
基于字典尺度自适应学习的欠定盲语音重构算法*
2023-09-26 11:22:38李嘉新俞守庚
电讯技术 2023年9期
李嘉新,魏 爽,2,俞守庚,刘 睿
(1.上海师范大学 信息与机电工程学院,上海 201418;2.上海交通大学 感知与导航研究所,上海 200030)
0 引 言
欠定盲源分离(Underdetermined Blind Source Separation,UBSS)广泛应用于语音分离[1]、干扰减缓[2]、图像处理[3]和通信信号处理[4]等领域。由于缺乏足够的先验信息,UBSS是一类不适定问题[1]。现有的“两步法”利用稀疏表示技术解决语音UBSS中的上述问题[5-6],但是“两步法”利用频域的稀疏性来恢复语音源信号,容易出现相位解耦和时延等问题[7]。考虑到字典学习算法可以直接在时域捕获语音信号的稀疏性[8-10],研究人员在“两步法”框架中应用字典学习技术,将UBSS问题转化为稀疏信号恢复问题[1],提高算法的通用性。
主流的字典学习算法包括在线字典学习(Online Dictionary Learning,ODL)[11]、K-SVD(K-means Singular Value Decomposition)[12]、同步码字优化(Simultaneous Codeword Optimization,SimCO)[13]等,采用优化算法训练字典,以获取语音信号的稀疏特征。但对于复杂多变的语音信号,上述算法始终使用固定的字典尺寸,导致字典对信号的稀疏表示效果不佳。此外,它们利用先验知识来预设字典尺寸,当训练数据或约束条件发生变化时,需要重新进行实验来确定字典尺寸。如果字典太大,训练字典的成本会增加,也会导致过拟合问题;字典太小,会导致信号的稀疏表示效果变差。以上问题限制了算法的性能,因此确定合适的字典尺寸是当前研究的重点和难点[14]。
目前,调整字典尺寸的算法有尺度自适应字典学习(Scale Adaptive Dictionary Learning,SADL)[15]、Stagewise K-SVD[16]、尺寸优化字典学习(Size-Optimizing Dictionary Learning,SODL)[14]、自适应字典学习(Adaptive Dictionary Learning,ADL)[17]、自适应尺寸字典学习(Adaptive-Size Dictionary Learning,AS-DL)[18-19]等。