
双分支多粒度局部对齐的实例级草图图像检索
2023-09-28 02:22韩雪昆苗夺谦张红云张齐贤
模式识别与人工智能 2023年8期
韩雪昆 苗夺谦 张红云 张齐贤
文本-图像检索(Text Based Image Retrieval, TBIR)是目前常用的检索方法之一.但是,文本包含的信息相对有限,因此学者们开始探究图像-图像检索方式.
相比文本,图像能够包含更多的信息.随着触屏设备的发展,学者们逐渐关注草图相关的研究,包括草图识别[1-3]、草图重构[4-6]及草图-图像检索(Sketch-Based Image Retrieval, SBIR)[7].草图携带信息的能力介于文本和真实图像之间.相比真实图像,草图更容易获取,也更能反映用户的想法.对于搜索引擎或者网络购物应用来说,通过草图搜索用户需要的内容是一个更好的选择.
草图-图像检索分为粗粒度的类别级草图-图像检索(Category Level SBIR, CL-SBIR)和实例级草图-图像检索(Instance Level SBIR, IL-SBIR),实例级草图-图像检索又称为细粒度草图-图像检索(Fine Grained SBIR, FG-SBIR).
类别级草图-图像检索只需找出和输入草图属于同类的图像,实例级草图-图像检索需要找出和输入草图姿态、细节完全对应的图像.相比传统的基于内容的图像检索,实例级草图-图像检索主要面临如下问题.1)目前常用数据集包含数据量较少.2)草图本身具有稀疏性和高度抽象性,传统图像处理方法很难直接用于草图.3)草图和真实图像之间的模态差异过大,草图不具备真实图像包含的纹理、颜色等信息,导致检索时判别信息不足.同时,真实图像中背景信息的干扰使该任务更加困难.
早期的实例级草图-图像检索采用手工提取特征,并通过RankSVM(Ranking Support Vector Ma-chine)进行检索.Yu等[8]提取真实图像的边缘图,利用Image-Net预训练的Sketch-a-Net作为特征提取网络,分别提取草图特征和真实图像特征.Song等[9]在Deep Spatial-Semantic Attention中将注意力机制引入草图图像检索,利用直连方法结合深层特征和浅层特征,从而避免卷积过程中细节信息的丢失,并引入HOLEF(Higher-Order Learnable Energy Function),解决空间不对齐问题.Lin等[10]认为利用边缘图代替真实图像更耗时,并且边缘图的质量在很大程度上影响检索精度,因此提出TC-Net(Triplet Classification Network),直接提取草图特征和真实图像特征,在使用三元组损失的同时,还引入多种分类损失,提高检索精度.Xu等[11]认为局部特征对于实例级草图-图像检索非常重要,提出LA-Net(Local Aligned Network),计算不同模态局部特征间的距离后加和,从而得到草图和真实图像的距离.同时,Xu等[11]又提出DLA-Net(Dynamic LA-Net),采用动态局部对齐方法解决局部特征不对齐问题.此后,Sun等[12]提出DLI-Net(Dual Local Interaction Network),在DLA-Net的基础上加入自交互模块,去除空白区域,加快检索速度.Ling等[13]提出MLRM(Multi-level Region Matching),首先通过DRE(Discrimina-tive Region Extraction Module)从不同层次和不同区域提取特征,然后采用RLA(Region and Level Attention Module)学习注意力权重,探索不同区域和不同层次的贡献.Bhunia等[14]提出Noise-Tolerant FG-SBIR,通过强化学习去除噪声笔画,在输入草图质量较差的情况下进行准确检索.
由于草图-图像检索数据集稀缺,上述方法都是采用Image-Net预训练的网络作为骨干网络.为了摆脱预训练的束缚,还有一些方法[15-17]利用诸如草图复原、拼图等任务,使模型获得提取草图特征和真实图像特征的能力,或是联合训练图像-草图生成模型和检索模型,从而解决数据稀缺的问题.
上述方法在提取草图特征和真实图像特征之后,大多利用全局特征计算草图和图像间的相似度,但对于实例级草图-图像检索而言,局部信息更重要.DLA-Net提取局部特征并考虑特征不对齐问题,然而草图和真实图像之间的不对齐还包括局部特征大小不匹配,只考虑单一粒度的特征无法解决特征大小不匹配问题.
草图-图像检索本质上是一个跨模态检索任务.跨模态任务的主要问题之一是如何减小不同模态间的域差异.Ye等[18-19]提出TONE(Two-Stream Convolutional Neural Network)和HCML(Hierarchical Cross-Modality Metric Learning),利用双流特征提取器提取不同模态间共享特征,并提出双向双约束排序损失.Zhang等[20]采用生成对抗的方式,使提取到的共享特征更纯粹.Lu等[21]认为除了共享特征,特异特征同样对跨模态检索起到重要作用,在使用共享特征的同时,通过建模模态内和模态间的相似度并根据近邻关系传递特异特征,在学习共享特征和特异特征时,还加入对抗学习等方式,确保共享分支和特异分支提取相应的特征,从而提高检索精度.
