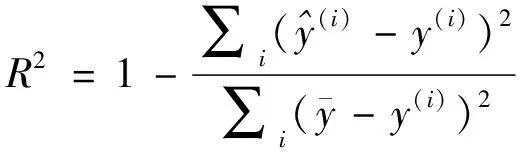
(10)
经过多次循环之后得到数据集a的MAE为0.011 13,MSE为0.013 9;数据集b的MAE为0.007 9,MSE为0.000 1;数据集c的MAE为0.007 5,MSE为0.000 1;数据集d的MAE为0.011 3,MSE为0.000 2。
在对LightGBM算法进行调参时,学习率(learning_rate)、弱学习器最大迭代次数(n_estimators)、最大树深(math_depth)、单叶最小权重(min_child_weight)、叶子节点数(num_leaves)为主要参数。上述参数的取值标准:取较小的学习率可以提高模型性能;弱学习器最大迭代次数越大,模型准确性越好;最大树深是LightGBM算法的核心参数,根据数据集特征取值在100~1 000;单叶最小权重即单个叶子上的最小样本数,取值过小停止分裂,过大则会造成过拟合;叶子节点数对模型的性能具有很大的影响,默认值为31。
设置迭代循环估计次数为200次,为了加速分析减少过多迭代,将学习率设置为0.1,该数据集特征数量多,在寻找分割点时容易产生过拟合,可以在group边界上找到分割点,将树中的最小数据设置为较大值来限制树的深度,完成最优调参后训练数据集得到的SOC估计结果,如图4所示。
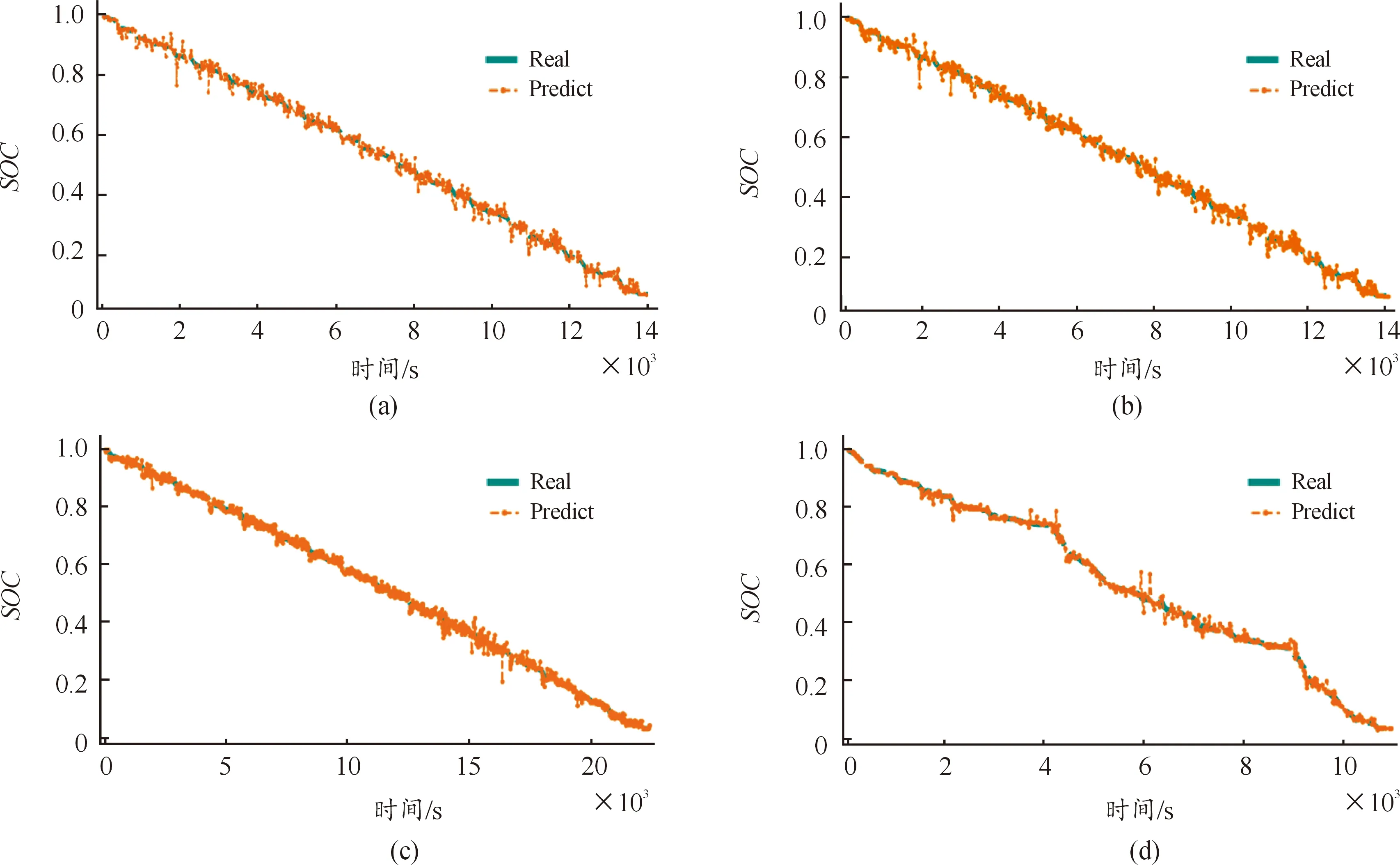
图4 LightGBM与实际对比
由图4可以得出,估计值与真实值的拟合结果比较准确,调至最优参数的训练模型在估计时间和精度方面都得到提升,4个子数据集的训练效果都比较好,说明LightGBM模型估计锂电池SOC的效果较好,满足实际需求。
2.3 对比算法分析
目前,估计锂电池SOC的新型方法主要有随机森林(random forest)、支持向量机(support vector machine)、线性回归(linear regression)、神经网络(neural network)4种模型。将对比4种模型与LightGBM模型的训练结果,通过分析对比训练结果的准确率与速率来体现其模型估计SOC的优势。
1) 随机森林模型
