
基于形态特征的终端区进场中心航迹识别方法
2023-10-09 01:57王超李昊昱陈含露
科学技术与工程 2023年26期
王超, 李昊昱, 陈含露
(中国民航大学空中交通管理学院, 天津 300300)
空中交通航迹数据反映了真实的空中交通情况,记录了真实的飞行路径、高度航向变化等细节,是管制员对大量航空器调度、指挥和引导的结果,空中交通轨迹的形态特征和空间分布特性是空中交通复杂性重要的外在表现形式。中心航迹是航空器飞行过程中具有代表性的轨迹,它描述了航空器群相似的运动趋势。在复杂的终端区运行环境下通过对轨迹进行相似性度量,聚类并提取中心航迹,对表征交通流特征、挖掘航空器飞行模式和检测异常轨迹[1],评估实际飞行轨迹与飞行程序的一致性[2],研究客观表征轨迹运动混乱程度的复杂性模型,量化分析空中交通系统性能等具有重要意义。
当前已有诸多学者开展了轨迹聚类及相似性度量的相关研究。王超等[3]考虑飞行速度差异带来的航迹点相似度的偏差,将雷达航迹点逆向比对,提出基于轨迹聚类的平均轨迹构造方法。熊伟等[4]通过相异度矩阵对数据进行预聚类处理,使用高斯混合EM算法对轨迹进行聚类,提高了聚类的准确性。杨璐等[5]建立了多特征融合的轨迹相似度模型,通过自适应谱聚类算法对轨迹进行分析,以各簇轨迹间距离为指标提取中心航迹。Besse等[6]对基于动态时间扭曲和基于形状的两种相似度度量方法的聚类结果进行了定量分析,发现基于形状的距离更适用于轨迹聚类,聚类主要考虑轨迹的空间紧凑性,而时间和速度等非空间特征的影响并非十分重要。Wang等[7]提出了一种考虑轨迹形状的相似性度量方法,但没有考虑到轨迹的连续性。Li[8]考虑了豪斯多夫距离在计算轨迹间距时容易受到航迹点跨度大、航迹点缺失等问题的影响,利用改进的DBSCAN算法进行轨迹段聚类,通过提取质心向量得到中心航迹。
现有轨迹聚类方法未考虑到轨迹整体的形状、轨迹段方向、速度、连续性等特征,同时易受到噪声点和轨迹长度的影响[9],无法在大量航迹数据中直观地挖掘出轨迹的整体运动特征并精确识别出中心航迹。因此,现提出一种基于单向距离(one way distance, OWD)和密度峰值聚类(density-peak clustering, DPC)的中心航迹提取方法。根据轨迹空间形态特征,采用单向距离相似度度量方法,同时考虑轨迹的位置属性和航向属性定义多特征轨迹相似度模型。通过密度峰值聚类进行分析,提取聚类结果中的每一簇中具有最高密度的真实轨迹作为中心航迹。最后通过实例分析,验证所提模型和方法的合理性和有效性。
