
基于拼音相似度的中文谐音新词发现方法
2023-09-27 06:31:04李瀚臣张顺香朱广丽王腾科
计算机应用 2023年9期
李瀚臣,张顺香*,朱广丽,王腾科
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.合肥综合性国家科学中心 人工智能研究院,合肥 230088)
0 引言
新词识别,即识别通用词典中的未收录词,通过上下文信息、词构造特点等构造规则或模型以达到识别新词的目的,可用于发现网络新词、专有名词、旧词新用等。在微博等社交网站,主要用户为年轻群体,这些用户群体拥有创新性的见解与表达能力,产生了一系列的网络新词。然而,新词的产生速度快、语法语用灵活,诸如谐音梗中使用同音近音汉字、英文或数字组合代替原本旧词,这些词的创造难度低,没有固定的组合规则,组成方式多样,易于产生与传播,导致使用现有的基于规则和统计的新词识别方法发现谐音新词的准确率不高、难以解释谐音新词的含义等问题。准确识别文本中的谐音新词,及时发现这些词并扩充至中文词典,有助于理解评论者的真实意见,方便有关部门对舆论及时管控,生产者可根据用户的真正反馈来更新产品,完善营销策略。
为了构建一个发现谐音词的新词识别方法,需考虑以下几点:1)如何将候选新词转换成发音相近的汉语拼音来与旧词拼音比较。2)如何判断并找出和谐音词最相近的旧词,根据判别结果判断候选新词是否为谐音新词。
基于以上考虑,本文提出一种中文谐音新词发现方法,引入新旧词拼音比较,通过拼音相似度判断候选词是否为谐音新词,以提高谐音新词识别的准确率。中文谐音新词发现方法的框架如图1 所示。首先,对微博评论文本进行预处理,进行编码格式的统一、特殊与重复字符串的过滤;然后,基于内部与外部的统计,使用互信息计算预选新词内部结合度,结合邻接熵确定候选新词边界;接着,将新词转换成发音相近的汉语拼音,与中文词典中的旧词拼音比较,找出发音最相似的对比结果;最后,根据最相似结果是否超过阈值判断候选词是否为谐音新词,并找出谐音新词对应的原有词。本文的主要工作包括:
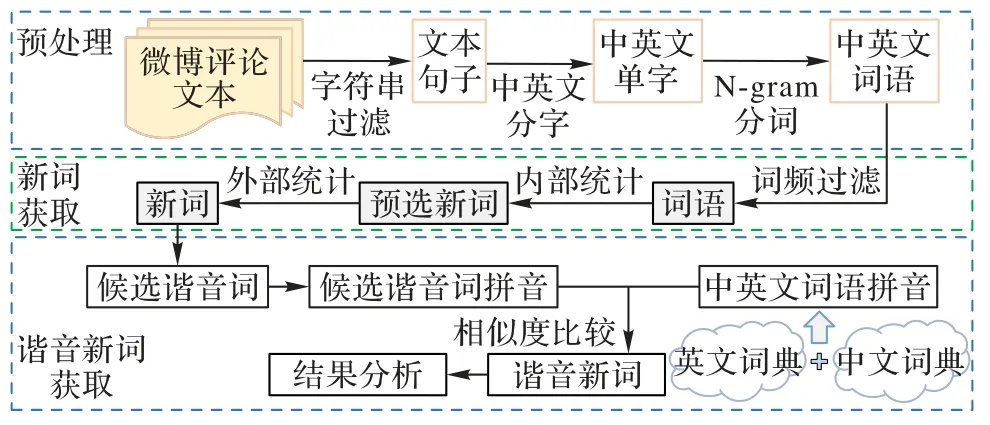
图1 本文方法框架Fig.1 Framework of the proposed method
1)提出一种改进的候选新词统计方法,用于发现新词。该方法通过综合左右邻接熵的值来计算候选新词邻接字符的不确定性,根据候选新词内外部统计的综合得分发现新词。
2)提出一种基于拼音相似度的谐音新词发现方法,用于提高谐音新词识别的准确率。该方法通过新词拼音与旧词拼音的比较,从最相似的比较结果中发现谐音新词。
1 研究现状
早期多采用基于规则的方法,通过总结新词的构词特点来建立人工规则,利用构词模式、词性规则、成词概率等识别未登录词。郑家恒等[1]根据汉语构词法建立规则语料库,构建词缀表过滤不同类型模式的垃圾串;崔世起等[2]采用自学习的方法建立垃圾词典和词缀词典对候选新词进行过滤。基于规则的方法具有较高的新词识别精度,但规则通常只适用于特定领域,导致该类方法可移植性较差,且建立人工规则的工作量大、成本高。目前新词识别方法主要分为基于统计的方法、基于规则与统计相结合的方法和基于深度学习的方法。
1.1 基于统计的方法
