
基于层次对比学习的半监督节点分类算法
2023-09-28 02:32李雅琪梁吉业
模式识别与人工智能 2023年8期
李雅琪 王 杰 王 锋 梁吉业
近年来,深度学习在很多领域都具有长足的进展[1-2],但是深度学习的成功需要使用大量的标记数据.然而,在许多实际问题中,标记样本的获取是相当困难的,需要耗费巨大的人力、物力和财力,通常无标记样本的数量远大于标记样本的数量.因此,如何使用少量的标记数据结合大量的无标记数据进行训练是机器学习领域广泛关注的问题之一[3].
半监督学习(Semi-Supervised Learning, SSL)[4]是应对上述问题的主流方法之一.SSL能够在没有外界干预的情况下,同时利用少量的标记样本和大量的无标记样本进行学习,改善学习性能.目前,半监督学习方法大致可分为5类:生成式方法[5]、半监督SVM(Semi-Supervised Support Vector Machine)[6]、图半监督学习[7-8]、基于分歧的方法[9]和基于深度学习的方法[10-11].其中,图半监督学习由于其概念清晰、可解释性强且性能优越,受到学者们越来越多的关注.
然而,图半监督学习在标记样本较少时性能退化严重,使用更少的标注代价学习高效的模型是图半监督学习面临的挑战之一.研究者们通过直接增强监督信息和间接增强监督信息的方式缓解标记样本过少的问题.
直接增强监督信息的方法包括标签传播或自训练技术.Zhu等[15]提出基于高斯随机场与调和函数的半监督学习方法,构造相似度矩阵,让每个样本的类标记信息在空间中传播.Sun等[16]提出M3S(Mulit-stage Self-Supervised),基于DeepCluster[17],在每个训练阶段为未标记节点分配伪标记.You等[18]提出Node Clustering,利用节点特征之间的相似性进行聚类,将簇索引作为自监督学习的伪标记,分配给所有节点.Li等[19]训练图卷积神经网络(Graph Convolutional Network, GCN)[20],利用特征提取增强监督信息.但标签传播或自训练技术存在一些缺点,如伪标记错误的累积.尤其是当标记节点特别稀疏时,会引入大量的噪声,影响标记的传播过程.
间接增强监督信息的方法是指通过挖掘数据的分布信息发现潜在规律,从而弥补监督信息的不足.在这方面,图自监督学习通过精心设计的代理任务而不依赖人工标注提取信息,从数据中挖掘自身的监督信息,从而学习到对下游任务有价值的表示[21-23].
图自监督学习方法包括预测式自监督学习方法、生成式自监督学习方法和图对比学习方法(Graph Contrastive Learning, GCL).预测式自监督学习方法将数据中自生成标记作为监督信号进行学习.生成式自监督学习方法将完整的图或子图作为监督信号,用于重构输入数据的特征或结构.图对比学习方法通过区分正对和负对进行训练.其中,图对比学习方法由于具有强大的学习表示性能成为当下研究的热点.
图对比学习通过图数据增强为每个节点生成多视图表示,同一节点生成的节点表示视为正例对,而从不同节点生成的节点表示视为负例对.图对比学习的主要目标是在最大化正例对的一致性的同时最小化负例对的一致性[24].
尽管图对比学习方法已得到广泛研究,但是存在如下不足:1)通过反复试错为每个数据集手动选择数据增强方案;2)引入昂贵的领域特定知识作为指导以获得数据增强;3)大多会改变图语义信息,丢弃一些重要的节点和边,使模型学习对不重要的节点和边缘扰动不敏感[29].因此,图对比方法中保持图的语义,同时减少人工的干预是必要的.
基于上述分析,本文提出基于层次对比学习的半监督节点分类算法(Semi-Supervised Node Classi-fication Algorithm Based on Hierarchical Contrastive Learning, SSC-HCL).不使用图数据增强的方式生成视图,而是将不同层次的图神经网络(Graph Neural Network, GNN)表示作为相关视图进行对比,保留图的语义信息.在此基础上,设计半监督对比损失,结合半监督任务和对比学习,可以有效利用少量标记信息提供监督信息,改进节点表示,进而改善节点分类任务的效果.一方面可以缓解繁琐的搜索,学习更好的节点表示,另一方面可以对不同跳邻居学到的节点表示进行约束,缓解由于数据增强及深度加深带来的语义破坏问题.在4个基准数据集上的实验验证SSC-HCL的优越性.