1 轨迹相似度
轨迹相似性度量是轨迹聚类的基础[10]。轨迹相似度是指一对轨迹之间的相似程度,包括时空位置、形状趋势、运动特征等,通过轨迹相似度可以衡量运动的整体相似性。基于几何形状计算相似度的主要有豪斯多夫距离和弗雷歇距离[11-12],它们都是基于点的相似度计算方法,易受到噪声较大的影响。现有的测量轨迹间相似性的方法多具有以下局限性:对噪声和误差非常敏感,鲁棒性差;多考虑时间和空间因素,忽略了轨迹形状、轨迹段方向等特征;在匹配轨迹时需要单调连续;对采样率和采样个数要求高,前期需要做大量的数据预处理工作[9]。本文研究在形状相似度度量方法单向距离的基础上进行相似度函数的构造,提出一种基于单向距离的多特征轨迹相似度模型。单向距离采用点到线段的距离而不是点到点之间的距离,分段对称计算轨迹之间的相似性,将轨迹作为一个整体考虑,包括轨迹的形状和物理距离,能够对不同长度的路径间距离进行归一化,对轨迹中的噪声点具有较强抗干扰能力,降低了对采样率的要求,且无需轨迹单调连续。
1.1 单向距离
使用网格对轨迹离散化处理,将整个区域分为相同大小的单元网格,每个单元网格根据其在x和y坐标中的位置进行标记。假设两个单元网格g1(x1,y1)和g2(x2,y2),则两个单元网格之间的距离为
(1)
网格轨迹Tg=(g1,g2,…,gn)由单元网格序列组成,相邻单元网格的距离为1,n为Tg的长度,记为|Tg|=n。
对于一个单独的单元网格g和一条轨迹Tg,如果网格轨迹Tg中的网格g′∈T到网格g的距离D(g′,g)小于网格轨迹Tg中任意其他网格g″到网格g的距离D(g″,g),则将单元网格g′定义为网格轨迹Tg上的局部最小点。单元网格g到局部最小点的距离D(g,g′)即为其到轨迹的最短距离。
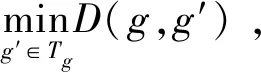
(2)
假设航迹数据集合中任意两条轨迹分别为Ti和Tj。从轨迹Ti到轨迹Tj的单向距离Dowd(Tgi,Tgj)定义为网格轨迹Tgi的局部最小点p到网格轨迹Tgj的距离除以Tgi的长度,该距离是从网格轨迹Tgi到网格轨迹Tgj的最短距离的积分,为有向距离。
(3)
两条轨迹Ti和Tj之间的单向距离Ds(i,j)是它们的单向距离之和的平均值,即得到的Ds(i,j)是对称的。
(4)
1.2 多特征轨迹相似度模型
