
甘肃省地表要素遥感解译样本库建设与应用
2023-10-10 14:35张宝安高小龙金仔燕马兰花
测绘通报 2023年9期
张宝安,高小龙,金仔燕,马兰花
(甘肃省地图院,甘肃 兰州 730000)
目前,各省卫星中心均可获取到大量时相新、覆盖范围广和更新频次高的国产卫星影像,包括资源三号、高分一号、高分二号和高分七号等,仅甘肃省每年覆盖省域的国产卫星影像就多达6000多景,如何对海量遥感影像进行快速精确识别迫在眉睫。现有自动解译方法较人工目视解译已有了一定进步,但受限于精度和效率,依然无法工程化应用,如全国国土三调90%以上还是依靠人工目视解译。为了进一步满足自然资源自动化、智能化管理需求,有必要在深度学习框架下对山水林田湖草沙等自然资源要素进行遥感智能解译。而成功训练一个解译精度高且泛化能力强的深度神经网络,需要建立样例尺寸多样、样例类别丰富、类别差异明确、样例数据多、类间数量平衡的样本库,以及一个集成算法模型的业务化软件系统[1]。
样本数据集方面,网络上已经有很多公开的深度学习样本数据集可供使用。其中,EuroSAT是土地利用和土地覆盖分类数据集,包括10个类别,共有27 000张图像[2];BigEarthNet是土地覆盖分类数据集,包括19个类别,共有590 326张图像,涵盖欧洲10个国家;西北工业大学发布的HRSC2016是用于轮船检测的专题数据集,包含4个大类19个小类,共有2976张图像,分辨率为0.4~2.0 m;Gaofen Image Dataset是土地利用和土地覆盖分类数据集,来源于150景高分二号影像,涵盖中国60个城市,覆盖面积超过50 000 km2;武汉大学发布的LuoJiaSET,对当前73个开源样本数据集进行统一处理[3]。文献[4]对2001—2020年发布的124个遥感影像样本库进行了归纳和综述,并从元数据、分辨率、算法模型和应用领域进行了分析。这些样本数据集均可以用于深度学习遥感解译,但还存在一些问题:①分类体系不统一,样本类型不足,导致相同地类采集指标不同而无法扩充样本库;②样本数量少,分布不均匀,导致泛化能力弱;③公开样本集样本纯净度不高;④样本无空间信息。现有的遥感影像解译样本分类体系和样本数据集,既无法完整反映甘肃省复杂的地理环境,也不能完全涵盖甘肃省自然资源地表要素。
业务化软件方面,吉威数源的SmartRS、航天宏图的PIE-AI、阿里巴巴达摩院的AIEarth和商汤的SenseEarth都实现了深度学习智能解译全流程,提供目标检测、要素提取、影像分类、变化检测等服务,但受限于自然资源业务化规则,还无法被应用于调查监测和基础测绘更新等一线生产中。相关算法模型均已嵌入系统中,用户无法参与改进。模型库标准化程度不够,不同行业领域的数据模型不能共享互通[5]。
