
融合多尺度特征的复杂手势姿态估计网络
2023-09-26 04:22:16贾迪李宇扬安彤赵金源
中国图象图形学报 2023年9期
贾迪,李宇扬,安彤,赵金源
1.辽宁工程技术大学电子与信息工程学院,葫芦岛 125105;2.辽宁工程技术大学电气与控制工程学院,葫芦岛 125105
0 引言
手势估计(鲍文霞 等,2019;王银 等,2021)的目标是对图像中人手的关键点进行识别和定位,在虚拟现实(virtual reality,VR)和增强现实(augmented reality,AR)中有着广泛应用,是计算机视觉领域的一个重要研究课题。与传统方法相比,基于深度学习的方法在处理速度和预测精度上都有明显优势,然而受摄影环境复杂与多样性(手形、遮挡等)的影响,导致手势估计的鲁棒性不高。
多数方法依赖于深度相机,如Tompson 等人(2014)首先利用深度神经网络估计每个手部关节的二维热图来定位手部关键点,但热图仅提供了关节点二维信息,并没有充分利用深度信息,而深度信息包含了空间中各点相对于相机的距离,这对三维手势估计有重要作用。Chen 等人(2020b)先利用最初估计的手势作为引导信息提取有效关节特征,再融合同一手指的关节特征形成手指特征;最后通过融合手指特征回归出手势。但相较于只连接中指和手掌的方法(Fan 等人,2021),采用多手指同时连接手掌的方法会造成一定精度的损失。Liu 等人(2020)对不同空间视角的二维平面进行手势估计,每个路径从分解后不同的空间进行潜在热图回归,通过融合网络获得最终的预测结果。Zhang 等人(2021b)充分利用了手指相邻关节间的信息估计深度坐标,利用二维手部关节估计和一部分手部关节的深度估计作为引导信息,借助引导信息可以估计相邻关节的深度坐标,进而得到所有手部关节的深度坐标。
深度相机的使用常受限于应用环境,因此一些学者采用直接从RGB 图像上估计手部姿态。Zimmermann 和Brox(2017)提出一种深度神经网络,从数据中学习相关潜在信息预测隐式手部关节。由于缺少真实图像与不同姿态大规模数据集的标注,降低了该模型识别手部姿态的准确性。Simon 等人(2017)从多视图图像中估计二维手部姿态,并将其扩展到三维空间中,但不能通过单幅RGB 图像(Mueller 等,2018)估计手部姿态。Cai 等人(2018)通过深度正则化器将RGB 图像估计的手势转化为深度图,再通过深度图对手势回归进行弱监督,有效解决了获取真实三维标注的问题,但严重依赖RGB和深度图像配对的准确性。Panteleris 等人(2018)采用深度学习模型解决二维手部检测和关节点定位问题,再使用生成模型拟合为非线性最小二乘优化问题来获得手部姿态。Iqbal 等人(2018)通过卷积神经网络(convolutional neural networks,CNN)架构隐式重构了深度图和2.5D热图,并从中估计出三维手关键点坐标,但在深度图像中存在严重自遮挡的情况,因此难以获得准确的结果。Spurr 等人(2018)采用RGB 图像训练编码器—解码器对,以不同的输入方式估计完整的三维手部姿态,由于没有充分利用手部结构,丢失了大量的手部结构信息。