
一种新型编解码结构的结肠息肉分割算法研究
2023-10-08 13:15:16杨海马宋夜夜
软件工程 2023年10期
李 筠, 汪 芳, 杨海马, 宋夜夜
(上海理工大学光电信息与计算机工程学院, 上海 200093)
0 引言(Introduction)
随着生活条件的改善,人们的生活饮食结构也发生了变化,流行病学研究显示不同地区居民的大肠息肉检出率在10.25%~26.64%,并呈逐年上升趋势[1]。由于大肠息肉的早期症状不明显,不易被发现,所以结肠检查对结直肠癌的早期诊断和预防非常重要[2]。为了解决医疗资源不足的问题,并且提高结肠检查的准确率,人们广泛运用高性能计算技术协助进行医疗诊断。
在图像分割的研究领域,ZHOU等[3]在U-Net模型的基础上提出了UNet++,将编码器和解码器通过一系列嵌套的密集跳过路径连接,从而缩小了编码器和解码器的特征映射之间的语义差距。FAN等[4]提出使用并行的部分解码器组件获取全局特征图和递归反向注意模块,然后通过全局特征图和反向注意机制建立区域与边界的关系,提高了对息肉分割的准确性。YEUNG等[5]采用双通道注意力,获取上下文的特征进行对比加权增强识别结果,弥补了传统空间卷积丢失相关细节特征的缺陷。
从上述研究内容可以看出,人们在基于U-Net模型的基础上提出了许多改进方案,但是这些改进方案中大部分忽略了在U-Net模型不断地编码解码的层次变换中出现了信息丢失,以及同一层次之间的编码器与解码器的联系,对一些畸形的不容易分割的息肉图像无法达到预期分割效果的问题。针对上述问题,本文在U-Net模型结构的基础上对编解码器结构模型进行优化,提出了一种新型结肠息肉图像分割模型。
1 模型结构(Model structure)
本文基于U-Net的编码器-解码器结构的模型基础提出了三种结构。
(1)轴向注意力机制的结合模块,弥补在网络层次加深后造成的梯度爆炸或者梯度消失的问题。同时,通过轴向注意力机制,保持了特征中较远距离的位置之间的联系。
(2)适应联系的训练。使用不同空洞膨胀率的空洞卷积弥补池化过程中的特征信息丢失问题。同时,采用自注意力模型弥补池化过程中空间结构的信息丢失问题。
