
强化学习在自动发电控制中的研究进展与展望
2023-10-12 03:10:50解立辉
三峡大学学报(自然科学版) 2023年5期
解立辉 席 磊
(三峡大学 电气与新能源学院, 湖北 宜昌 443002)
电力系统的频率控制可分为一次、二次和三次调频.一次调频是指利用系统固有的负荷频率特性及发电机组的调速器,来阻止系统频率偏离标准的调节方式,即通过发电机组的调速器跟踪本地频率信号完成一个“小”闭环控制;二次调频是在各控制区域采用集中的计算机控制,以保持发电功率与负荷功率的平衡,即通过调度端AGC 实时控制器跟踪全网频率和联络线功率偏差后,将调节指令下发给电厂PLC 完成一个“大”闭环控制,机组功率分配常采用简单的比例法,机组容易偏离经济运行点;三次调频是对发电机组的有功功率进行经济分配,即对电网的有功发电功率进行超短期经济调度.
AGC是电力系统的基础问题,是实现频率无差调节的关键,一般以经典的IEEE 标准两区域负荷频率控制(load frequency control,LFC)模型为基础的频域线性模型进行研究,并不考虑电网拓扑,经过多年发展已较为成熟.各国AGC 基本是以参数固定的PI(proportional integral)控制或线性控制为核心,二、三次调频分开设计,性能虽能满足一般工程需要,但仍存在3个难题:(1)在调度端AGC控制器无法有效解决机组响应的大时滞,长期存在火电AGC 机组调节次数高和频繁反调,导致机组调节能耗高、寿命下降;(2)在调度端AGC 总调节功率指令无法实现“秒级”动态优化分配,导致不同类型机组动态互补调节特性无法充分利用,在系统内快速调节资源耗尽时,CPS(control performance standard)性能急剧变坏;(3)随着间歇性新能源的大规模接入,对传统集中式确定性能源形成“挤出”效应,电网运行呈现更强的分散性、多样性和随机性特征,如何有效利用新能源与柔性负荷参与电网调节是一个巨大挑战.
对不确定性进行量化是机器学习的基础,传统认为机器学习模型是一种函数,将它与某些数据进行拟合从而进行预测,就像借助数据拟合曲线一样.广义的机器学习就是机器对世界进行建模,这个模型对不确定性进行量化,不确定性的积分就是概率.故机器是建立在概率基础上的,它对世界的理解本身就包含不确定性.随着它“看”到的数据越来越多,不确定性通常会降低.换句话说,机器从数据中学到了一些东西.这一思想在“贝叶斯定理”这一优雅的数学理论中得以体现.故认为贝叶斯及“通过概率量化不确定性”,正是机器学习的基石.
1 强化学习(RL)在AGC中的应用
对于融入大量具有随机性新能源的电力系统,及大时延、无法准确建模且动态优化决策实时性强的庞大系统,相较于经典优化方法,机器学习是一个有效的手段.机器学习是一个算法范畴,其本质[1]是找到一个目标函数f,使其成为输入变量X到输出变量Y之间的最佳映射:Y=f(X).机器学习主要分4类:有监督式学习,无监督学习,半监督式学习和强化学习(reinforcement learning,RL).RL 在电力调度控制决策中颇具潜力.
AGC是动态的多级决策问题,可视为非马氏环境下的决策过程,以最终实现全系统内发电出力和负荷功率相匹配.李红梅等[2]将RL 引入到水火混杂AGC系统中,针对水轮机非线性特点,将环境知识转化成RL 的先验知识以加快AGC 的调整速度.在AGC的随机最优控制中,同样可应用RL,如与模型无关且具有先验知识的Q 学习[3-4]、基于平均报酬模型的全过程R(λ)学习[5-6]和在策略SARSA 算法[7].有学者将多agent RL[8]和深度强化学习[9]用于互联大电网的AGC,以有效提高由于新能源并网所带来的随机扰动以至电网越来越差的控制性能.此外,RL还可与多目标优化策略相结合用于解决AGC 问题[10].Q 学习与深度学习相结合可形成深度Q 学习用于强鲁棒性AGC控制器的设计[11].有关学者还将R(λ)学习用于孤岛微网的AGC.总之,在AGC 中引入RL,可将CPS指标转化为强化信号反馈给AGC系统,能够有效实现功率调节指令的在线优化.
目前AGC 在新型电力系统中发展,逐渐从单agent RL 过渡到多agent RL,学者们提出并逐步丰富了智能发电控制(smart generation control,SGC)概念及算法体系,形成分布式SGC 策略.SGC 与AGC的最大区别在于,无论是AGC总调节功率动态优化控制(即通过AGC控制器来获取总调节功率,下文亦称“控制”),还是AGC 总调节功率指令动态优化分配(即机组功率动态优化分配,下文亦称“分配”),都将用智能方法取代原有的PI控制及固定比例分配法(按各机组可调容量裕度的比例进行分配,简称PROP),即从整体到分支实现真正意义的智能化.以近期学者们的研究为主线来讲述AGC 发展历程(如图1所示).即从单agent到多agent,从集中式AGC(centralized-automatic generation control,CAGC)、分布式AGC(distributed-automatic generation control,D-AGC)、分层分布式SGC(hierarchical and distributed-SGC,HD-SGC)分析其发展历程.
