
结合会员借阅行为的图书馆启发式借阅流程模型构建
2023-10-12 09:41:44刘晶
微型电脑应用 2023年9期
刘晶
(青岛大学附属医院,图书馆,山东,青岛 266003)
0 引言
近年来,因为会员阅读习惯逐渐转向有声书及电子书,公共图书馆的实体书借阅市场受到冲击。而公共图书馆属于非盈利机构,其对社会效益的需求远大于经济效益[1]。实体书本身的文化承载力、知识传播力应得到有效强化。所以,当前各地公共图书馆在全面展开纸质书电子化的技术革新的同时,也在积极构建实体书借阅推荐技术升级工作[2]。
该研究有两个前提:①所有实体书均经过了全面电子化处理,包括借阅卡信息的电子化和图书内容的电子化,图书全部检索信息和图书内容均可通过计算机通道完成检索;②公共图书馆有完善的会员体系,该会员支持会员在线借阅电子书、有声书的同时,也支持会员的实体书借阅过程,且全部借阅信息形成统一的会员数据画像系统[3]。
通过会员借阅习惯大数据画像,构建启发式借阅流程,向会员推荐适合其阅读习惯的图书,并完成借阅预约,是该研究的重点和创新点[4]。
1 全面电子化的公共图书馆大数据体系
公共图书馆的数据来源主要为以下3项:①图书电子化大数据:通过激光扫描、文字识别、机器翻译等模块化数据处理工具,将实体书的文字部分转化为多种语言的电子文本,部分图书馆可以利用机器朗读等模块化处理工具将实体书转化成的电子书转化为音频,构建有声书数据,这些数据可以实现电子书与实体书的线上线下双通道借阅;②图书借阅卡大数据:图书的书名、作者、出版社、出版时间、印次与印数、开本、页数、文献识别码、中图分类号、多语言版本摘要、关键词等形成传统图书借阅卡的基本内容,这些内容之间可以形成检索逻辑,实现批量检索,大数据环境下,图书电子化后,图书的词频特征码、文风标识码等图书内容挖掘信息也会被计入图书借阅卡大数据中,实现整体检索逻辑;③会员大数据:会员的姓名、年龄、性别、民族、工作单位、工作性质、线上借阅记录、实体书借阅记录等会形成会员大数据,该研究中重点利用图书电子化大数据和图书借阅大数据对会员大数据进行赋值,形成启发式借阅推荐流程模型。上述3项大数据的逻辑关系如图1所示。

图1 启发式借阅流程模型基本逻辑架构图
图1中,系统最终向借阅者提供的图书推荐分类,按照优先级,主要有以下4类:①与会员多次借阅历史图书相同关键词或相近书名、相近内容的图书,从受众心理学角度分析,这类图书属于纯理智条件下会员最容易接受的图书,但应排除会员希望更换借阅范畴尝试新型图书的心理趋向;②与会员多次借阅历史图书相同作者或作者存在关联的图书,作者存在关联指2个作者多次发表同类图书或2个作者存在亲缘、同事等关系,如读者多次借阅贾平凹的图书,系统可以尝试向其推荐贾浅浅的图书;③推荐与读者工作内容、工作性质相关的图书,因为当前实体书中比例最大的图书种类为职业经验、辅导类图书,如读者为公务员或企事业单位管理干部,则向其推荐管理学、心理学相关书籍,如读者为工程师、技术类工作或工人,则向其推荐技术辅导类图书;④推荐读者自选多个关键词相关的图书,包括书名、关键词、摘要、内容词频特征等借阅卡资料中包含该类关键词的图书[5-6]。