Yang 和Yao(2019)通过解纠缠变分编码器学习手部姿势和手部图像来实现图像的合成和姿势估计,但分解过程可能损失一些有助于生成有用数据的信息。Ge等人(2019)引入图卷积网络估计三维手部网格从而回归手部姿态,但是现有数据集中,真实三维手部网格难以获得。Baek 等人(2020)采用神经渲染器实现了从RGB 图像中估计手势姿态,先估计二维关节点和三维网格模型参数,再采用二维分割掩膜和基本骨架来拟合三维模型。Chen 等人(2020a)采用条件生成对抗网络构成深度映射重构模块,以此生成彩色图像的伪真实深度图像,并将配对后的彩色图像和伪真实深度图像作为手部姿态估计模块的输入,虽然避免了输入真实深度图像,但在伪真实深度图像和真实深度图像之间仍然存在差距,导致估计精度较低。Kong 等人(2020)利用旋转网络获得旋转角度,通过旋转角度对图像进行旋转,同时进行后期的手势姿态估计,在有遮挡的情况下也能缓解手部关节点间的几何不一致性。Moon 等人(2020)提出一个包含大尺度高分辨率的单手和交互手序列的数据集,并提出一种InterNet 模型通过单幅RGB 图像估计手势姿态,但由于没有考虑到手指边缘的局部细节信息,因此在有遮挡手势的情况下,结果准确率较低。Chen 等人(2021)从RGB 图像中获取二维姿态、形状和纹理等几何信息,并利用二维和三维间的一致性,从有噪声的几何信息中获取精确的手部重建模型。Zhang等人(2021a)先采用两层沙漏网络获取图像特征图和21 个关节点热图,再通过Res2d模块更新初始关节点位置,提高模型泛化能力,最后通过编码解码的方式从二维坐标获取三维坐标。Ishii等人(2021)通过多个并行的图卷积网络估计不同方向的三维姿态,再融合多个方向的姿态获取估计的三维姿态。在现实场景中,只有小部分手势是简单的单手姿态,大部分手势都是复杂的交互手姿态,降低了上述方法的实用性。
边缘信息在手姿态估计中易被忽略,这类信息对于提取遮挡部分的手势姿态更重要。此外,由于指尖较小,因此在指尖识别关节相对困难。为了解决该问题,提出一种多尺度特征融合网络(multiscale feature fusion network,MS-FF),用于构建包含丰富细节和全局信息的特征图,以此提高手势估计结果的鲁棒性。本文主要贡献如下:1)提出一种多尺度特征融合网络模型,能够更好地处理不易识别的关节点和解决遮挡场景中手势识别不准确的问题。2)不同特征通道包含不同的隐式信息,有些特征通道信息中包含了更多的关节点位置信息,而其他特征通道信息含有干扰信息。因此,本文设计了通道变换模块,用于调整特征通道的比重,增强重要特征通道信息,弱化次要特征通道信息,以便全局回归模块和局部优化模块可以更好地利用特征图的信息,从而加快收敛速度。3)指尖在图像中为小区域,相对其他关节点更加难以识别。为了更好地识别指尖关节点的位置,本文通过构建全局回归模块获得包含丰富全局信息的高分辨率特征图,这些信息可以帮助更精确定位这些关节点的位置。该模块融合不同分辨率的特征图,较好地利用了图像边缘细节与全局信息。4)全局回归模块可能无法准确识别遮挡环境中的手势姿态。本文采用局部优化模块从全局回归模块获得的特征图中挖掘潜在信息,再融合全局回归模块中所有层级的特征图,对部分没有回归到正确位置的关节点进行适当修正,从而能更好地处理遮挡问题。