在终端空域中,航空器一般都是按照规定的标准飞行程序从不同的方向进场,仅使用单向距离的度量方法并不完全适合于处理空管航迹数据,因此在使用单向距离计算轨迹相似度的基础上,考虑到两条轨迹之间的位置属性和航向属性,定义轨迹之间的位置特征距离和航向特征距离。
航迹数据是一个多维序列,由多维数据点组成每个航迹点包括经度、纬度、地速、高度和时间等信息[13]。假设航迹数据集合中第i条和第j条轨迹分别表示为
(5)
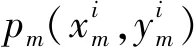


(6)
轨迹Ti与Tj的所有航迹点的欧式距离d={d1,d2,…,dk},定义轨迹Ti到轨迹Tj的位置特征距离为
(7)
定义轨迹Ti到轨迹Tj的航向特征距离为
Dθ(i,j)=|θi-θj|
(8)
式(8)中:θi和θj分别为轨迹Ti和Tj靠近终端区边界处航迹点的航向平均值。
定义轨迹Ti到另一条轨迹Tj的多特征轨迹相似度模型为
D(i,j)=ωsDs(i,j)+ωdDd(i,j)+ωθDθ(i,j)
(9)
式(9)中:Ds(i,j)为轨迹Ti与Tj之间的单向距离;Dd(i,j)为轨迹Ti与Tj之间的位置距离;Dθ(i,j)为轨迹Ti和Tj之间的航向距离;ωs为单向距离的权重因子;ωd为位置距离的权重因子;ωθ为航向距离的权重因子。权重因子的取值取决于多特征距离的应用场景,满足ωs≥0,ωd≥0,ωθ≥0且ωs+ωd+ωθ=1。
(10)
轨迹之间的各特征距离进行归一化处理,Xi为转换前的数值,XN表示转换后的数值,Xmax和Xmin分别为样本最大值和最小值,nT表示轨迹总条数。经过多特征轨迹相似度模型计算之后,得到对称的距离矩阵DT,作为之后聚类分析的输入。
(11)
2 密度峰值聚类分析及中心航迹提取
基于所定义的轨迹之间的相似度表达,通过无监督聚类算法将轨迹按照空间相似度进行划分。目前广泛使用的聚类算法包括k均值算法、分层聚类、密度算法等[14]。线段簇通常是任意形状的,基于密度的轨迹聚类方法可以发现任意形状的聚类并且过滤噪声,是最适合用于线段的聚类方法。密度峰值聚类(density-peak clustering, DPC)[15]基于两个假设:簇中心的局部密度大于围绕它的其他数据点的局部密度;不同簇中心间的距离较远。基于多特征相似度模型的密度峰值聚类算法具体步骤及流程如下。
步骤 1对给定的航迹集,首先计算相似性距离矩阵DT,随机选取k个初始对象(T1,T2,…,TK)作为初始聚类中心点。
步骤 2计算各个初始聚类中心的局部密度值ρi,并将各中心的密度从大到小排列。各轨迹的局部密度是以该轨迹为中心,截止距离dc为半径的范围内的轨迹的数量,使用高斯核函数计算局部密度ρi,计算公式为