现有的草图-图像检索工作大多通过共享参数或不共享参数的两个网络提取草图特征和图像特征,利用三元组损失拉近同一物体特征距离,并使不同物体特征距离增大,找出和草图距离最近的图像作为检索结果.
然而,草图和图像之间的模态差异过大,导致同一物体不同模态特征之间的距离大于不同物体特征之间的距离,进而导致检索错误.
基于上述分析.本文提出双分支多粒度局部对齐网络(Two Stream Multi-granularity Local Alignment Network, TSMLA),着重解决草图和图像模态差异过大的问题以及空间不对齐问题.采用双分支特征提取器(Two Stream Feature Extractor, TSFE)提取草图和图像的共享特征,解决草图和图像模态差异过大的问题,并且同时利用共享特征和特异特征约束模型训练.采用多粒度局部对齐模块(Multi-granu-larity Local Alignment Module, MLA),在不同粒度上进行局部特征之间的对齐,大幅减轻位置不对齐和特征大小不一致问题,进一步提升网络性能.在多个不同的数据集上的实验表明TSMLA的有效性.
1 双分支多粒度局部对齐网络
1.1 问题描述
对于FG-SBIR任务,给定一个草图,希望能够找到和它的姿态及细节完全对应的图像.网络以三元组(s,p+,p-)作为输入,s表示草图,p+表示和草图对应的图像,p-表示和草图不对应的图像.
首先将(s,p+,p-)三元组送入特征提取器,获得草图特征、正样本特征和负样本特征.这些特征用于计算草图和真实图像之间的距离,最终计算三元组损失:
L(s,p+,p-)=max(0,δ+d(s,p+)-d(s,p-)),
其中,d(s,p+)表示草图和正例的距离,d(s,p-)表示草图和负例的距离,δ表示人为设置的常量,防止模型过快收敛.
TSMLA的整体结构如图1所示,草图和正负样本被成对送入双分支特征提取器中,提取模态共享特征和模态特异特征,利用共享特征和特异特征分别计算距离矩阵,对距离矩阵进行多粒度局部对齐后计算三元组损失.
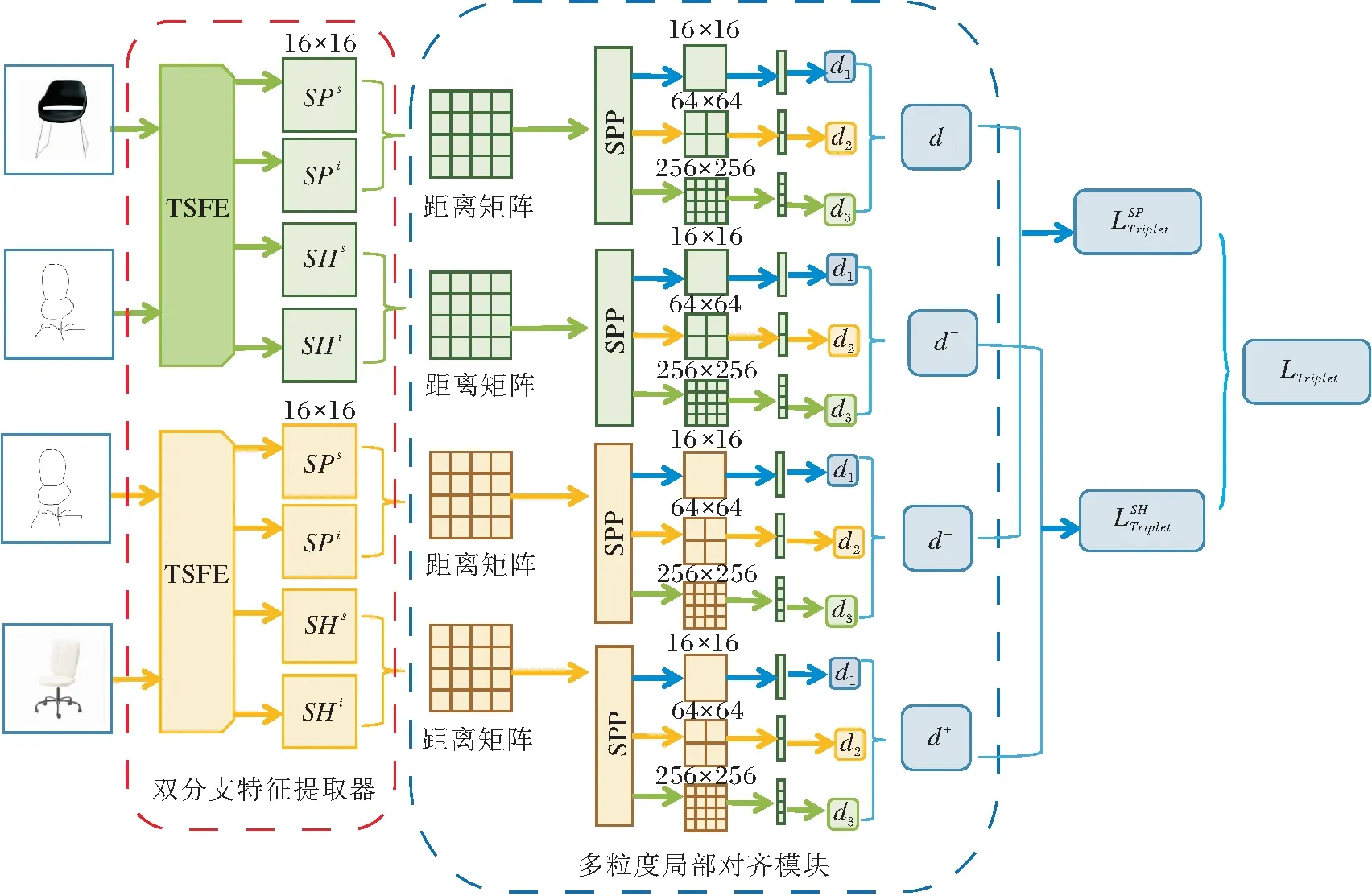
图1 TSMLA整体结构
1.2 双分支特征提取器
FG-SBIR需要提取草图特征和真实图像特征.在早期工作中,由于使用边缘图替换真实图像,真实图像和草图间的模态差异较小,因此使用孪生网络提取特征,效果较优.TC-Net及之后的工作直接将真实图像作为输入,模态差异较大,使用异构网络提取草图特征和真实图像特征,效果更优.