1 本文方法
1.1 网络总体架构
手势图像通常包含复杂的细节特征,手指间与关节间具有较强的关联性,因此仅使用单一特征进行手势估计往往会忽视多样化特征,导致难以准确提取到更多的手势信息。本文提出的多尺度特征融合网络如图1 所示,目的是通过单幅RGB 图像进行手势估计。首先,通过ResNet50(50-layer residual network)模块从RGB 图像中提取不同分辨率下的特征图。其次,将该特征图输入到通道变换模块中,显式地学习特征通道间的依赖关系,即增强相对重要的特征通道信息,弱化次要信息。由于不同分辨率的特征图包含不同程度的特征信息,因此通过全局回归模块可以获得包含更多的全局信息的高分辨率特征图,并将结果分别输入到局部优化模块中,提取特征图更深层次的特征信息,获得手部关节点的高斯热图(HQ),提高模型的空间泛化能力。该热图的维度为64 × 64像素,目的是从更大的空间上获取关节点可能存在的位置,从而获得更精确的关节点位置。最后,取出通道变换模块处理的最小尺寸特征图,获得手势类别(hQ)及腕关节间相对深度信息(zR→L),综合上述结果共同估计手势姿态。即
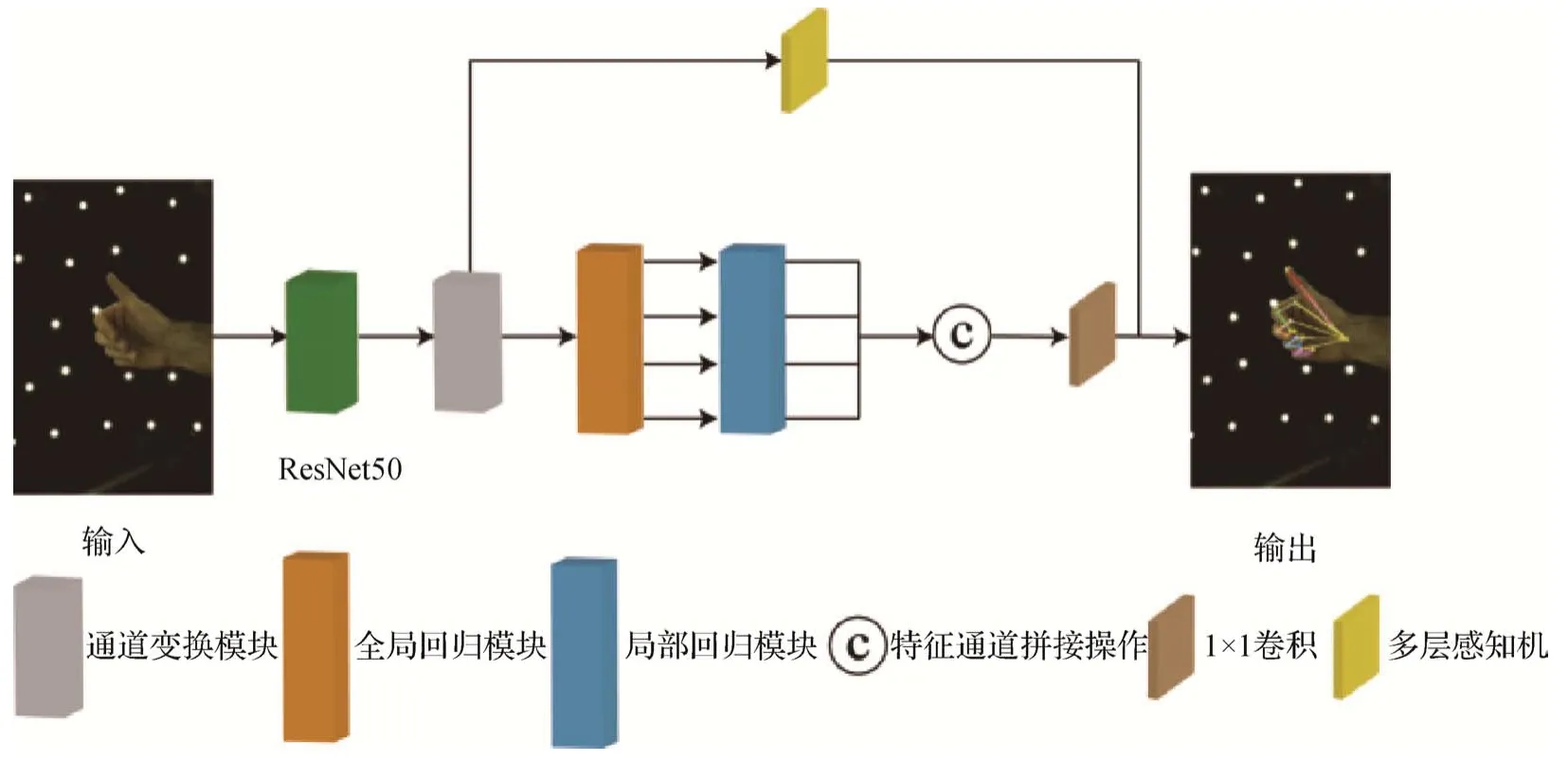
图1 多尺度特征融合网络结构Fig.1 Structure of multiscale feature fusion network
式中,To表示MS-FF 方法,In表示输入的图像信息。手势估计的结果为
式中,Π和t-1分别表示相机逆投影和逆仿射变换。
1.2 通道变换模块
特征图中每个特征通道包含不同特征信息,对于能更好地表征关节点信息的特征通道应赋予更高权重。为了更好地利用不同特征通道的特征信息,对特征图通道之间的关系进行显式建模,学习每个特征通道的权重并进行特征重标定,依照权重大小增强有效特征通道信息,以此提高网络模型对重要特征信息的敏感性,结构设计如图2所示。
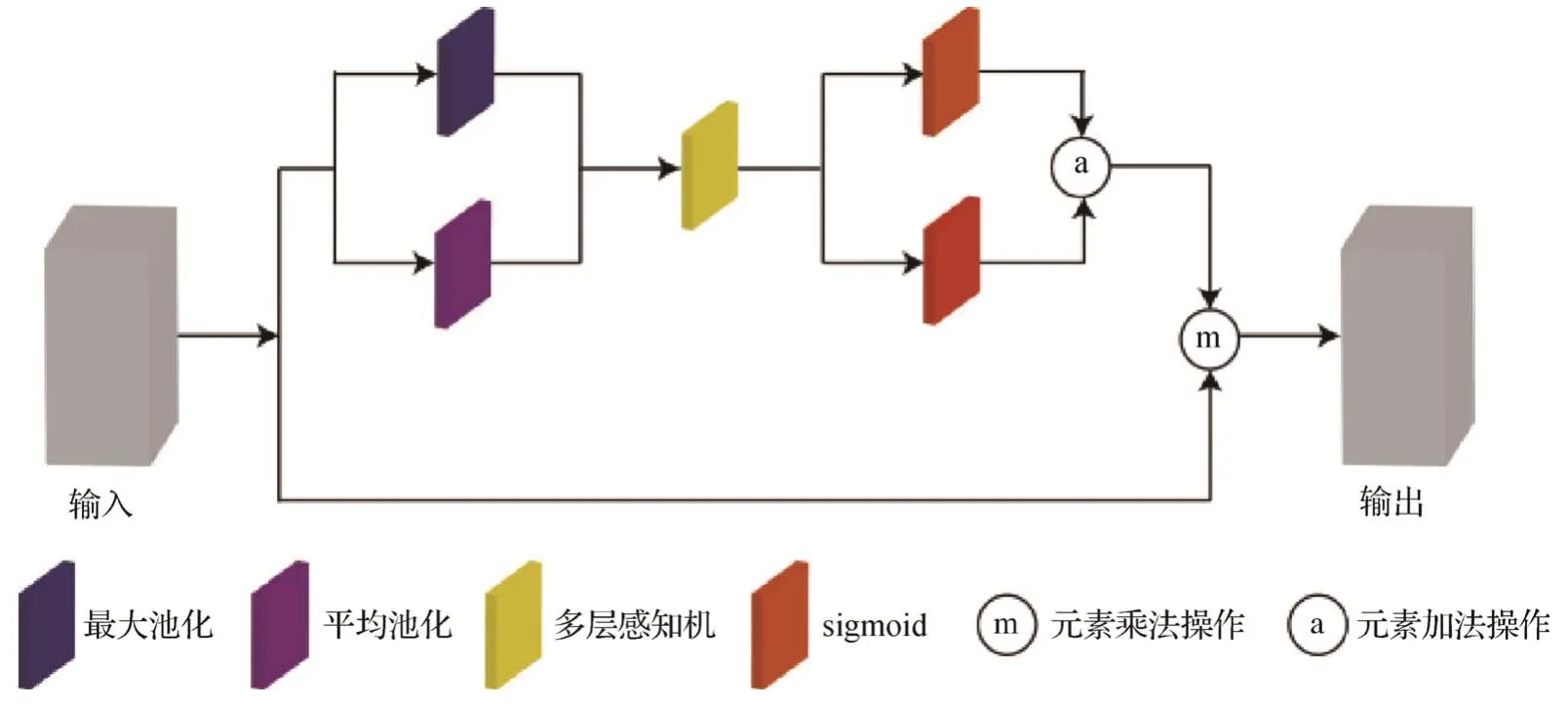
图2 通道变换模块结构Fig.2 Structure of channel conversion module
平均池化可以获取空间聚合信息,最大池化可用于提取每个特征通道最敏感的信息。因此本文对每个特征通道的特征矩阵采用最大池化和平均池化相结合的方式获得更加丰富的描述信息。首先,将初始特征图u分别以平均池化和最大池化的方式获得特征通道描述符,该信息通过全连接层学习特征通道间的依赖关系。然后,经sigmoid 激活函数生成权重向量,以此表征每个特征通道的重要程度。最后,将权重向量与原特征图相乘得到重新分配权重后的特征图,该特征图可以增强重要信息并弱化次要的信息。权重向量的计算过程为
式中,Ma表示对特征图进行最大池化操作,Av表示对特征图进行平均池化操作,Ml由两个全连接层组成,用以获取特征通道间的依赖关系,φ为sigmoid激活函数,对特征图的通道信息进行重新标定。具体为
1.3 全局回归模块