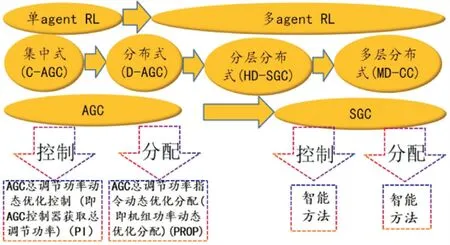
图1 AGC发展历程
2 集中式AGC(C-AGC)策略
目前AGC系统(如图2所示)是集中式的,其决策系统位于省调EMS、电厂PLC或微网EMS内,由“控制”及“分配”两个关键部分构成.
图2 C-AGC系统结构
2.1 基于单agent RL“控制”与PROP方法“分配”的C-AGC策略
对C-AGC 系统的总调节功率控制,即AGC 控制器,目前国内采用南瑞EMS自带的离线优化参数PI控制器.由于火电机组响应时间长,PI控制器对此类时变大时滞系统处理效果差,导致机组频繁调节、甚至反调,即前述难题(1).
学者们采用了例如Q、Q(λ)、Sarsa(λ)、R(λ)、ERL等单agent RL作为C-AGC策略的“控制”(“分配”为PROP法),对C-AGC控制器进行了持续性改进,显著提高了CPS性能.周斌等[12]采用Q 学习对AGC进行求解,证明其能够提高AGC 系统的鲁棒性.余涛等[13-14]提出了具有“松弛”策略的Q(λ)及SARSA(λ)方法,有效解决了火电机组大时滞问题,改善了AGC控制策略不当带来的频繁调节和反调问题.余涛等[15]提出了基于平均报酬的R(λ)来求解AGC,克服了RL需另外搭建模型来进行预学习的严重缺陷,与Q(λ)相比收敛速度更快,CPS指标更优.YIN L F等[16]将“人类情感”函数与Q 学习结合形成了情感RL,通过模拟人类在处理复杂情况下的非线性情感函数,对Q 学习“学习率、奖励函数和动作选择”进行了修正,显著改进了CPS指标.在广东电网上的仿真结果见表1.
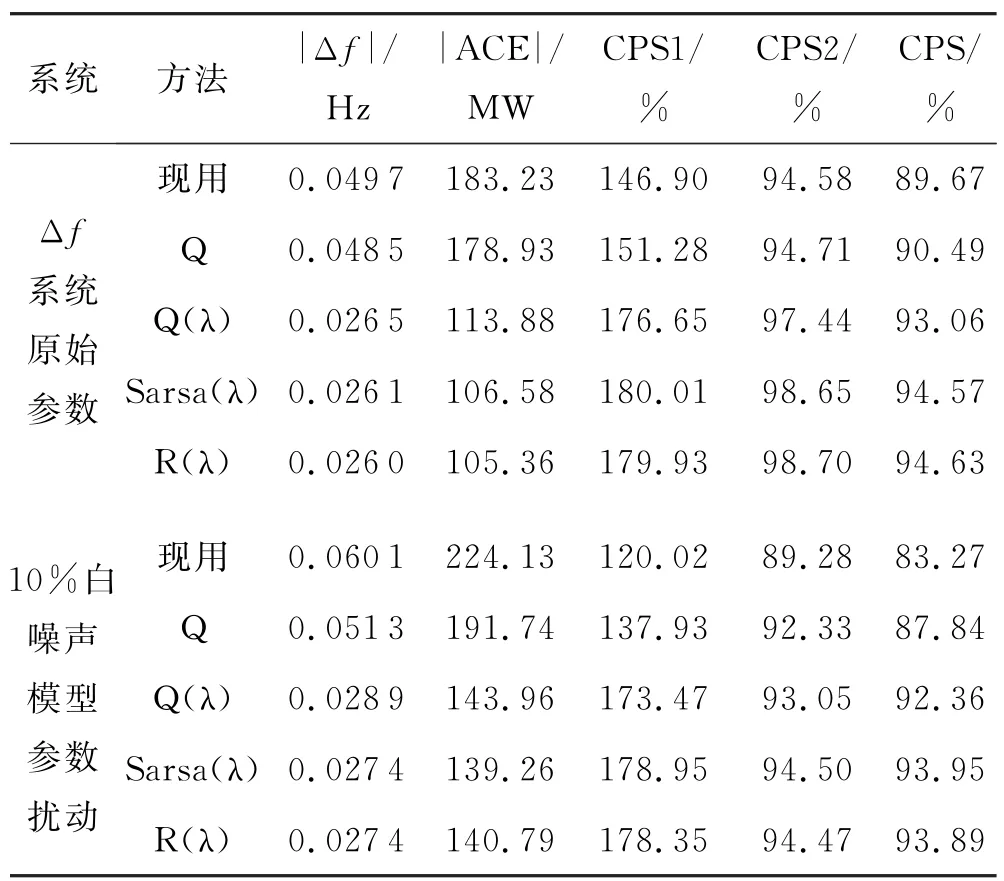
表1 集中式AGC总功率动态优化控制性能指标对照表
上述方法基本覆盖了Q 框架体系所衍生的经典单agent RL,Q、Q(λ)和R(λ)属于离策略,而Sarsa(λ)属于在策略.从对同一个研究对象(广东电网)的CPS效果来看,所有RL 应用于广东中调的控制器,发电机组的调节和反调次数明显下降,此效果在随机性变强后尤其明显;在RL诸多算法中,R(λ)和Sarsa(λ)差别已很小,但采用在策略改进后,有效避免了搜索大幅扰动状态,收敛速度进一步提升.
