
基于自适应惩罚的潜变量高斯图模型结构学习
2023-09-27 01:36:00郑倩贞徐平峰
吉林大学学报(理学版) 2023年5期
郑倩贞, 徐平峰
(1. 长春工业大学 数学与统计学院, 长春 130012; 2. 东北师范大学 前沿交叉研究院, 长春 130024)
图模型的结构学习问题, 是指从给定的数据集中估计出反映随机变量间独立性结构的图, 也称为模型选择问题[1]. 高斯图模型的参数估计和模型选择问题等价于协方差逆阵的估计问题及协方差逆阵中零元素的识别问题, 协方差逆阵的元素为零表示对应两个随机变量在给定其余随机变量时具有条件独立性[2]. 随着高维复杂数据的不断增多, 研究稀疏图模型的估计问题尤为重要. 为估计稀疏协方差逆阵, 常用的方法为惩罚似然方法, 例如: 文献[3-5]基于惩罚似然方法研究了变量完全观测时的高斯图模型选择问题. 但在实际生活中, 观测变量通常与一些潜在的不可观测变量(即潜变量)相关. 此时, 观测变量间的图模型结构不一定具有稀疏性, 需考虑潜变量对观测变量的影响, 在给定潜变量时探讨观测变量间的条件独立性. 通常情况下, 潜变量会对图模型选择问题造成很大困难, 因为潜变量的个数以及潜变量与观测变量之间的关系可能都是未知的.
Chandrasekaran等[6]首先对含潜变量的图模型选择问题进行了研究, 提出了当潜变量和观测变量服从联合高斯分布时, 观测变量边缘协方差阵的逆阵可分解为稀疏阵和低秩阵之和, 其中稀疏阵对应给定潜变量时观测变量间的条件独立性. 基于稀疏低秩分解, 文献[6]提出了正则化极大似然分解框架进行潜变量图模型的结构学习, 其中正则项包含对稀疏阵施加的LASSO(least absolute shrinkage and selection operator)惩罚以及对低秩阵施加的核范数惩罚. 由于这两种惩罚均不含自适应权重, 因此称这两种惩罚为非自适应惩罚, 由此得到的稀疏阵和低秩阵估计称为非自适应惩罚似然估计. 文献[6]将优化问题视为对数-行列式半正定规划问题, 采用Wang等[7]提出的对数-行列式近端点算法(log-determinant proximal point algorithm, LogdetPPA)进行求解. 针对文献[6]中的优化问题, Ma等[8]提出了两种交替方向的求解方法: 一种是将目标问题视为一致性优化问题, 利用传统的交替方向乘子法(alternating direction method of multipliers, ADMM)[9]进行求解; 另一种是基于近端梯度的交替方向法(proximal gradient-based alternating direction method, PGADM). 这两种方法都是把包含3个变量的原始问题转换成包含2个变量块的优化问题. PGADM算法速度比LogdetPPA更快, 并具有全局收敛性. 此外, Ma[10]提出了一种交替近端梯度方法求解文献[6]中的优化问题, 并证明了算法的全局收敛性; Meng等[11]对文献[6]的方法做了进一步的理论研究; 文献[12-15]等也对含潜变量图模型结构学习进行了相关研究.
研究表明, 非自适应惩罚得到的估计, 包括LASSO惩罚得到的稀疏协方差逆阵估计[16]以及核范数惩罚在降秩回归问题中得到的低秩系数阵估计[17], 均存在偏差较大的问题, 而自适应惩罚通常可降低估计偏差. 因此, 本文采用自适应惩罚似然方法处理含潜变量的高斯图模型结构学习问题, 对稀疏阵和低秩阵进行估计, 以得到给定潜变量时观测变量间的条件独立关系. 本文对稀疏阵部分施加自适应LASSO惩罚[18], 对低秩阵部分施加自适应核范数惩罚[17]. 与非自适应惩罚的优化问题类似, 采用ADMM算法优化求解自适应惩罚似然的最小化问题, 并且在求解过程中仍具有显式表达式, 以确保算法的计算效率. 本文模拟比较了自适应惩罚与非自适应惩罚在潜变量高斯图模型结构学习和参数估计上的性能. 结果表明, 自适应惩罚显著优于非自适应惩罚, 有效降低了稀疏阵和低秩阵的估计偏差, 能更准确地学习观测变量间的条件独立关系.