ResNet50 模块会产生不同分辨率特征图,其中高分辨率下的低层特征图包含全局信息较少,但空间细节信息丰富;低分辨率的高层特征图拥有丰富的全局信息,但空间细节信息较少。为充分利用不同维度的特征信息,将低分辨率特征图与高分辨率特征图通过纵向与横向路径结合。在纵向路径上,将低分辨率的高层特征图通过上采样的方式构造高分辨率特征图,该特征图具有丰富的全局信息,再将低层特征图通过1 × 1 卷积处理,减少特征通道数,以此获得与之对应纵向路径下同维度的特征图。横向路径融合上述两个特征图,得到所需的融合特征图,结构如图3 所示。这种金字塔式结构可以融合不同分辨率下的特征图,以此包含更多的全局信息,使网络学习到更加丰富的特征信息。

图3 全局回归模块结构Fig.3 Structure of global regression module
图3 中,令ResNet50 模块和通道变换模块得到的特征图Conv2—Conv5 表示为{C2,C3,C4,C5}。其中,C2与C3具有更大的空间分辨率,但包含的深层特征信息较少;C4和C5具有更多的深层特征信息,但空间分辨率较低。融合不同特征图不仅能获取丰富的手部特征信息,还能获得像指尖部分和遮挡边缘部分的细节信息。对不同维度的特征图进行降维操作,将特征图的通道统一到同一维度下,以便融合它们的特征信息。具体为
式中,Vk为降维过程得到的特征图,Uk为上采样操作得到的特征图,R1为卷积核大小为1 × 1的卷积操作,δ为ReLU(rectified liner unit)激活函数,B为双线性插值的上采样操作。通过4 个周围已知像素的坐标点计算新图像中对应的点P,其计算式为
式(7)(8)是在x方向上进行线性插值操作,式(9)是在y方向上进行线性插值操作。e1和e2是Q11、Q12和Q12、Q22分别在x方向上进行线性插值后得到的两个点。Q11、Q12、Q21和Q22分别为原图像中的4个 点,其坐标分别为(x1,y1)、(x1,y2)、(x2,y1) 和(x2,y2),P点是经过上采样操作得到的点。将Vk和Uk+1进行加法操作,即可融合不同空间分辨率下的特征信息,即
1.4 局部优化模块
为减少全局回归模块产生的误差,通过局部优化模块修正遮挡等条件下预测关节点位置不准确的问题。该模块在不同层次的特征图上提取特征,并通过上采样与拼接操作整合不同的层次信息。如图4 所示,局部优化模块通过两条路径处理上述特征图,其中一条路径包含1 × 1 的卷积,另一条路径分别由1 × 1、3 × 3 和1 × 1 的卷积组成。通过该路径继续提取全局信息,并采用通道变换模块构建特征通道间依赖关系,增强重要的信息并弱化次要信息,通过残差连接解决网络退化问题,提高网络的表征能力,采用双线性插值的上采样操作获得大分辨率特征图。

图4 局部优化模块结构Fig.4 Structure of local optimization module
从全局回归模块中取出4 个不同分辨率的特征图,通过局部优化模块获得相同维度特征图,过程为
式中,O为局部优化模块,B为上采样操作。令m=2,4,8,16,则I1/4,I1/8,I1/16和I1/32分别表示在原始图像1/4、1/8、1/16 和1/32 尺度下的特征图。式(12)的计算结果表示上述4 个特征图经局部优化模块的处理次数,得到的结果分别为和此时4个特征图具有相同维度,再进行拼接操作(Cas),过程为