本文以多年度遥感影像和地理国情数据为主要数据源,在制定甘肃省自然资源地表典型要素遥感解译样本分类体系的基础上,建设甘肃首个顾及全省地形地貌分区的多尺度遥感解译样本库,研究建立自动化、分布式多源遥感信息解译系统。
1 方 法
首先按照已有分类体系,构建符合甘肃省情的遥感解译分类体系;其次根据地理特点、地物类型和样本数量选取样本标注区域;然后基于遥感影像及对应的历史数据采集样本,自动构建样本数据集;最后利用地物分类和变化检测模型进行智能解译和变化发现,形成“样本-模型-知识”的样本库建设方法。方法流程如图1所示。
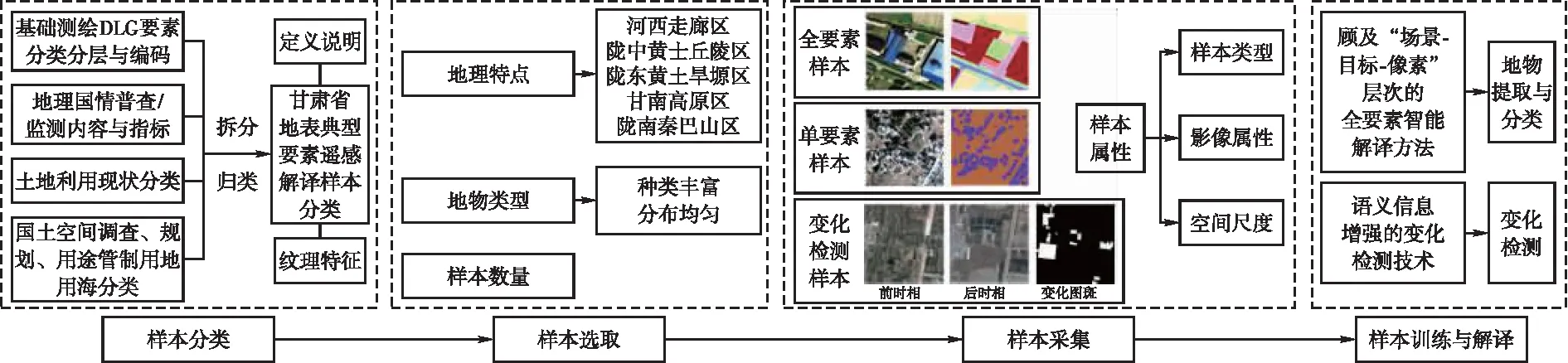
图1 遥感解译样本库建设流程
1.1 地表典型要素遥感解译样本分类体系构建
甘肃省内拥有高山地、山地、平川、河谷、沙漠和戈壁等多种地貌,针对现有分类体系不能有效涵盖甘肃省地表要素问题,需要重新对已有内容与指标进行归类或拆分。分类体系要与当前自然资源管理要求相适宜,满足生态文明建设和国土空间规划的要求,采用开放框架,注意样本类型全面性,对于可能出现的新地类,都能纳入相应分类体系中。
综合考虑国产卫星数据地物识别能力及多种土地分类标准,如《地理国情普查内容与指标》(GDPJ01—2013)、《基础性地理国情监测内容与指标》(CH/T9029—2019)、《基础测绘DLG要素分类分层与编码》《土地利用现状分类》(GB/T21010—2017)和《国土空间调查、规划、用途管制用地用海分类指南》[6]。基于深度学习的地物类型划分既要结合遥感数据源的光谱纹理信息,又要考虑其通用性及与其他土地分类体系之间的转换能力[7]。相比而言,地理国情普查和监测数据采集原则为“所见即所得”,因此以地理国情普查和监测分类标准为依据,结合遥感影像的特征和地物要素的可识别性,将同种类别合并,并单独划分可区分的重要类别,形成适用于遥感自动解译的分类体系,包括全要素样本、单要素样本和地表变化样本,并对每类地物定义分类标准及纹理特征。
(1)全要素样本:对不同分类体系在遥感影像上显示相同纹理的地类进行合并,删除地类内部要素复杂的图斑,如地理国情普查中构筑物一级类中的碾压踩踏地表,按照定义在其范围内包括多种要素,因此不适宜当作样本。经过整理后,全要素样本包括10大类:耕地、园地、林地、草地、房屋建筑区、路面、硬化地表、动(推)土、荒漠裸露地表和水面,该样本数据集主要用于土地利用分类。
(2)单要素样本:以地理国情普查和监测分类为参考,按照业务需求,将独立房屋建筑、露天体育场、堤坝、公路、水体、温室大棚、光伏用地、水渠和冰川积雪等为单要素样本,该样本数据集主要用于专题要素提取。
(3)地表变化样本:地表变化分为两类,一类是通用变化检测,即不定性,只表示变化范围;另一类是定性变化检测,包括新增/灭失耕地、新增/灭失建筑、新增/灭失路面、新增/灭失推填土、新增/灭失林草地、新增/灭失园地等。