SADL将多元莫罗近端指标(Multivariate Moreau Proximal Indictor,MMPI)作为字典学习目标函数中的惩罚项,在图像重建中优化字典尺寸。SODL首先根据先验知识预设一组字典尺寸,训练字典时在预设的字典尺寸范围内筛选出一个符合训练数据的字典尺寸。虽然该方法简单易懂,但是它在确定最佳字典尺寸方面存在限制,具有不灵活性。Stagewise K-SVD与ADL在迭代训练字典的过程中,通过扩大字典尺寸来降低稀疏表示误差,然而它们面对不同训练数据时的适应性较差,应用于语音UBSS中的效果不理想。AS-DL应用信息论准则(Information-Theoretic Criteria,ITC)来优化字典尺寸,并且在磁共振成像(Magnetic Resonance Imaging,MRI)中取得了不错的效果。但是该算法过渡依赖ITC,导致训练的字典不能很好地拟合语音数据,造成语音源信号的恢复效果不佳。
针对上述算法存在的问题,本文提出一种尺度自适应同步码字优化(Scale Adaptive Simultaneous Codeword Optimization,SASimCO)算法来解决语音UBSS中优化字典尺寸的问题。本文算法既不会在预设的字典尺寸中进行机械地筛选,也不会简单地增加字典尺寸,而是在训练字典的过程中同时调节尺寸与更新原子,降低稀疏表示误差,得到一个具有良好稀疏性的过完备字典。这使得字典对语音信号的稀疏表示更加灵活和稳定,有效提高语音源信号的恢复效果,具有实际应用价值。
1 系统模型
1.1 欠定盲源分离模型
不考虑噪声的情况下,UBSS的模型为
X=AS。
(1)
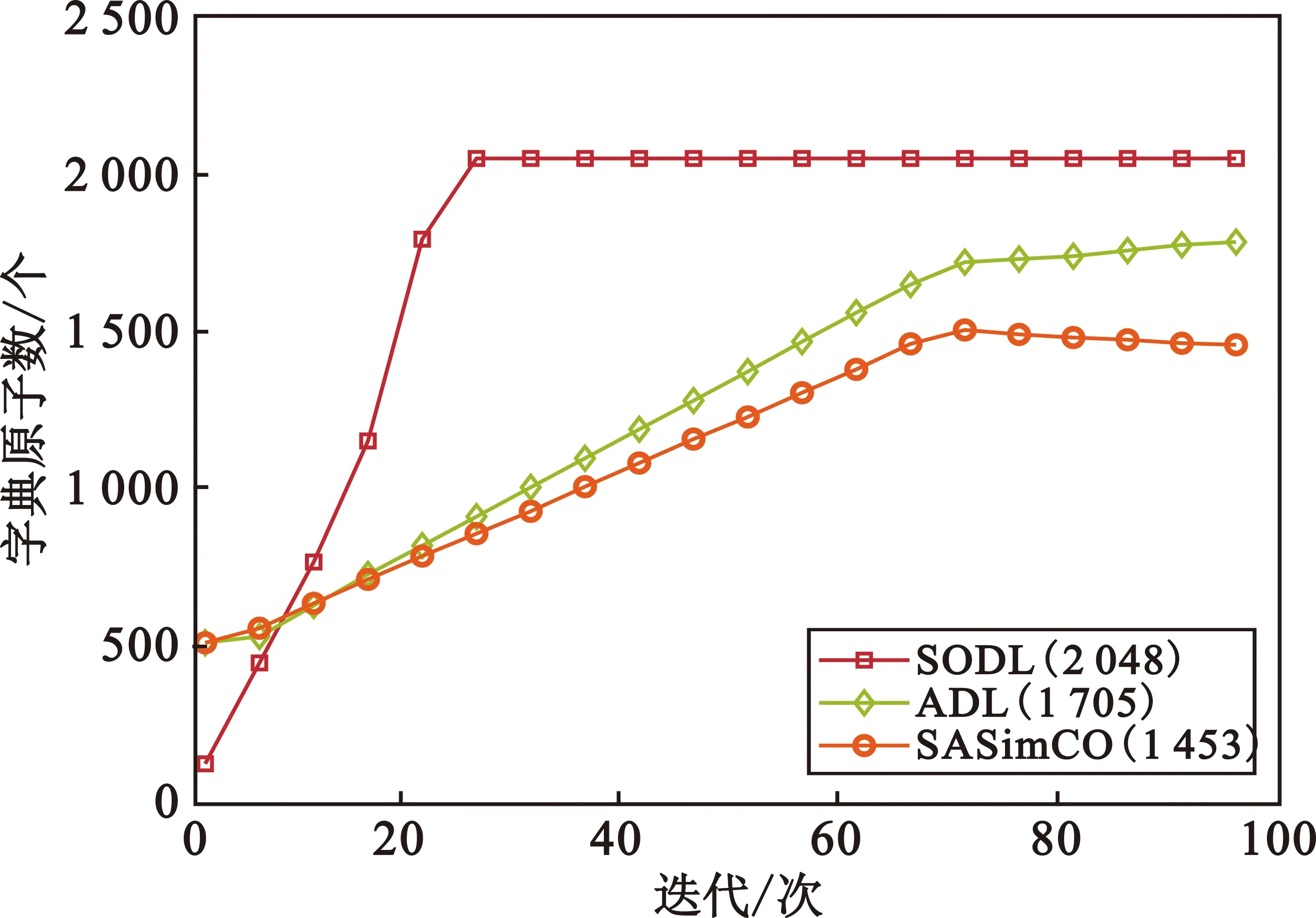
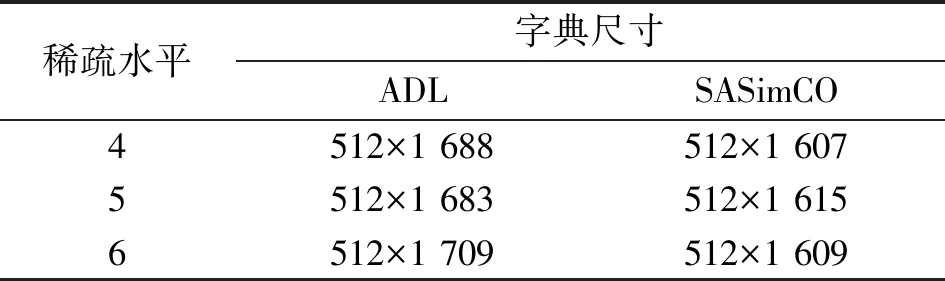
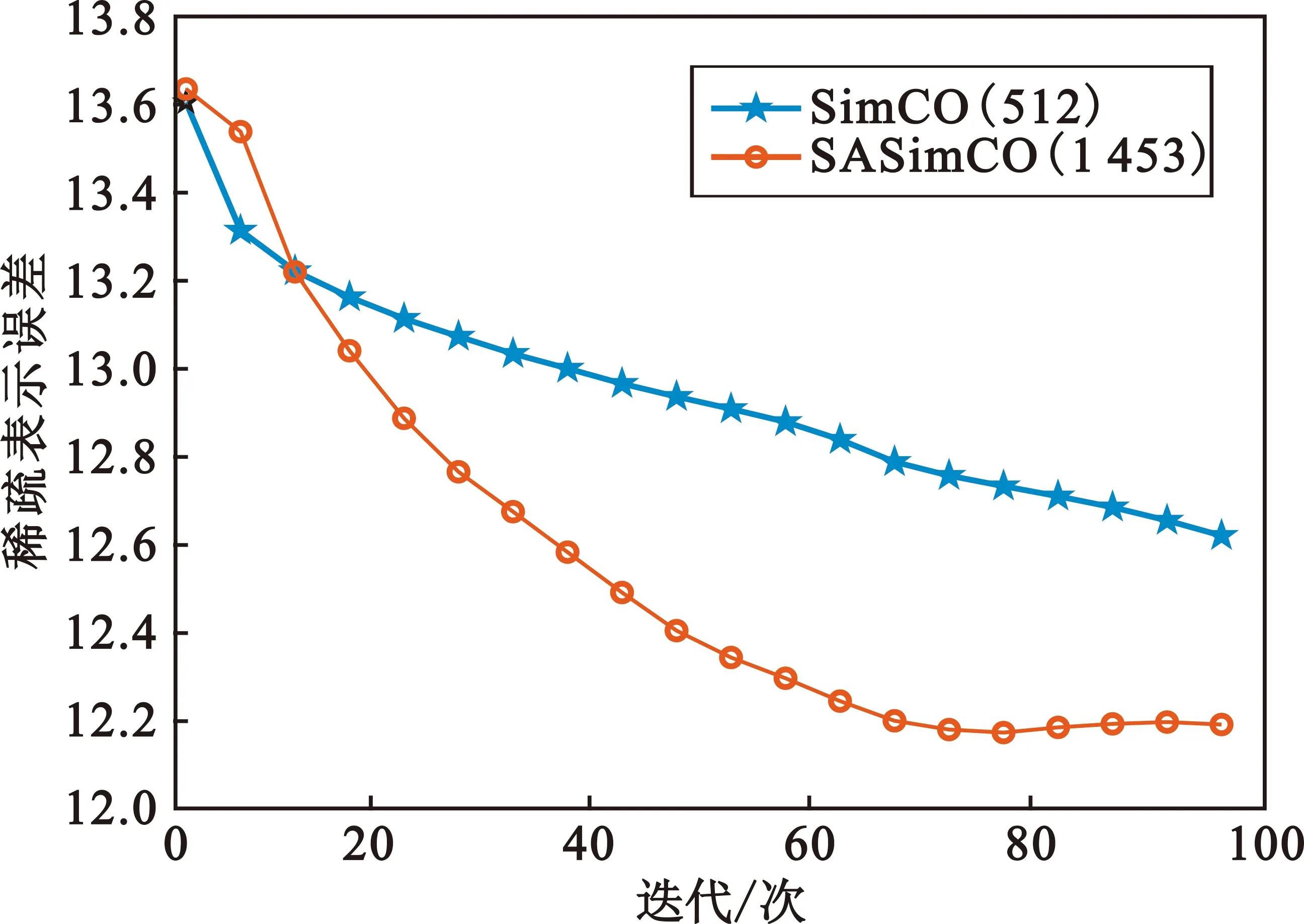
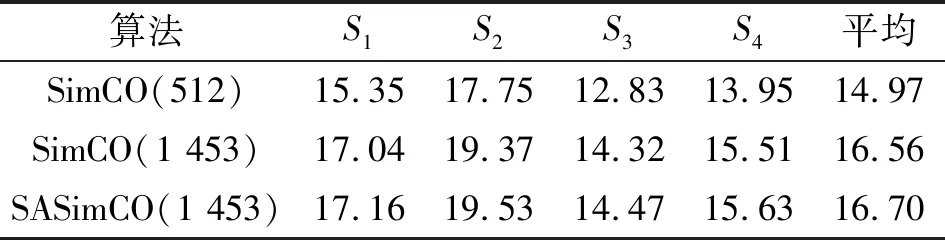