dc=dround[τ·mT]
(12)
(13)
式(13)中:D(i,j)为轨迹Ti和Tj的多特征相似度距离;dc为截止距离阈值参数,将距离矩阵的距离dround按升序排列即为d1≤d2≤…≤dmT;mT为距离矩阵中距离的个数;τ为百分比;[]为取整函数在以dc为半径的范围内进行搜索计算。
步骤 3根据密度值计算初始聚类中心Ti与其最近的较高密度聚类中心Tj之间的上向距离δi,即
(14)
步骤 4将各样本划分到局部密度较大且与各聚类中心最近的类簇中,得到新的聚类中心,重复执行步骤2和步骤3,至聚类中心不再变化。
步骤 5算法终止,输出最终的聚类中心点和类簇。
从各类轨迹簇中计算并提取一条能够代表整体运动方向的中心轨迹。计算得到局部密度最高和距离更高密度中心较远的轨迹,密度峰值聚类算法输出的各聚类中心即为需要提取的中心航迹。
3 实例分析
3.1 实验环境与数据预处理
以双流国际机场终端区进场ADS-B航迹数据为例,使用MATLAB作为数据处理和实验分析软件,提取航空器运行的经度、纬度、高度、速度、时间等航迹点信息,以及机型、起降机场等航班信息,对航迹点进行航迹整合、裁剪和清洗操作。将同航班号的航迹点数据按照时间顺序构成一条轨迹序列,删除时间与经纬度同时重复的相邻航迹点。
空管监视系统获取的航迹数据尽管经过相关、降噪、降重等处理,但是仍然包含大量冗杂无关的航迹信息。大部分航迹数据包含航路飞行阶段,甚至是从起飞到落地的全部飞行过程。首先对轨迹数据进行裁剪,终端空域的地理范围是一个多边形,剔除那些超出终端空域范围外的航迹,保留在多边形上和多边形内部的航迹。在终端空域内包含大量飞越航空器的航迹,也存在通航飞行、训练飞行的空域。在通航飞机装备了ADS-B发射机的情况下,监视系统同样会记录其轨迹。可以依据轨迹的起点、终点,高度变化和飞行范围,通过判断航空器是否在使用本场跑道落地来剔除这些航迹。
由于进离场航班存在完全不同的飞行模式,需对进离场飞行轨迹进行区分。依据轨迹对应的航班飞行计划数据提供的航班进离场时间、起落机场等信息,识别起飞机场与目的地机场,将轨迹数据划分为进场与离场。对于经停航班,由于前期已根据高度范围将轨迹数据中地面滑行段航迹点剔除,计算轨迹中相邻航迹点时间差,将轨迹划分为进离场两段轨迹。通过对轨迹数据的预处理,仅保留在终端空域范围内的进场商业航空器飞行过程中的航迹数据。