然而,草图和真实图像之间模态差异过于明显.真实图像中包含的纹理、颜色、背景等信息,在草图中都不存在.
受其它跨模态检索方法的启发,TSMLA在实例级草图-图像检索任务中引入双分支特征提取器(TSFE),提取共享特征和特异特征.模态共享特征是指草图特征和真实图像特征都包含的特征.而特异特征指某一模态特有的特征,如真实图像中的纹理信息、颜色信息等.
TSFE结构图如图2所示.TSFE包含共享特征分支和特异特征分支.特征提取器以草图S和真实图像P作为输入,共享分支和特异分支都利用Image-Net预训练的ResNet-50提取特征,并且两个分支不共享参数.
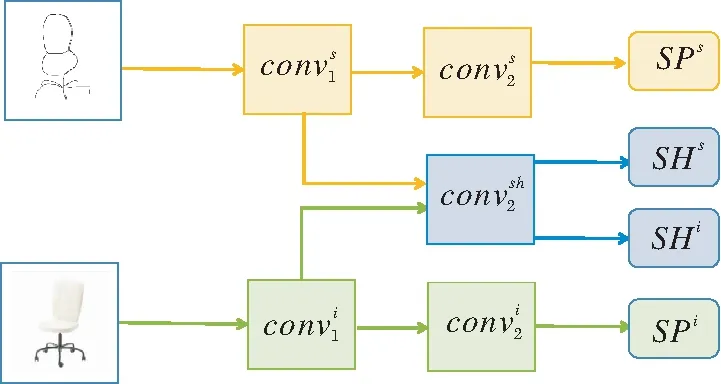
图2 TSFE结构图
Xu等[11]认为在特征提取的过程中,深层特征的语义表达能力更强,但是会丢失细节信息,因此更适合图像识别及分类任务,而浅层信息语义表达能力较弱,但携带的细节信息更多,更适合实例级草图-图像检索任务.参考其做法,TSFE去掉ResNet最后的卷积块,将ResNet50的前两个卷积块作为Conv1,将第3个卷积块作为Conv2.特异分支的Conv1的输出分别送入共享分支和特异分支的Conv2,从而得到共享特征和特异局部特征.从草图和真实图像中提取的特异特征如下所示:
其中,S表示输入草图,P表示输入的真实图像.从草图和真实图像中提取的共享特征如下所示:
得到的共享和特异的草图和真实图像局部特征使用多粒度局部对齐模块进行特征对齐.
1.3 多粒度局部对齐模块
在获得模态共享和模态特异的局部特征之后,分别使用这两种局部特征计算草图和真实图像之间的距离.最简单的方法是认为相同位置的局部特征是对齐的,利用每个成对的局部特征计算距离后求和,这要求草图和真实图像严格对齐.然而,草图是抽象的,并且不同的人对于同个物体有不同的画法,很难做到严格对齐.
为了解决空间不对齐问题,学者们大多采用动态对齐策略,将局部特征和另一模态下所有的局部特征进行对比,距离最小的两个局部特征即为对齐的.
但特征不对齐不仅仅是特征位置上的不对齐,还包括局部特征大小不匹配,如图3中右下方阴影部分所示.此外,在草图中一个局部特征代表的部分在真实图像中可能同时属于两个局部特征.如图3所示,草图中左上方阴影部分表示的特征在真实图像中属于两个不同部分.这些问题导致特征对齐过程中的错误匹配,最终导致检索错误.