(3)双通道注意力连接,挖掘特征图中目标区域的结构信息,将粗略和低分辨率的预测图细化为一个完整的包含目标区域和细节高分辨率的显著图。
1.1 模型结构图
如图1所示,本文所提研究模型基于U-Net模型的对称编码器-解码器结构。编码器阶段,在进行每一层卷积运算之前加入跳跃轴向注意力模块,解决原编码器结构中存在的梯度问题;池化过程中,加入自适应联系训练,弥补池化过程中的信息丢失问题;解码器阶段,每层的输入特征与同层的编码器输出特征进行双通道注意力连接,保留目标区域信息。经过4层编码器-解码器运算,得到输出结果。
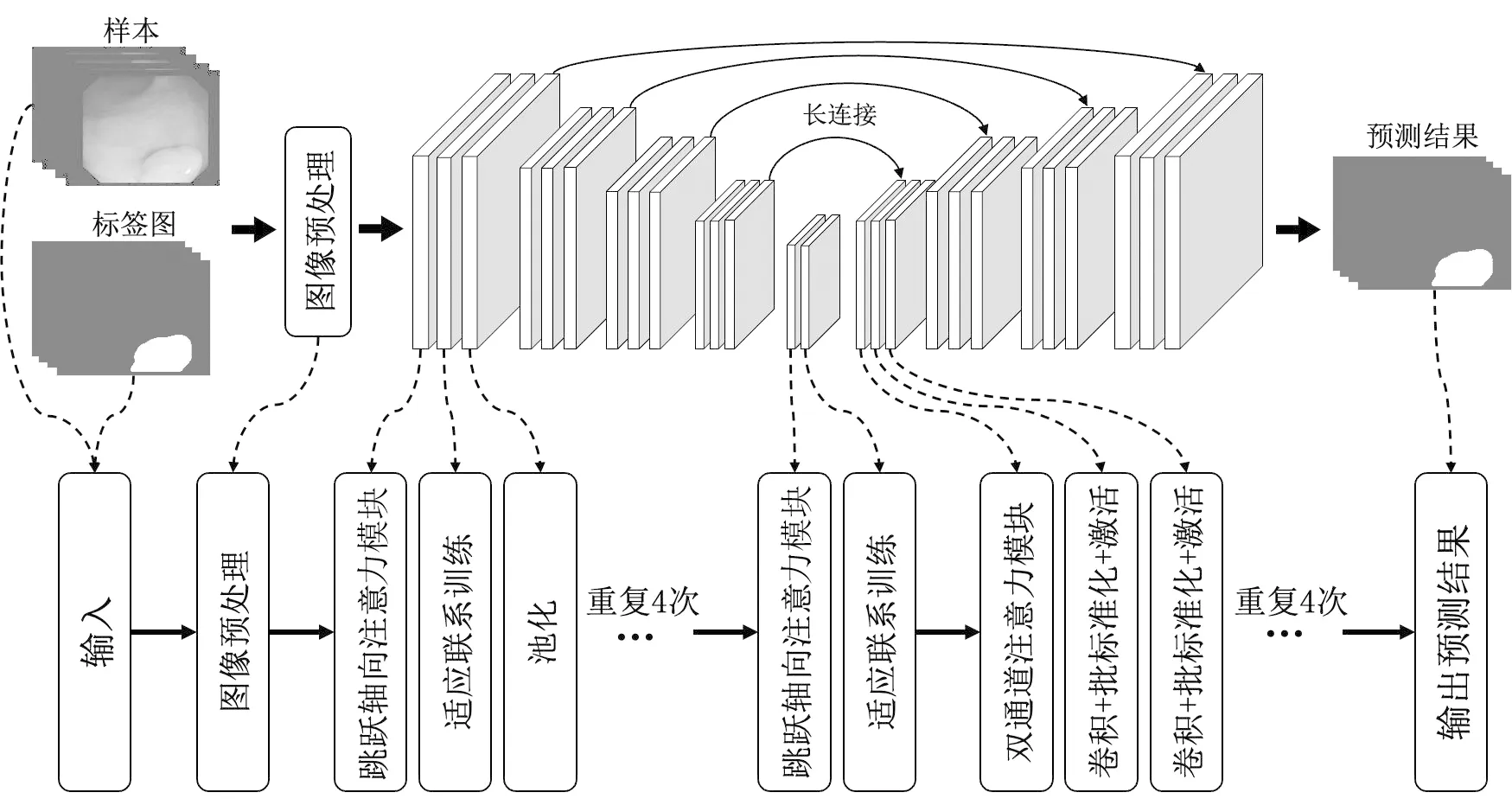
图1 模型结构Fig.1 Model structure
1.2 跳跃轴向注意力
随着神经网络层次的增多,容易造成梯度爆炸和梯度消失的问题。梯度爆炸会导致神经网络的训练不稳定,无法获得有效的数据,而梯度消失会导致训练权重的更新缓慢甚至停滞。于是,本文提出跳跃轴向注意力机制解决梯度问题。跳跃轴向注意力模块结构如图2所示。
(1)先将每一层的输入进行2次卷积、1次批标准化及1次激活的运算,运算结果记为R1。
(2)将每一层的输入进行一次1×1的卷积运算和批标准化,运算结果记为R2。
(3)将R1与R2进行矩阵相加融合,运算结果记为R3。
(4)将R3加入轴向注意力模块,轴向注意力即图3所示的横向注意力模块与图4所示的纵向注意力模块的并联结合,图3中的V、Q、K分别代表值矩阵(Value Matrix)、查询矩阵(Query Matrix)和键矩阵(Key Matrix)。这些矩阵都是在训练过程中随机初始化的权重矩阵,并在梯度下降过程中进行优化。将两个注意力的运算结果进行矩阵相加融合,结果记为整体跳跃轴向注意力机制的输出。
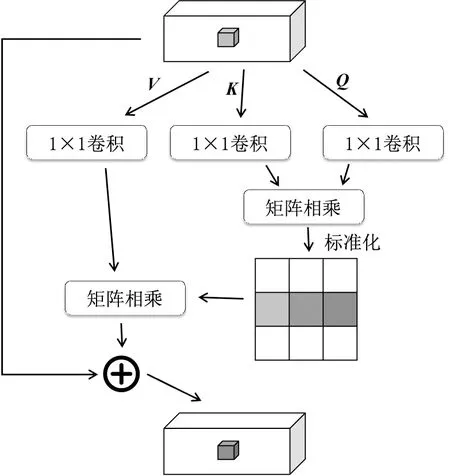
图3 横向注意力结构Fig.3 Row attention structure
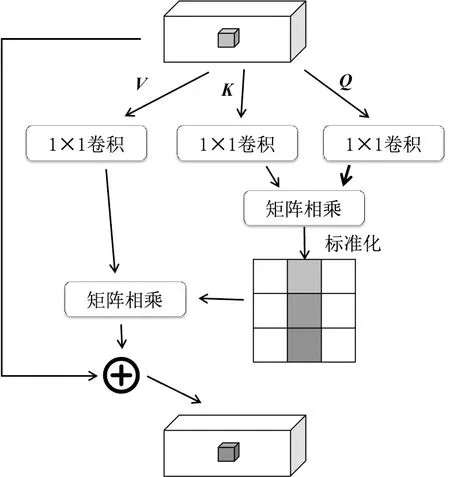
图4 纵向注意力结构Fig.4 Col attention structure