聚类时使用直角坐标系进行计算,为提高数据处理与计算速度,选取终端区范围内航迹进行分析。双流国际机场共有两条跑道02L/20R以及02R/20L,如图1所示,双流国际机场主要使用IGNAK、EKOKA、AKDIK、LADUP、MEXAD方向进场程序进场,使用跑道02R的进场程序主要有8条,使用跑道02L的进场程序主要有7条,使用20L跑道进场程序较少,一般只因施工或天气因素才使用。

图1 双流机场主要进场飞行程序示意图
3.2 进场交通流识别及中心航迹提取
对航迹数据预处理后,基于多特征轨迹相似度模型和密度峰值聚类算法,以对双流机场终端区单日414条进场飞行轨迹为研究对象,首先由式(1)~式(4)计算进场飞行轨迹的形状距离,由式(6)~式(7)计算进场飞行轨迹的位置距离,之后通过式(8)计算进场飞行轨迹的航向距离。依据实际数据经过多次试验得到权重因子。通过式(9)对各个距离进行加权,利用式(10)对所有距离进行归一化,得到式(11)轨迹之间的所有轨迹相似性距离矩阵DT。DPC算法的参数截断距离dc的值需要通过设置一个百分比τ来确定,τ取值范围一般为1%~2%,确定截断距离前,需要先根据式(12)对DT所有轨迹间的相似度距离D(i,j)做升序排列。本算例中过滤掉前1.4%的值,取此时的最小值为截断距离。本算例中dc,计算结果为0.012 3。根据式(13)计算该轨迹的局部密度参数ρi。根据式(14)计算数据轨迹Ti到具有更高密度的轨迹的最近距离δi。当局部密度和相对距离的值都比较大时,此时对应的轨迹则为初始聚类中心即密度峰值点。
通过密度峰值聚类算法不断迭代从而将轨迹划分成不同类型的轨迹簇,进场交通流轨迹识别结果如图2所示。该方法可以识别出符合标准进场程序的主要交通流和不同于进场程序的其他主要进场路径,能较全面地反映出航空器进场轨迹的主要特征,从而掌握终端区航空器的飞行模式,分析轨迹簇的分布规律。实际运行中轨迹的时空分布十分复杂,在终端区内,航空器还存在着一些异常轨迹。产生异常飞行状态一般由于管制员工作负荷大、管制水平低、工作经验不足,飞行员未执行标准操作,空域飞行流量大和恶劣天气等原因造成。将形态差异度过大、航向大幅改变、偏离标准程序、与大部分轨迹运动模式相异且数量较少的轨迹作为异常轨迹。使用密度峰值聚类算法得到单日终端区进场飞行轨迹各簇形态如图3所示,识别出的8个类簇的轨迹彼此在形状和空间分布上有着显著的差异,而同一簇内的轨迹有着较高的相似度和形态特征。统计得到不同飞行模式下的飞机数量,一定程度上反映出了终端区内各交通模式的频繁程度以及总体运行情况。