1.2 顾及地理地貌分区的遥感解译样本选取标准
甘肃地域辽阔、东西跨度大,相同地物在不同区域形态差异较大,拥有不同的地表特征,如河西走廊区的旱地多位于平地,地块规整集中,而陇中、陇东和陇南的旱地多位于山地,地块不规则且零散,因此不同区域之间的样本混合学习会导致模型训练效果差[8]。针对此问题,引入地理地貌分区概念,通过对甘肃现有地貌分区进行分析,沿用并适当调整国土三调中的地貌区划分方法,将甘肃省共分为5部分,分别是河西走廊区、陇中黄土丘陵区、陇东黄土旱塬区、甘南高原区和陇南秦巴山区。因此在省域的大尺度样本库的基础上,以5大地貌分区分别构建中尺度样本数据集。综合考虑每个地貌分区的地域特点和地表覆盖类型,选择具有代表性的县区作为样本采集区域,即该县区训练的模型在同地貌分区的其他县区也适用。如果条件允许,也可在每个县区采集样本,样本数量达到训练要求后构建小尺度样本数据集。每个样本选取区域应具有地物多样性,即最大程度涵盖自然资源典型要素,不同类别要素之间应存在明显的差异。
1.3 基于历史成果的样本集构建方法
基于历史成果数据制作样本采集成果,包括样本影像数据、矢量数据,通过自动化裁切方法制作样本瓦片成果,包括影像瓦片、标签瓦片,且记录样本知识特征,入库后形成多类型、多属性、多尺度的甘肃省遥感解译样本库。
(1)样本采集成果。地物分类和提取模型训练需要大量的、种类丰富的样本,应最大限度利用已有数据[9]。首先将不同分类体系的测绘成果按照编码对照统一归入新的遥感解译分类体系中,且在样本采集时也按照三级类采集,通过编码对照将二级类或三级类归入全要素样本和单要素样本中,新增要素可增加编码按需扩展入库。然后进行交互式采集,样本采集原则包括:最大最小范围原则,最大指影像范围内的样本要完整,即要保持完整边界,最小指样本内部特征唯一,无杂质干扰;“宁无不错”原则,删除影像质量不好、对样本识别和可分性带来干扰的影像区域;“所见即所得”原则,即如实反映客观情况。
地表变化样本采集时,要求前后影像分辨率接近,空间坐标系一致,影像上相同地物位置完全套合。基于地类变化监测数据,保留可用于制作变化检测样本的数据,若无地类变化监测数据,通过两期影像上的比较,找到符合要求的变化范围明显的区域,如建筑灭失、道路拓宽等,将变化区域和未变化区域分别采用像素级别标注[10]。
(2)样本瓦片成果。影像数据和采集数据按照规范组织好后,通过分布式自动裁剪程序制作瓦片样本,包括影像瓦片、标签瓦片及瓦片元数据。深度学习不同的算法满足图片大小的要求,且还考虑边缘特征、局部特征和整体特征等,样例尽可能体现地物的全部特征。样本切片尺寸大小根据数据情况自定义,主要有1024×1024、512×512、256×256像素。同时,可通过设置重叠度和旋转角度扩充样本数量。