1×1的卷积核提供了类似全连接的运算,有效地增加了网络的深度,保证输入尺寸不变,同时增强了非线性运算能力,有效地提高了整个网络的表达能力[6]。轴向注意力将平面上的特征沿着横向和纵向进行平行的分解,将平面特征降为一维的线性特征,有效地降低了学习成本[7]。
1.3 适应联系训练
在每一层运算结束后,模型会进行池化运算再进入下一层,这样的池化操作会丢失较多的空间结构信息,导致出现不同尺寸大小的图像、分割目标的尺寸相差过大,以及畸形或者尺寸较小的样本等现象,会导致模型泛化能力变弱,无法分割出复杂样本区域[8]。于是,本文提出了适应联系训练用于抽取不同尺寸的样本关联,从而适应更多尺寸的样本。适应联系训练结构图如图5所示。
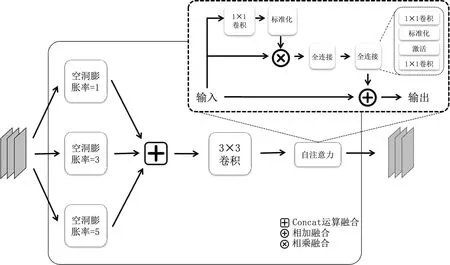
图5 适应联系训练结构图Fig.5 Diagram of adaptive connection training structure
(1)对输入分别进行空洞膨胀率为1、3、5的空洞卷积,将输出记为R1、R2、R3。
(2)将R1、R2、R3进行Concat运算融合,结果记为R4。
(3)将R4进行一次3×3卷积运算,结果记为R5。
(4)将R5加入如图5所示的自注意力模块,将输入特征复制为3份,即I1、I2、I3,对I1进行1×1卷积及标准化操作,得到R6,将R6与I2进行相乘融合及两次全连接运算,得到R7,再将R7与I3进行相加融合,作为模块输出。
通过空洞卷积,保留了图像内部结构的特征。通过自注意力模型,将任意位置的信息关联,让模型在充分利用池化的操作增强感受野优势的同时,也弥补了池化操作造成的信息丢失问题。
1.4 双通道注意力门控模块
解码阶段,在进行上采样时,通常会忽视编码器-解码器特有的对称结构信息,没有充分联系对应编码层输出所包含的信息,容易造成信息缺失[9]。于是,本文改造了上采样阶段流程,具体流程如图6所示。

图6 双通道注意力门控模块Fig.6 Dual channel attention gating module
(1)将前一层产生的输入特征进行上采样运算,运算结果记为R1。
(2)通过长连接将对应编码层的输出与R1进行特征融合,结果记为R2。