随机森林模型调参,将估计循环次数调至与LightGBM一致的200次,森林中树的深度设置为10。随机森林模型的重要参数主要有随机发生器的种子数、最大特征数、决策树的最大深度、强学习器的最大迭代次数等参数。
2) 支持向量机模型
SVM允许决策边界很复杂,在低维数据和高维数据下的表现都比较好,缺点是运行时间和内存使用方面消耗比较大。基于SVM的估计模型输入变量为电压,输出变量为SOC。计算得出SVM模型的MAE为0.033 23,MSE为0.045 1。
3) 线性回归模型
应用线性回归模型对数据集进行训练,本次研究中特征值为电压,目标值为SOC。设置计算时使用的核数为默认值1,减小loss函数值,增大学习比率值。线性回归模型应用简单,训练速度快,但是估计结果准确率较低。
4) 神经网络模型
神经网络调参将所有的参数值权重设置为0,均值为0,方差较小的正态分布初始化,选用的神经网络模型迭代第100次需要的时间为23.961 4 s,loss函数为0.001 1,MAE为0.026 8,第500次需要的时间为119.097 5 s,loss函数值为0.001 0,MAE为0.025 7。迭代500次训练模型准确度与调整至最优参数,正式训练整个数据集迭代至3 000次,训练时间为717.630 2 s,loss函数值为0.000 6,MAE值为0.018 5,MSE为0.000 6。
2.4 最终结果对比
将LightGBM模型与经过参数调优的随机森林、支持向量机、线性回归、神经网络4种主流的机器学习算法模型进行对比,再将数据集分别代入各机器学习模型进行训练,并且对模型进行参数调优以达到各自最优的估计结果,训练结果如图5所示。
图5为LightGBM与随机森林模型估计结果对比。从曲线中可以得出,LightGBM模型的估计结果比随机森林模型估计结果更加接近SOC真实值,模型估计精度和拟合度都比较好。调参完成后的模型的估计速度和精度得到提升,相比其他4种对比模型,具有快速、高精度的优点。证明LightGBM模型估计锂电池SOC的变化结果比较准确,可以作为电池工作过程中SOC变化的参考,监测电池工作状态,延长电池使用寿命。