1 基于层次对比学习的半监督节点分类算法
1.1 图半监督学习问题定义
设G=(V,ε)表示一个无向图,其中,
V={v1,v2,…,vN}
表示N个节点的集合,包括l个标记样本
Dl={(x1,y1),(x2,y2),…,(xl,yl),
yi∈{1,2,…,C}},
C表示样本的类别,和u个无标记样本
Du={(xl+1),(xl+2),…,(xl+u)},
通常,l≪u.ε⊆V×V表示节点之间的边集.X∈RN×F表示节点的特征矩阵,F表示特征维度,Y表示节点的标记矩阵.
A=[aij]∈RN×N
表示节点的邻接矩阵.
D=diag(d1,d2,…,dN)
表示A的度矩阵,
表示顶点i的度.
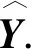
1.2 图神经网络
图神经网络的目标是学习一个编码器
f(X,A)∈RN×F′,
以图的特征和结构作为输入,产生低维的节点嵌入,即F′≪F.GCN的卷积层传播公式为
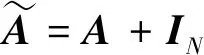
ReLU(·)=max(0,·).
1.3 算法介绍
本文提出基于层次对比学习的半监督节点分类算法(SSC-HCL),框架如图1所示.
SSC-HCL将原始图G=(X,A)的结构和特征作为输入,采用GCN对图进行编码,在学习的过程中,将不同层次上得到的嵌入表示作为不同的视图,用作对比学习.同时,使用半监督对比损失,最大化多个视图上学得表示的一致性,通过迭代优化学习节点的表示.
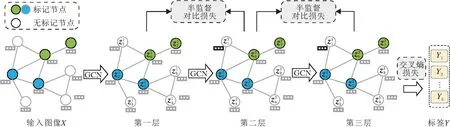
图1 SSC-HCL结构图
具体地,SSC-HCL(以三层为例)通过在图G上应用GCN,得到第1层~第3层视图表示:
其中,
表示归一化邻接矩阵.然后,将层次视图设计为对比视图,以增大正例对的相似性、降低负例对的相似性为目的,改进图的嵌入表示.
半监督对比损失同时利用大量的无标记样本和少量的标记样本,为仅使用无标记样本的对比学习提供丰富的监督信息,帮助模型学习更好的节点表示,进一步提高模型性能.在学习的过程中,使用评分函数衡量节点编码特征的相似度,目标是尽可能地增大同一类别的节点之间的相似度,尽可能地减小不同类别的节点之间的相似度,指导学习过程.半监督对比损失分为两部分:监督对比损失和无监督对比损失.
SSC-HCL的半监督对比损失机制如图2所示.使用xi表示视图中的节点,如果xi为标记节点,xi的正例为与它具有同类的标记节点,负例为与它具有不同类的标记节点,即图2中的紫色箭头和蓝色箭头指向的节点分别表示节点xi的正例和负例.如果xi为无标记节点,xi的正例为另一个视图上它本身,负例为除xi之外的其它节点,即图2中的绿色箭头和红色箭头指向的节点分别表示节点xi的正例和负例.
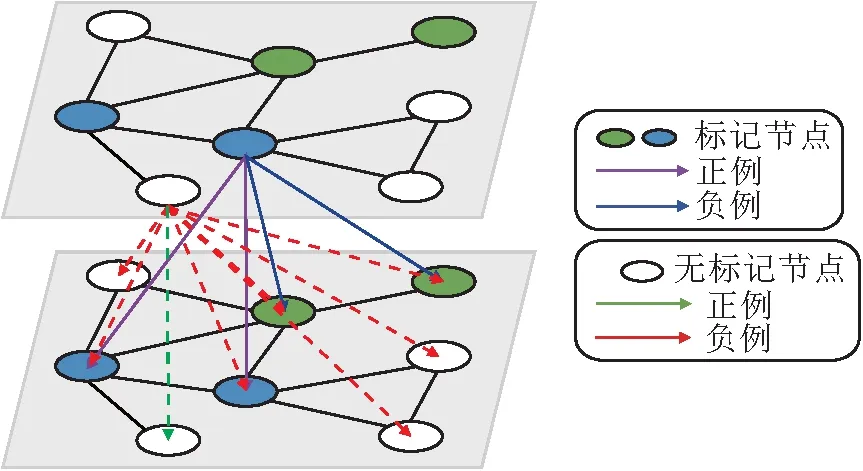
图2 半监督对比损失机制示意图
无监督对比损失表示如下:
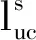
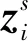
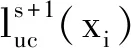
同时,为了充分利用稀缺但有价值的标记样本,使用监督对比损失为学习节点表示提供额外的监督信号.监督对比损失表示如下:
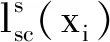
其中,II[·]表示指示函数,在[·]内为真和假时分别取值为1和0.