在微博评论文本的新词识别方面,Yang 等[3]采用改进互信息筛选出大于2 字组成的候选新词,再利用邻接熵确定新词。在产品评论方面,Zhu 等[4]通过互信息与改进邻接熵从产品评论中发现潜在词集,从而有效判断用户的隐私偏好;王煜等[5]使用改进频繁树算法筛选出候选新词,引入时间逐点互信息判定候选新词内部结合度和时间性,加入时间特征提高热点新词识别率;Kim 等[6]对谷歌与苹果使用的本地化差分隐私(Local Differential Privacy,LDP)进行改进,从而解决一词多个LDP report 导致的计算成本与隐私预算问题;Wu等[7]利用在线资源构建俚语情感词典,有助于俚语情感新词的识别与情感分析的任务;Qian 等[8]则针对传统分词技术难以切分保留新词的问题,提出一种基于词嵌入的方法,结合词嵌入和频繁N-gram 串完成新词发现;Shang[9]将相似度和互信息组合为相似度增强互信息,提出了一种基于相似度判断的新词发现算法。针对谐音新词的识别,目前有Chung等[10]采用混合数字与符号的中文谐音新词发现方法BNShCNs(Blended Numeric and symbolic homophony Chinese Neologisms),针对台湾批踢踢(PTT)在线社区文本发现数字谐音词,采用无监督方法获得候选新词。
1.2 基于规则与统计相结合的方法
赵志滨等[11]通过构建领域句法词典,结合词向量技术实现了领域新词发现。张爽等[12]基于卷积神经网络(Convolutional Neural Network,CNN)模型,提出了一种依存句法与语义信息结合的相似性计算模型(similarity computing model based on Dependency Syntax and Semantics,DSSCNN),融合相似度判断以更有效地发现新词。针对社交媒体内容中的新词,Zalmout 等[13]提出了一种无监督的方法来检测Reddit 评论数据中的新词,而且并不依赖于并行训练数据。Li 等[14]针对相邻两字的凝固度导致错误分词的情况,提出了一种基于N-gram 模型和多特征频率的新词发现算法。在新情感词提取方面,Zhang 等[15]提出了一种基于序列标注和句法分析的数据处理方法,从产品评论中获取新情感词的候选集。在英文新词识别方面,Ryskina 等[16]从语义分布、语义稀疏性的内部因素和技术文化变化的外部因素综合考虑英文新词识别。
1.3 基于深度学习的方法
针对金融市场的分析,Yan 等[17]提出了SD-SPP(Source Diversity-Significance of Principal Patterns),使用动态特征描述上下文模式相似性进行新词识别。针对twitter 等社交媒体中的新词,Sarna 等[18]提出一种从社交媒体信息中提取关键词的新方法,根据现有的字典和概率找到每个域的新单词。而McCrae[19]针对形容词-名词形式的新词,采用预训练的语言模型进行识别,并与单个嵌入词进行比较。Liang等[20]提出了边缘似然法和独立领域的中文新词检测,有效提高了中文新词边界和域外数据发现新词的准确率。Wang[21]将未标记数据与统计方法结合,并将标记数据与隐马尔可夫模型相结合来增强新词识别效果。
基于以上研究分析,现有方法虽然可以有效识别中文新词,但仍有不足之处。现有中文新词识别方法很少考虑谐音新词,在分词阶段采用针对新词识别的分词方法将谐音新词切分成多个旧词,导致谐音新词的识别率不高。本文将候选新词与中文词典中的词转换成拼音,进行相似度比较,判断比较结果中与旧词相似度最大的候选词是否为谐音新词,从而提高谐音新词识别准确率。
2 微博评论文本候选新词的确定
微博面向年轻用户群体,里面的评论文本具有创新性、灵活性,评论新词涉及领域广、构词模式自由,微博评论文本分词效果直接影响预选新词的获取效果,进而影响后续新词识别的准确率。本文预选新词获取的流程如图2 所示。
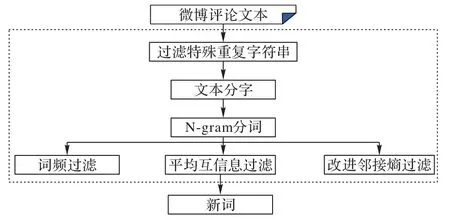