式中:X∈m×T表示m个真实已知的观测信号,T表示样本点;S∈n×T表示n个未知的源信号,需要通过重构算法恢复;A∈m×n表示混合矩阵,需要从X中估计。该模型的目的是求解在m (2) 现把式(2)简写成 b=Hf。 (3) 式中:f,b和H表示变换后的元素,f表示源信号,b表示观测信号,H表示混合矩阵。假设f在字典域是稀疏的,那么f可以写成 f=Dy。 (4) 式中:D∈M×K表示字典,K表示字典原子数量;y表示稀疏系数。根据式(3)和式(4),可以得到 b=HDy。 (5) 式中:H本质上由混合矩阵估计算法估计得到,字典D由字典学习算法训练得到,b由已知的观测信号X变换而来。至此,源信号f可由稀疏信号恢复算法得到。 SASimCO算法具有优化字典尺寸的策略,它根据训练数据自适应地优化字典尺寸。该策略的关键在于设计候选矩阵,以及根据候选原子分数和字典原子“能量”在字典中添加或删除原子。首先,为了避免不恰当的初始字典尺寸影响训练字典的效果,SASimCO算法将字典尺寸设置为可选值范围的中间值,并使用离散余弦变换(Discrete Cosine Transform,DCT)来初始化字典原子。然后,SASimCO算法利用SimCO算法[13]来更新字典原子,利用正交匹配追求(Orthogonal Matching Pursuit,OMP)算法[21]进行稀疏编码。但是不同于传统的字典学习算法,SASimCO算法在预设初始字典尺寸后,执行优化字典尺寸的策略,删除无用的原子并且增加有用的原子,最会得到一个最优的字典尺寸,使得该字典对信号的稀疏表示误差最小。因此,SASimCO算法训练得到的字典尺寸与初始字典尺寸有本质的区别。SASimCO算法既可以提高训练字典的效率,又可以降低字典对信号的稀疏表示误差,是同时兼具效率与性能的算法。 SASimCO算法的伪代码如下: 输入:Y∈M×N,K0,Kmin,Kmax,L,SP,Imax,errmin 输出:D∈M×K 初始化DCT字典D0∈M×K0 fori=1 toImax Gi-1=OMP(Di-1,Y,SP) (Di,Gi)=SimCO(Y,Di-1,Gi-1) 训练候选矩阵Ui∈M×L 删除Di中很少使用的原子 将Ui中原子添加到Di (Di,Gi)=SimCO(Y,Di,Gi) 迭代停止 设计候选矩阵是为了存储能够提高字典对信号稀疏表示性能的原子,通过对残差矩阵r∈M×N进行奇异值分解(Singular Value Decomposition,SVD)来训练候选矩阵中的原子。残差矩阵r的计算方法如下: r=Y-DG。 (6) 式中:Y∈M×N表示训练数据;D表示当前字典;G∈K×N表示稀疏矩阵。