半监督对比损失结合无监督对比损失和监督对比损失,表示如下:
(1)
使用交叉熵损失衡量网络的实际输出与真实标记之间的差异,即
(2)
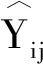
结合半监督对比损失和交叉熵损失,得到整体的网络输出,总体的目标损失函数表示如下:
(3)
其中,λ>0表示半监督对比损失和交叉熵损失之间的相对权重,k表示第s层和第s+1层上的半监督对比损失.
最终,第i个节点的预测函数表示如下:
1.4 算法步骤
SSC-HCL的详细训练过程如算法1所示.
算法1SSC-HCL(以三层为例)
输入特征矩阵X,邻接矩阵A,标记矩阵Y,
迭代次数N
输出未标记节点的标记
初始化随机初始化模型参数
Forepoch=1 toNdo
通过GCN得到第1层的嵌入表示Z1
通过GCN得到第2层的嵌入表示Z2
通过GCN得到第3层的嵌入表示Z3
由式(2)计算交叉熵损失lce
由式(3)计算总体目标损失l
根据梯度下降方法,更新参数l
End for
预测未标记节点的标记
2 实验及结果分析
2.1 实验数据集与实验设置
为了验证本文算法的有效性,在Cora[33]、CiteSeer[33]、PubMed[33]、Amazon Photo[34]这4个基准数据集上进行实验,数据集信息如表1所示.Cora、CiteSeer、PubMed为引文网络数据集,节点表示文档,边表示文档之间的引用关系,每个文档都由一个词袋向量表示相应的词存在或不存在.Amazon Photo数据集是亚马逊产品联合购买数据集,节点表示商品,边表示两种商品经常被同时购买,节点特征表示产品评论,类别标签由产品的类别给出.
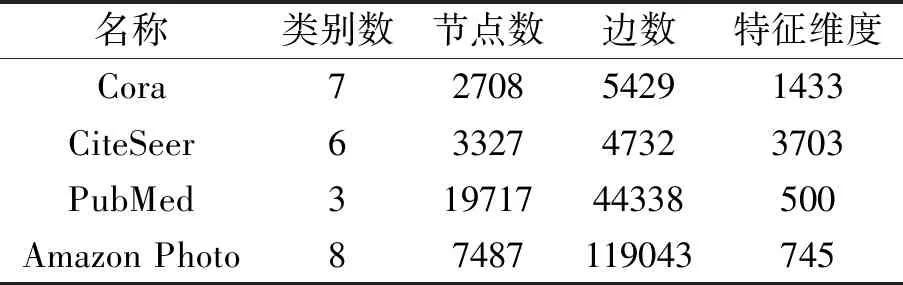
表1 实验数据集信息
在Cora、CiteSeer、PubMed数据集上,本文使用与Yang等[35]相同的训练集、验证集、测试集划分方式,即每类随机抽取20个节点作为标记数据进行训练,500个节点用于验证,1 000个节点用于测试.在Amazon Photo数据集上,每类随机抽取30个节点作为标记数据进行训练,随机抽取30个节点用于验证,其余节点用于测试.
2.2 基线方法
本文选择如下对比方法.
1)DeepWalk[12].基于图嵌入的方法,通过随机游走学习节点的嵌入表示.
2)Chebyshev[13].基于图卷积的方法,把CNN扩展到非欧数据上.
3)GATs[14].使用注意力机制学习邻居节点的权重,对邻居节点的特征加权求和,为不同的节点分配不同的权重.
4)文献[15]方法.传统的基于图的半监督学习方法,通过节点之间的边传播标签,将标签分配给未标记节点.
5)GCN[20].对图数据进行操作的经典的图卷积神经网络.
6)DGI[25].最大化图局部和全局的互信息,学习节点表示.
7)文献[26]方法.最大化图的多视图编码表示之间的互信息,学习节点表示.
8)GMI[27].对比输入图和每个节点的隐藏表示之间的相关性,学习节点表示.