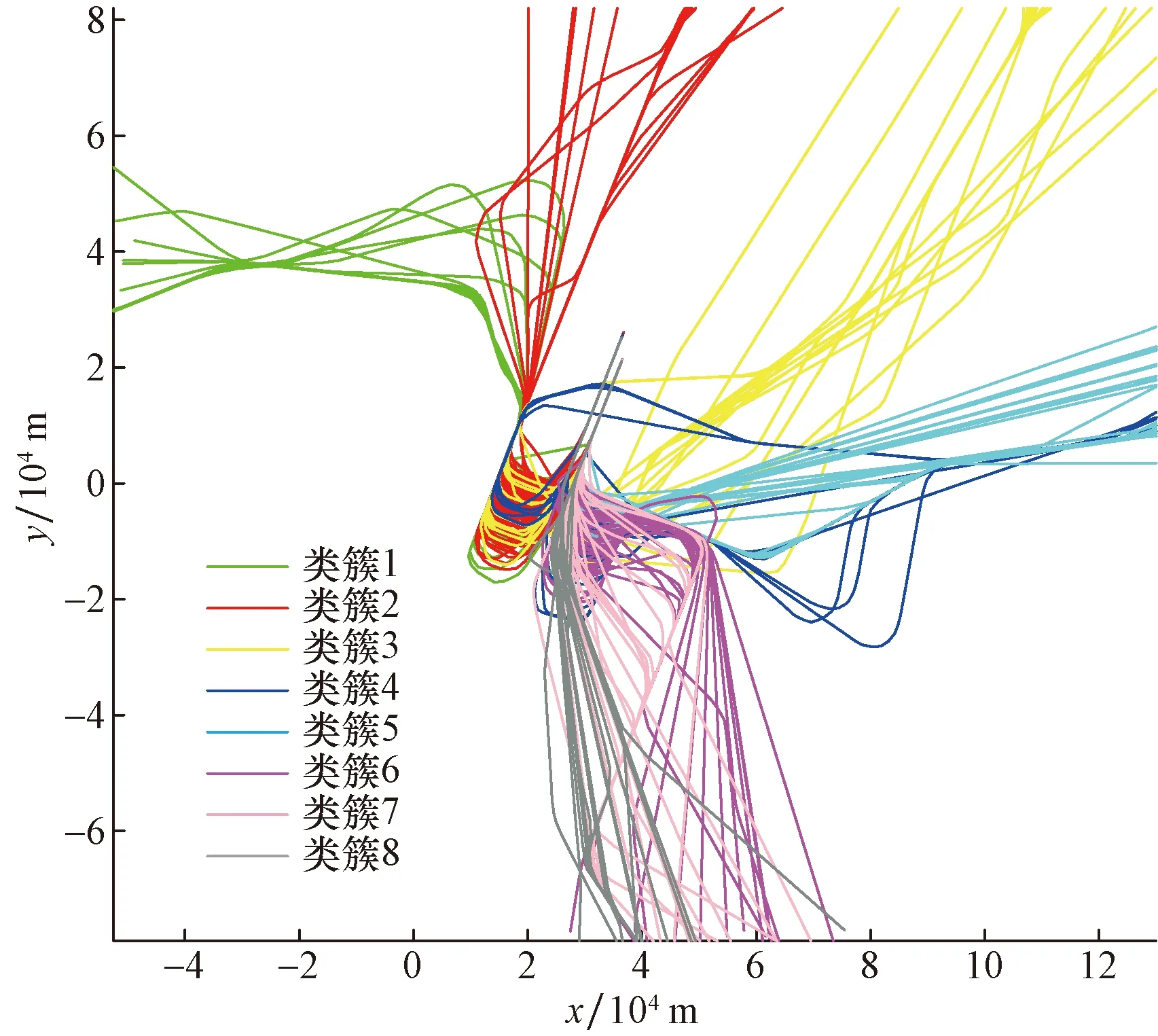
图2 终端区进场飞行轨迹聚类结果

图3 各簇进场飞行轨迹形态示意图
根据实际情况对轨迹进行分类时,既需要保持簇内轨迹的相似性,又要体现不同类簇轨迹的分布特征和差异性。类簇数目k对聚类的合理性具有重要的影响,当类簇数目k的取值较小时,基本可以表达有特点的轨迹路线,但仍有部分较为典型的轨迹无法被表达。根据实际当类簇数目k的取值较大时,可区分同一个进场且形态多样的各类轨迹,但有些实质为管制员引导航空器飞三边等指挥路线的变形,应视为同一类轨迹。在本算例中,当k=8时效果最好,可以较为科学全面地反映出实际运行中航空器各类进场轨迹的主要特征。
对轨迹数据聚类分析得到轨迹簇后,为进一步挖掘各轨迹簇的整体运动规律,用一条或多条代表性的轨迹来描述海量轨迹的空间整体移动特征,这个过程就是中心航迹的提取。其他轨迹与这些中心航迹具有相同或相似的行径路线。因此,通过计算聚类簇中的每条轨迹到簇中其他轨迹的相似度距离之和,将距离较远相似度较高且具有最高密度的一条轨迹作为中心航迹,在密度峰值聚类算法中,其聚类中心是具有局部最高密度且距离更高密度中心较远的轨迹,因此选取各簇轨迹的聚类中心作为中心航迹,如图4所示,各轨迹簇聚类中心vi的上向距离和局部密度如表1所示。
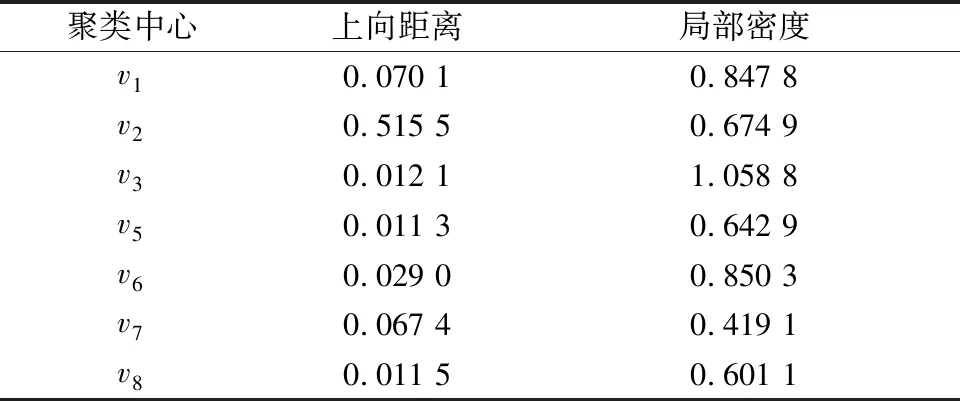
表1 各轨迹簇聚类中心实验参数表
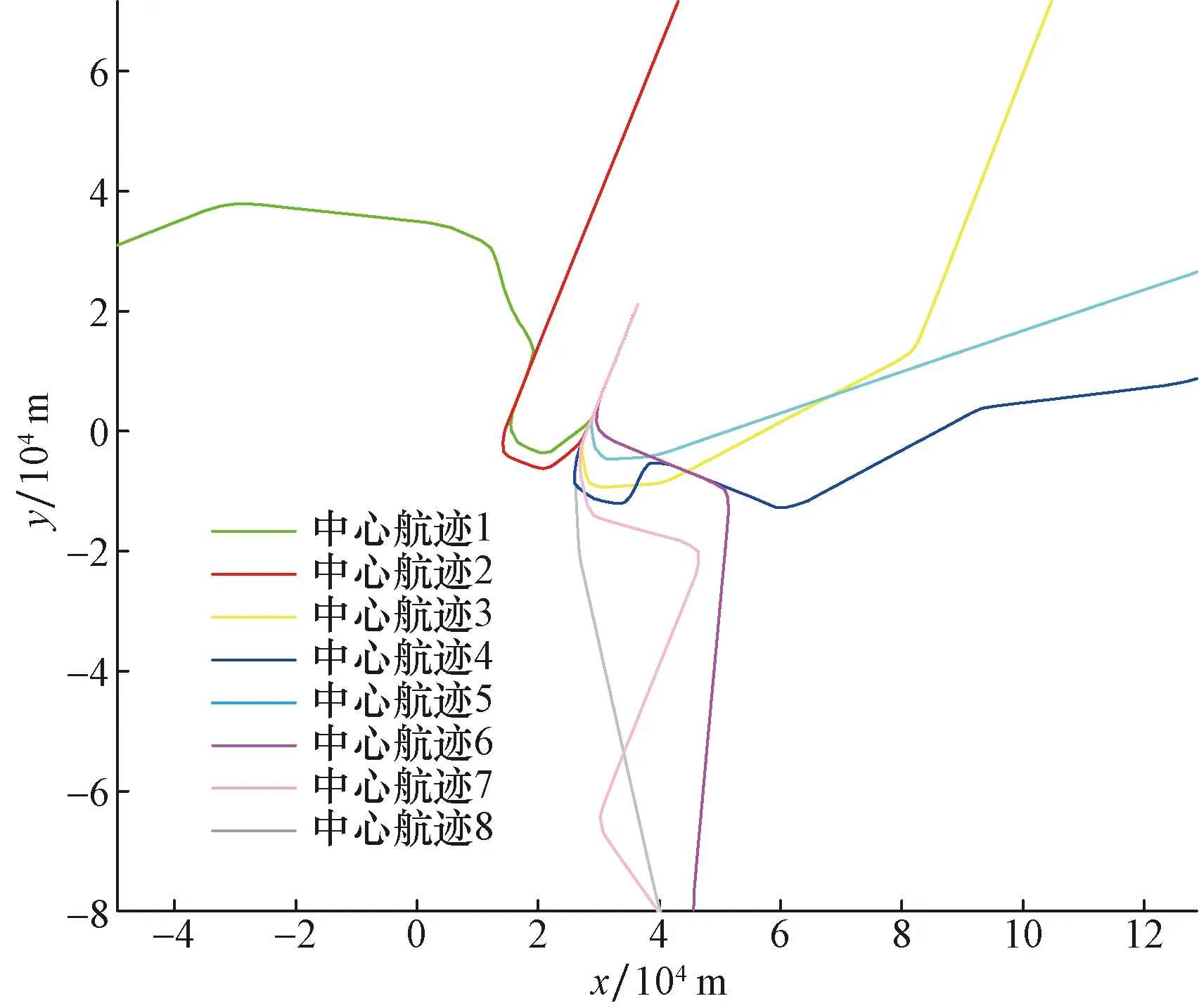
图4 单日终端区进场飞行轨迹各簇中心航迹图
对航迹运行数据进行统计,实际数据表明,管制员只使用了部分偏好程序,双流机场切入02跑道航向道的导航点位于距离跑道入口73.2 km处,然而在实际运行中航空器一般在距离跑道入口40 km处切入跑道航向道,这是出于安全和效率的考虑,在保证航空器安全间隔的条件下,内移切入跑道航向道的导航点。从IGNAK方向进场的轨迹簇空间形态和位置特征与标准飞行程序差异显著,该类轨迹整体直线段较多,可能是由于交通流量控制,空管运行部门直接指挥引导航空器直飞最后进近定位点、引导至某点再直飞五边、飞三转弯等距圆等实施机动飞行的指令造成的,可以一定程度上提高航空器进场的效率。
3.3 聚类效果评价
SD是基于密度的指标[16],SD由簇间密度和簇内方差组成,通过对比类内的紧密性和类间的密度来评估聚类的有效性。SD的取值越小表明聚类效果越好,计算公式为
SD=SC+ρW
(15)
(16)