(3)将R2通过图7所示的双通道注意力模块,首先将模块输入与图8所示的通道注意力模型进行运算,其次与模块输入进行融合,再次与图9所示的空间注意力模型进行运算,最后与模块输入进行融合得到模块输出R3。
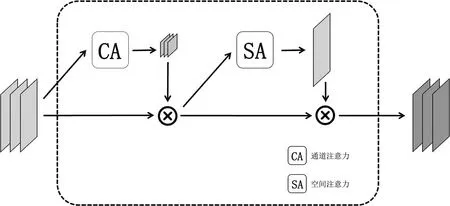
图7 双通道注意力结构图Fig.7 Diagram of dual channel attention structure
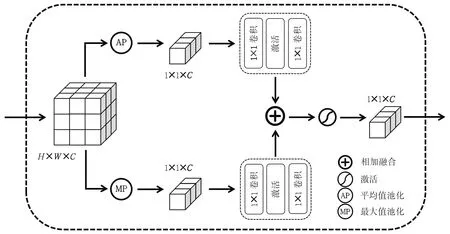
图8 通道注意力结构图Fig.8 Diagram of channel attention structure
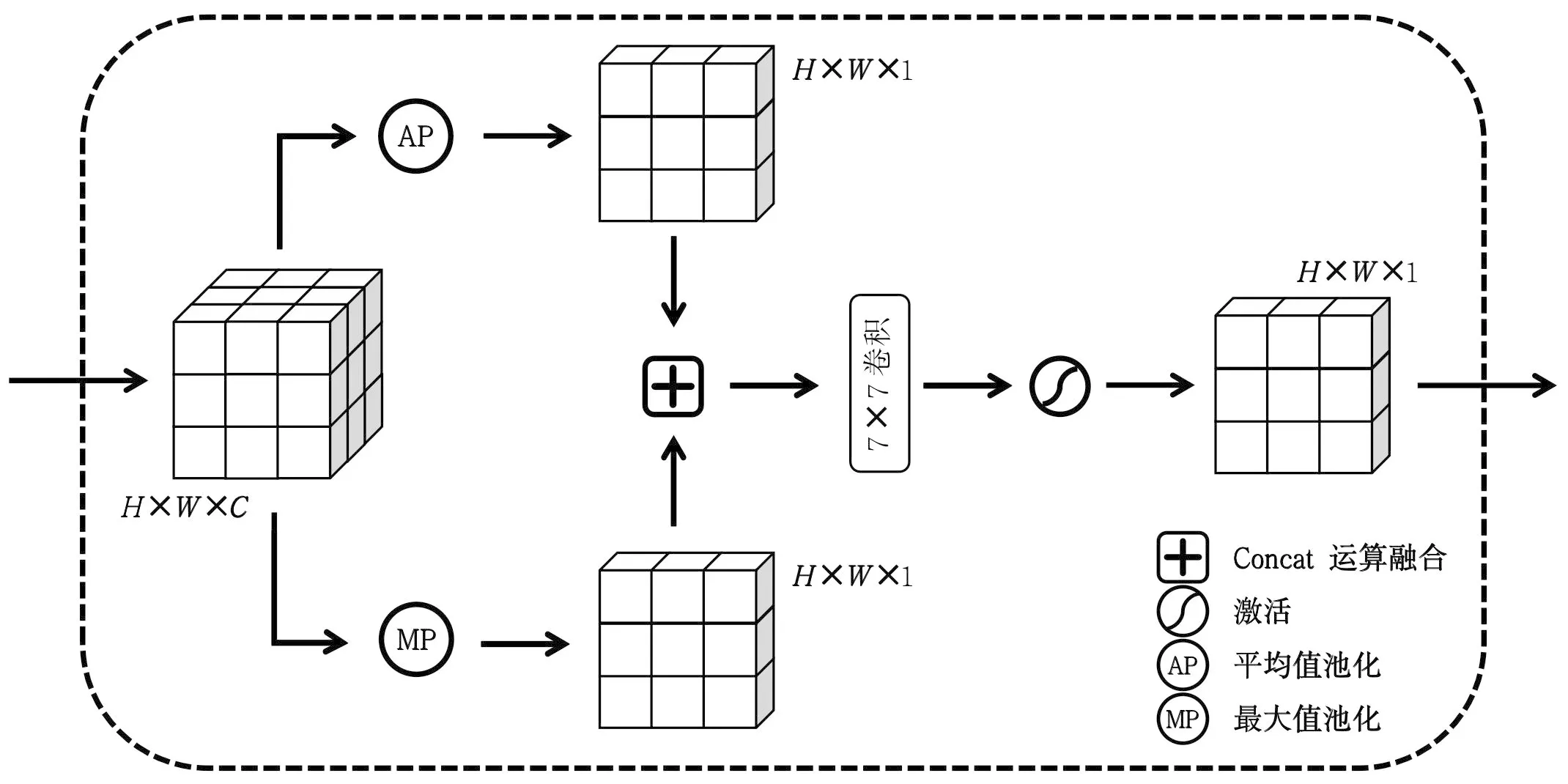
图9 空间注意力结构图Fig.9 Diagram of spatial attention structure
(4)将R3进行批标准化和激活运算,作为整个模块输出。
1.5 损失函数设计
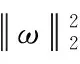
(1)
2 实验过程(Experimentation)
2.1 数据集
如表1所示,本文所使用的数据集分别是:CVC-ClinicDB,Kvasir-SEG,其中CVC-ClinicDB包含612张样本数据,Kvasir-SEG包含1 000张样本数据。将数据集分为8份训练集、1份验证集和1份测试集。训练集用于模型的训练,验证集用来进行模型泛化使用,将得到的预测图与标记图进行比对,得到评价指标得分,量化模型分割效果,测试集用来将得分最高的模型进行泛化,得到预测图。由于不同数据集的尺寸大小不一,所以训练前需要对数据集进行预处理工作,将样本图片尺寸统一以保证训练参数的一致性。
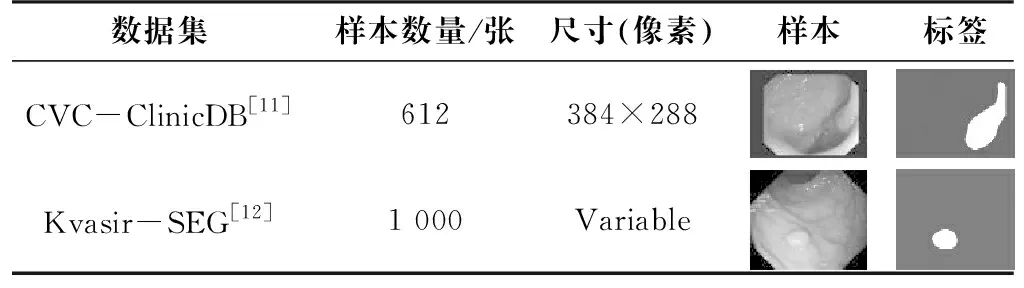
表1 实验数据集的构成Tab.1 The composition of the experimental dataset
2.2 评价指标
本文引入4个分界定义:TP(真阳性),即样本预测为正,标记为正,预测正确;FN(假阴性),即样本预测为负,标记为正,预测错误;FP(假阳性),即样本预测为正,标记为负,预测错误;TN(真阴性),即样本预测为负,标记为负,预测正确。同时,引入了4个评价指标量化检验所用模型的效果,具体的评价指标计算公式如下。