对残差矩阵r执行SVD,只取前L个最大奇异值对应的的左奇异向量构成候选矩阵U∈M×L,在这些最大奇异值所对应的左奇异向量的方向上储存有残差矩阵r的重要信息。因此,候选矩阵U能最大限度地保留残差矩阵r的本质特征,并且减少了残差矩阵r的冗余信息。候选矩阵U中L个原子的候选分数Cscores可以根据式(7)来计算: (7) 式中:i0=1:L表示候选矩阵U中每列原子的索引;⊙表示哈德玛积;δ表示风险阈值;|·|表示绝对值;V∈1×N与p∈1×N分别表示矩阵|UTr|∈L×N中每列的最大值和对应的行索引;J={p≡i0}表示p中等于i0的索引集合。现在用E表示(V⊙V)∈1×N,Υ(E≥δ)∈1×N,el与Υl分别表示E与Υ的第l个元素,表示计算指定集合J中Υ(E≥δ)的非零元素个数。候选分数较高的原子在对信号的稀疏表示中发挥着重要作用,首先考虑将它们添加到字典中。在训练字典的过程中,这些重要的原子将从候选矩阵添加到字典中来减少稀疏表示误差,从而提高字典对语音信号的恢复效果。因此,候选矩阵的性能直接影响到字典对语音信号的稀疏表示效果,进而又影响到语音源信号的重构效果。 为了降低字典对信号的稀疏表示误差,需要将候选矩阵中的部分原子添加到字典中来促进语音信号的恢复效果。当候选矩阵中原子的候选分数Cscores大于候选阈值τ时(Cscores为正实数,不失一般性,τ设为1),就将该原子添加到字典中,从而减小字典对信号的稀疏表示误差,字典和语音信号之间的拟合程度可以得到提高,语音UBSS的效果就可以在很大程度上得到改善。 在字典域对语音信号进行稀疏表示时,字典中有部分原子没有被使用或很少被使用。为了优化字典尺寸,提高语音信号的恢复效果,应该从字典中删除这部分原子。受到字典学习问题即式(8) (8) 启发,有 (9) 式中:dj表示字典的第j列;gj表示稀疏矩阵的第j行。由于每一列字典原子dj都对应着特定的稀疏系数gj,因此原子的重要性,即原子“能量”,可以通过其稀疏系数来表达。原子“能量”Oenergy根据以下公式计算: (10) 式中:ζj={l|gjl≠0}表示gj中第j行非零元素的位置,j=1:K,l=1:N。“能量”越高,原子的重要性就越大。具有较低“能量”的原子首先考虑从字典中删除,这样可以保证字典中没有无用或很少使用的原子,在保证不增大误差的同时又缩小了字典尺寸。 在训练字典之前,考虑到语音信号的短时平稳性[22-23],并且每一帧语音成分都存在差异性,首先将语音训练数据分帧处理,然后逐帧去训练字典原子,从而应用SASimCO算法来优化语音UBSS的字典尺寸。