图6为LightGBM模型训练数据集估计SOC的误差。从图中可以看出,模型训练的整个过程中误差值比较小,且模型估计误差的波动也小。考虑外界因素如电池放电过程中温度、运行工况等的影响,整个电池放电过程中误差值最大达到0.10,整体误差不超过0.06,误差值集中在0.02以内,其中数据集c的误差最小。训练结果表明,LightGBM模型估计SOC效果较好,且可满足实际的需求。

图6 误差分析
表3为LightGBM模型与4种对比算法的SOC估计结果对比。表中各算法训练的数据集均为同一数据集,各个模型均经过参数调优至各自最佳的训练效果。由表3中数据可知,LightGBM的估计速率以及精确度都优于其他几种算法,估计结果误差小且实验数据精确度高,在MAE、MSE、R2-score均取得较好的结果,LightGBM算法在保证高效率的同时防止了训练产生过拟合,显著提高了锂电池SOC估计的速率与精确度。
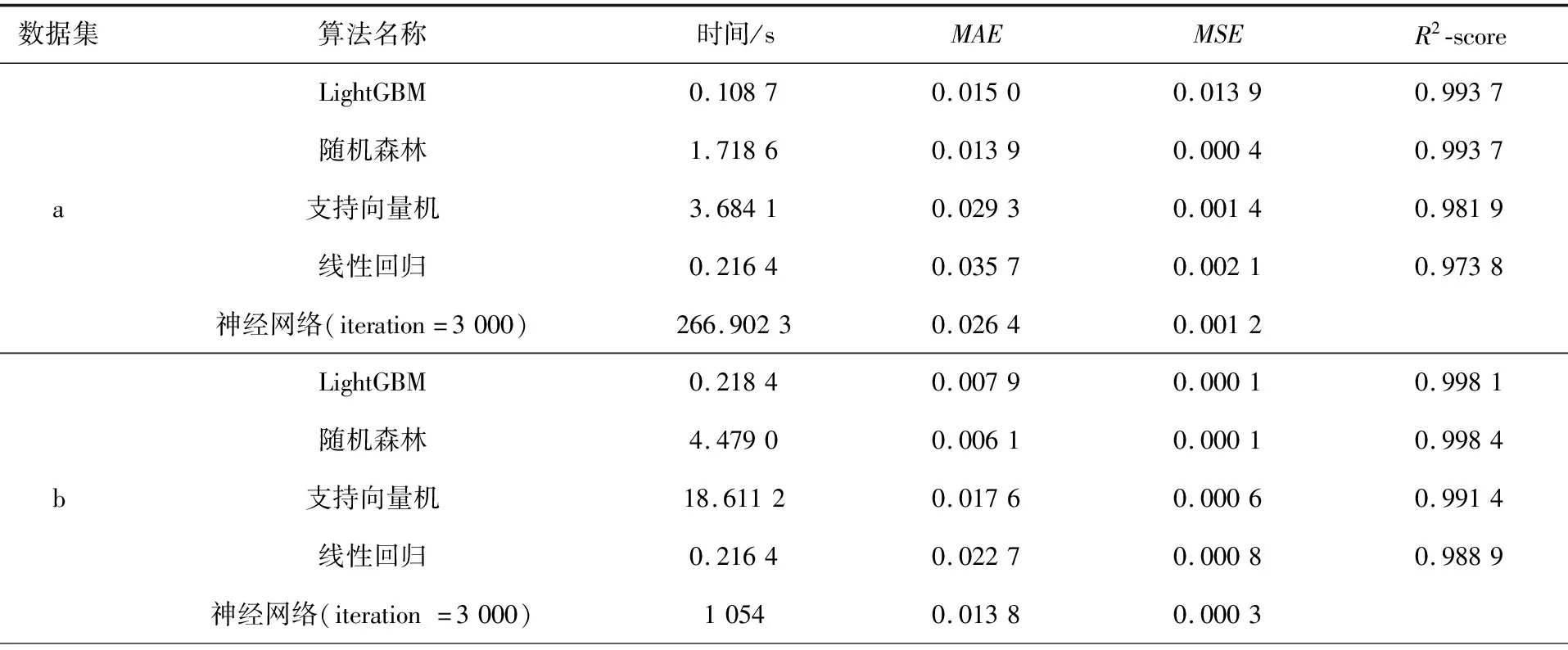
表3 各算法训练结果对比
3 结论
1) 提出新型的机器学习方法估计锂电池SOC,得到比传统方法更好的估计效果。
2) 采用Panasonic-18650PF-Data锂电池实验数据集验证了所提出的LightGBM算法的创新性,减小了数据训练误差,并评估机器学习模型的泛化误差,将实验数据进行可视化处理,可显示参数之间的相互关系。
3) 应用LightGBM算法及支持向量机等对比算法训练Panasonic-18650PF-Data锂电池数据集,得出估计时间为对比算法随机森林的1/22,支持向量机的1/88,神经网络的1/1 330。改进的LightGBM算法具有更快的估计速度和更高的估计精度。
猜你喜欢
今日农业(2022年14期)2022-09-15
军事文摘(2022年14期)2022-08-26
科学大众(2021年21期)2022-01-18
小学科学(学生版)(2021年12期)2021-12-31
电子制作(2019年19期)2019-11-23
重型机械(2016年1期)2016-03-01
电源技术(2016年2期)2016-02-27
大连工业大学学报(2015年4期)2015-12-11
电源技术(2015年7期)2015-08-22
海军航空大学学报(2015年4期)2015-02-27