2.2 基于PI算法“控制”与单agent RL“分配”的CAGC策略
目前关于机组功率分配的文献相对较少,省调采用的南瑞AGC系统,其“控制”为PI算法,“分配”为PROP法.由于AGC调节周期4~8 s,“控制”采用基于模型的经典方法根本无法满足其实时优化的收敛性.学者们尝试用如遗传算法等作为“控制”来解决此问题,但在实时性要求下,只能完成一些PROP模式下的等比例优化,无法实现复杂环境下的动态优化.实际中这种无动态优化的分配方式易优先把调节功率指令分配给动态调节性能优异的水电,而对于大量调节缓慢的火电却未加有效利用.故对于火电占优的电网,易出现在快速调节机组裕度耗尽后性能急剧变坏的情况,电网公司由于CPS不合格被罚电量每年高达数亿度,这一直是各省调心中的一个“痛”.
RL的特点是与环境互动和在线学习,实现长期运行环境中获得的总收益最大.故学者们采用Q、Q(λ)和分层Q 等单agent RL 作为“分配”部分的方法(“控制”仍为PI算法),余涛等[17]提出基于Q 学习的“分配”方法,提高了系统的适应性和CPS性能.余涛等[18]提出基于Q(λ)学习的“分配”方法,能有效解决火电大时滞环节带来的延时回报问题,收敛时间较Q学习缩短50%以上.余涛等[19]提出基于分层Q(λ)学习的“分配”方法,通过引入一个裕度协调因子来协调AGC和电厂PLC层的两层动态分配器.上述文献表明此C-AGC策略提高了系统实时优化的收敛性、鲁棒性和CPS性能.
从表2得出集中决策式AGC总功率动态分配器通过各类算法调出各机组实际发电曲线,RL 在负荷急剧变化时依赖水电,而在系统负荷平稳阶段会智能地缓慢“释放”一部分功率让火电来承担,继而为下一次负荷快速急剧变化做好准备.
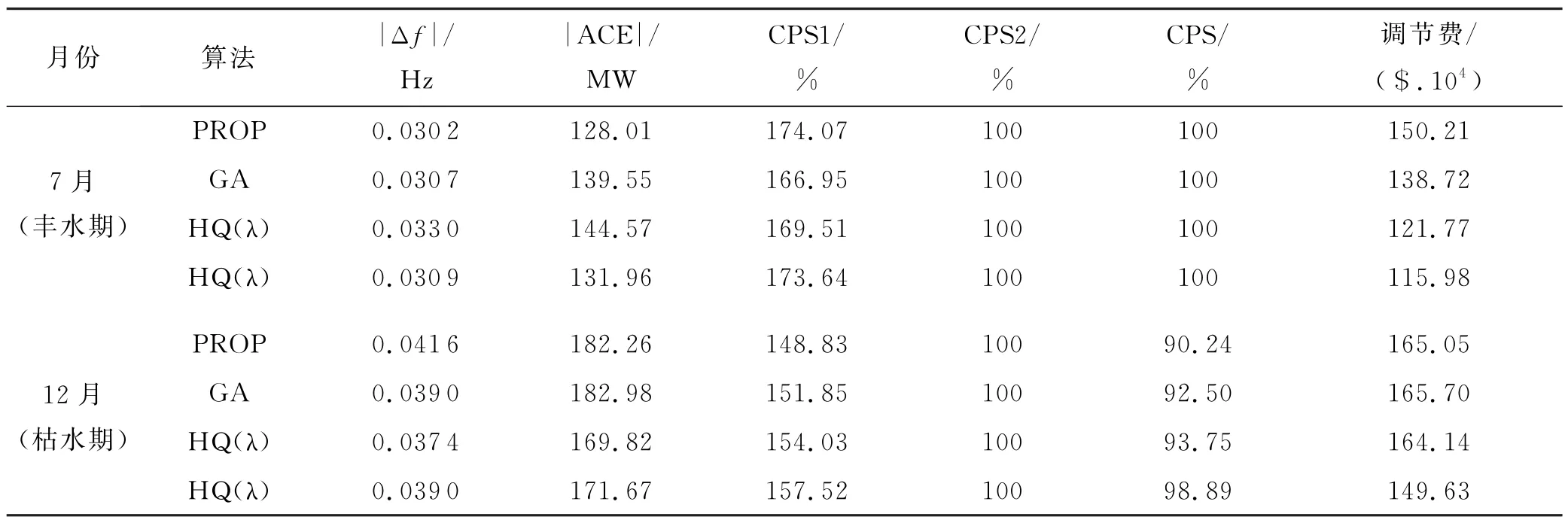
表2 集中决策式AGC总功率动态分配器性能指标对照表
3 分布式AGC(D-AGC)控制策略
C-AGC系统模式下无论“控制”亦或“分配”均采用单agent RL.当AGC 机组规模增加时,会暴露出控制效果下降和收敛时间延长等缺陷,同时加重AGC执行超短期时间尺度控制与调度任务的负担.且仅依靠单agent独立学习无法实现各区域的信息共享和交互协作,会降低AGC 系统的综合控制性能.同时,近年来新能源及负荷大量接入,电力系统EMS逐步走向分散自治的模式.故为解决难题(3),学者们开始从C-AGC 系统到D-AGC 系统转变.DAGC系统框架如图3所示.