(3)样本知识特征。样本元数据主要记录样本知识特征,按照3个维度描述:①按样本类型(全要素、单要素、地表变化样本等);②按影像属性(数据源、成像时间、传感器、空间分辨率等);③按样本空间尺度(大尺度-省域、中尺度-地貌分区和小尺度-县域),实现样本特征多维信息组织与存储[11]。
1.4 基于深度学习的智能解译与变化检测模型训练
1.4.1 顾及多层次的要素智能解译方法
顾及多层次要素智能解译方法的思路是在训练端多模型解译时,首先对总体样本集进行特征抽取,然后根据抽取的特征进行聚类,分别对N个样本子集进行训练,得到N个模型。解译端待解译的影像,首先通过特征提取选择与子模型中相似的若干模型,然后使用若干个模型进行解译,加权得到解译结果。针对每个模型,采用遥感影像智能解译模型的层次认知方法,实现遥感影像从数据到场景级别的智能解译。
基于深度卷积网络的高分辨率遥感影像层次认知方法主要包括3部分:像素级语义分割、目标级语义分割,以及场景约束级语义分割。像素级语义分割综合考虑尺度、感受视野、先验知识融合及网络所占GPU显存等方面因素,实现语义分割任务“端对端”优化;目标级语义分割侧重研究遥感影像中的目标特征不变融入语义分割框架,实现对旋转不变因素的抵抗;场景约束级语义分割主要目的是融入大范围的场景信息,提高遥感影像语义分割结果的可靠性[12]。
1.4.2 语义信息增强的变化检测技术
语义信息增强的变化检测思路为:首先采用面向对象进行变化检测,然后基于全卷积孪生拼接网络结构(FCSCN)提取变化图斑,将两种方法融合使得变化信息提取的同时具有较高的查全率和查准率。
(1)基于语义信息的面向对象变化检测。首先采用面向对象的变化检测方法对两期影像进行分割,获取分割对象的语义信息和上下文特征;然后通过最大类间方差得到二值化变化置信度图;最后输出变化图斑。影像分割使用超像素代替像素进行分析,使最后得到的变化图斑更符合实际地物的轮廓。
(2)基于FCSCN端对端变化信息提取。对称编码-解码的拼接网络结构(FCSCN)由全卷积神经网络(FCN)和孪生神经网络(Siam)组成,基于变化检测样本进行模型训练,直接提取两期影像的变化信息,从而实现端到端的变化检测。在编码操作时,基于权值共享的孪生神经网络,分层逐步提取两期变化影像特征。在解码操作时,将当前的特征与对应的编码特征融合,采用上采样技术分层逐步解码,在上述编码与解码双重耦合作用下,得到变化图斑。
2 样本管理与智能解译系统设计与建设
在上述方法基础上,建立甘肃省遥感解译样本库平台,包括样本管理与智能解译两个分系统。样本管理系统可对多类型、多属性、多尺度样本数据进行集成管理与动态维护,智能解译系统可以实现大范围遥感影像高精度解译与变化检测。系统总体构架如图2所示。
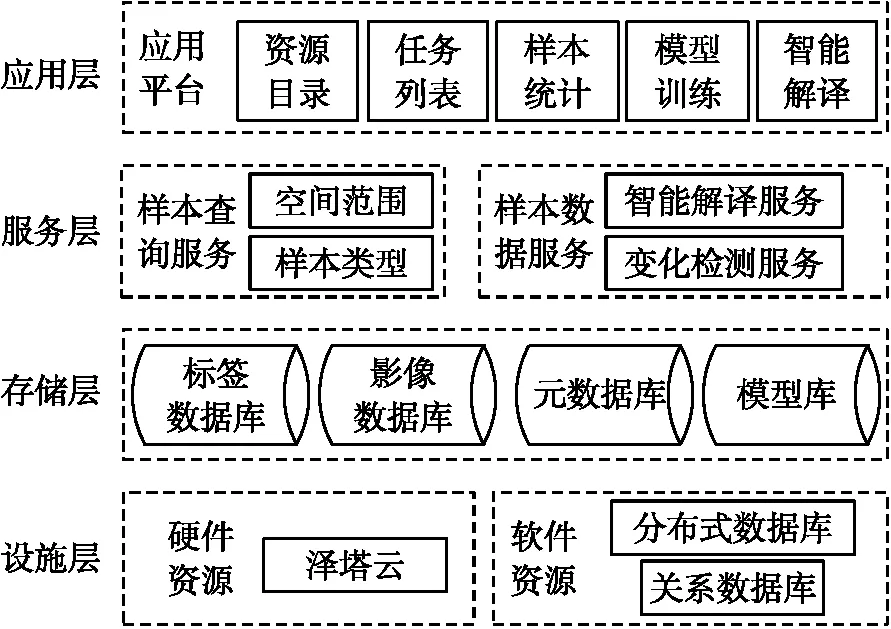
图2 甘肃省遥感解译样本库平台总体架构