1 含潜变量的无向高斯图模型及其自适应惩罚似然
无向高斯图模型是指与无向图G=(V,E)相关的多元正态分布模型, 其中顶点集V中的每个顶点v∈V表示一个高斯随机变量Xv, 边集E中的每条边(u,v)∈E蕴含了给定其余随机变量Xv′(v′∈V{u,v})时随机变量Xu与Xv之间的条件相关性.当采用无向高斯图模型对实际问题进行分析时, 可能会出现随机变量为潜变量的情况, 即变量不存在观测值.因此, 本文考虑含潜变量的无向高斯图模型结构学习问题, 考察给定潜变量时观测变量间的条件独立性关系.
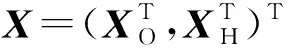
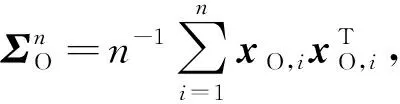
基于惩罚似然方法, 考虑对稀疏阵S施加自适应LASSO惩罚[18], 对低秩阵L施加自适应核范数惩罚[17].自适应LASSO惩罚和自适应核范数惩罚分别为加权版的LASSO惩罚和核范数惩罚. 最初, 自适应LASSO惩罚用于线性回归的变量选择问题, 自适应核范数惩罚用于高维多元降秩回归问题. 对于潜变量无向高斯图模型问题, 自适应惩罚似然估计为
其中:S-L≻0表示矩阵S-L为正定阵,L0表示矩阵L为半正定阵;λ>0和β>0均为调整参数, 参数λ控制惩罚的强度, 参数β用于权衡稀疏阵和低秩阵两项惩罚;σ1(L)≥…≥σp(L)≥0为矩阵L的奇异值;为自适应LASSO惩罚,为自适应核范数惩罚,Sij为矩阵S中第(i,j)位置的元素.当自适应惩罚项中的权重W=(Wij)p×p及w=(w1,w2,…,wp)T满足Wij=1,wi=1(i,j=1,2,…,p)时, 式(1)中的估计退化为非自适应惩罚似然估计.
自适应惩罚要求权重Wij(或wi)随着|Sij|(或σi(L))的增大而减小, 以降低估计偏差.为使权重具有上下界, 本文采用类似于文献[19]的权重形式, 即对任意的i,j=1,2,…,p,

(2)
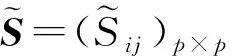
2 优化方法
下面采用ADMM算法求解式(1)中的最小化问题, 并给出调整参数λ和β的选取方法.
2.1 ADMM算法
ADMM算法是一种迭代算法, 广泛应用于求解线性约束下的优化问题中, 如稀疏低秩分解问题[20]. 该算法通过分解-协调过程将一个大的全局问题分解成多个小的局部子问题, 从而通过整合各子问题的解得到原问题的最优解[9]. 考虑约束条件M=S-L, 将式(1)中的目标问题转化成ADMM形式下的优化问题:
于是, 增广Lagrange函数为
其中Y∈p×p为Lagrange乘子,μ>0为惩罚参数, 〈·,·〉表示矩阵内积, ‖·‖F表示矩阵的Frobenius范数.给定第t次ADMM迭代的估计值(Mt,St,Lt,Yt,μt), 则第(t+1)次迭代的更新步骤为
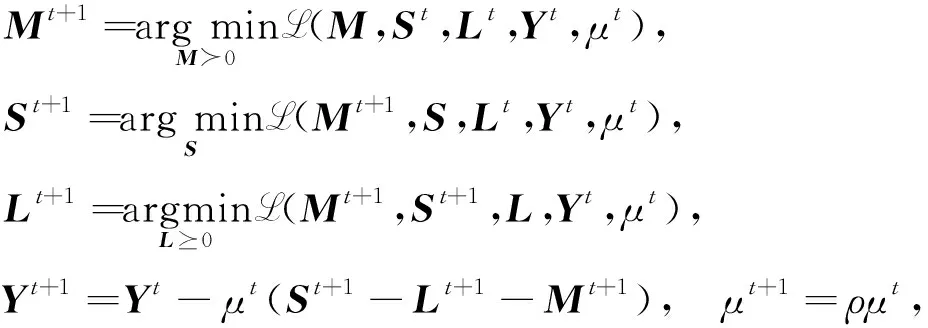
(3)
其中ρ>1为放大因子.下面给出关于矩阵M,S,L子问题的解.