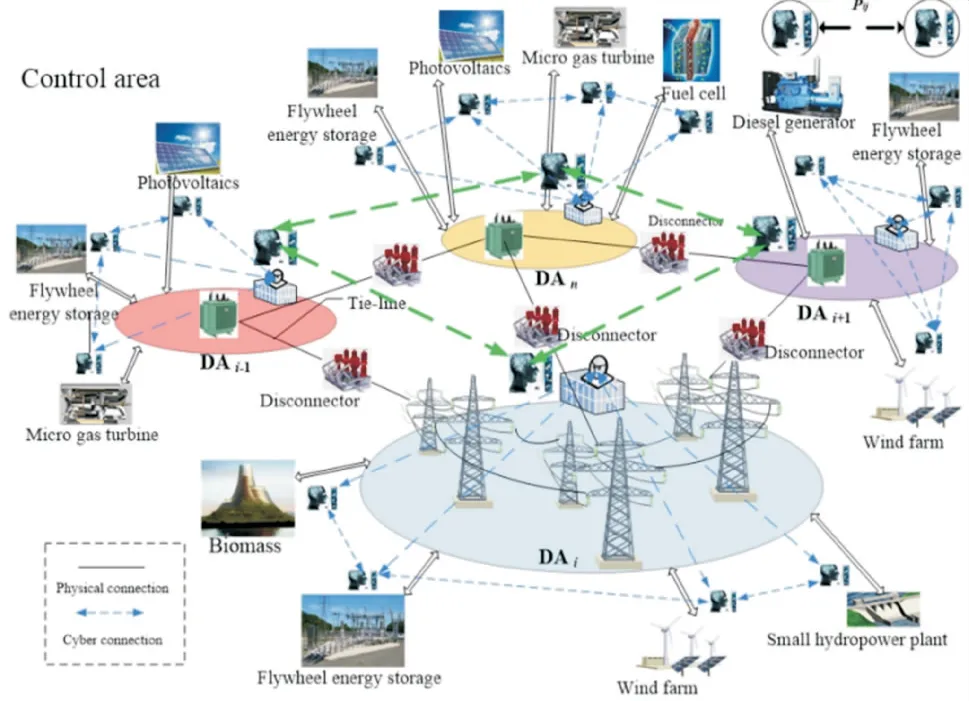
图3 D-AGC系统框架
对比图2、3可见,D-AGC系统不需做C-AGC系统调度端“集中协调”工作,系统被分割为多个分布式区域,各区域都有一个异构属性的“大脑”(智能控制器),通过多agent博弈来获取各分布式区域的调节功率,而“分配”采用PROP法;亦或各区域“大脑”均为PI控制,而“分配”采用动态优化分配的智能方法.C-AGC系统在结构形式上为集中式控制,只有一个“大脑”,无法实现分布式多agent 协同.这也是C-AGC系统与D-AGC系统的最大区别.
将分布在输电网和配电网层级的集中式水、火、气、核等确定型能源、分布式风、光、海洋等随机型能源、可控负荷、静止/移动储能等资源充分利用起来,完成稳态并列运行时的最优发电控制及故障解列式的孤岛独立频率支撑的双重任务.宋成铭[20]提出了一种三级架构多智能体系统实现对AGC 和AVC 的协调控制,提高有功、无功控制的自主应变能力和分布式控制能力.强化学习应用于AGC 方面,学者们分别从“控制”和“分配”角度提出了适用于D-AGC系统的基于多agent RL的D-AGC策略.
3.1 基于多agent RL“控制”与PROP方法“分配”的D-AGC控制策略
RL通过试错所有可能动作找出最优解,由于参数设置简单、普适性强,其在众多方法里具有很强的竞争力.图3所述为多个单agent构成的群体智能控制器,根据agent特征,分为同构、异构.对于异构多agent系统,学者们将博弈论与Q学习结合,形成了基于多个单agentRL 的随机对策算法体系,如图4所示.