(1)Dice相似系数(Dice Similarity Coefficient):计算预测目标区域与实际目标区域的相似性。Dice公式计算如下:
(2)
(2)平均交并比系数(mIoU):计算预测值和实际值两个集合的交集与并集的比值,结果的交并比系总和取平均值。mIoU公式计算如下,其中k表示类别,k+1表示加上了背景类,i表示真实值。
(3)
(3)准确率(Precision):计算机预测符合要求的正确识别物体的个数占总识别出的物体个数的百分数,准确率相关公式如下:
(4)
(4)正确率(Accuracy):计算机预测正确物体的个数占所有样本个数的百分数,正确率计算公式如下:
(5)
2.3 实验结果
如图10所示,与同类模型相比,本文所提出的模型具有更好的分割效果。在CVC-ClinicDB数据集上,本文实验的mIoU和Dice数值分别为0.903和0.947,Precision为0.933,Accuracy为0.933,对比其他组实验均有更好的效果,在CVC-ClinicDB数据集上不同模型的结果对比如表2所示。

图10 模型在CVC-ClinicDB数据集上的部分分割结果对比图Fig.10 Comparison of partial segmentation results of the model on the CVC-ClinicDB dataset

表2 在CVC-ClinicDB数据集上不同模型的结果对比Tab.2 Comparison of results of different models on the CVC-ClinicDB dataset
在Kvasir-SEG数据集上,本文实验的mIoU和Dice的指标分别为0.763和0.868,Precision为0.857,Accuracy为0.867,均比对比实验组有更好的效果,在Kvasir-SEG数据集上不同模型的结果对比如表3所示。
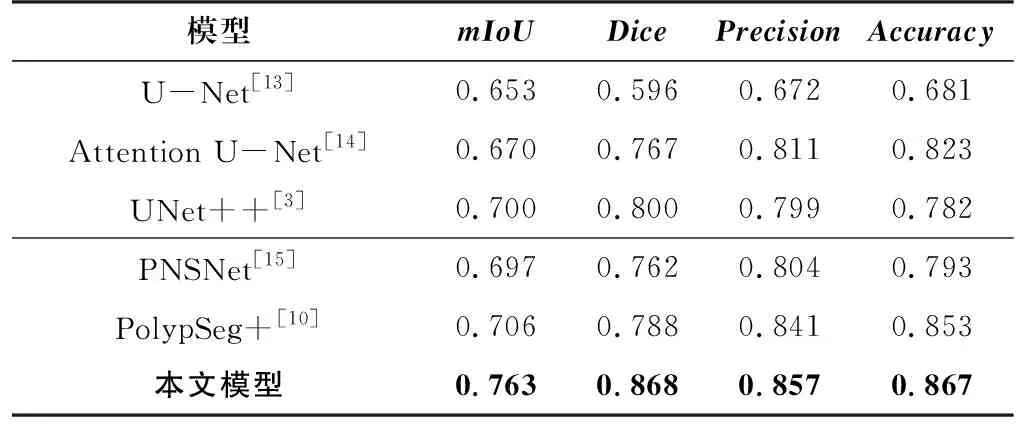