图2 微博评论文本预选新词的获取Fig.2 Candidate new word acquisition from Weibo comment text
2.1 文本预处理
微博评论文本中含有大量表情符号、特殊字符串等不利于分词的无用信息,需要经过预处理。
1)将文本字符转换为UTF-8 编码。
2)过滤掉微博文本中网址链接、@用户名等特殊字符串。
3)过滤掉微博文本中重复聚集字符串,如“!!!”“???”“……”等。
4)查找文本中连续的数字和英文字母,并将它们作为单字,防止一个词中英文字母和数字的数量超过最大词窗口导致分词错误的问题。
5)采用N-gram 模型对文本进行切分,考虑到目前谐音词多是4 字以内的组成形式,本文的N-gram 最大词窗口取4,以减少4 字谐音词未被正确切分的情况。
6)对于切分后得到的词,用词典过滤掉已有的词。
2.2 候选新词获取
对预处理后的文本采用互信息和改进邻接熵进行候选新词筛选。互信息表示两个对象间相互依赖的程度,可表示字与字、字与词之间的相关性,相关性越大,字与字、字与词的成词概率越大,依赖程度越高。本文采用平均互信息(Average Mutual Information,AMI)来表示字或词x、y之间的相关性,如式(1)所示:
其中:n表示x,y组成的候选词的长度;p(x)、p(y)表示字或词x、y单独出现在文本中的概率;p(x,y)表示x与y同时出现在文本中的概率;AMI(x,y) 表示x与y的相关联程度。当AMI(x,y)>0 时,表示x与y相互关联,AMI(x,y)越大,两者关联程度越高,越有可能成为新词。
使用左右邻接熵来确定新词左右边界。邻接熵可以衡量候选新词的左右邻接字符的不确定性,不确定性越大,说明左右邻接字符包含的信息越多,成词的概率越高。左、右邻接熵分别如式(2)、(3)所示。
其中:N(wi,w)表示wi与w同时出现的次数;N(wj,w)表示wj与w同时出现的次数;N(w)表示w出现的次数。
考虑因式(2)或式(3)值过大或过小,导致候选新词邻接熵偏大的情况,假如新词的左邻接熵远低于右邻接熵,而作求和运算得到的邻接熵值会偏大,容易将它划分为新词。为减少此类情况出现,本文采用一种改进的邻接熵来表示左右邻字的丰富程度,综合左右邻接熵来计算候选新词邻接字符的不确定性,如式(6)所示。考虑到HL(w)与HR(w)可能相等,本文改进邻接熵中的分母,采用来避免分母为0 的情况。
得到平均互信息与邻接熵两个评估指标后,对候选新词进行打分,当分数超过阈值时,将它视为新词。候选新词的总体得分计算式如式(7)所示。
其中:α表示平均互信息的权重;β表示邻接熵的权重。
3 谐音新词识别
谐音词具有与原有词相同的含义,组成形式灵活多样,较为常见的有中文谐音字词、英文单词或数字替换原字词组成新词。为了提高谐音新词识别的准确率,便于含有谐音词的评论文本的情感分析,本文将候选谐音新词转化成汉语拼音,与中文词典旧词的汉语拼音比较,从候选谐音新词中找出候选谐音新词。对于含有数字的谐音新词,如484(是不是)、521(我爱你)、886(拜拜咯),每个数字都对应一个原有字从而构成谐音词,因此对于1~9 的数字本文同样采用将其转换成汉语拼音的方式。
针对含有英文单词的谐音新词,考虑到谐音词组成的灵活性与易传播性,通常不会采用复杂生僻的英文单词作为谐音词,因此本文准备了包含3 000 个常用单词的英文词典,并保留单词长度在3~5 的常用英文单词,约1 200 个,如表1 所示。如候选谐音新词“duck 不必”,将英文单词duck 对应的音标[dʌk]转换成汉语拼音[da-ke],通过计算新词拼音[da-ke-bu-bi]和旧词拼音之间的编辑距离与相似度,找到满足条件的旧词拼音[da-ke-bu-bi],对应旧词“大可不必”,则该词“duck 不必”为谐音新词,其对应的是中文词典中的原有词“大可不必”。首先,调用函数库将候选谐音新词与英文词典中的单词转换成拼音;其次,计算候选谐音新词拼音与中文词典原有词拼音的编辑距离;最后,将两种拼音进行相似度比较,找出相似度最高的比较结果,并对找出的谐音新词标注其对应的原有词。