1) 更新M.
式(3)中矩阵M的优化子问题可表示为
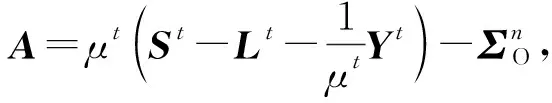
A=Udiag(e1(A),…,ep(A))UT,
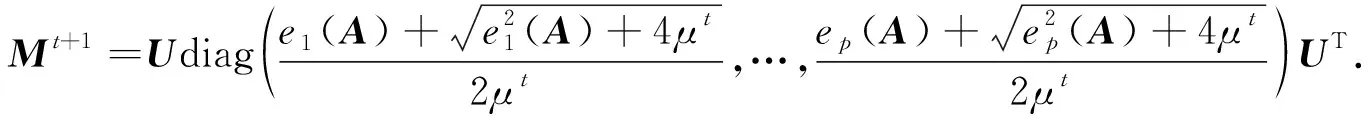
2) 更新S.

上述优化问题完全可分, 即对任意i,j=1,2,…,p, 均有
其中sign(·)为符号函数, (·)+=max{·,0}.
3) 更新L.
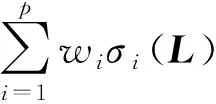
令B=St+1-Mt+1-Yt/μt, 则式(3)中稀疏阵L的优化子问题可写成
对矩阵B做特征值分解
B=Qdiag(e1(B),…,ep(B))QT,
其中e1(B)≥…≥ep(B)为矩阵B的特征值,Q为正交阵,QQT=QTQ=I.从而可推得
Lt+1=Qdiag((e1(B)-λw1/μt)+,…,(ep(B)-λwp/μt)+)QT.
2.2 调整参数的选取
调整参数λ和β控制模型的复杂度, 不同的参数设定可得到不同稀疏度的S及不同秩的L.对于优化问题(1), 可采用K折交叉验证的方式选择最优参数组合(λ*,β*).将样本分成K折互不相交的子集, 记为Tk(k=1,2,…,K).定义K折交叉验证的得分函数为
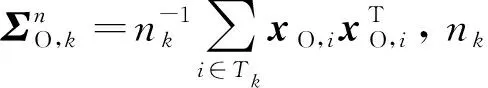
3 数值模拟
在模拟实验中, 对自适应惩罚(γ1≠0,γ2≠0)和非自适应惩罚(γ1=0,γ2=0)在含潜变量的无向高斯图模型上的模型选择和参数估计性能进行比较.对于自适应惩罚情况, 仅考虑γ1=γ2=1.
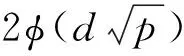

为评价模型选择性能, 比较真阳率(TPR)、 阳性预测率(PPV)及马修斯相关系数(MCC):
其中TP为真阳类个数, TN为真阴类个数, FP为假阳类个数, FN为假阴类个数. 表1列出了不同情形下TPR,PPV和MCC的均值及标准差. 由表1可见, 在所有情形下由自适应惩罚得到的PPV和MCC均显著优于非自适应惩罚. 对于TPR, 当n=500时非自适应惩罚性能更好, 但当样本量增大(即n=1 000)时, 两种惩罚的TPR几乎一样好, 均接近于1. 因此, 基于自适应惩罚似然的潜变量图模型结构学习性能更好.