应用平台架构包括基础设施层、数据存储层、数据服务层和应用层4个层次。
(1)基础设施层: 软件环境部署分布式网络环境、分布式文件系统、分布式数据库和关系数据库等软件环境。硬件设备采用数据中心云操作系统并配备高性能GPU计算资源。针对遥感智能解译算法的多核并行任务调度需求,研发了CPU+GPU异构多核混合并行调度方法,采取了使逻辑控制、串行运算的任务优先调度CPU计算节点、计算密集型大规模并发任务优先调度GPU计算的方法,极大提高了计算资源的综合使用效率。
(2)数据存储层:提供数据的存储、扩展与维护能力。样本数据存储于分布式数据库HBase中,数据标签功能采用ElasticSearch搜索服务器,元数据存储在关系数据库postgreSQL中。
(3)数据服务层:支持导入公开遥感样本数据集,支持样本的多维语义查询,通过传感器、时间、空间位置、地物类型和空间分辨率进行检索。在样本数据服务中,系统通过归纳总结不同影像各地类的光谱、纹理、形状、拓扑等属性特征,设定、配置有关特征规则与调整参数,实现智能解译与变化检测过程的简易化操作[13]。
(4)应用层:搭建Web端样本库平台,提供样本的录入、校验、多维语义查询、数据获取、可视化、样本分析与应用功能服务[14]。
3 应 用
基于云上物理资源和逻辑资源的样本管理与智能解译系统,在5大地貌区选择18县区作为样本采集区域,在每个样本采集区域采集全要素、单要素和变化检测样本。经过裁切后,全要素样本有270.5万个,单要素样本有20.4万个,变化检测样本有8.1万个。基于样本制作-模型训练-智能解译-质量评估的遥感智能解译流程开展不同尺度的工程化应用,在大尺度省域范围上开展了省级基础测绘更新;在中尺度区域范围上开展了城市国土空间监测;在小尺度县域范围上开展了非农化监测。
3.1 省级基础测绘更新
2023年甘肃省省级基础测绘已从覆盖生产转变到要素变化更新,而首要任务是发现哪里有变化。首先基于样本库的单要素解译对建筑物、道路、水体和光伏发电装置进行自动提取,然后套合已有DLG,通过空间分析技术判别变化范围,重点关注城镇区域、道路两侧、河道附近等人类活动频繁地区。选取平凉、庆阳、天水、陇南4市州为研究区,变化发现图斑分布如图3所示,对比目视解译结果,大部分变化范围都可以提取。然后通过定量方法对解译结果进行精度评价(见表1)。其中,定量精度评价采用查全率和查准率表示(A代表人工解译结果,B代表智能解译结果)。可以看出,重点要素自动提取查全率达97%,查准率达90%。
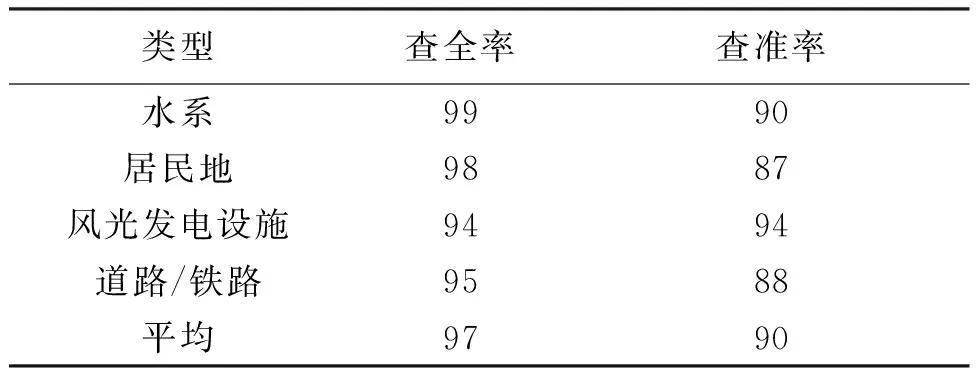
表1 定量精度评价(%)

图3 变化发现图斑分布
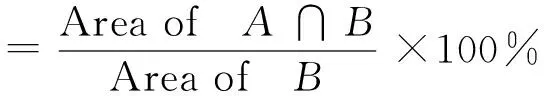
3.2 城市国土空间监测