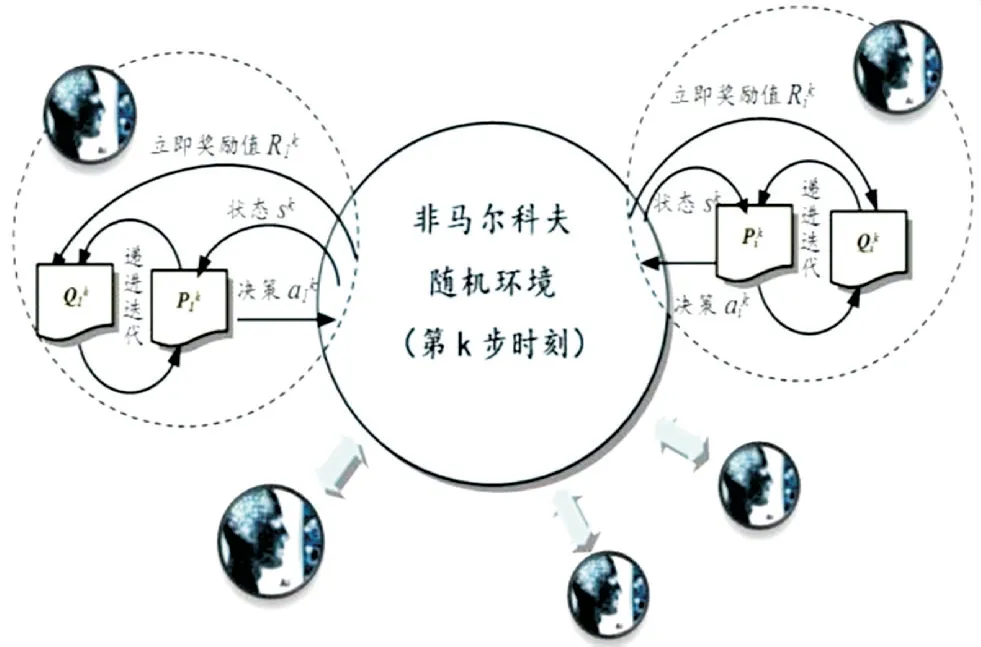
图4 群体Q 学习的随机对策论算法体系
这种基于多个单agent RL 的“伪”多agent RL理论应用遇到了新的挑战.所谓“伪”:首先为多个单agent RL 定义最优的共有学习目标较困难;其次各agent都需要记录其他agent的动作(稳定性差),才能与其他agent交互以获得联合动作.如此差的稳定性导致多个单agent RL 收敛速度慢,这也推动了多agent RL的快速发展.
AGC可描述为非马尔可夫环境下的异构多agent复杂随机动态博弈问题,基于RL 的多agent系统随机博弈(MAS-SG)理论可解决此问题.Greenwald A.等[21]提出了基于多agent RL的CEQ 方法,根据预设的均衡选择函数在线获得奖励值,从而收敛到最优均衡.当机组数不多时,上述RL 都能适应强随机环境.随着区域及机组数大量增多时,状态和动作维度过高,使得agent很难遍历所有情况,导致算法无法学到合理的策略,存在维数灾问题.学者们发现,将深度神经网络作为近似函数[22-25]引入到RL 中是一种解决维数灾问题的有效方法.
随着“双碳”目标倒逼能源互联网加快发展,从频率控制的角度,万物互联将给电网带来更强的随机扰动及更多的维数灾.席磊等[26]融合DDQN-AD 与比例经验回放法,提出PRDDQN-AD[27],对采样的数据单元进行重要性评估,在避免获取的稀缺经验数据可能被快速遗忘的同时,提高学习效率.
目前所查文献关于微网或微网群协同的AGC算法相对较少.綦晓[28]针对多区域互联微网系统,结合线性自抗扰算法和基于原对偶梯度算法的多agent系统,提出了分布式优化算法.曹倩[29]在微网分层控制结构的框架下,提出多agent自适应算法,使频率恢复额定值.衣楠[30]在Q 学习基础上提出了面向混合交互环境的基于MAS 和元胞自动机的微网分布式协调自趋优控制策略.李楠芳[31]提出基于多agent微电网控制框架的多agent协作学习算法.无论是大电网亦或微网的协同方法,传统RL 均有一个缺陷,即在随机环境中易出现动作值在探索过程中的“高估”现象,导致决策质量低.且上述算法均属于离策略,收敛速度慢且精度低.
Kristopher[32]通过引入参数σ统一离策略与在策略的优缺点,提出了基于“将各种看似不同的算法思想联合统一以产生更好的算法”思想的Q(σ)算法,能够解决上述离策略固有的“收敛”问题.席磊等[33]在Q(σ)基础上融入资格迹与双重学习,提出了一种基于多步统一RL的多agent协同DQ(σ,λ)算法.解决RL的时间信度分配问题,且“后向估计”机理提供了一个逼近最优值函数Q*的渐进机制,可提高AGC机组功率调节快速性.
在超大规模新能源接入模式下,D-AGC 策略的“控制”部分采用性能优异的多agent协同算法,这种无动态优化“分配”的AGC性能仍有提升空间.
3.2 基于PI算法“控制”与多agent RL“分配”的DAGC控制策略
图3的D-AGC系统“分配”因涉及到大量同构多agent的动态计算,比图2 的C-AGC 系统要复杂得多,实时性的困难更加难以克服.故学者们提出了适应D-AGC系统的“分配”RL 方法,例如HCEQ[34]、协同一致性(collaborative consensus,CC)[35]、RCCA[36]、CTQ[37]等,对机组功率进行动态优化分配.