表1 英文词典例子Tab.1 Examples of English dictionary
算法1 谐音新词识别的算法。
输入 候选谐音新词w1,中文词典chinese.xlsx,英文词典english.xlsx;
输出 谐音新词与它对应的旧词。
3.1 词语拼音的转换与距离计算
本文引入一种新的谐音新词识别的方法,以识别包含英文单词和数字的谐音新词。在将候选谐音新词与中文词典旧词转换成拼音s1与s2后,需要计算两个字符串之间的距离。由于是针对谐音新词的识别,不仅要考虑拼音字符串中各个字符出现的次数,还需要考虑拼音字符串中各个字符的位置顺序,因此本文采用两种拼音字符串之间的编辑距离Dis(s1,s2),如式(8)所示。总体思路如下:
1)s1的第i个字符与s2的第j个字符相同时,即无需对s1的第i个字符进行操作就能和s2的第j个字符一致,则edit(i,j)=edit(i-1,j-1),即与s1的前i-1 个字符到s2的前j-1 个字符需要操作的次数一致。
2)s1的第i个字符与s2的第j个字符不同时,需考虑以下三种操作:
①删除操作。edit(i,j)=edit(i-1,j)+1 表 示s1的 前i-1 个字符已经转换为s2的前j个字符,则在s1的第i个字符位置只需进行一步删除操作。
②插入操作。edit(i,j)=edit(i,j-1)+1 表 示s1的 前i个字符已经转换为s2的前j-1 个字符,则在s1的第i个字符位置只需进行一步插入操作,插入一个与s2的第j个字符相同的字符。
③替换操作。edit(i,j)=edit(i-1,j-1)+1 表示s1的前i-1 个字符已经转换为s2的前j-1 个字符,则在s1的第i个字符位置只需进行一步替换操作,替换一个与s2的第j个字符相同的字符。
对于s1与s2其中一个的字符串长度为0 时,它们的编辑距离为另一个的字符串长度大小。由于本文考虑的是候选谐音新词字符串与中文词典旧词字符串的编辑距离计算,理论上不存在其中一个长度为0 的情况。
其中:i表示候选谐音新词拼音字符串s1的下标,从1 开始;j表示中文词典旧词拼音字符串s2的下标,从1 开始表示当前候选谐音新词拼音字符串s1的下标为i对应的字符表示当前中文词典旧词拼音字符串s2的下标为j对应的字符;edit(i,j)与Disi,j(s1,s2)表示长度为i的当前候选谐音新词的拼音字符串s1和长度为j的当前中文词典旧词拼音字符串s2之间的编辑距离。
算法2 候选谐音新词拼音与旧词拼音编辑距离的算法。
输入 候选谐音新词w1,词典旧词w2;
输出 候选谐音新词拼音字符串s1与其对应的旧词拼音字符串s2的编辑距离Dis(s1,s2)。
3.2 拼音相似度比较
经过3.1 节候选谐音新词与中文词典旧词的拼音转换后,计算出当前候选谐音新词拼音与各个中文词典旧词拼音的编辑距离Dis(s1,s2),然后通过本节计算候选新词拼音与中文词典旧词拼音之间的相似度Sim(s1,s2),如式(9)所示:
其中:n1为候选新词拼音字符串s1的长度;n2为中文词典旧词拼音字符串s2的长度。s1与s2之间的编辑距离Dis(s1,s2)越小,s1与s2之间越相似,它们的相似度Sim(s1,s2)越大。