综合上述推荐需求,结合前文图1展示的逻辑架构,该大数据体系中核心工作流程节点为图书的电子化过程、词频提取过程、图书文风标识码提取过程。下文中将重点针对这三项工作展开论述[7-9]。
2 实体书电子化相关技术及工作流程
当前技术条件下,实体书电子化工作仅能满足将实体书的文本部分转化为电子文本并进行后续处理,包括机器翻译、词频提取、机器朗读等,但实体书电子化过程是实现该技术的重要支持因素。相比较单纯使用电子化图书借阅卡执行图书推荐操作,将实体书电子化后形成更完善的图书特征描述体系,更适合大数据云计算体系下的计算机辅助图书推荐算法需求。该过程基本逻辑架构如图2所示。

图2 实体书电子化工作流程逻辑架构图
图2中,激光扫描位图生成过程和识别过程采用汉王激光扫描系统,机器翻译使用百度翻译系统,机器朗读采用科大讯飞机器朗读系统,均可实现相关软件技术的全面国产化,而后续的词频分析功能、神经网络分析功能使用MATLAB大数据分析工具软件。该系统通过文风特征码和词频特征码实现对图书内容可供机器学习功能主动识别的数字化信息,文字识别后的原始语言版本和机器翻译后多语言版本,也用于直接检索过程[10]。
3 词频特征码与文风特征码的提取与应用过程
词频特征码与文风特征码均为64位比特型数据,其实际构成为2个每个4字节(32位)双精度浮点型变量的前后叠加,其初始生成算法架构如图3所示。
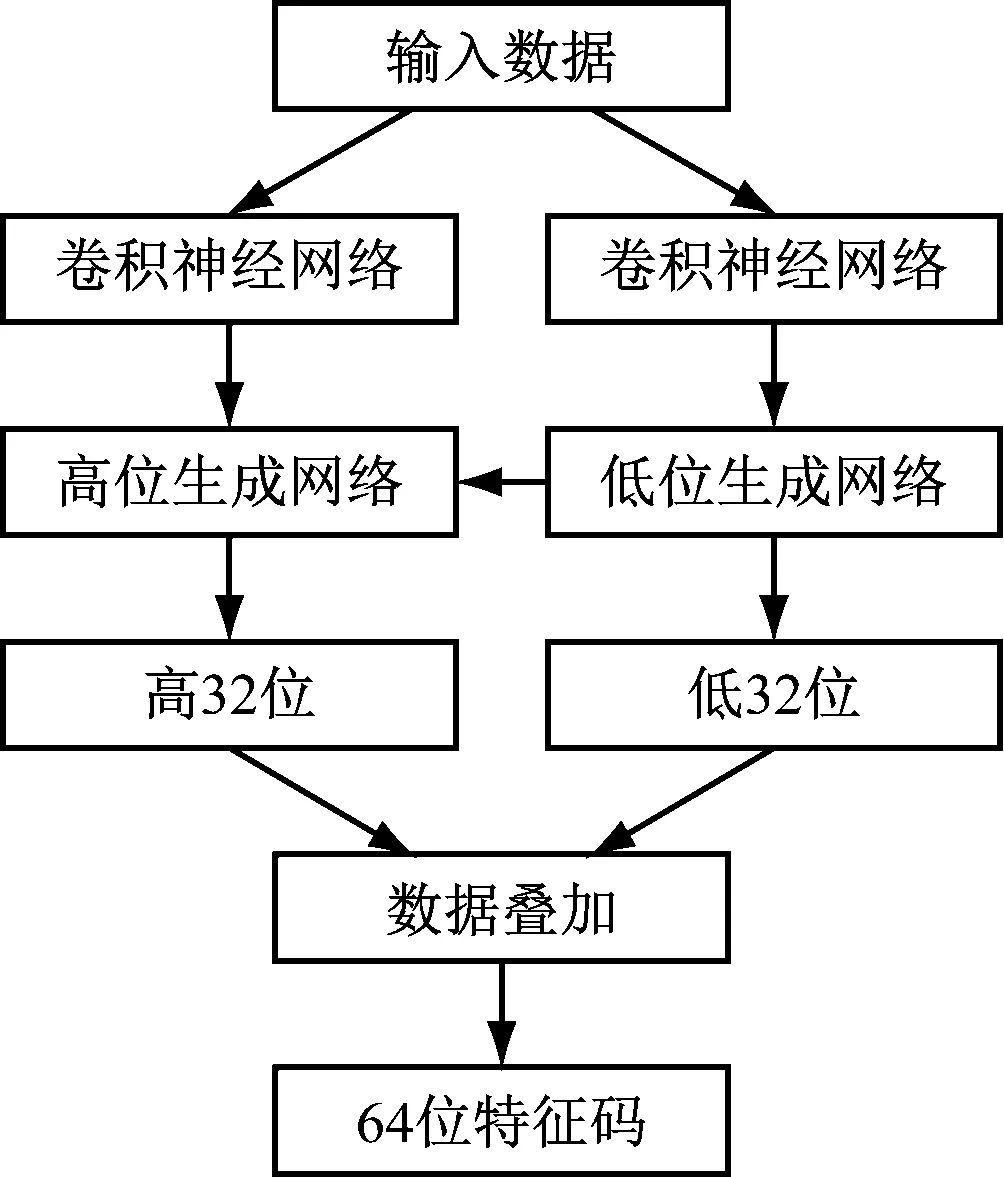
图3 特征码生成算法逻辑架构图
图3中,使用2个结构相同、输入数据相同的卷积神经网络模块分别生成2列独立数据,2个神经网络模块在不同训练需求下向不同方向收敛,进而进入2个卷积神经网络,分别生成特征码的高32位(由双精度浮点型变量强制转化而来)和低32位(由双精度浮点型变量强制转化而来)。其中,生成高32位特征码的神经网络在另一路神经网络输出端取1路补充数据。最终叠加为一个64位特征码。词频特征码与文风特征码的生成逻辑架构基本一致,仅其输入数据有所差异,生成词频特征码的输入数据为电子书经过词频提取算法后的词频序列数据,生成文风特征码的输入数据为电子书的原始文本数据[11-12]。
2个特征码被提取后,与会员阅读习惯特征码进行比较和合并,机器学习算法会判断会员阅读习惯特征码与图书的2个特征码的相似度,给出推荐序列,且会员执行借阅后,其会员特征码会根据图书的2个特征码进行刷新改写。该过程的逻辑架构如图4所示。
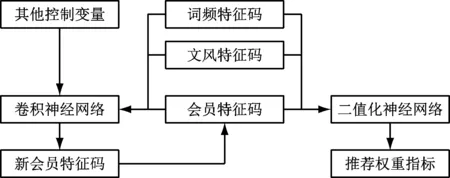