训练好的过完备字典在字典域中对混合语音进行稀疏表示,然后经过分离系统,在时域重建分离后的语音源信号。 图1 基于SASimCO算法的欠定盲语音分离框架 实验在Matlab R2020a中进行仿真,实验数据来自SiSEC “Underdetermined speech and music mixtures development 2”数据库的4个男声和女声。每段语音信号持续时间为10 s,采样频率为16 kHz,这意味着每段语音信号有T=160 000个样本点。该实验中预定义的混合矩阵A为 (11) (12) 图2 语音源信号混合与恢复 语音源信号的分离性能可以通过信噪比(Signal-to-Noise Ratio,SNR)来衡量[28]: (13) 4.2.1 候选原子数对源信号分离效果分析 本节评估不同候选原子数L对所提算法性能的影响。候选原子是候选矩阵U的基础,字典训练过程中会选择U中的候选原子添加到字典。L越多,U中存在重要候选原子的机会就越大,从U向字典添加重要的候选原子数量也会变多。通过L,可以间接地控制添加候选原子到字典的数量,从而影响所提算法的性能。图3展示了实验数据为4个女声时,本文算法在不同L下语音源信号分离的平均SNR结果。根据实验结果可以看出,随着L的增加,语音源信号的分离性能逐渐增加。本文综合考虑了算法性能与计算成本,将L设置为20,并将用于后续实验。 图3 不同L下语音源信号分离的平均信噪比 4.2.2 字典学习算法对源信号分离效果分析 本节将SASimCO与上述几种主流的字典学习算法在语音UBSS中的效果进行比较,算法的测试参数完全相同,实验结果如表1和表2所示。通过对比发现,在每路源信号恢复结果或者平均恢复结果上,本文提出的SASimCO算法比其他字典学习算法的源分离性高1~3 dB,性能优势较为明显。 表1 恢复4个女声的SNR结果 单位:dB 表2 恢复4个男声的SNR结果 单位:dB 为了探究SASimCO算法在训练字典过程中对字典尺寸的优化性能,使用4个女声为实验数据,图4展示了ADL、SODL和SASimCO在迭代过程中字典原子数的变化情况。可以看出,SODL在迭代过程中首先达到规定预设的最大尺寸,并保持字典原子数2 048不变。ADL在迭代过程中逐渐增加字典尺寸,最终字典原子数为1 705。