通过1 × 1卷积得到关节点的2.5D高斯热图为
式中,R1表示卷积核大小为1 × 1的卷积操作。
2 实 验
2.1 实验环境
实验采用的CPU 型号为Intel Core i9-10900,内存32 GB,显卡型号为NVIDIA 3090,操作系统为Ubuntu,开发框架选用PyTorch。
2.2 实验数据
实验在RHD(rendered handpose dataset)和Inter-Hand2.6M 数据集中进行。RHD 数据集包含不同视角和背景下合成的39 个手部动作,由41 258 幅训练图像和2 728幅测试图像构成。InterHand2.6M 是一个大规模真实数据集,由单手和交互手序列的手部姿态构成,采用人工和机器两种标注方式,将Inter-Hand2.6M 分为InterHand2.6M(H)、InterHand2.6M(M)和InterHand2.6M(H+M)。InterHand2.6M(H)包含528 482 幅训练图像和121 573 幅测试图像,InterHand2.6M(M)包含909 037 幅训练图像和727 587 幅测试图像,InterHand2.6M(H+M)包含1 361 062 幅训练图像和849 160 幅测试图像,测试集包含380 125幅验证图像。
2.3 评价指标
本文将手势类别分为左手手势、右手手势以及交互手手势。采用手势类别准确率(average precision of handedness estimation,APh)、根节点平均误差(mean relative-root position error,MRRPE)和关节点平均误差(mean per joint position error,MPJPE)3 种评估指标评估手势预测结果。具体为
式中,m为将手势类别预测正确的图像数量,n为所有手势图数量为真实右手相对左手的深度,表示预测的关节点位置,p表示真实关节点位置。
2.4 实验设置
将原始图像尺寸裁剪为256 × 256 像素,并输入到网络中。批量大小设置为16,进行20轮训练。初始学习率为0.000 1,在第15 和17 轮分别将学习率减少到之前的1/10,从而使网络的输出结果能够尽可能接近最优值。网络的总体损失为
式中,Lrel表示右手相对左手深度的损失,Lpose表示手部关节点损失,Lh表示手势类别损失。具体为
式(19)采用L1 损失判定右手相对左手深度的误差。式(20)采用L2 损失函数计算手部关节点误差,HQ*采用高斯公式计算关节点的真实高斯热图,Q∈(R,L)表示RGB图像中包含哪只手。式(21)采用二元交叉熵损失函数计算手势类别误差,gQ代表左右手是否存在,hQ表示属于相对应手势类别的概率值。
2.5 实验结果
图5给出了PoseNet、InterNet和本文方法的手势估计结果。由于手势关节点大多比较灵活,且手势交互时会存在遮挡情况,因此通过单幅RGB 图像进行手势的估计较为复杂。由图5(b)B 列和D 列可见,PoseNet 网络无法准确估计单手和交互手的姿态。采用InterNet和本文方法估计图5A列的手部姿态,由结果可见,预测单手姿态相比预测交互手姿态更为准确。