9)GRACE[28].利用节点级对比目标的无监督图表示学习框架.
2.3 实验结果
本节计算各方法10次运行的平均分类准确率以评估性能.各方法在4个数据集上的结果如表2所示,表中黑体数字表示最优值.由表可见,SSC-HCL优于对比方法,在Cora、CiteSeer、PubMed、Amazon Photo数据集上与次佳方法的分类准确率相比,分别提升0.8%、0.6%、0.5%和1.2%.因此可以看出,利用不同层次进行对比学习,能够更好地保留图的节点特征和拓扑信息,学得更好的表示,从而验证SSC-HCL的有效性.
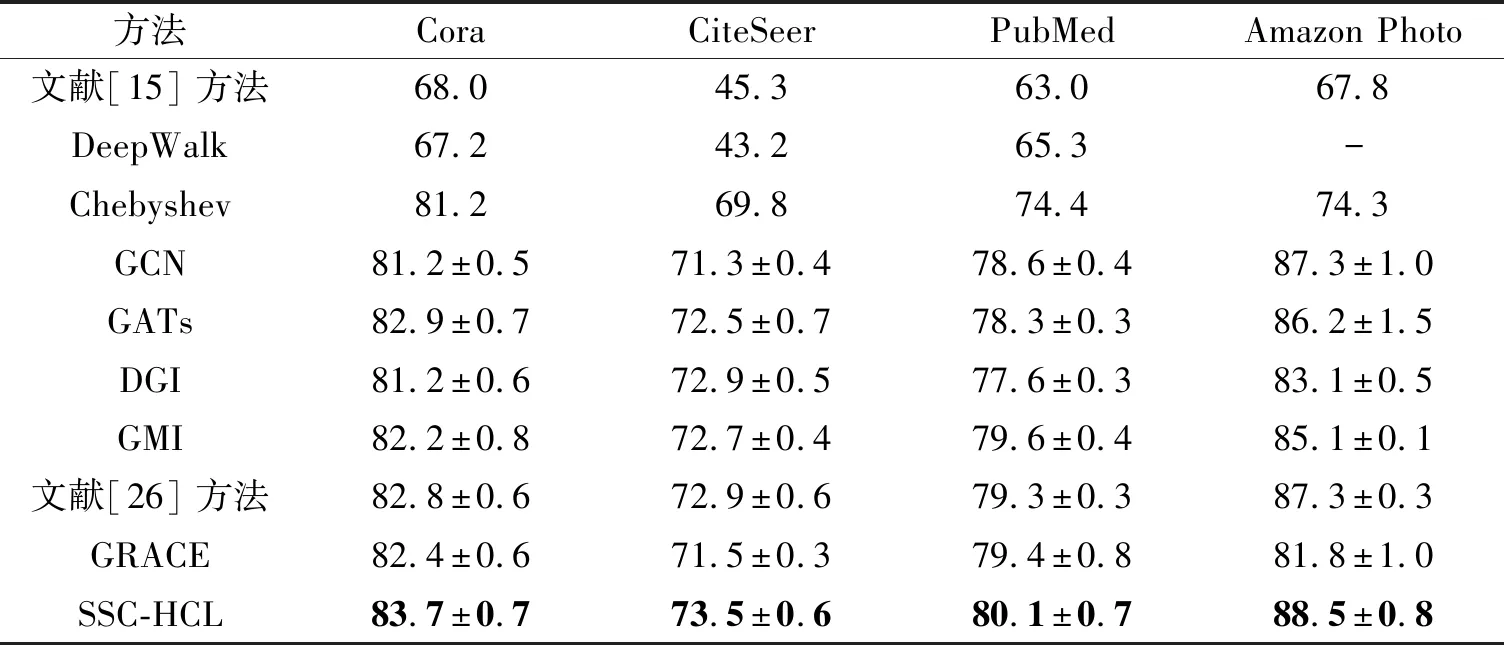
表2 各方法在4个数据集上的分类准确率对比
为了进一步分析模型深度对分类准确率的影响,改变模型中编码器的卷积层数,设置隐藏层维度为128.SSC-HCL和GCN在不同层数上的分类准确率如图3所示.