表3 在Kvasir-SEG数据集上不同模型的结果对比Tab.3 Comparison of results of different models on the Kvasir-SEG dataset
2.4 消融实验
为了验证模型结构的合理性,在CVC-ClinicDB数据集上进行消融实验。Baseline为骨干网络;SAA为跳跃轴向注意力模块;ACT为适应联系训练模块;DCG为双通道注意力门控模块。本文设计了8组实验进行评估:①骨干网络;②骨干网络引入SAA模块;③骨干网络引入ACT模块;④骨干网络引入DCG模块;⑤骨干网络引入SAA和ACT模块;⑥骨干网络引入ACT和DCG模块;⑦骨干网络引入SAA和DCG模块;⑧本文模型。不同模块的消融实验结果对比如表4所示,在分别引入了三个模块后对比骨干网络均有显著提升,引入三个模块后,模型取得了较好的实验结果,证明了本文模型结构的合理性。
表4 不同模块的消融实验结果对比Tab.4 Comparison of ablation experimental results of different modules
3 结论(Conclusion)
本文提出了以编码器-解码器结构模型为基础,通过采用1个跳跃连接模块和接入轴向注意力机制,解决了因神经网络的层次加深导致的梯度消失或者梯度爆炸的问题,更好地获取整个图像远近位置的联系。采用适应联系训练,有效地减少了池化过程中空间信息的丢失。采用双通道门控模块,保证了解码过程中空间信息和通道信息的完整性。经过对比实验验证了本文提出模型的效果和可行性。经过消融实验验证了本文结构的合理性。未来,需要丰富更多的数据集验证本文模型的效果,同时对模型进行工程类的嵌入开发,实现标准化输入与标准化输出,实现可以完成批量工业化处理图像的能力。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
昆明医科大学学报(2021年4期)2021-07-23 01:21:56
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
计算机技术与发展(2019年1期)2019-01-21 00:56:38
电子设计工程(2015年16期)2015-02-27 12:07:56