图5(a)的A 列和B 列为手部姿态相对简单的单手姿态图,在采用InterNet 方法的预测结果(图5(c)A 列)中,无名指的指尖关节点被预测在中指的位置上,采用本文方法(图5(d)A 列)对该关节点的位置做出修正,更容易区分中指和无名指的姿态。在InterNet方法预测的结果(图5(c)B 列)中,由于该手势相对复杂,使得拇指和食指指尖关节点的预测位置“粘合”在一起,并且其余3 指的姿态也比较混乱,采用本文方法(图5(d)B 列)能够区别拇指和食指指尖位置并更清晰地识别手势。图5(a)的C 列和D列为存在手指自遮挡和双手相互遮挡的手部姿态,因而在估计手势时比预测单手姿态更加困难。采用本文方法能够在一定程度上解决InterNet方法识别不准确的问题。在InterNet 方法估计的手势(图5(c)C 列)中,左手的姿态没有被精确地预测出来,而且右手部分手指的关节点被预测在左手上;采用本文方法(图5(d)C 列)能更好地估计左手的手势,也能更好地区分不同手指的关节点位置。在采用InterNet 方法估计的手势结果中(如图5(c)D 列),手部关节点的预测位置较为混乱,采用本文方法(图5(d)D 列)可以更好地区分出两只手,并且能更准确地获得关节点位置。

图5 不同方法在测试集的预测效果Fig.5 Prediction results of different methods in the test set((a)RGB images;(b)PoseNet(Zimmermann and Brox,2017);(c)InterNet(Moon et al.,2020);(d)MS-FF(ours))
在InterHand2.6M 数据集上,采用PoseNet、InterNet 和本文方法进行实验,得到的评估指标如表1和表2所示。由表可见,与InterNet方法相比,本文方法在不同测试集上均取得更好的结果。选用InterHand2.6M(H+M)数据集作为训练集,与Inter-Net方法获得的评估指标相比,本文方法获得的评估指标中,根节点的平均误差(MRRPE)、单手上关节点的平均误差(MPJPE(S))和交互手上关节点的平均误差(MPJPE(I))均取得了更低的误差值,分别为30.92 mm、11.10 mm 和15.14 mm,相比InterNet 方法获得的指标降低了5.1%、8.3%和5.8%。模型的初始参数值是通过正态分布的方法随机产生的,在每次迭代优化后得到的参数也会略有不同,因而得到的APh值也有区别,但APh值并未大幅下降。

表1 不同方法在验证集(M)和测试集(H)数据集的测试结果Table 1 Results of different methods on Val(M)and Test(H)datasets
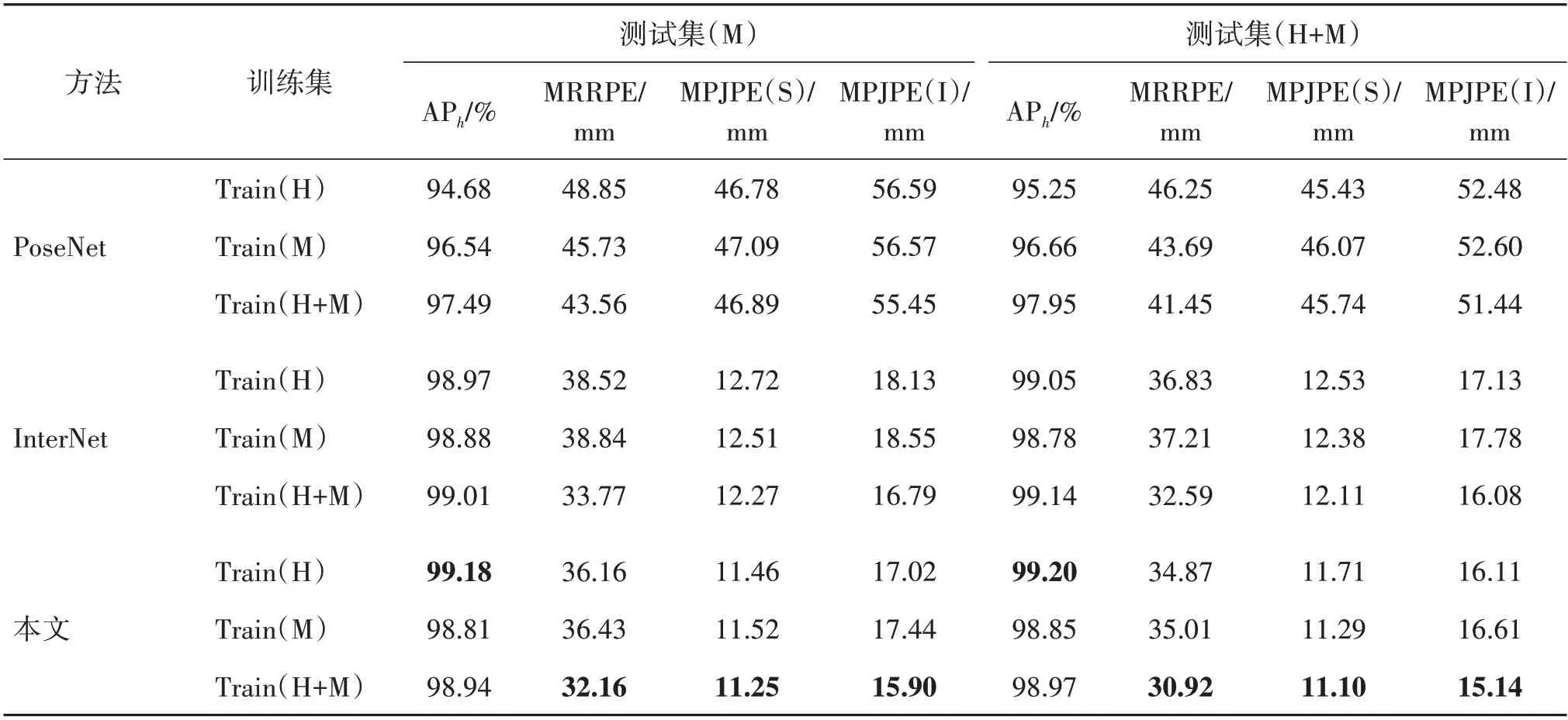
表2 不同方法在测试集(M)和测试集(H+M)数据集的测试结果Table 2 Results of different methods on Test(M)and Test(H+M)datasets