(17)
式中:ρW为类间的密度;SC为簇间的平均分离度;c为类簇数目;ci为第i类;ρ(vi)为第i类的聚类中心vi的密度;ρ(vj)为第j类的聚类中心vj的密度;ρ(uij)为第i类和第j类之间的中心uij的密度;uij为聚类中心vi和vj两点连线的中点;‖δ(S)‖为整个样本数据S的方差;‖δ(vi)‖为第i类样本数据的方差。
轮廓系数(silhouette coefficient, SC)[5]通过内聚度和分离度来评估聚类算法的性能,适用于实际类别信息未知的情况。假设某一轨迹和它位于的类簇Cc空间中的其他轨迹的相似度为ai,轨迹和其他类簇Cp中的轨迹的相似度为bi,则第i条轨迹的轮廓系数si可表示为
(18)
(19)
(20)
(21)
假设样本在类簇C中;n为样本总数,nc为当前类簇样本数,np为其他类簇样本数;轮廓系数越接近于1,聚类效果越理想。
对单日进场飞行轨迹聚类分析,将得到的中心航迹与轨迹簇通过SD指标和轮廓系数指标进行聚类效果评价,并与层次聚类算法进行对比,不同参数下的轮廓系数SC和SD指标值如表2所示,可以看出,使用密度峰值聚类算法对双流机场进场轨迹进行聚类分析时分为8个类簇时效果最好,且密度峰值聚类算法模型的评估结果要优于层次聚类算法。
4 结论
(1)基于ADS-B航迹数据,使用单向距离度量轨迹之间的相似性,根据轨迹的形状、航向、位置特征构建了相似性矩阵,利用密度峰值聚类算法对轨迹进行划分并提取聚类质心作为中心航迹。结果表明,模型能有效且直观地识别出复杂环境下不同空间形态的轨迹簇。
(2)该方法为终端区航空器飞行模式挖掘,异常轨迹识别和终端空域空中交通时空复杂性及形成机理等相关研究提供了技术支持。接下来将围绕评估实际运行轨迹与飞行程序的一致性,精确识别异常轨迹和探究广义空中交通复杂性模型等做进一步的研究。
猜你喜欢
青年歌声(2019年12期)2019-12-17
知识经济·中国直销(2018年12期)2018-12-29
证券市场红周刊(2018年22期)2018-05-14
证券市场红周刊(2018年26期)2018-05-14
北京航空航天大学学报(2017年7期)2017-11-24
西南石油大学学报(社会科学版)(2016年1期)2016-12-01
北京航空航天大学学报(2016年7期)2016-11-16
北京航空航天大学学报(2016年6期)2016-11-16
太空探索(2016年3期)2016-07-12
太空探索(2016年8期)2016-07-10