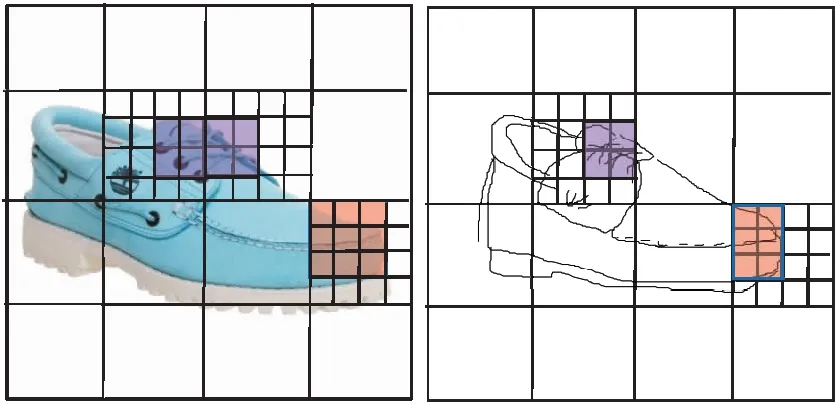
图3 特征大小不匹配示例
为了解决这些问题,本文采用多粒度局部对齐模块(MLA),在不同粒度上进行局部特征对齐.此前大多数类似的方法或是获取不同卷积层的输出从而获得不同大小的特征,或是对特征使用空间金字塔池化(Spatial Pyramid Pooling, SPP).然而FG-SBIR对于局部特征具有依赖性,使用不同卷积层特征无法利用局部特征.对特征进行池化则会导致细节信息的丢失,性能下降.
因此本文选择对使用局部特征计算得到的距离矩阵进行池化操作,即
TSFE提取到的草图和真实图像特征大小为C×16×16,C为通道数,特征矩阵中每个C×1×1的部分SP(x,y)表示一个图像块的特异特征,SH(x,y)表示一个图像块的共享特征,矩阵平铺得到的C×256的向量可以看成256个图像块的特征.dj,k表示草图第j块的特征和真实图像第k块的特征计算得到的距离,j=1,2,…,256,对于j的每个取值,同样k=1,2,…,256,即对每个草图块,计算它和真实图像所有块之间的距离,得到256×256的距离矩阵D.参考DLI-Net[12],这里选择欧氏范数计算特征间的距离.
为了在不同粒度上进行特征对齐,将该矩阵变形为256×16×16的矩阵,对这256个16×16的距离矩阵分别进行不同粒度的平均池化,在每个粒度下各得到256个距离矩阵,将256个距离矩阵组成的三维矩阵重新变为二维矩阵后,就完成矩阵D列方向上的多粒度池化.对池化后的矩阵D在行方向上进行同样的操作.这样,完成对距离矩阵D的多粒度池化操作,得到不同大小的距离矩阵.矩阵大小m越大,距离矩阵中每个距离度量的图像块越小,信息粒度越细,感受野越小,进行特征对齐时越会出现图像局部大小不匹配的问题;m越小,距离矩阵中每个距离度量的图像块越大,信息粒度越粗糙,但感受野越大,能够在一定程度上解决图像局部大小不匹配的问题.
对D进行池化后得到大小为m×m的距离矩阵:
Dm×m=Averagem(D).
然后,利用池化得到距离矩阵进行动态局部对齐,对于Dm×m的每行Dj,使用这行中的最小值代替它,即认为特征距离最小的两个块是对齐的,具体公式如下:
Dj=min(dj,1,dj,2,…,dj,m),
其中,dj,k为Dm×m第j行第k列的元素,表示草图第j个块的特征和真实图像中第k个块的特征的距离,m表示距离矩阵的大小.
使用这个最小距离表示草图的一个局部和真实图像对应部分的距离,得到大小为m×1的向量.在不同大小的距离矩阵上进行动态局部对齐,更准确地寻找相互对应的局部特征.
利用每个草图局部特征和其对应部分的距离计算草图和真实图像的距离.参照DLI-Net[12],这里使用欧氏范数计算距离,即
最后,将使用不同大小的距离矩阵计算得到的草图和图像之间的距离相加,用于结合不同粒度的信息.结合不同粒度的信息,既能有效利用细节信息,又能在一定程度上解决大小不匹配的问题,即
MLA的做法是符合人类的习惯的.在判断一幅图像和草图是否对应时,首先整体上看二者是否相似,然后逐步对比二者的细节是否对应.
1.4 损失函数
通过MLA,可以得到使用共享特征计算得到的距离dsh和使用特异特征计算得到的距离dsp.特征提取器包含共享和特异两个分支,提取共享特征和特异特征,共享特征不一定都是对检索有帮助的,而特异特征也不都是没用的,如果只使用共享特征计算三元组损失,会导致模态特异信息的丢失.在其它使用双分支的跨模态检索方法中,往往使用分类损失约束特异分支.然而,由于数据集的稀缺,每个物品只有一幅真实图像和少数草图,不适合使用分类损失.所以,本文同时使用共享特征和特异特征计算三元组损失:
L=αmax(0,δ+dsp(s,p+)-dsp(s,p-))+
βmax(0,δ+dsh(s,p+)-dsh(s,p-)),
(1)
其中α、β为提前设置的参数.