本文保留相似度Sim(s1,s2)最大时对应的候选新词,并与阈值进行比较,若超过阈值,则将该候选谐音新词判定为谐音新词。当多个候选新词找到对应的旧词,且这些候选新词在文本中相邻出现,则将这些候选新词合并,并认为由这些候选新词共同组成一个候选谐音新词。考虑到谐音词读音与原词读音多为同音或近音,本文优先考虑同音词与近音词作为候选谐音新词。
4 实验与结果分析
本文的实验环境如下:采用Windows 10 版本,64 位操作系统,CPU 为12 代i5 12400F,GPU 为NVIDIA GeForce RTX 3060 12 GB,16 GB 内存,数据读取采用MySQL,编程语言为Python3.7。选取的数据集如下:
数据集1 本文爬取的当下微博热门话题的评论数据集,包含类别、话题、内容、评论、情感极性等微博语料,选取其中10 000 条评论文本数据。
数据集2 北理工NLPIR 大数据搜索挖掘实验室的微博评论数据集,包含500 万条微博语料,随机抽取其中10 000条评论文本数据。
表2 列举了两个数据集中的部分内容。

表2 实验数据举例Tab.2 Examples of experimental data
4.1 评价指标
实验采用准确率P(Precision)、召回率R(Recall)和F1 分数F作为评价指标,如式(10)~(12)所示。
其中:N为实验获得的谐音新词总个数;M为微博语料中存在的谐音新词总个数。
4.2 实验方法
本文的具体实验操作如下。
步骤1 数据预处理。过滤掉数据集中重复和特殊的字符串,对文本进行分字与分词处理,得到分词后的数据。
步骤2 基于统计的新词识别。数据经预处理后,计算词的互信息得到候选新词,改进邻接熵确立新词边界,得到新词。
步骤3 谐音新词识别。将所有新词与中文词典中的词转换成拼音,采用编辑距离找出相似度最大的新词与词典中的词,若相似度超过阈值,则将新词判定为谐音新词。
为了验证本文谐音新词发现方法的有效性,设置对比实验,对比方法如下:
1)BNShCNs[10]:利用无监督方法获取候选新词,通过词嵌入向量筛选出数字谐音新词。
2)DSSCNN[12]:基于字粒度根据统计量获取候选新词,并通过新词与历史表达的句法结构与上下文语义计算语句相似度来获取新词。
为了验证改进的外部统计筛选新词以及拼音相似度比较对整体谐音新词发现方法效果起作用,分别改变这两个部分的方法,其他部分保持不变。设置消融实验进行对比。
1)改进内外部统计(方法1):不进行新词与词典旧词的拼音相似度比较,对微博评论文本预处理后,结合平均互信息与改进邻接熵的综合得分来获取谐音新词。
2)内外部统计+拼音相似度比较(方法2):在预选新词的外部统计阶段,对左右邻接熵求和来判断其值是否超过阈值来划分该词是否为新词,再采用新词与词典旧词的拼音相似度比较方法获取谐音新词。
4.3 实验结果及分析
根据4.2 节的实验方法,本文进行如下实验。
1)在数据集1 上,不同方法获取谐音新词的实验结果如表3 所示。本文方法在数据集1 上的F1、准确率、召回率比BNShCNs 提高了1.75、0.51 和2.91 个百分点。BNShCNs 能更好地识别数字谐音新词,而数据集1 还含有中英文谐音新词,导致该方法对谐音新词识别的总体效果下降。相较于DSSCNN,本文方法的F1、准确率、召回率提高了5.81、5.27与6.31 个百分点。
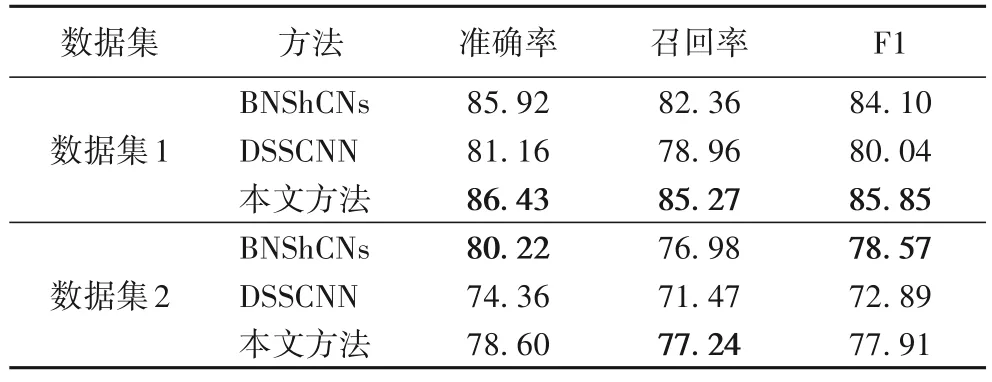
表3 不同方法在数据集1、2上的实验结果对比 单位:%Tab.3 Comparison of experimental results of different methods on dataset 1 and 2 unit:%