通过利用多尺度融合全卷积神经网络的建筑物和道路提取方法,在2022年城市国土空间监测项目中,选取永昌县作为试验区,数据源为高分二号影像,提取了城区内房屋建筑[15],且对路网进行更新[16],后处理时通过规则化算法对结果进行了修正,永昌县城区房屋建筑和路网自动提取结果如图4—图5所示。

图4 永昌县房屋建筑提取结果

图5 永昌县路网提取结果
3.3 “非农化”监测
“非农化”主要表现为耕地变林地、建设用地、水面、道路、推填土等。选择古浪县泗水镇为试验区,在甘肃省遥感解译样本库中筛选达到高精度模型训练要求的“非农化”样本数据集,通过构建的耕地“非农化”样本体系和样本库训练所得的深度学习模型[17],选取2015和2023年0.8 m遥感影像,自动识别耕地发生变化的疑似“非农”图斑,共356个;通过目视解译和外业检核两种方式,对自动识别出的“非农”图斑进行精度验证,选用查全率和查准率定量评价精度,计算得到精度评价结果(见表2)。可以看出,基于目视解译方法的查准率为74.4%,查全率95.7%;基于外业核查方法的查准率为77.8%,全率为93.3%。

表2 基于目视解译和外业核查点精度评价
4 结 语
本文围绕甘肃省自然资源地表要素样本的类别细分,建立了适于甘肃特色的典型要素遥感解译样本分类体系,并以此为基础,分步、分层建设甘肃首个地表典型要素遥感解译样本库,样本数量达300万个以上,时相为2013—2023年,样本空间分辨率为0.1~2.0 m。样本库涵盖甘肃地表各类型地物,样本类型精细,具有较高的类内多样性和较低的类间可分离性,并可根据业务需要进行统一和扩展。样本基于不同地貌分区均匀选取样本制作区域,更能符合甘肃省地物遥感解译的需求。在样本和算法上均不同程度地考虑了空间位置、分辨率、传感器、季节特征等图像差异,使得模型泛化性更强。
样本库平台集成了顾及多层次的要素智能解译模型和语义信息增强的变化检测模型,还提供了其他模型、算法接口,实现数据、模型和算法开源生态。依据甘肃本省地方和业务特色,将样本规则建立与业务适配模式融合,推进了技术转化工程的应用。下一步将不断扩充样本,为相关科研院所提供高质量样本服务,同时在自然资源管理工作中发挥支撑作用。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
河北地质(2021年1期)2021-07-21
当代水产(2020年4期)2020-06-16
开放教育研究(2020年2期)2020-03-31
中国生物医学工程学报(2019年5期)2019-07-16
现代园艺(2017年22期)2018-01-19
中南林业科技大学学报(2017年12期)2017-12-19
河北书画研究(2017年1期)2017-08-22
现代语文(2016年21期)2016-05-25
山东青年(2016年2期)2016-02-28