2 实验及结果分析
2.1 实验数据集
目前常用的FG-SBIR数据集有如下5个:QMUL-ChairV1、QMUL-ShoeV1、QMUL-ChairV2、Q-MUL-ShoeV2、Sketchy数据集[22].本文在这5个数据集上进行实验.
QMUL-ShoeV1数据集包含419个草图-图像对,QMUL-ChairV1数据集包含297个草图-图像对.使用QMUL-Shoev1数据集上300个草图-图像对和QMUL-ChairV1数据集上204个草图-图像对作为训练集,其余的作为测试集.
QMUL-ChairV2、QMUL-ShoeV2数据集分别是QMUL-ChairV1、QMUL-ShoeV1数据集的扩展版本.QMUL-ChairV2数据集包含400幅椅子照片和1 275幅草图,QMUL-ShoeV2数据集包含2 000幅鞋的照片和6 730幅草图,每幅照片都有至少三幅对应的草图.参照其它工作的做法,在QMUL-ChairV2数据集上选择300幅图像及其对应的草图作为训练集,在QMUL-ShoeV2数据集上选择1 800幅照片及其对应草图作为训练集,其余的作为测试集.
Sketchy数据集包含12 500幅真实图像和74 425幅草图,这些图像属于125个不同类别,每个类别包含100幅图像和其对应草图.与其它4个数据集不同,Sketchy数据集上的真实图像包含背景.因此在Sketchy数据集上的检索更加困难.参考其它方法,在每类中挑选90%的图像和对应草图作为训练集,其余的作为测试集.
2.2 实验设置
实验在RTX 3090 GPU上使用PyTorch完成.将草图扩展至3个通道,并将草图和真实图像一起作为输入.在训练过程中,草图和真实图像都重新调整为288×288,并裁剪到255×255.在测试过程中,输入图像直接被调整为255×255.
TSMLA使用Res-Net-50提取特征.在式(1)中,α和β都设置为1.在使用Chair-V2数据集训练模型时,δ设置为0.3,在使用其它数据集训练时,δ设置为0.1.
在实现多粒度对齐模块时,将大小为256×256的距离矩阵进行平均池化,得到大小为64×64和16×16的距离矩阵,并使用这3种大小的距离矩阵进行动态对齐.
网络使用Adam(Adaptive Moment Estimation)优化,在Sketchy数据集上训练300个迭代周期,学习率设置为0.000 01,在其它数据集上使用0.000 1的学习率训练100个迭代周期.
给出一幅输入草图,将所有图像按照和草图距离从小到大排序,acc@k表示正例在前k个图像的次数与总的测试图像数量的对比值.本文选择acc@1作为评价指标.
2.3 实验结果
为了验证网络的有效性,选择如下对比网络:文献[8]网络、文献[9]网络、TC-Net[10]、LA-Net[11]、DLA-Net[11]、DLI-Net[12]、MLRM[13]、Noise-Tolerant
SBIR[14].
各网络的acc@1值对比结果如表1所示,表中黑体数字表示最优值.由表可以看到,TSMLA在多个数据集上性能都有一定的提升.在QMUL-ShoeV1数据集上acc@1提升2.61%,在QMUL-ChairV2数据集上acc@1提升4.51%,在QMUL-ShoeV2数据集上acc@1提升3.52%.尽管在QMUL-ChairV1数据集上acc@1有所下降,但是QMUL-ChairV1数据集是一个非常小的数据集且模型准确率接近100%,提高模型复杂度不一定能在其上获得更优结果.
值得注意的是,DLI-Net在Sketchy数据集上实验时去除数据集上部分不可用的数据,本节并没有这么做.在相同的实验设置下,DLI-Net在Sketchy数据集上的acc@1为59.32%,检索精度仍有所提升.