SASimCO在前期迭代中,从候选矩阵添加了大量重要的原子到字典;在迭代后期,删除了字典中较多“能量”低的原子,最终SASimCO训练的字典原子数为1 453。ADL和SASimCO在不同数据的多个稀疏水平下对字典尺寸优化的结果如表3和表4所示。当面对不同的语音数据时,ADL获得的字典尺寸没有太大差别,但SASimCO获得的字典尺寸却有明显不同。相比于SODL与ADL,SASimCO优化字典尺寸的策略最成功,并且经过SASimCO训练得到的字典尺寸最小,降低了训练字典的成本。 图4 字典原子数在迭代中的变化情况 表4 男混合语音的字典尺寸优化结果 信号在字典域中的稀疏表示误差定义为 err=‖Y-DG‖F。 (14) 误差越小,字典对信号的稀疏表示性能就越好。SimCO和SASimCO在训练字典的过程中误差变化情况如图5(a)所示,实验数据为4个女声。SimCO在100次迭代训练的过程中,字典原子数保持512不变;SASimCO在优化字典尺寸的过程中,字典原子数由初始的512变为1 453。由图5(a)可知,SimCO训练的字典稀疏表示误差约为12.6,SASimCO的误差约为12.2。SASimCO误差下降的幅度与速度都优于SimCO,具有明显优势。 (a)迭代100次 (b)迭代1 000次图5 稀疏表示误差在迭代中的变化情况 由于图5(a)中误差没有达到稳定状态,为了进一步验证SASimCO对字典的优化性能,在前100次迭代训练的基础上增加了900次的迭代训练。在900次的迭代训练中,SASimCO字典原子数保持1 453不变,只更新字典原子不再优化字典尺寸。SimCO在字典原子数分别为512与1 453时,迭代1 000次的误差变化情况如图5(b)所示。当原子数为512时,SimCO的误差约为10.5,SASimCO训练的字典误差约为9.5;SimCO在字典原子数为1 453时的误差与SASimCO相近,但是SimCO获取与SASimCO相同的字典尺寸有一定滞后性。只有当SASimCO训练得到最优的字典原子数1 453时,SimCO才能设置与SASimCO相同的字典尺寸;在SASimCO训练字典结束之前,SimCO的字典原子数并不知道该设置为1 453。因此,SASimCO在优化字典尺寸的策略上是成功的。 SimCO与SASimCO训练1 000次后的字典用于语音UBSS的SNR结果如表5所示。