2)在数据集2 上,不同方法获取谐音新词的实验结果如表3 所示。本文方法的召回率比BNShCNs 高0.26 个百分点,但准确率和F1 降低了1.62 和0.66 个百分点。可能是本文方法在数据集2 上获得的谐音新词较多,但与数据集上相符的谐音新词较少,导致和BNShCNs 相比在准确率和F1 上有所下降。相较于DSSCNN,本文方法的准确率、召回率和F1 提高了4.24、5.77 和5.02 个百分点。
本文方法在两个数据集上的结果均高于DSSCNN 方法,这可能是DSSCNN 方法虽然能有效识别新词,但没有针对谐音新词的识别,导致该方法在本实验结果中的谐音新词识别效果不好。各方法在数据集2 上的实验结果普遍较低,这可能是该数据集非针对包含谐音新词的评论文本收集,导致各方法在本实验结果的谐音新词识别效果整体有所下降。
3)消融实验的结果如表4 所示。本文方法在数据集1 上的F1、准确率、召回率比方法1 高出了12.60、12.08 和13.09个百分点。因为方法1 缺少对谐音新词的筛选,将所有识别出的新词作为谐音新词的识别结果,导致谐音新词识别的准确率不高。相较于方法2,本文方法的F1、准确率、召回率提高了10.18、10.12 和10.23 个百分点。这是由于部分候选新词的左邻接熵或右邻接熵过小,但左右邻接熵之和大于阈值,被错误筛选成新词,影响了谐音新词识别结果。

表4 中文谐音新词发现方法的消融实验结果 单位:%Tab.4 Ablation experimental results of Chinese new homophonic word discovery method unit:%
从表3~4 可以看出:融入拼音相似度比较的谐音新词识别方法在准确率、召回率和F1 上均有一定提升;使用改进的外部统计方法识别新词在一定程度上提高了谐音新词识别的效果。谐音新词识别的准确率得到提升的重要原因是本文方法考虑了平均互信息与改进邻接熵的综合得分来获取新词,并利用拼音相似度对谐音词拼音与旧词拼音比较,找出与旧词发音最相似的谐音新词,有利于谐音新词的识别。
5 结语
为了丰富谐音新词的语义信息,提高谐音新词识别的准确率,本文提出一种谐音新词发现方法。通过对分词后的文本计算平均互信息得到候选新词,利用改进邻接熵筛选出新词,并将拼音的相似度比较应用于谐音新词识别方法,提高了谐音新词识别的准确率。
实验结果表明,在微博评论文本的谐音新词识别方面,使用中文拼音进行相似度比较能提高谐音新词的识别效果。未来将基于本文方法,结合深度学习Bi-LSTM-CRF(Bidirectional Long Short-Term Memory Conditional Random Field)利用上下文信息识别低频新词,从而对谐音新词的识别效果进一步改进,推进中文新词识别等研究。
猜你喜欢
小猕猴学习画刊·下半月(2020年11期)2020-12-15 10:49:47
语文建设·下半月(2020年2期)2020-05-28 10:05:02
小读者·阅世界(2019年8期)2019-09-10 07:22:44
党的生活(黑龙江)(2016年3期)2016-03-21 21:19:42
电脑迷(2014年8期)2014-04-29 07:37:40
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
网络安全与数据管理(2011年17期)2011-07-25 00:33:50
卷宗(2011年9期)2011-05-14 17:51:19
计算机应用文摘(2009年11期)2009-04-29 00:44:03