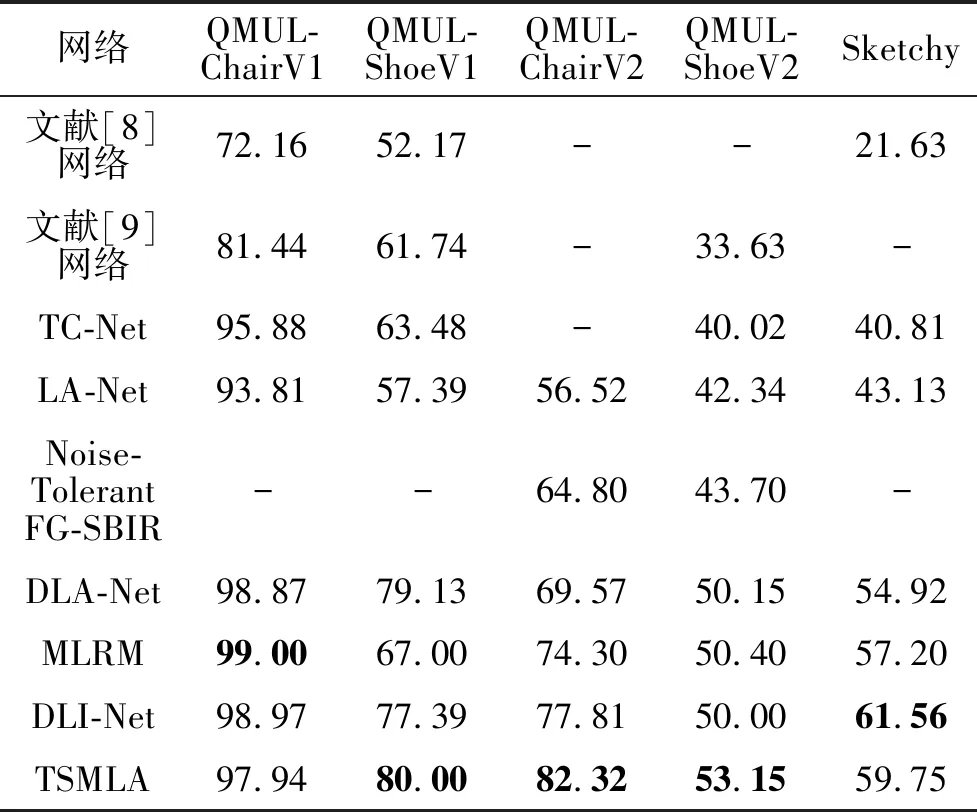
表1 各网络在5个数据集上的acc@1值对比
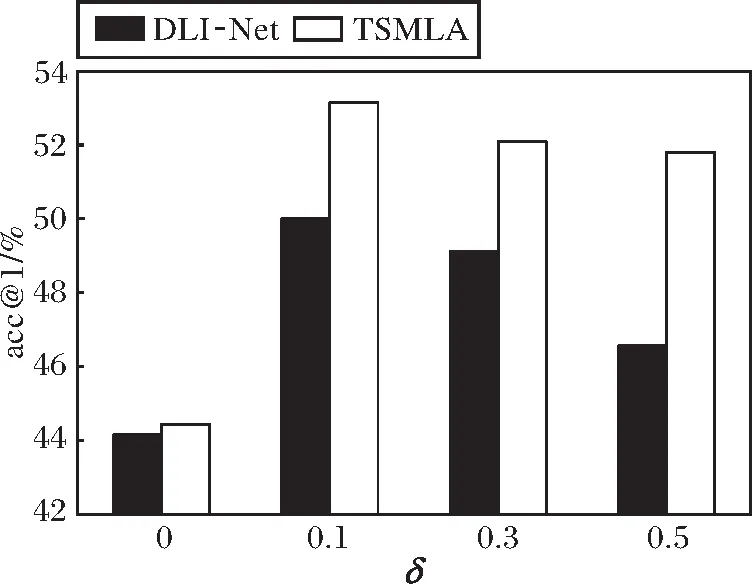
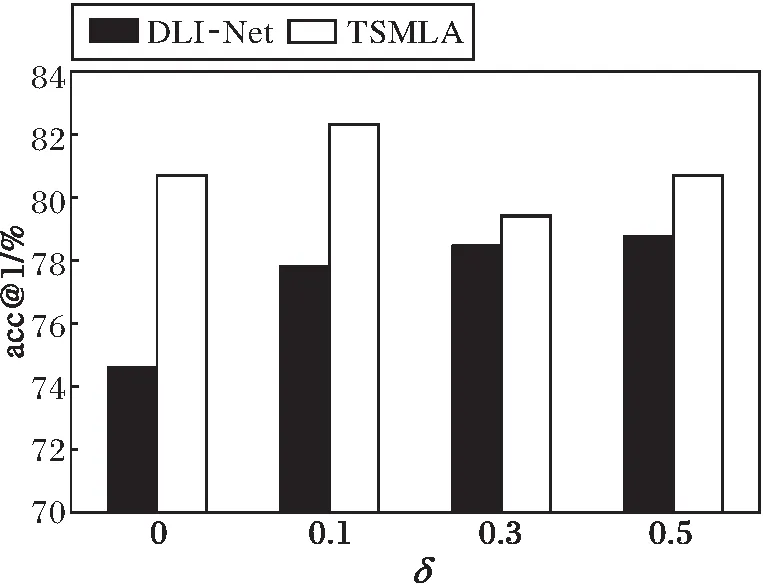
此外,在δ=0,0.1,0.3,0.5时对比TSMLA和DLI-Net,在QMUL-ShoeV2、QMUL-ChairV2数据集上的acc@1如图4所示.