表3给出了近年学者们研究的具有动态优化的“分配”方面的算法总结,均以广东电网为例进行分析计算.从HQ(λ)、HCEQ、CCA、RCCA 到 最 新 的CTQ,实现了机组功率动态优化分配,并持续性提升了广东电网CPS性能,枯水期比现用PROP 模式调节总成本下降了30.3%,丰水期更是发挥了RL自主探索最优策略的能力,实现了频率偏差减少14.4%、调节总成本下降35.6%.
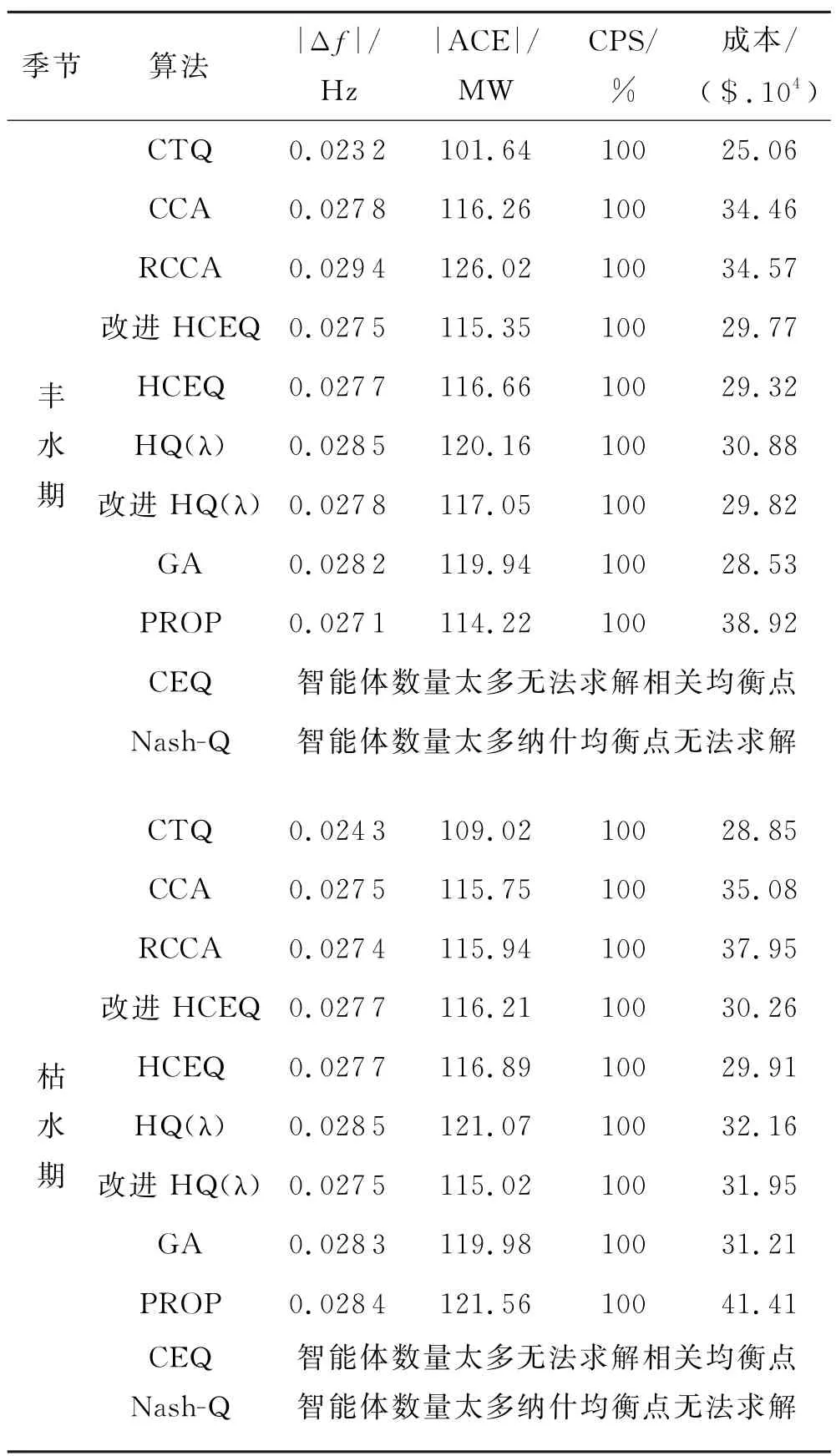
表3 分布式与集中式总功率指令动态优化分配指标对照表
4 分层分布式SGC(HD-SGC)策略
在超大规模新能源接入模式下,即便D-AGC 策略的“控制”部分采用性能优异的多agent协同算法,这种无动态优化“分配”的AGC 仍有很大提升空间.D-AGC策略非最优,D-AGC系统须在策略核心技术上实现重大突破,以适应大规模分布式多区域模式下的复杂环境.“控制”不仅具有自学习和自寻优能力的多agent协同,且“分配”应与此同时具有动态优化协同模式,“SGC”应运而生.