图4 特征码应用及转换机制逻辑架构图
图4中,使用二值化神经网络,给出一个[0,1]区间上的判断结果,经过神经网络数据训练,少部分图书会偏向1.000方向,作为推荐筛选结果书目,其余大部分图书偏向0.000方向,在推荐系统中被筛选屏蔽。会员借阅时,词频特征码与文风特征码联通会员特征码一起被输入到一个卷积神经网络模块中,生成合并后的新会员特征码,该特征码会对会员卡数字化信息进行重新赋值,用于后续判断过程。在新会员特征码的生成算法中,实体书借阅时间、电子书和有声书的浏览时间等会作为其他控制变量用于新会员特征码的生成计算过程。
上述特征码比较过程独立在前文所述的传统图书推荐流程之外,形成该研究中创新提出的基于机器学习的图书推荐算法,用于前文4种推荐需求的第1种推荐需求中。该算法将彻底杜绝传统算法的以下两点不足:①传统算法受制于图书借阅卡基本信息的不完备性,图书借阅卡中不论是关键词、书名还是摘要信息,均无法全面表达图书的类型信息,而使用该推荐算法后,当神经网络的节点数量和隐藏层规模等达到一定两边基数后,系统可以更充分判断会员的后续借阅行为;②传统算法与该创新算法相结合,将该算法作为优先推荐门类,在其他推荐板块仍然保留传统推荐算法的推荐结果,可以使两者形成有益互补[13]。
4 该算法对启发式借阅流程的实际支持效果
4.1 仿真条件下的效果测试
首先对该算法的神经网络进行数据训练,训练模式为在MATLAB环境下搭建镜像仿真平台,电子化实体图书原始资料和图书借阅卡原始资料拷贝自公共图书馆真实资料,训练数据来自会员借阅记录,即根据会员之前借阅记录和下次借阅记录,推测一个推荐范围,使推荐范围内图书出现在该推荐范围中。实际训练过程中,选择2019年及2020年全年的借阅记录,使用其中18个月数据作为原始训练数据,6个月数据作为验证数据。根据个人阅读习惯,选取前6位推荐和前20位推荐,最终验证结果如表1所示。

表1 仿真环境下的验证结果
表1中,t值与P值来自SPSS大数据分析软件中的双变量t校验分析,用于比较的差异性并提供差异性结果的信度。当t<10.000且P<0.01时,认为2组数据具有显著的统计学差异,且t值越小证明差异性越大,P值越小证明差异性结果信度越高。表1中,使用该系统后,前6位重点推荐书目中,会员借阅量从0.271册提升到0.893册,即借阅率从4.5%提升到14.9%,提升了3.3倍,前20位推荐书目中,会员借阅量从0.639册提升到1.580册,即借阅率从3.2%提升到7.9%,提升了2.5倍。该借阅率提升的量变引起了质变,即会员从前20位推荐书目中必然选择借阅1册,使推荐效率大幅度提升,会员对推荐书目的依从性大幅度增强。
4.2 启发式借阅系统试运行结果