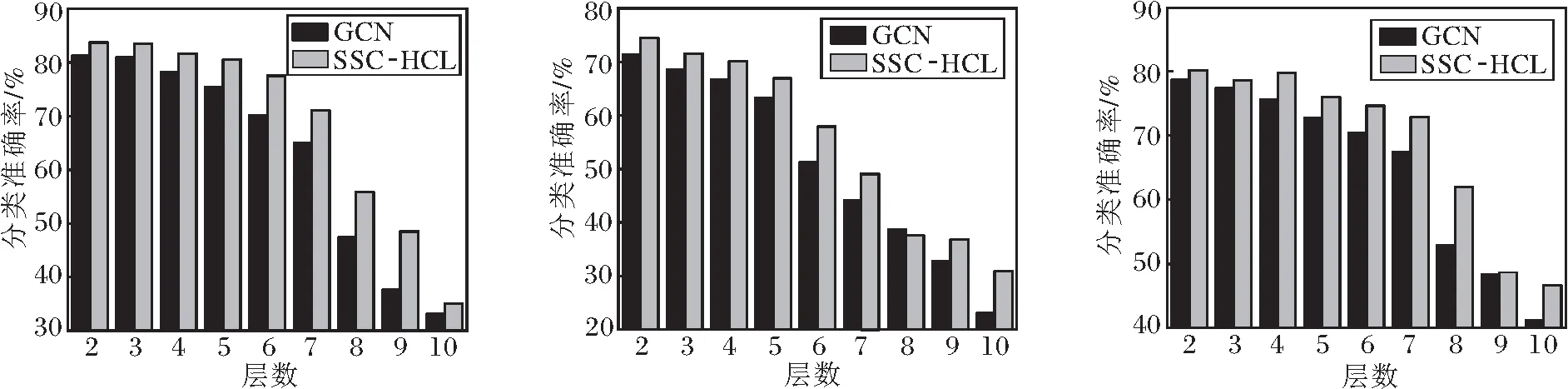
(a)Cora (b)CiteSeer (c)PubMed
由图3可以看出,两层GCN编码器的性能最佳,随着层数的不断增加,性能下降,多卷积层可能产生从较远的邻域聚合信息的噪声,从而降低节点表示的质量和下游节点分类任务的性能.尽管GCN和SSC-HCL的性能都有一定下降,但SSC-HCL在不同深度下的性能大幅优于GCN.
此外,进一步研究不同标记数量对方法性能的影响.对于每个数据集,为每类抽取n个标记样本进行实验,n=10,15,20,25,30.GCN、DGI、文献[26]方法、GRACE、SSC-HCL在Cora、CiteSeer、PubMed数据集上的分类准确率如表3~表5所示,表中黑体数字表示最优值.
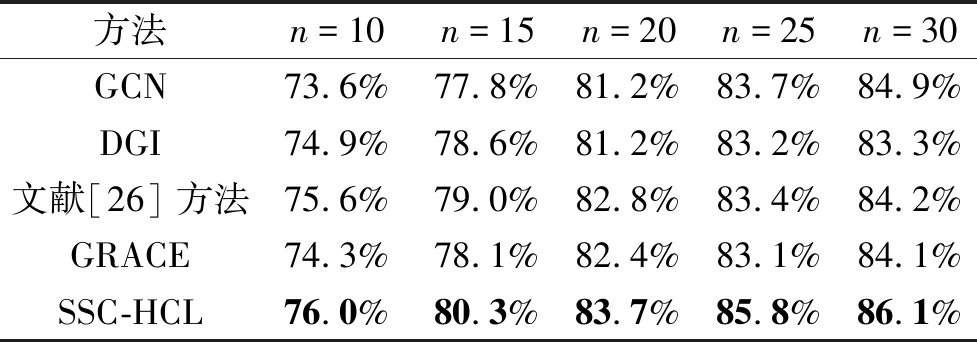
表3 各方法在Cora数据集上不同标记数量下的分类准确率
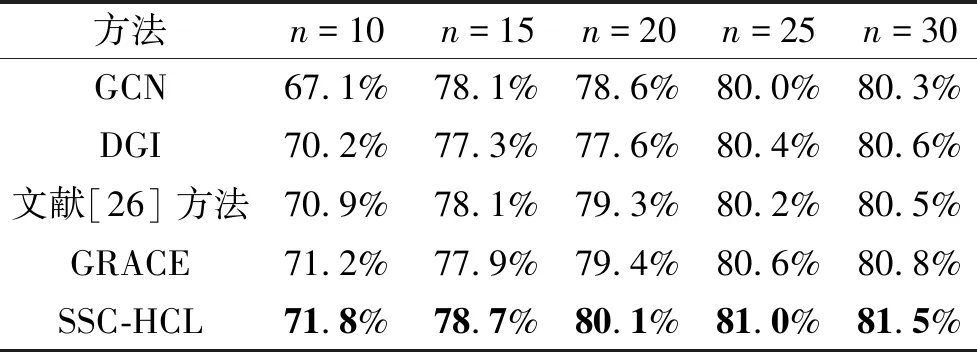
表5 各方法在PubMed数据集上不同标记数量下的分类准确率
由表3~表5可以看出,随着标记数量的增加,性能随之上升,这一结果表明,样本的标记数量与方法性能相关,标记数量越高,分类准确率越高.在3个引文网络数据集上的实验结果表明,SSC-HCL在不同标记数量上的分类准确率均最优.