SGC策略与D-AGC策略所应用的AGC系统的结构相同,均为D-AGC 系统结构,二者最大区别在于“控制”及“分配”两部分,SGC 策略将用智能方法取代原有的PI控制及PROP法.
谈竹奎等[38]研究了需求侧响应中的柔性温控负荷控制问题,提出了将柔性温控负荷融入分布式分层控制策略,减轻响应事件中管理单元的通信负担.席磊等[39]提出一种基于爬升时间一致性的狼群捕猎HD-SGC策略,实现AGC总调节功率动态优化控制的同时,机组功率动态优化分配,与C-AGC 及D-AGC策略相比,具有更优的CPS性能.席磊等[40]为从配网角度求解SGC,提出了基于成本一致性的狼群捕猎HD-SGC 策略,相较其他方法具有更低的发电成本.进一步验证“领导-跟随”思想在求解SGC方面不仅大电网有效,配网同样有效.
随着新能源持续不断的大规模接入,其收敛速度逐渐下降.究其原因,无非是“控制”和“分配”的问题.上述策略的“分配”所采用的协同一致性(collaborative consensus,CC)只是简单的一阶一致性算法,其对优化模型依赖较强且易陷入局部最优解;可查文献,关于RL在AGC“控制”的应用,动作选取均为单步贪婪法[41],限制了动作策略最优选择,降低了算法收敛速度.在HD-SGC模式基础上,寻求性能更优的“控制”及“分配”策略或模式.
针对“分配”部分“一阶一致性算法”问题,张孝顺等[42]曾提出CC 迁移Q 学习算法,对一致性和迁移Q 学习进行高度融合.而Q 学习不依赖于数学模型,只需获取外部环境的实时状态和实时反馈,即可计算出agent当前的最优动作策略.
针对“控制”部分“单步贪婪”问题,Efroni Y等[43]提出了具有多步前瞻属性的RL算法,对选取多步动作的贪婪策略进行预见性的多次迭代更新.相关研究也已证明多步贪婪策略在鲁棒性及收敛性能上均优于单步贪婪策略[44-46].李嘉文[47]提出了一种基于追踪-探索策略的大规模多智能体深度确定性策略梯度算法,引入追踪-探索和集成学习策略等多种技巧,引导算法收敛防止陷入局部最优,智能体仅根据自身区域状态即可得出全局优化决策.
有学者在VWPC-HDC 基础上进行改进,在“控制”部分采用融入多步贪婪策略迭代的Q 学习,即多步贪婪Q 学习(MSGQ)来获取总调节功率指令;“分配”部分将HQL(λ)算法与CC 融合,提出了两层功率分配模式的HQCC 方法,对机组功率进行动态优化分配,进而形成一种将具有多步前瞻属性的贪婪控制算法与具有自学习能力的功率优化分配算法相融合的多层AGC策略[48](ML-AGC).
“控制”部分,MSGQ 通过对将来多步动作选取的贪婪策略进行预见性的多次迭代更新,从长期的角度以期累积折扣报酬总和最大,进而快速收敛至最优策略.“分配”部分通过构建两层功率分配模式,将具有交互协同和自学习特点的HQCC 作为多层“分配”算法,提高了CC 在复杂随机环境的适应性.群体Q学习的随机对策论算法体系如图5所示.
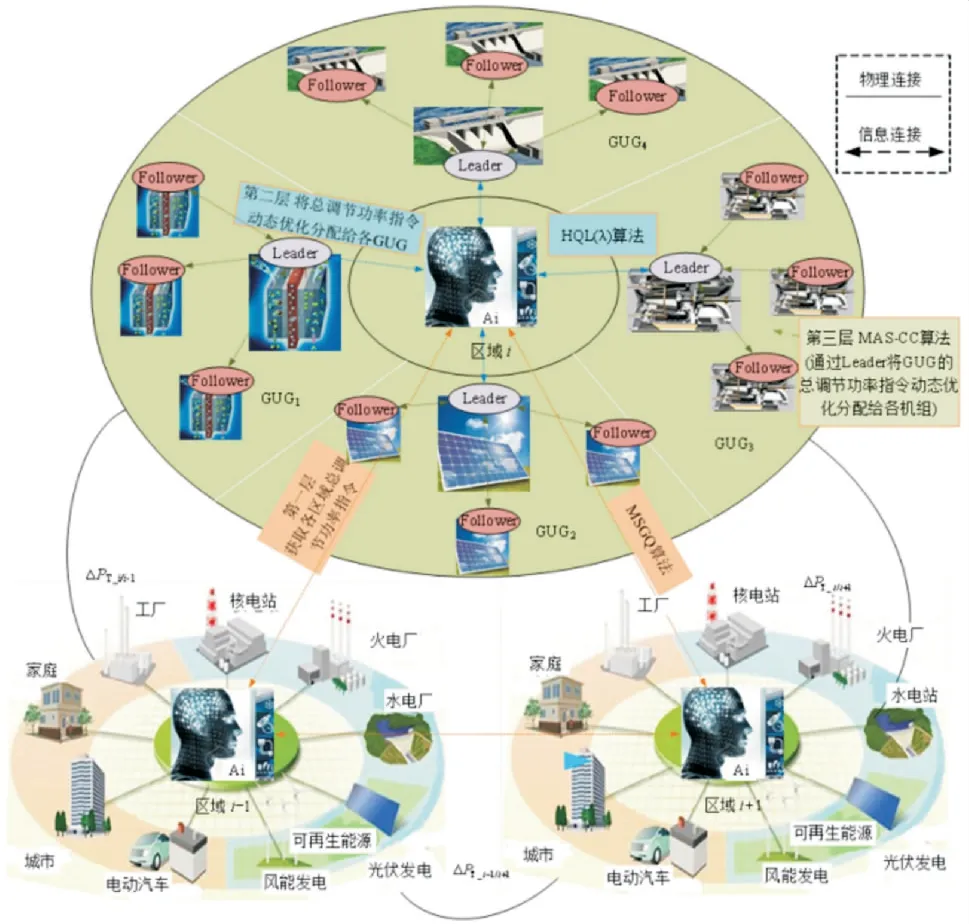
图5 群体Q 学习的随机对策论算法体系
5 结论与展望
AGC是建设大规模电力系统,实现自动化生产运行控制的一项最基本、最实用的功能.随着大规模新能源的接入,传统调节手段已不能满足新型电力系统的要求,强化学习在参数设置方面具有简单性及普适性,推动了强化学习在AGC 方面的快速发展.本文从强化学习在AGC 中的应用角度出发,分别为传统集中式AGC策略、分布式AGC 策略、分层分布式SGC策略,阐述了其研究历程.