为了进一步验证本文方法的性能,采用不同方法对单手和交互手图像进行测试,并将左右手关节点的平均值作为各关节点误差,结果如图6和图7所示,其中,t,i,m,r,p分别表示拇指、食指、中指、无名指和小指,1,2,3,4对应手指根部关节点到手指指尖关节点。可以看出,相比预测靠近手掌的关节点,预测靠近指尖的关节点更为困难,本文方法在不同手指关节点上的平均误差率均低于其他对比方法。

图6 不同测试集上单手关节点平均误差Fig.6 The mean per joint position error of single hand on various testing set((a)test(H);(b)val(M);(c)test(M);(d)test(H+M))

图7 不同测试集上交互手关节点平均误差Fig.7 The mean per joint position error of interacting hand on various testing set((a)test(H);(b)val(M);(c)test(M);(d)test(H+M))
表3 是不同方法的参数比较。可以看出,由于MS-FF 需要提取并融合多个分辨率特征图的潜在信息,因而训练和测试时间都比其他方法要长。与其他方法相比,在提高识别精度的同时,具有模型参数少、计算复杂度低(表3 中Flops 数值较小)的特点。InterNet网络采用ResNet50模块,生成的特征图维度为2 048,对其进行反卷积操作会产生大量参数,增加了计算复杂度。MS-FF 在全局回归模块中通过1 × 1 卷积,将4 个不同分辨率特征图的维度降低至256,减少了后续网络计算的相关参数和计算量。在局部优化模块中,MS-FF 采用1 × 1、3 × 3 的卷积操作提取图像特征,采用双线性插值操作获得更大尺度下的特征图,该操作同样会减少模型的参数与计算量。由于MS-FF 从4 个不同分辨率下的特征图提取全局和局部信息,构建过程比InterNet网络更为复杂,因此造成了碎片化(Ma 等人,2018)的特点。这种情况下,MS-FF 的串行化等待将增加时间开销。此外,其内核启动与同步时间开销也将增加,导致MS-FF 在时间开销上高于InterNet 网络,因此MSFF 的运行速率(28 帧/s)低于InterNet 的运行速率(53帧/s)。
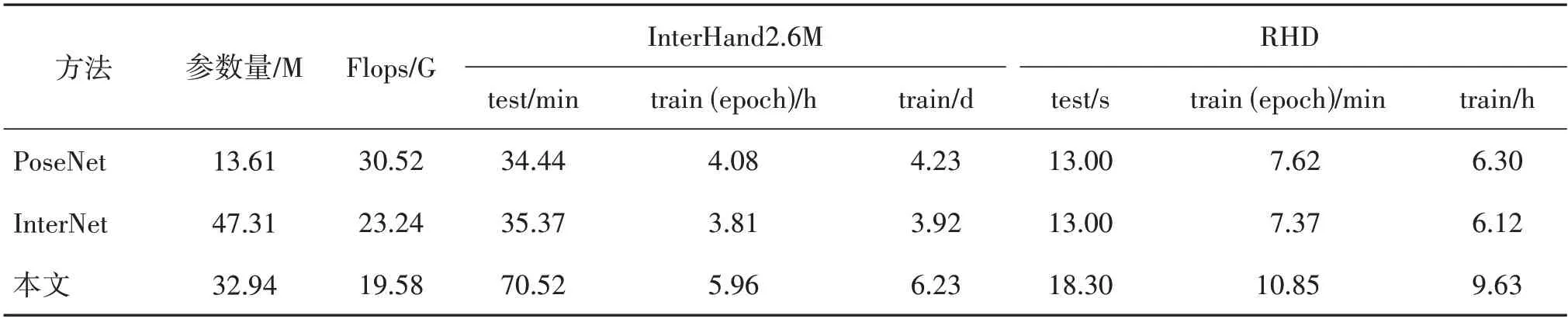
表3 不同方法的参数比较Table 3 Comparison of parameters of different methods
表4 给出了不同方法在RHD 数据集上的实验结果,GT H(ground truth handness)和GT S(ground truth scale)分别表示测试时需要使用真实的手部类别和尺寸,EPE(end point error)为关节点的平均误差。Spurr等人(2018)、Yang 和Yao(2019)的实验需要额外输入手部类别和尺寸,因而取得了较低的关节点误差。由表4 可见,本文方法在测试时即使没有真实的手部类别和尺寸,也可获得较低的误差值。
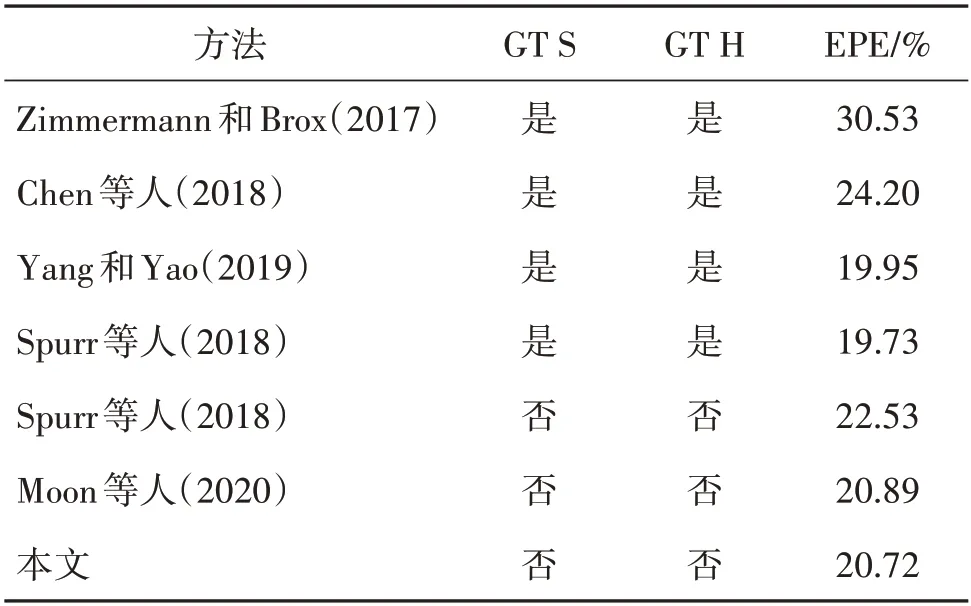
表4 不同方法在RHD数据集的测试结果Table 4 Results of different methods on RHD
2.6 消融实验