为了提供更直观地说明,在Cora数据集上,给出SSC-HCL、DGI、GMI学得的节点嵌入表示的t-SNE[36]可视化结果,具体如图4所示,图中不同颜色表示不同类别.由图可观察得出,SSC-HCL得到的子簇内较紧凑,子簇间界限较明显,不同颜色的子簇间重叠较少.DGI得到的红色子簇和绿色子簇之间重叠部分较多,且属于同类的黑色子簇之间的距离较远.GMI得到的橙色子簇和黑色子簇之间重叠于左上方,且属于同类的黑色子簇之间的距离较远.结果表明,SSC-HCL能够得到良好的节点嵌入表示.
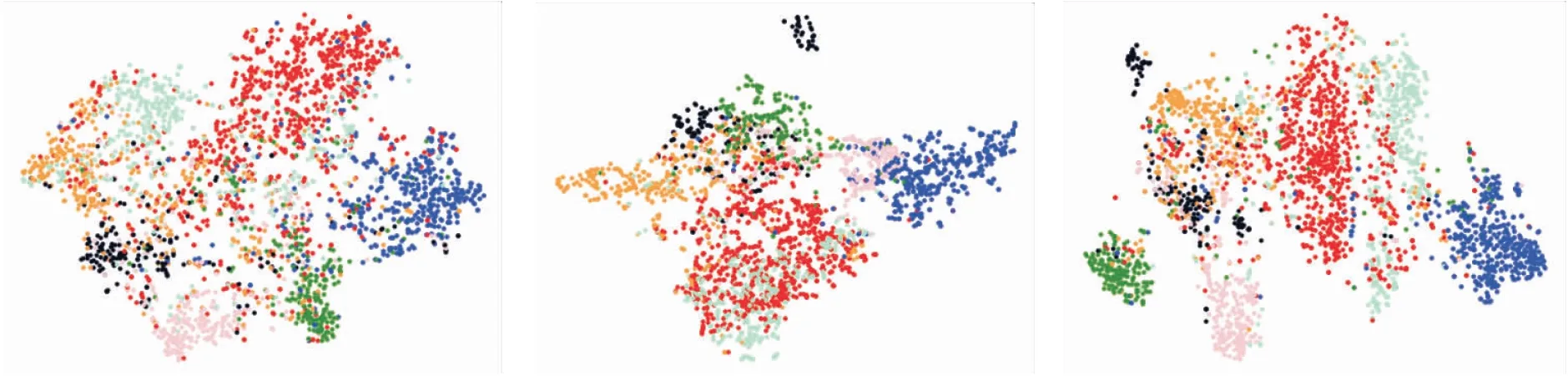
(a)SSC-HCL (b)DGI (c)GMI
3 结 束 语
本文提出基于层次对比学习的半监督节点分类算法(SSC-HCL).利用GCN的不同层次作为视图进行对比学习,不需要通过图数据增强得到视图,从而有效缓解通过繁琐复杂的试错选择数据增强方法的问题,并且对不同跳邻居学到的节点表示进行约束,缓解图数据增强以及深度加深对图语义信息造成的破坏.此外,设计半监督对比损失,有效利用大量的无标记样本和少量的标记样本,提供丰富的监督信息.在4个基准数据集上的实验表明SSC-HCL在节点分类任务上的有效性.今后考虑研究动态环境下的图对比学习,学习图结构中的丰富特征.
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
今日农业(2019年15期)2019-01-03
数学物理学报(2017年5期)2017-11-23
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