集中式AGC策略主要对比了Q 框架体系所衍生的经典单agent RL 控制策略,解决火电机组响应时间长,传统的PI控制器对此类时变大时滞系统处理效果差,导致机组频繁调节、甚至反调的问题.随着新能源的规模化接入,集中式AGC 控制策略出现控制效果下降和收敛时间延长等问题,降低AGC 系统的综合控制性能.随着电力系统EMS逐步走向分散自治的模式,逐渐由集中式演变为分布式AGC策略.
分布式AGC策略分别研究了“控制”部分的博弈论与Q 学习结合随机对策算法体系,“分配”部分的HCEQ、协同一致性(collaborative consensus,CC)、RCCA、CTQ 等算法,实现机组功率进行动态优化分配,发挥RL 自主探索最优策略的能力,减小频率偏差与调节成本.
最后在超大规模新能源的接入背景下,D-AGC系统须在策略核心技术进行改进,“控制”及“分配”采用智能方法取代原有的PI控制及PROP法,主要介绍了狼群捕猎、迁移Q 学习算法、贪婪Q 学习(MSGQ)等智能算法,通过多智能体参与AGC 的系统运行,提高智能电网的运行稳定性.
随着电网规模升级、新能源比重的进一步增大,结合强化学习在AGC中的研究现状对以下方面进行讨论与展望,主要有4点:
1)强化学习的可解释性.目前强化学习等人工智能算法与自动发点控制的结合还在研究阶段,并没有在实际工程中进行大规模推广,一个重要原因是强化学习等人工智能算法的可解释性与强功能性并没有做到完全兼容.安全可靠往往是工程应用的先决条件,因此对于人工智能黑盒模型的研究探索,提高对于强化学习的物理可解释性,有助于提高强化学习在AGC的可靠性和安全性.
2)大规模区域电网模型.随着互联电网规模增大,需要考虑到拓扑结构以及状态空间等多方面的因素就会越多,从而导致建模难度呈几何倍数提高,后续研究需进一步拓展区域互联电网模型.
3)强化学习探索过程的估值范围.RL 均存在动作值在探索过程中的“高估”和“低估”问题,解决办法是在双Q 学习基础上引入加权思想,旨在单估计量法的高估和双估计量法的低估之间进行权重平衡,从而使多agent可以既不低估、也不高估、适度乐观地选择和探索动作值.同时融入时延更新策略来减少Q值更新的次数,提高了多agent的更新效率.
4)强化学习与深度学习的融合.传统强化学习算法存在决策精度低和收敛性能差的缺陷,在复杂的新型电力系统背景下,当状态空间和动作空间庞大复杂或应用场景连续时,强化学习的值函数由查表法实现,有一定失效的概率,进而令迭代收敛困难.需进一步探索深度与强化结合方法,从而将更智能的控制策略应用于AGC系统中.
猜你喜欢
青少年科技博览(中学版)(2022年11期)2023-01-07 06:21:30
汽车维修与保养(2021年8期)2021-02-16 00:28:20
铁道通信信号(2020年9期)2020-02-06 09:15:22
数学大王·趣味逻辑(2019年5期)2019-06-13 20:27:43
小学科学(学生版)(2019年5期)2019-05-21 01:00:18
经济技术协作信息(2018年30期)2018-11-22 06:20:24
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
工业设计(2016年4期)2016-05-04 04:00:15
雷达与对抗(2015年3期)2015-12-09 02:38:50