(a)QMUL-ShoeV2
(b)QMUL-ChairV2
δ是三元组损失中设置的常量,用于减小草图和正例的距离,同时增大草图和负例的距离.δ太大会导致网络很难收敛,δ太小会导致网络鉴别能力下降,因此δ的变化会产生一定程度的性能波动.由图4可以看出,δ=0,0.1,0.3,0.5时,虽然DLI-Net和TSMLA的性能都有一些起伏,但是TSMLA的acc@1都高于DLI-Net.
在相同输入情况下,Noise-Tolerant FG-SBIR[14]、DLI-Net[12]和TSMLA在3个样本上的检索可视化结果如图5所示.由图可以看出,由于充分利用草图特征和真实图像特征,TSMLA能够准确找出正确结果.尽管Noise-Tolerant FG-SBIR在样本1和样本3中能够找出正确结果,DL1在样本2和样本3中能够找出正确结果,但两者找出的其它候选图像和正确结果并不相似,而TSMLA找出的候选图像大多和正确结果相似,说明其判别能力更强.

(a1)Noise-Tolerant FG-SBIR

(a2)DLI

(a3)TSMLA

(b1)Noise-Tolerant FG-SBIR

(b2)DLI

(b3)TSMLA

(c1)Noise-Tolerant FG-SBIR

(c2)DLI

(c3)TSMLA
下面在QMUL-ChairV2、QMUL-ShoeV2数据集上进行消融实验,验证TSFE和MLA的有效性.在DLI-Net上加入不同模块后的acc@1值如表2所示.由表可以看出,在DLI-Net上加入TSFE后,在QMUL-ChairV2数据集上acc@1提升2.30%,在QMUL-ShoeV2数据集上acc@1提升2.55%.在DLI-Net上加入MLA后,在QMUL-ChairV2数据集上acc@1提升2.32%,在QMUL-ShoeV2数据集上acc@1提升2.21%.在DLI-Net上同时加入TSFE和MLA后,在QMUL-ChairV2数据集上acc@1提升4.51%,在QMUL-ShoeV2数据集上acc@1提升3.52%.由此可见,在DLI-Net上添加模块,性能都会出现一定提升.
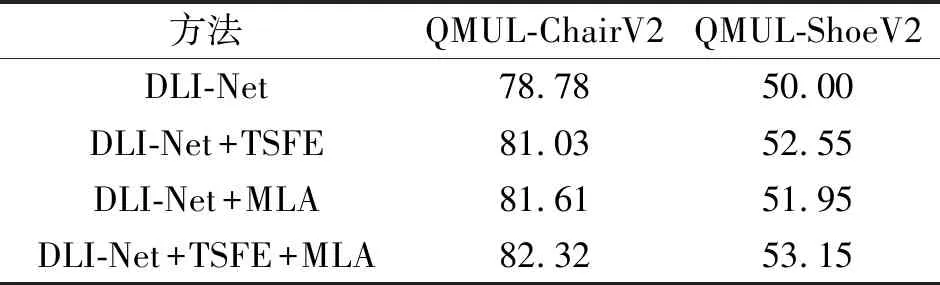
表2 不同模块对网络性能的影响
模态共享特征权重和特异特征权重对网络性能的影响如表3所示,表中(α,β)表示式(1)中的α和β,分别表示模态特异特征权重和模态共享特征权重.共享特征不一定包含检索需要的信息,特异特征可能包含检索需要的关键信息.当两幅真实图像形状相差较大时,模态共享特征较重要;当两幅真实图像形状接近时,模态特异特征起到关键作用.因此,无论舍弃共享特征或是特异特征,都会导致性能下降.
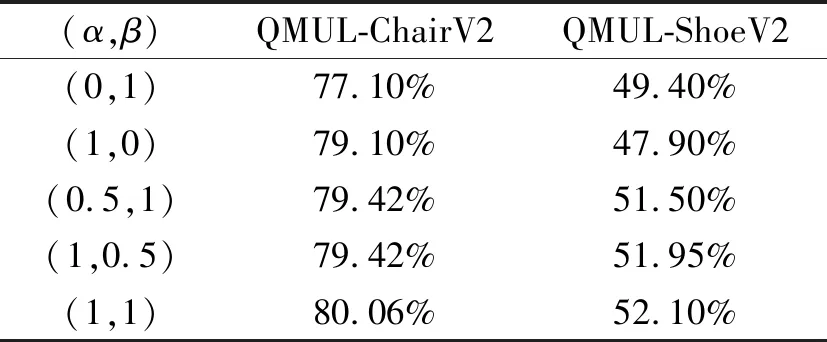
表3 模态共享特征权重和特异特征权重对网络性能的影响
下面讨论不同池化方式对网络性能的影响.在DLI-Net+TSFE这个基准网络上,对特征矩阵进行池化和对距离矩阵进行池化,得到网络的acc@1值如表4所示.在表中,POF表示在MLA中对特征矩阵进行池化,POF(1)表示不对特征矩阵进行池化操作,POF(2)表示将特征矩阵缩小到原来的1/2,POF(4)表示将特征矩阵缩小到原来的1/4,POF(1,2,4)表示将三种粒度的特征矩阵计算得到的图像距离相加,POD表示对距离矩阵进行相应的池化操作,黑体数字表示最优值.