即使当SimCO设置与SASimCO相同的字典尺寸,其训练的字典用于语音UBSS的效果依然不如SASimCO。主要原因是SASimCO训练字典的策略包括更新原子与优化尺寸,它不仅可以将候选矩阵中候选分数较高的原子增加到字典,还可以删除字典中“能量”低的原子,而SimCO只单纯地更新字典。 表5 训练1 000次的字典恢复4个女声的SNR结果 单位:dB 综上所述,经过SASimCO训练得到字典的稀疏表示性能比SimCO更好,用于语音UBSS具有明显的优势。 为了衡量算法的复杂度,表6展示了不同字典学习算法训练一次字典所需CPU运行时间的对比结果,可以看到SimCO算法运行时间最短;由于SODL需要对一组字典尺寸进行遍历,所以花费时间最多;由于本文算法需要进行字典尺寸更新的策略,故其运行时间高于SimCO算法;但是SASimCO运行时间比同类需要优化字典尺寸的ADL算法降低了约17.2%,比SDOL算法降低了约66.3%,具有明显的实用价值。 表6 不同算法的CPU运行时间 本文提出SASimCO算法来解决传统字典学习算法不能优化字典尺寸的问题,根据不同的训练数据自适应地获得不同大小的字典,在很大程度上增强了字典域中语音信号的稀疏表示性能。从多个角度的验证表明,SASimCO算法比基于先验知识预先定义字典尺寸的方法更灵活,并且比其他优化字典尺寸算法训练的字典更紧凑,用于语音UBSS具有明显的优势。然而,本文算法可能对噪声缺乏鲁棒性,在接下来的研究工作中将重点考虑噪声环境下的欠定盲语音分离问题。1.2 稀疏信号恢复模型

2 SASimCO算法

2.1 训练候选矩阵
2.2 添加原子
2.3 删除原子
3 基于SASimCO算法的欠定盲语音分离框架


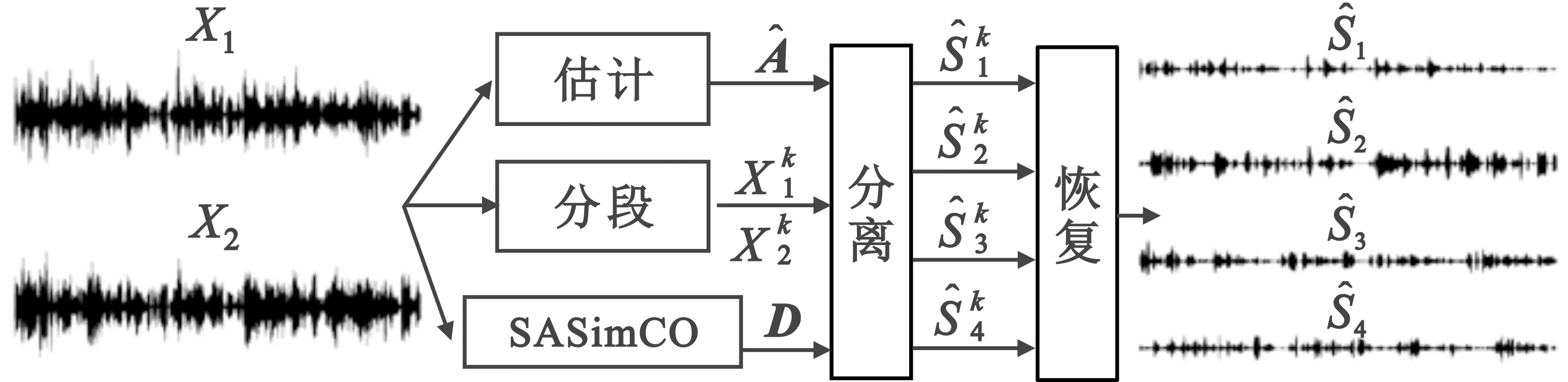
4 仿真与分析
4.1 实验仿真


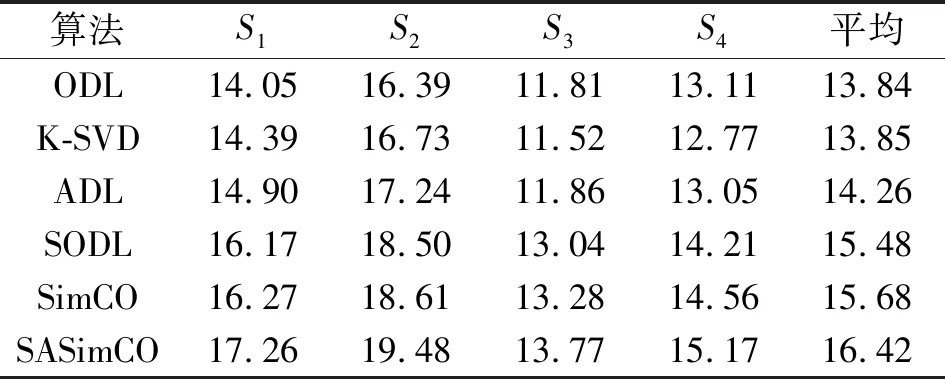
4.2 源信号分离效果分析
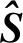

4.3 优化字典性能分析
4.4 稀疏表示误差分析

4.5 运行时间分析

5 结束语
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 06:42:32
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