为分析本文方法中各模块的有效性,对不同模块在提高网络性能方面进行消融实验。在多尺度特征融合网络中,采用分别去除通道变换模块、全局回归模块和局部优化模块进行实验,实验数据选用32 000幅训练图像和1 000幅测试图像,批量大小设置为4,进行20 轮训练,初始学习率为0.000 1,在第15 轮和第17 轮分别将学习率减少到之前的1/10,实验结果如表5 所示。可以看出,去除全局回归模块的实验结果与整体模型的实验结果最为接近,证明该模块虽然可以融合不同特征图的空间细节信息和全局信息,但在手势估计的过程中起到的作用相对有限。去除局部优化模块的实验结果与整体模型的实验结果相差最大,因此该模块能充分利用特征图并提取深层次特征信息,能够在回归手势的方面起到较大作用,局部优化模块可以修正部分预测不准确的关节点。通道变换模块不仅需要处理由ResNet50 模块得到的特征通道信息,而且在局部优化模块中优化特征通道信息,因此也起到了较为重要的作用。该实验结果表明,在这3 个模块的共同作用下,多尺度特征融合网络的整体性能获得最大值,证明了各个模块的有效性。
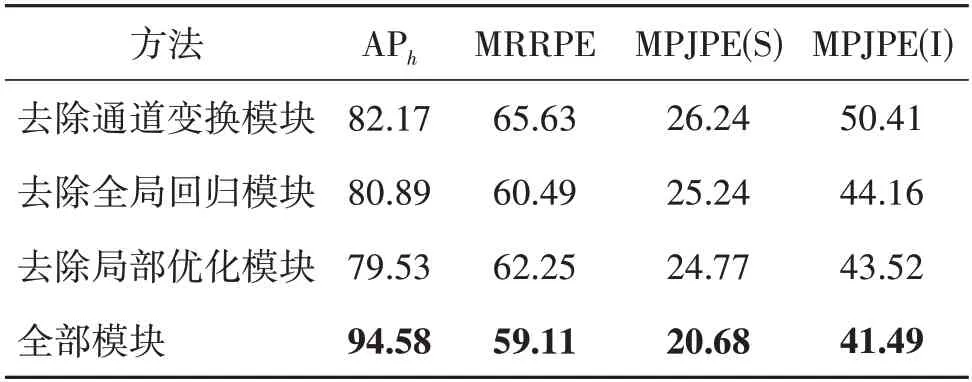
表5 消融实验:不同模块在数据集上的效果Table 5 Ablation experiments:the effect of different modules on the dataset
3 结论
本文提出一种面向单目视觉手势姿态估计的多尺度特征融合网络,可以从不同分辨率特征图中提取不同层次信息,从而有效地处理遮挡边缘和指尖部分的细节,更准确地估计手部姿态。1)该网络采用通道变换模块调整特征通道的比重,增强有用特征通道权重;2)通过全局回归模块融合不同分辨率特征图,保证融合的特征图既能包含图像的边缘细节特性,又能充分利用全局信息;3)通过局部优化模块修正部分未回归到正确位置的关节点;4)在Inter-Hand2.6M 和RHD 数据集上的实验表明,与其他方法相比,本文方法得到了更低的关节点误差,能够更好地对单手和交互手姿态进行估计,可以在一定程度上避免手指遮挡带来的误差,取得了更高的准确性与鲁棒性。
但是,MS-FF 的运行速率比InterNet 方法要慢,这是由于MS-FF 方法的构建过程更加复杂,增加了串行等待和内核启动与同步时间开销。在未来的工作中,将继续优化本文模型,在保证识别精度的同时,增加模型的运行速率,实现更快的识别速度,为在现实场景中快速准确识别手势进行铺垫。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31 09:48:02
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
军营文化天地(2017年6期)2017-06-28 11:30:19
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
实用手外科杂志(2015年4期)2015-08-27 01:54:14
中华皮肤科杂志(2014年4期)2014-12-19 12:56:00
中国药业(2014年21期)2014-05-26 08:56:48