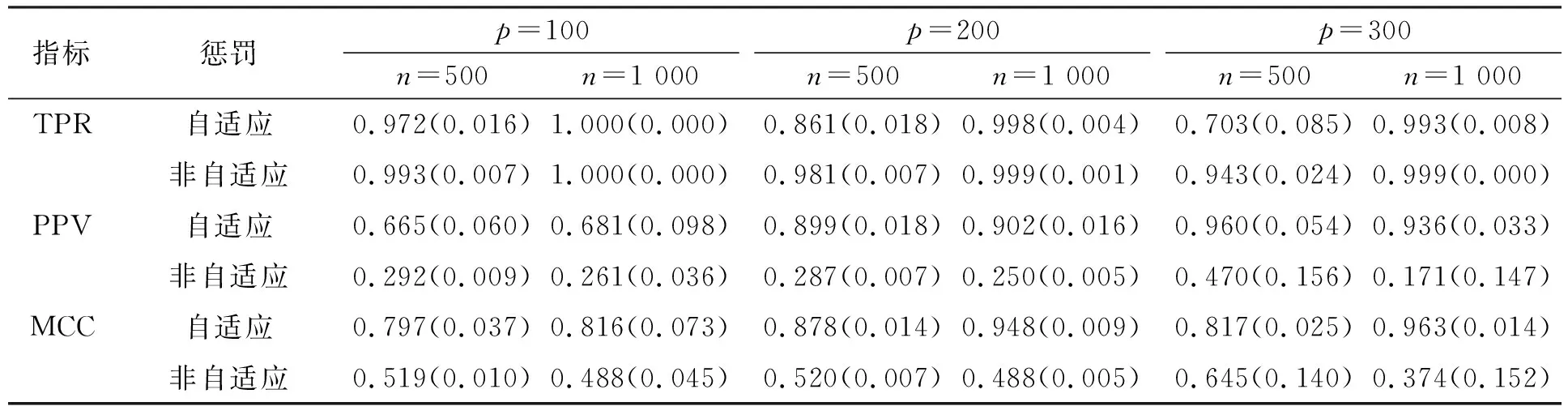
表1 不同情形下TPR,PPV,MCC的均值及标准差Table 1 Means and standard deviations of TPR,PPV,MCC in different situations
为比较参数估计结果, 考虑矩阵M,S,L的估计误差, 分别为
表2列出了不同情形下参数估计误差的均值及标准差.由表2可见, 所有情形下自适应惩罚的参数估计误差均小于非自适应惩罚.由自适应惩罚得到的参数估计更接近于真实值.