在上述仿真分析的基础上,该研究成果论证阶段,推出了与传统借阅系统平行的借阅系统,会员可以在使用借阅推荐系统时选择使用新系统或者传统系统检索图书。2021年1月20日至今,使用新系统完成借阅检索的会员2761人,人均使用5.27次,即该系统先后服务借阅过程14 550人次,比较会员使用该系统后选择借阅图书的位置,得到表2。
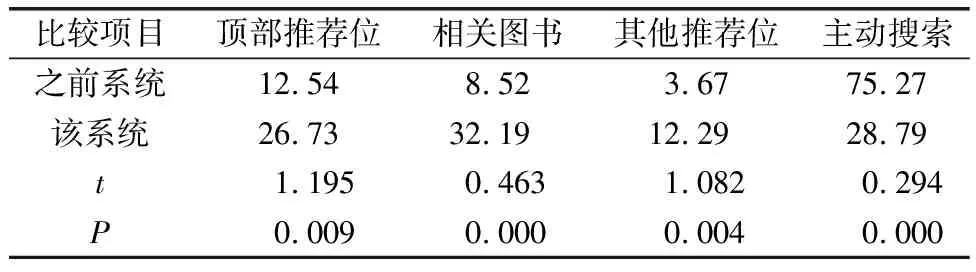
表2 会员借阅过程推荐位置使用率的比较结果
表2中,推荐位的相关算法有直接差异,具体表现在该系统使用的推荐算法结合了前文所述的机器学习推荐算法,之前系统的推荐算法是根据关键词检索的传统推荐算法。使用该系统后,推荐位给出的书目,会员接受度和认可度更高,具体表现在之前系统中75.27%的借阅行为需要通过会员主动搜索才可以确定借阅书目,而使用该系统后,会员主动搜索的借阅行为占比下降到了28.79%,可以推算出,推荐成功率从24.73%提高到71.21%,提升2.9倍。表2中,双变量t校验结果,t<10.000,P<0.01,具有显著的统计学差异。
在验证过程中,为了评价会员对系统推荐效果的主观评价,要求使用过该系统的会员做出主观满意度评价,满分10分,最低0分,参加该主观评价的会员量为851人,占全部使用过该系统会员2761人的30.8%,其评价结果如表3所示。

表3 会员主观评价结果汇总表
表3中,使用该系统后,会员对该系统的主观评价明显高于对之前系统的评价,平均分从7.52提升到8.93,提升幅度为18.75%。该数据经过双变量t校验,t<10.000,P<0.01,具有显著的统计学差异。
5 总结
该研究核心创新点在于引入基于卷积神经网络、二值化神经网络等机器学习算法,让系统的推荐书目更符合会员的借阅预期书目,实现启发式借阅推荐模式。经过仿真实验和试运行,会员对推荐位置书目的借阅量显著增加。因为该研究使用了最初级的神经网络架构,所以神经网络设计过程未展开论述,后续研究中,将从软硬件两方面全面升级神经网络,实现更深度地数据挖掘机器学习过程,使启发式借阅模式的算法效率进一步提升。
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
电脑爱好者(2021年3期)2021-02-06 10:19:45
中国外汇(2019年13期)2019-10-10 03:37:48
山西财税(2019年3期)2019-02-19 10:16:10
出版人(2017年8期)2017-08-16 10:57:07
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
汽车科技(2015年1期)2015-02-28 12:14:46
图书馆论坛(2014年8期)2014-03-11 18:47:59
城市道桥与防洪(2013年8期)2013-03-11 15:18:02