由表4可以看出,直接对特征矩阵进行池化,并使用池化后的特征计算距离,会在不同程度上导致检索精度降低.池化后的特征矩阵越小,检索性能越差,这也表明对特征矩阵进行池化会导致细节信息的丢失.对距离矩阵进行平均池化能够避免特征信息的丢失,将不同粒度下得到的距离结合,能够利用不同粒度信息,有效解决特征不对齐问题.需要注意的是,如果距离矩阵缩小倍数过大,说明用于距离度量的特征块过大,信息粒度过于粗糙,反而导致检索结果不准确.
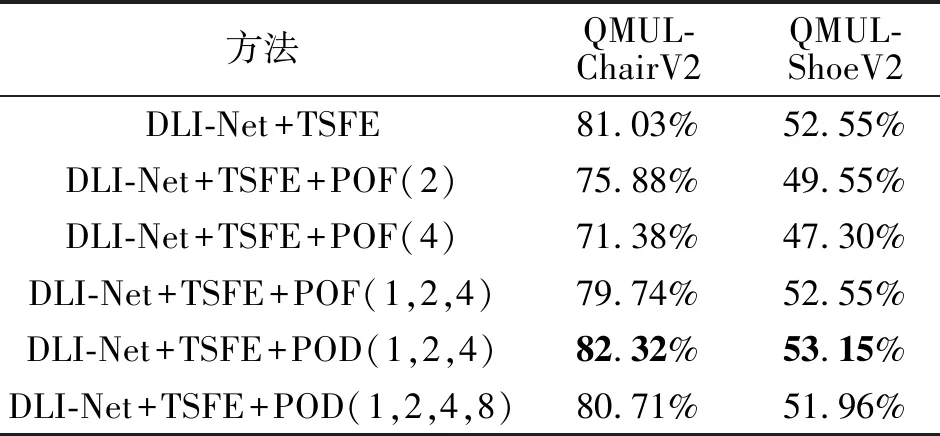
表4 不同池化策略对网络性能的影响
各网络检索不同数据集上所有草图对应的真实图像的效率对比如表5所示,表中黑体数字表示最优值.DLI-Net使用自交互模块去除背景区域,提升检索速度,DLI-Net(W)表示没有使用自交互模块.由于TSMLA在特征提取时使用共享特征提取分支和特异特征提取分支,并在不同尺度上进行局部特征对齐,因此相比DLI-Net,TSMLA的检索性能有所下降,考虑到精度的提升,额外的计算开销是可以接受的.
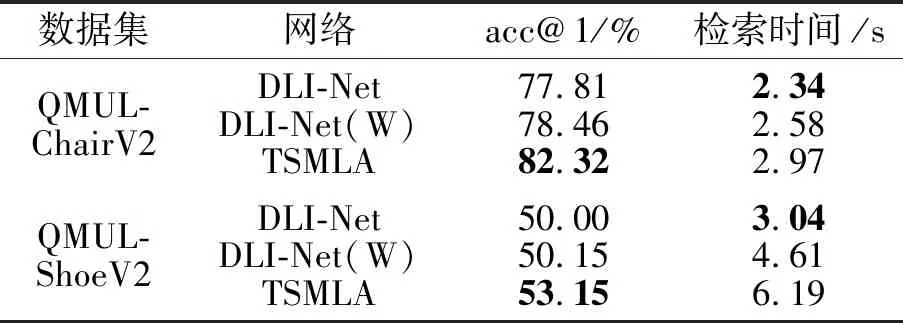
表5 各网络检索效率对比
3 结 束 语
本文针对实例级草图-图像检索中存在的模态差异大和空间不对齐问题,提出双分支多粒度局部对齐网络(TSMLA).在网络中,分别提出双分支特征提取器(TSFE)和多粒度局部特征对齐模块(MLA),利用共享特征和特异特征同时训练模型,解决模态差异过大的问题,同时在不同粒度上进行草图和真实图像局部特征的对齐,解决特征的空间不对齐和特征大小不匹配的问题.虽然TSMLA在QMUL-ChairV2、QMUL-ShoeV2等多个数据集上提升检索精度,但双分支特征提取以及多粒度特征对齐使网络的检索速度下降.今后将着重提升检索速度,同时进一步提升检索精度.
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28
南京大学学报(自然科学版)(2021年1期)2021-01-30
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
系统工程与电子技术(2016年12期)2016-12-24
福建中学数学(2016年4期)2016-10-19
中学生理科应试(2016年2期)2016-05-30
小学生导刊(中年级)(2014年3期)2014-05-09
应用技术学报(2014年1期)2014-02-28