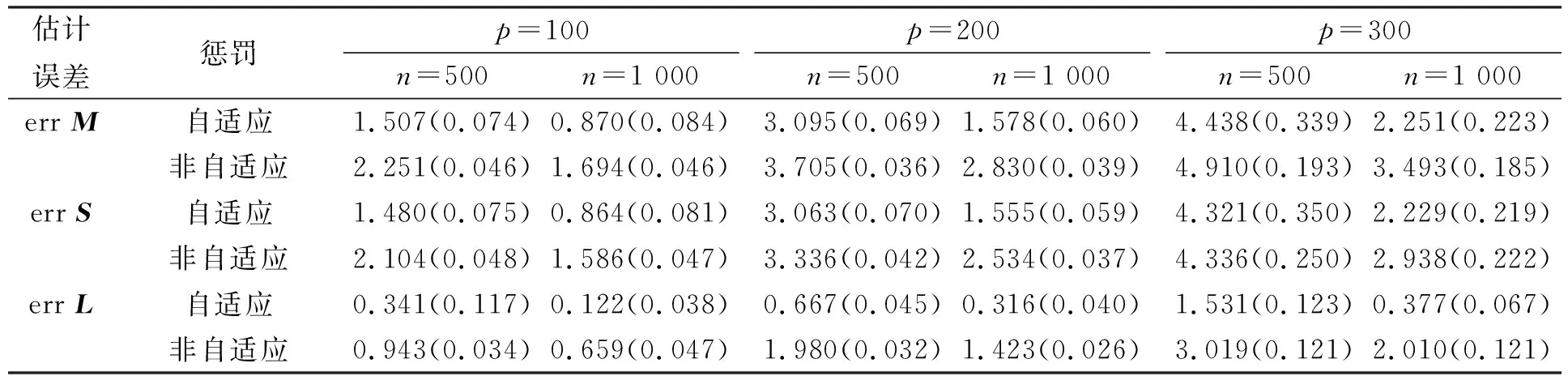
表2 不同情形下矩阵M,S,L的估计误差均值及标准差Table 2 Means and standard deviations of estimation errors of matrices M,S,L in different situations
4 实例分析
下面采用自适应惩罚似然方法对枯草芽孢杆菌核黄素(维生素B2)生产数据集(该数据集可在文献[21]的补充材料中下载)进行图模型结构学习. 该数据集的样本量为71, 变量个数为4 089, 其中有4 088个变量表示不同基因表达水平的对数, 1个变量表示核黄素生产率的对数. 本文仅对文献[21]中简化后的数据集riboflavinv100.csv做图模型推断, 其中包含经验方差最大的100个基因表达水平变量和1个测量核黄素生产率的变量.
为比较含潜变量和不含潜变量(即固定低秩阵L=0)时观测变量间的图结构, 将样本分为训练集和测试集, 其中训练集包含57个样本, 测试集包含14个样本.首先, 基于训练集样本得到稀疏阵和低秩阵的估计; 然后, 基于测试集样本计算负的对数似然.图1为由自适应惩罚(γ1=γ2=1)得到的图模型选择结果, 其中(A)为给定潜变量时观测变量间的条件独立性关系, (B)为不考虑潜变量时观测变量间的条件独立性关系. 图1中横轴从左至右(纵轴从上至下)依次对应第1~101个观测变量, 黑色表示对应观测变量间条件相关, 白色表示对应变量间条件独立. 当考虑潜变量时, 估计出的图模型共包含531条边(占观测变量对总数的10.5%)以及13个潜变量(对应低秩阵的秩), 基于测试集的负对数似然为49.54. 当不考虑潜变量时, 估计出的图模型共包含1104条边(占观测变量对总数的21.9%), 基于测试集的负对数似然为50.48. 显然, 考虑潜变量时能得到更稀疏的图模型, 且负对数似然更小, 表明考虑潜变量对观测变量的影响能更好地拟合枯草芽孢杆菌核黄素生产数据集.
综上所述, 本文提出了一种基于自适应惩罚似然的潜变量高斯图模型结构学习方法. 首先, 在观测似然后面加上两项自适应惩罚项, 分别为稀疏阵部分的自适应LASSO惩罚以及低秩阵部分的自适应核范数惩罚; 然后, 通过ADMM算法最小化惩罚似然以求解稀疏阵和低秩阵的参数估计, 从而得到给定潜变量时观测变量间的条件独立关系. 在模拟实验中, 通过与非自适应惩罚的比较, 验证了自适应惩罚似然方法在模型选择和参数估计方面性能均更好.
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:28
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
中国校外教育(下旬)(2017年8期)2017-10-30 17:32:36
数学物理学报(2017年3期)2017-07-01 16:18:48
统计与决策(2017年2期)2017-03-20 15:25:22
数学物理学报(2016年5期)2016-08-24 07:38:48
系统工程与电子技术(2016年2期)2016-04-16 05:17:08
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
数学年刊A辑(中文版)(2014年1期)2014-10-30 01:48:06
